這個方法之所以有效,是因為均勻分布幫助我們將Mq(x)提供的“封包”縮放到p(x)的概率密度函數。另....

考慮到強化學習[10]訓練大語言模型的困難性,我們從語言建模的角度對大語言模型進行解毒。已有工作將解....

? 本篇內容是對于ACL‘23會議上陳丹琦團隊帶來的Tutorial所進行的學習記錄,以此從問題設置....
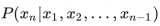
多模態(Multimodality)是指在信息處理、傳遞和表達中涉及多種不同的感知模態或信息來源。這....

大型語言模型的出現極大地推動了自然語言處理領域的進步,但同時也存在一些局限性,比如模型可能會產生看似....
該研究同時提出了一個全新任務,圖像對比 VQA (difference VQA):給定兩張圖片,回答....

現有大模型在預訓練過程中都會加入書籍、論文等數據,那么在領域預訓練時這兩種數據其實也是必不可少的,主....
盡管開源大語言模型 (LLM) 及其變體(例如 LLaMA 和 Vicuna)取得了進步,但它們在執....

隨著 Llama 2 的逐漸走紅,大家對它的二次開發開始流行起來。前幾天,OpenAI 科學家 Ka....

目前 DETR 類模型已經成為了目標檢測的一個主流范式。但 DETR 算法模型復雜度高,推理速度低,....

蘇神最早提出的擴展LLM的context方法,基于bayes啟發得到的公式

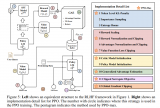
如果你動手跑幾次ppo的過程就發現了,大模型的強化學習非常難以訓練,難以訓練不僅僅指的是費卡,還是指....
最近,大語言模型(Large Language Models, LLMs)的快速發展帶來了自然語言處....
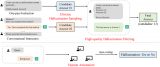
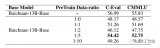
ChatGLM2-6b是清華開源的小尺寸LLM,只需要一塊普通的顯卡(32G較穩妥)即可推理和微調,....

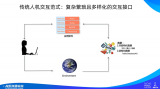
在大模型出來之前,人和數據怎么發生關系?人不能直接與數據發生關系,需要通過一個中介,這個中介就是應用....
LoRA微調是一種高效的融入學習算法。類似人類把新知識融入現有知識體系的學習過程。學習時無需新知識特....
通過線性插值RoPE擴張LLAMA context長度最早其實是在llamacpp項目中被人發現,有....
LLM 是黑箱模型,缺乏可解釋性,因此備受批評。LLM 通過參數隱含地表示知識。因此,我們難以解釋和....

現在chatglm2的代碼針對這兩個問題已經進行了改善,可以認為他就是典型的decoder-only....
對齊:我們提出了一種混合對齊策略,以確保實體在話語和信念狀態中都能被替換為所需的翻譯。具體而言,我們....
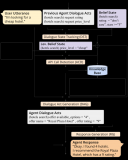
此外,BATGPT還采用了強化學習方法,從AI和人類反饋中學習,以進一步提高模型的對齊性能。這些方法....

大語言模型目前已經成為學界研究的熱點。我們統計了arXiv論文庫中自2018年6月以來包含關鍵詞"語....

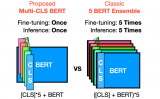
在 GLUE 和 SuperGLUE 數據集上進行了實驗,證明了 Multi-CLS BERT 在提....
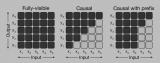
? ? 在大家不斷升級迭代自家大模型的時候,LLM(大語言模型)對上下文窗口的處理能力,也成為一個重....

把大模型的訓練門檻打下來!我們在單張消費級顯卡上實現了多模態大模型(LaVIN-7B, LaVIN-....
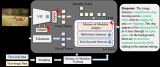
? ? 在這篇文章中,我們將盡可能詳細地梳理一個完整的 LLM 訓練流程。包括模型預訓練(Pretr....

今天分享一篇普林斯頓大學的一篇文章,Tree of Thoughts: Deliberate Pro....

為了解決這一問題,本文提出了三個LLM模型——理解、經驗和事實,將它們合成為一個組合模型。還引入了多....
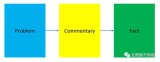
一、概述 1 Motivation 構造instruction data非常耗時耗力,常受限于質量,....

近年來,大規模深度神經網絡的顯著成就徹底改變了人工智能領域,在各種任務和領域展示了前所未有的性能。這....
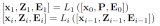



 工商網監
湘ICP備2023018690號-1
工商網監
湘ICP備2023018690號-1

