") 大型語言模型在關(guān)鍵任務(wù)和實(shí)際應(yīng)用中的挑戰(zhàn)
大型語言模型在關(guān)鍵任務(wù)和實(shí)際應(yīng)用中的挑戰(zhàn)
大型語言模型的出現(xiàn)極大地推動了自然語言處理領(lǐng)域的進(jìn)步,但同時也存在一些局限性,比如模型可能會產(chǎn)生看似合理但實(shí)際上是錯誤或虛假的內(nèi)容,這一現(xiàn)象被稱為幻覺(hallucination)。幻覺的存在使得大型語言模型在關(guān)鍵任務(wù)和實(shí)際應(yīng)用中的可靠性受到挑戰(zhàn)。
模型產(chǎn)生幻覺可能是由于模型缺乏或錯誤地理解了相關(guān)的知識。當(dāng)人類思考和記憶事物時,本體知識在我們的思維過程中扮演著重要角色。本體知識涉及類別、屬性以及它們之間的關(guān)系。它幫助我們理解世界、組織和分類信息,并且能夠推導(dǎo)出新的知識。對于語言模型,我們可以通過設(shè)計探測任務(wù),模型內(nèi)部的隱含知識和學(xué)習(xí)偏差。
背景介紹
為了探索大模型在預(yù)訓(xùn)練階段學(xué)習(xí)到的各類知識,研究者們通過設(shè)計探針任務(wù)來對這些模型進(jìn)行測試。通過模型在這些任務(wù)上的表現(xiàn),我們可以了解語言模型在不同方面的學(xué)習(xí)偏差、錯誤或限制,并嘗試改進(jìn)模型的性能和可靠性。然而,現(xiàn)有的知識探針主要研究模型對事實(shí)性知識的記憶,也就是描述具體事實(shí)、屬性和關(guān)系的知識。比如,我們知道在《西游記》中“孫悟空三打白骨精”,這就是一條具體的事實(shí)性知識。
相比事實(shí)性知識,本體知識關(guān)注類和屬性、以及它們之間的關(guān)系,能夠描述概念之間的層級關(guān)系、屬性約束等關(guān)聯(lián),為理解世界知識提供了一種結(jié)構(gòu)化的方式。如下就是一個本體知識圖譜,從“孫悟空三打白骨精”這樣一條事實(shí)性知識,發(fā)散出了更多概念之間的關(guān)聯(lián),包括實(shí)例類型(type)、子類(subclass)、子屬性(subproperty)、屬性領(lǐng)域(domain)和屬性范圍(range)。
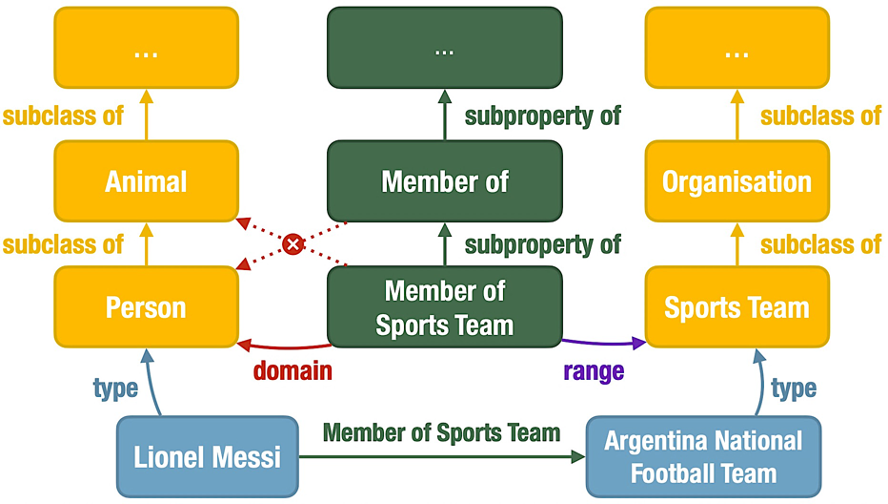
本體知識可以幫助模型更好地理解現(xiàn)實(shí)世界中的對象及其關(guān)系,在問答等許多 NLP 任務(wù)中起著至關(guān)重要的作用。因此,探究預(yù)訓(xùn)練語言模型是否記憶和理解本體知識,能夠拓展學(xué)術(shù)界對語言模型認(rèn)知能力的認(rèn)識,在這個大模型快速發(fā)展的時代具有重要意義。
探針方法
我們研究了基于編碼器的預(yù)訓(xùn)練語言模型 BERT 和 RoBERTa,以及基于解碼器的大模型 ChatGPT。對于編碼器結(jié)構(gòu)模型,我們使用基于提示詞(prompt)的探針方法,探究模型是否能夠根據(jù)未被遮蓋的上下文預(yù)測出正確的答案;而對于解碼器結(jié)構(gòu)模型,我們則將需要填空的提示詞轉(zhuǎn)化成多項(xiàng)選擇題,探究模型是否能夠給出正確的選擇。2.1記憶任務(wù)
我們設(shè)計了五個記憶任務(wù)子測試,每個任務(wù)子測試都是為了探測預(yù)訓(xùn)練語言模型對于一種本體關(guān)系的記憶能力:
1. 給定實(shí)例的類型;
2. 給定類的上級類別;
3. 給定屬性的上級屬性;
4. 給定屬性的領(lǐng)域約束;
5. 給定屬性的范圍約束。
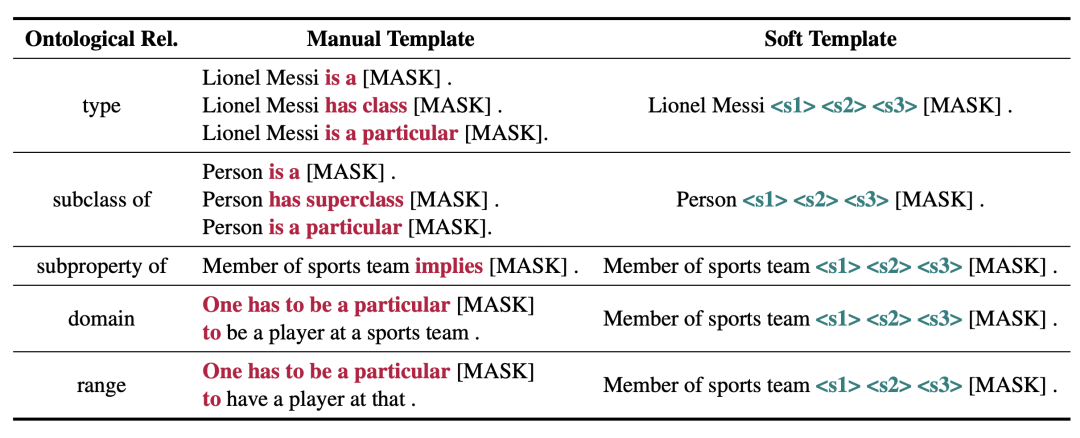
對于 BERT 模型,我們使用人工提示和可訓(xùn)練的軟提示(soft prompt)進(jìn)行探針測試,為每種本體關(guān)系設(shè)計了如下提示詞。模型基于對數(shù)概率預(yù)測,對候選詞進(jìn)行排序。
2.2推理任務(wù)
我們根據(jù)資源描述框架模式(Resource Description Framework Schema, RDFS)中規(guī)定的規(guī)則構(gòu)建推理任務(wù),每個推理子任務(wù)探索預(yù)訓(xùn)練語言模型按照一條三段論規(guī)則進(jìn)行推理的能力。對于每個前提,我們區(qū)分模型輸入中是否明確包含前提,并利用記憶任務(wù)的探針結(jié)果進(jìn)一步區(qū)分這個前提是否被模型記憶,探究前提的不同形式對模型推理的影響。

為了防止模型通過對假設(shè)的記憶而非推理過程得出正確結(jié)論,我們使用生造詞替換假設(shè)提示中包含的特定實(shí)例、類和屬性。對于編碼器結(jié)構(gòu)的模型,我們通過創(chuàng)建沒有特殊語義的詞嵌入來獲得預(yù)訓(xùn)練語言模型的生造詞。
實(shí)驗(yàn)結(jié)果與發(fā)現(xiàn)
3.1記憶任務(wù)
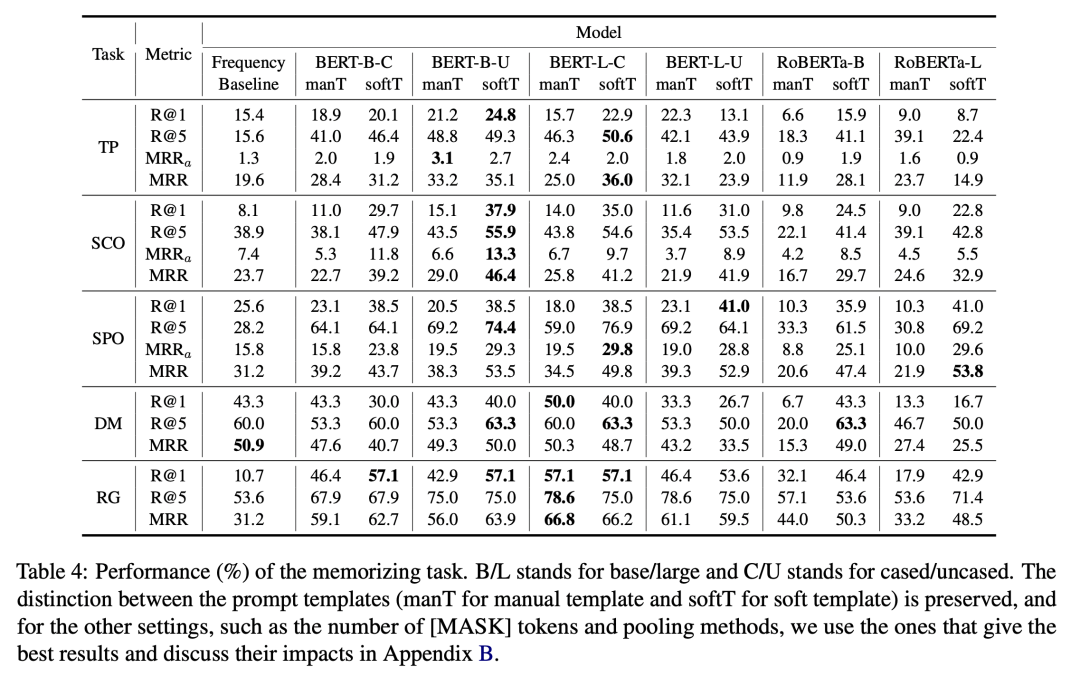
通過對實(shí)驗(yàn)數(shù)據(jù)的分析,我們發(fā)現(xiàn):BERT 和 RoBERTa 模型可以記憶一定的本體知識,但并不完美。
BERT和 RoBERTa 在記憶任務(wù)中擊敗了一個較強(qiáng)的頻率基線模型。這表明,在預(yù)訓(xùn)練過程中,語言模型不僅學(xué)習(xí)了關(guān)于實(shí)體的事實(shí)性知識,而且學(xué)習(xí)了事實(shí)背后更加抽象的本體關(guān)系,這對于模型更好地組織對于世界的認(rèn)識至關(guān)重要。然而,模型在五個子任務(wù)上的準(zhǔn)確率還有很大提升空間,表明模型對本體知識記憶的局限性。
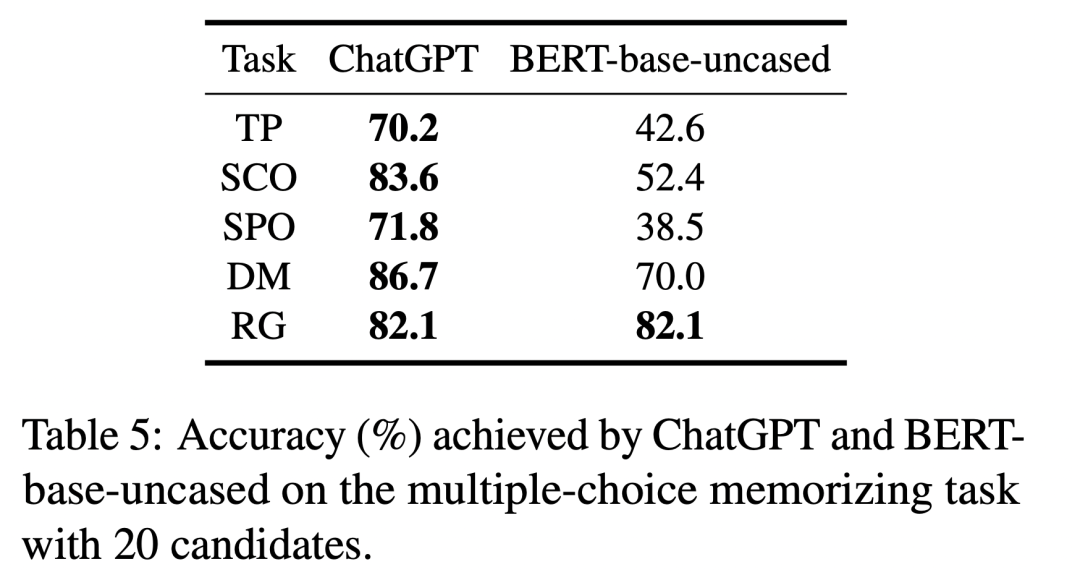
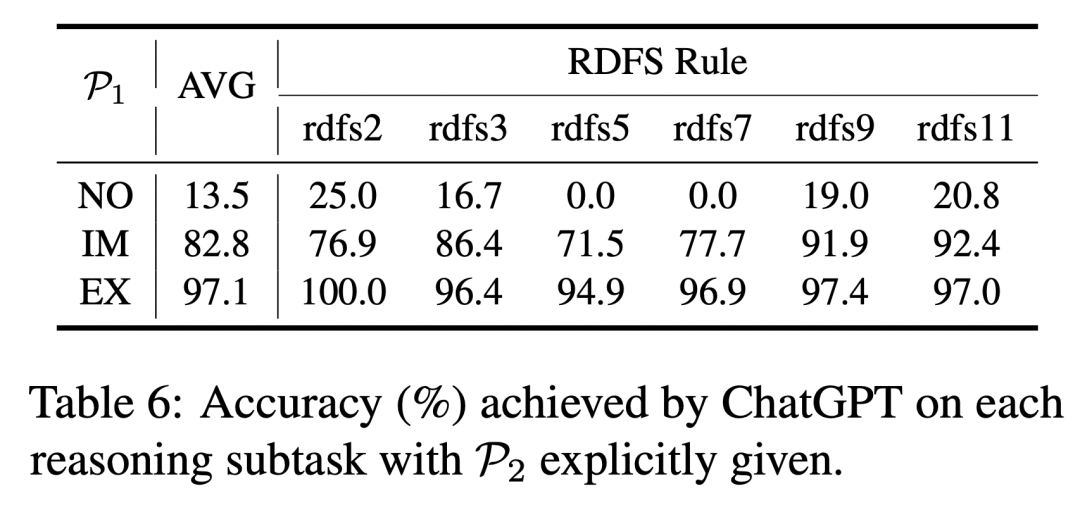
ChatGPT 相比于 BERT 模型,在記憶任務(wù)中準(zhǔn)確率有了顯著提升。
由于多項(xiàng)選擇與填空的難度并不直接可比,我們將多項(xiàng)選擇形式的提示詞輸入給 BERT-base-uncased 模型,并與 ChatGPT 進(jìn)行比較。從下表可以看出,在大多數(shù)與本體知識相關(guān)的記憶任務(wù)中,ChatGPT 在準(zhǔn)確性方面明顯優(yōu)于 BERT-base-uncased,展現(xiàn)出更強(qiáng)的本體知識記憶能力。
3.2推理任務(wù)
通過對實(shí)驗(yàn)數(shù)據(jù)的分析,我們發(fā)現(xiàn):BERT 和 RoBERTa 模型對本體知識的理解也是比較有限的。
下圖展示了對所有推理規(guī)則和 BERT 與 RoBERTa 模型取平均之后的推理表現(xiàn)。當(dāng)輸入文本中明確給出 時,模型能夠顯著提高正確答案的排名。由于 包含了需要預(yù)測的正確答案,這就使人懷疑表現(xiàn)的提升并非通過邏輯推理獲得的,而是因?yàn)槟P蛢A向于預(yù)測輸入中出現(xiàn)的詞及相關(guān)詞匯。 當(dāng)前提被隱式給定時,MRR 高于前提末給定時。這意味著一定程度上,預(yù)訓(xùn)練語言模型可以利用編碼的本體知識,選擇正確的推理規(guī)則進(jìn)行推理。但是,所有的前提組合都不能給出近乎完美(MRR 接近 1)的推理表現(xiàn),說明預(yù)訓(xùn)練語言模型對本體知識的理解能力仍具有局限性。
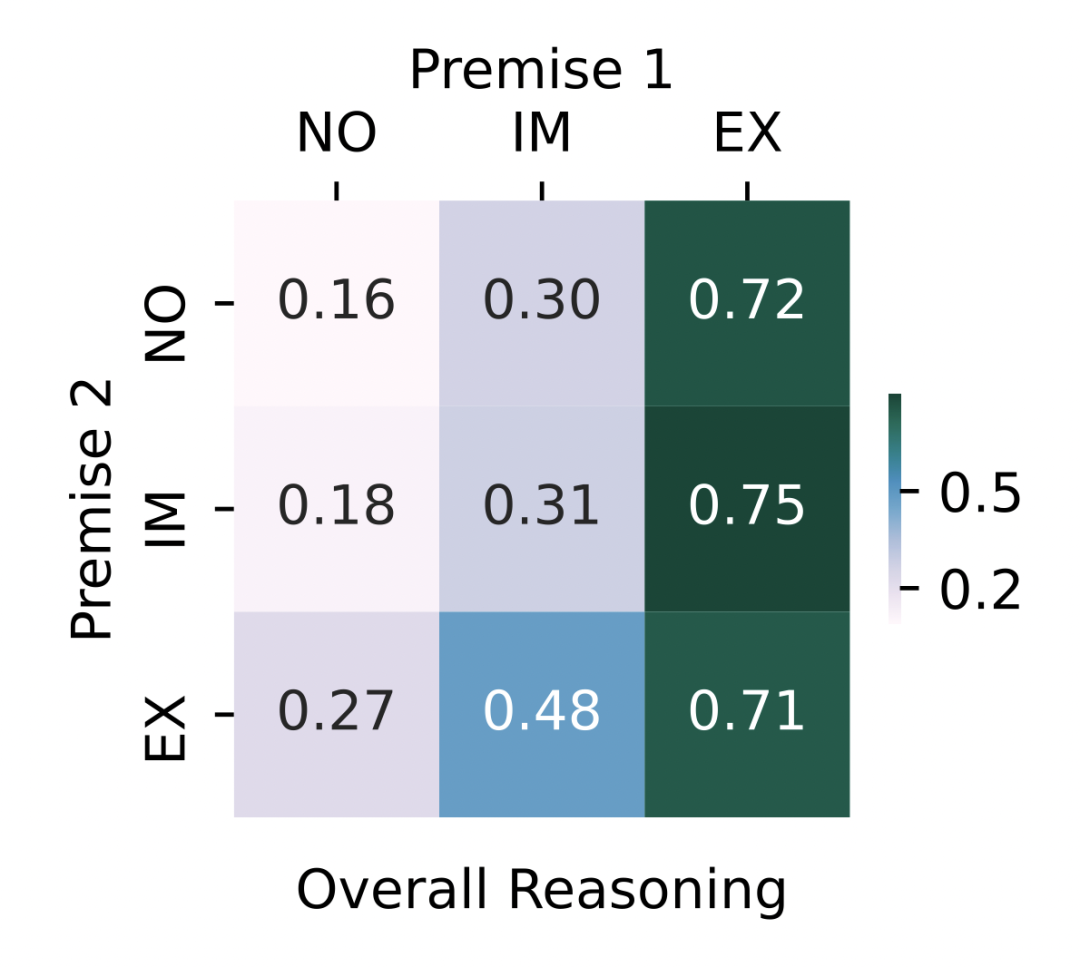
ChatGPT 具有更強(qiáng)大的推理和理解本體知識的能力。
當(dāng)模型輸入或記憶中包含推理前提時,ChatGPT 在各項(xiàng)推理子任務(wù)中展現(xiàn)出了很高的準(zhǔn)確性。同時,與 BERT-base-uncased 模型相比,ChatGPT 的顯式推理能力也更加優(yōu)秀(97.1% vs 88.2%)。
總結(jié)
在本研究中,我們對預(yù)訓(xùn)練語言模型是否能夠在預(yù)訓(xùn)練過程中對本體知識進(jìn)行有效編碼以及是否能夠深入理解語義內(nèi)容進(jìn)行了全面系統(tǒng)的探討,發(fā)現(xiàn)語言模型確實(shí)具備一定的能力來記憶和理解本體知識,并且能夠根據(jù)這些隱含的知識遵循本體知識推理規(guī)則進(jìn)行一定程度的推理。然而,模型的記憶和推理都具有局限性。同時,ChatGPT 在兩個任務(wù)上的亮眼表現(xiàn)證明了模型對本體知識的記憶和理解仍具有進(jìn)一步提升的可能。
責(zé)任編輯:彭菁
-
解碼器
+關(guān)注
關(guān)注
9文章
1148瀏覽量
40938 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7145瀏覽量
89584 -
語言模型
+關(guān)注
關(guān)注
0文章
538瀏覽量
10342 -
自然語言處理
+關(guān)注
關(guān)注
1文章
619瀏覽量
13646 -
大模型
+關(guān)注
關(guān)注
2文章
2551瀏覽量
3172
原文標(biāo)題:ACL 2023杰出論文 | 探測語言模型對本體知識的記憶與理解
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
探索高效的大型語言模型!大型語言模型的高效學(xué)習(xí)方法
【大語言模型:原理與工程實(shí)踐】探索《大語言模型原理與工程實(shí)踐》
【大語言模型:原理與工程實(shí)踐】核心技術(shù)綜述
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
【大語言模型:原理與工程實(shí)踐】大語言模型的評測
【大語言模型:原理與工程實(shí)踐】大語言模型的應(yīng)用
基因組學(xué)大型語言模型在多項(xiàng)任務(wù)中均展現(xiàn)出卓越的性能和應(yīng)用擴(kuò)展空間
大型語言模型有哪些用途?
大型語言模型有哪些用途?大型語言模型如何運(yùn)作呢?
大型語言模型能否捕捉到它們所處理和生成的文本中的語義信息

大型語言模型的應(yīng)用
大語言模型推斷中的批處理效應(yīng)

FP8數(shù)據(jù)格式在大型模型訓(xùn)練中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論