") 如何構(gòu)建及優(yōu)化GPU云網(wǎng)絡(luò)
如何構(gòu)建及優(yōu)化GPU云網(wǎng)絡(luò)
并從計(jì)算節(jié)點(diǎn)成本優(yōu)化、集群網(wǎng)絡(luò)與拓?fù)涞倪x擇等方面論述如何構(gòu)建及優(yōu)化GPU云網(wǎng)絡(luò)。
Part 1:Compute Fabric 計(jì)算節(jié)點(diǎn)的選型
計(jì)算節(jié)點(diǎn)作為AI算力中心的核心組成部分,其成本在建設(shè)報(bào)價(jià)中占據(jù)極大比重。初始獲取的HGX H100物料清單(BoM)通常采用頂級(jí)配置,價(jià)格不菲。
值得注意的是,HGX與NVIDIA的系統(tǒng)品牌DGX不同,它作為一個(gè)授權(quán)平臺(tái),允許合作伙伴根據(jù)需求定制GPU系統(tǒng)。針對(duì)這一特點(diǎn),我們可以從以下幾方面著手,合理優(yōu)化成本,以適應(yīng)業(yè)務(wù)實(shí)際需求;
默認(rèn) HGX H100 機(jī)箱 物料報(bào)價(jià)清單

來(lái)源:SemiAnalysis
選擇中端CPU
LLM大型語(yǔ)言模型訓(xùn)練主要依賴于GPU的密集計(jì)算能力,對(duì)CPU的工作負(fù)載要求不高。CPU在此過(guò)程中承擔(dān)的角色較為簡(jiǎn)單,包括但不限于使用PyTorch進(jìn)行GPU進(jìn)程控制、網(wǎng)絡(luò)初始化、存儲(chǔ)操作以及虛擬機(jī)管理程序的運(yùn)行。選取一款中端性能的CPU例如Intel CPU,可以確保NCCL性能和虛擬化支持方面表現(xiàn)更為出色,且系統(tǒng)錯(cuò)誤率較低。
RAM 降級(jí)到 1 TB RAM 同樣是計(jì)算節(jié)點(diǎn)中相對(duì)昂貴的部分。許多標(biāo)準(zhǔn)產(chǎn)品都具有 2TB 的 CPU DDR 5 RAM,但常規(guī)的AI工作負(fù)載根本不受 CPU RAM 限制,可以考慮減配。 刪除 Bluefield-3 DPU
Bluefield-3 DPU最初是為傳統(tǒng) CPU 云開(kāi)發(fā)的,賣(mài)點(diǎn)在于卸載CPU負(fù)載,讓CPU用于業(yè)務(wù)出租,而不是運(yùn)行網(wǎng)絡(luò)虛擬化。結(jié)合實(shí)際情況,奔著GPU算力而來(lái)的客戶無(wú)論如何都不會(huì)需要太多的 CPU 算力,使用部分 CPU 核心進(jìn)行網(wǎng)絡(luò)虛擬化是可以接受的。此外Bluefield-3 DPU 相當(dāng)昂貴,使用標(biāo)準(zhǔn) ConnectX 智能網(wǎng)卡完全可滿足網(wǎng)絡(luò)性能所需。綜合考慮前述幾項(xiàng)成本的優(yōu)化,已經(jīng)可為單個(gè)服務(wù)器降低約5%的成本。在擁有 128 個(gè)計(jì)算節(jié)點(diǎn)的 1024 H100 集群中,這個(gè)比率背后的金額已經(jīng)相當(dāng)可觀。
英偉達(dá)官網(wǎng)對(duì)Bluefiled-3和CX智能網(wǎng)卡的應(yīng)用解釋?zhuān)築lueField-3 適用于對(duì)數(shù)據(jù)處理和基礎(chǔ)設(shè)施服務(wù)有較高要求的場(chǎng)景,如云計(jì)算、數(shù)據(jù)中心等;ConnectX-7 則更適合需要高速網(wǎng)絡(luò)連接的應(yīng)用,如高性能計(jì)算、人工智能網(wǎng)絡(luò)等。
減少單節(jié)點(diǎn)智能網(wǎng)卡數(shù)量(請(qǐng)謹(jǐn)慎選擇)
標(biāo)準(zhǔn)物料清單中,每臺(tái) H100 計(jì)算服務(wù)器配備八個(gè) 400G CX-7 NIC,單服務(wù)器的總帶寬達(dá)到 3,200Gb/s。如果只使用四塊網(wǎng)卡,后端計(jì)算網(wǎng)的帶寬將會(huì)減少 50%。這種調(diào)整顯而易見(jiàn)可以節(jié)約資金,但多少會(huì)也對(duì)部分AI工作負(fù)載性能造成不利影響。
AI智能網(wǎng)卡Smart NIC主要解決的問(wèn)題是網(wǎng)絡(luò)傳輸上無(wú)法線性傳輸數(shù)據(jù)問(wèn)題,以及卸載更適合在網(wǎng)絡(luò)上執(zhí)行的業(yè)務(wù),更適用于對(duì)網(wǎng)絡(luò)傳輸要求較高的AI網(wǎng)絡(luò)基礎(chǔ)設(shè)施。智能網(wǎng)卡作為后端網(wǎng)絡(luò)的重要組件,配合其他硬件設(shè)備(交換機(jī)與光模塊等)共同解決大規(guī)模網(wǎng)絡(luò)擁塞死鎖、丟包及亂序等一系列網(wǎng)絡(luò)傳輸?shù)膯?wèn)題。因此,我們不建議在AI工作負(fù)載網(wǎng)絡(luò)下減少智能網(wǎng)卡的數(shù)目以達(dá)到避免網(wǎng)絡(luò)傳輸故障的可能。
Kiwi SmartNIC 產(chǎn)品介紹
Kiwi小編將于近期為大家講述AI智能網(wǎng)卡與DPU的主要區(qū)別,敬請(qǐng)期待。
Part 2:集群網(wǎng)絡(luò)的選型
集群網(wǎng)絡(luò)是繼Compute計(jì)算節(jié)點(diǎn)之后的第二大成本來(lái)源。本文舉例的 NVIDIA H100 集群有三種不同的網(wǎng)絡(luò): 后端網(wǎng)絡(luò)(計(jì)算網(wǎng),InfiniBand 或 RoCEv2):用于將 GPU 之間的通信從數(shù)十個(gè)機(jī)架擴(kuò)展到數(shù)千個(gè)機(jī)架。該網(wǎng)絡(luò)可以使 InfiniBand 或 Spectrum-X 以太網(wǎng),也可以使用其他供應(yīng)商的以太網(wǎng)。 前端網(wǎng)絡(luò)(業(yè)務(wù)管理和存儲(chǔ)網(wǎng)絡(luò)): 用于連接互聯(lián)網(wǎng)、SLURM/Kubernetes 和網(wǎng)絡(luò)存儲(chǔ)以加載訓(xùn)練數(shù)據(jù)和Checkpoint。該網(wǎng)絡(luò)通常以每 GPU 25-50Gb/s 的速度運(yùn)行,滿配八卡的情況每臺(tái)GPU服務(wù)器的帶寬將達(dá)到 200-400Gb/s。
帶外管理網(wǎng)絡(luò) :用于重新映像操作系統(tǒng)、監(jiān)控節(jié)點(diǎn)健康狀況(如風(fēng)扇速度、溫度、功耗等)。服務(wù)器上的BMC、機(jī)柜電源、交換機(jī)、液冷裝置等通常連接到此網(wǎng)絡(luò)以監(jiān)控和控制服務(wù)器和各種其他 IT 設(shè)備。
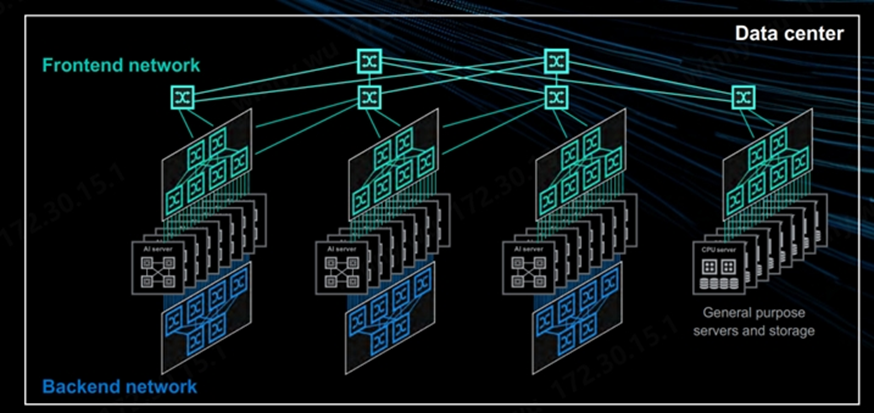
來(lái)源:Marvell ,AI集群網(wǎng)絡(luò)
默認(rèn) HGX H100 集群網(wǎng)絡(luò)物料報(bào)價(jià)清單

來(lái)源:SemiAnalysis
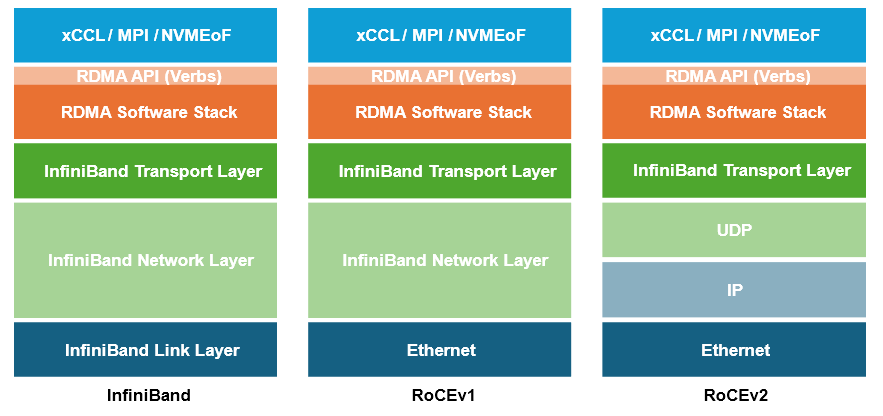
計(jì)算網(wǎng)絡(luò):RoCEv2替代IB
與以太網(wǎng)解決方案相比,NVIDIA 提供的InfiniBand無(wú)疑更昂貴,但部分客戶會(huì)認(rèn)為以太網(wǎng)性能相對(duì)偏低,這主要是因?yàn)橐蕴W(wǎng)需要進(jìn)行必要的無(wú)損網(wǎng)絡(luò)參數(shù)配置并且針對(duì)性調(diào)優(yōu)才能發(fā)揮集合通信庫(kù)的性能。
然而,不過(guò)從對(duì)業(yè)務(wù)性能的影響角度看,目前在萬(wàn)卡以下的AI網(wǎng)絡(luò)技術(shù)背景下使用IB或是RoCEv2作為后端計(jì)算網(wǎng)并沒(méi)有太多差異。這兩類(lèi)網(wǎng)絡(luò)在千卡級(jí)別的集群規(guī)模下經(jīng)過(guò)調(diào)優(yōu)都可以實(shí)現(xiàn)相對(duì)無(wú)損的網(wǎng)絡(luò)傳輸。以下圖示主要基于大規(guī)模集群條件下IB和RoCEv2的共同點(diǎn)與差異點(diǎn)。

IB VS RoCEv2主要區(qū)別
與此同時(shí),隨著遠(yuǎn)程直接內(nèi)存訪問(wèn)(RDMA)被普遍應(yīng)用,現(xiàn)在越來(lái)越多的關(guān)注點(diǎn)轉(zhuǎn)向了將開(kāi)放標(biāo)準(zhǔn)、廣泛采用以太網(wǎng)用于大規(guī)模算力網(wǎng)絡(luò)場(chǎng)景。與InfiniBand相比,以太網(wǎng)降低了成本和復(fù)雜性,并且沒(méi)有可擴(kuò)展性的限制。
AMD近期提及以太網(wǎng)據(jù)最新實(shí)例統(tǒng)計(jì),在后端網(wǎng)絡(luò),相比InfiniBand,以太網(wǎng)RoCEv2是更好的選擇,具有低成本、高度可擴(kuò)展的優(yōu)勢(shì),可將TCO節(jié)省超過(guò)50%,能夠擴(kuò)展100萬(wàn)張GPU。而InfiniBand至多能擴(kuò)展48000張GPU。
無(wú)論是在AI訓(xùn)推的測(cè)試場(chǎng)景,還是頭部云廠商已有的組網(wǎng)案例中,AI以太網(wǎng)都有了大量成功案例可供參考。據(jù)統(tǒng)計(jì),在全球 TOP500 的超級(jí)計(jì)算機(jī)中,RoCE和IB的占比相當(dāng)。以計(jì)算機(jī)數(shù)量計(jì)算,IB 占比為 47.8%, RoCE 占比為 39%; 而以端口帶寬總量計(jì)算,IB占比為 39.2%,RoCE 為 48.5%。目前包括奇異摩爾在內(nèi)的AI產(chǎn)業(yè)鏈成員相信有著開(kāi)放生態(tài)的高速以太網(wǎng)將會(huì)得到快速發(fā)展。
前端網(wǎng)絡(luò):合理降低帶寬速率
NVIDIA 和一些OEM/系統(tǒng)集成商通常會(huì)在服務(wù)器提供 2x200GbE 前端網(wǎng)絡(luò)連接,并使用 Spectrum Ethernet SN4600 交換機(jī)部署網(wǎng)絡(luò)。我們知道,這張網(wǎng)絡(luò)僅用于進(jìn)行存儲(chǔ)和互聯(lián)網(wǎng)調(diào)用以及傳輸基于 SLURM,Kubernetes 等管理調(diào)度平臺(tái)的帶內(nèi)管理流量,并不會(huì)用于時(shí)延敏感和帶寬密集型的梯度同步。每臺(tái)服務(wù)器 400G 的網(wǎng)絡(luò)連接在常規(guī)情況下將遠(yuǎn)超實(shí)際所需,其中存在一些成本壓縮空間。
帶外管理網(wǎng)絡(luò):選用通用的以太網(wǎng)交換機(jī)
NVIDIA 默認(rèn)物料清單一般包括 Spectrum 1GbE 交換機(jī),價(jià)格昂貴。帶外管理網(wǎng)絡(luò)用到的技術(shù)比較通用,選擇市場(chǎng)上成本更優(yōu)的 1G 以太網(wǎng)交換機(jī)完全夠用。
Part 3:計(jì)算網(wǎng)絡(luò)拓?fù)涞募軜?gòu)優(yōu)化
GPU集群計(jì)算網(wǎng)將承載并行計(jì)算過(guò)程中產(chǎn)生的各類(lèi)集合通信(all-reduce,all-gather 等),流量規(guī)模和性能要求與傳統(tǒng)云網(wǎng)絡(luò)完全不同。
NVIDIA 推薦的網(wǎng)絡(luò)拓?fù)涫且粋€(gè)具有無(wú)阻塞連接的兩層胖樹(shù)網(wǎng)絡(luò),理論上任意節(jié)點(diǎn)對(duì)都應(yīng)該能同時(shí)進(jìn)行線速通信。但由于存在鏈路擁塞、不完善的自適應(yīng)路由和額外跳數(shù)的帶來(lái)的通信延遲,真實(shí)場(chǎng)景中無(wú)法達(dá)到理論最優(yōu)狀態(tài),需要對(duì)其進(jìn)行性能優(yōu)化。
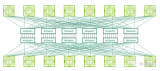
軌道優(yōu)化(Rail-optimized)架構(gòu)
舉例來(lái)說(shuō):Nvidia的DGX H100服務(wù)器集成了八個(gè)通過(guò)NVSwitches連接的H100 GPU,實(shí)現(xiàn)了7.2 TBps的無(wú)阻塞內(nèi)部帶寬。而GB200 NVL72計(jì)算機(jī)則更進(jìn)一步,以每GPU 14.4 TBps的速度將72個(gè)B200超級(jí)芯片通過(guò)第五代NVLink技術(shù)連接在機(jī)架內(nèi)。(相關(guān)閱讀:預(yù)計(jì)OCP成員全球市場(chǎng)影響力突破740億美元——OCP 2024 Keynote 回顧)
這里將這些具備TB級(jí)內(nèi)部帶寬的平臺(tái)統(tǒng)稱(chēng)為高帶寬域”HBD”。Rail優(yōu)化網(wǎng)絡(luò)作為一種先進(jìn)的互聯(lián)架構(gòu)被廣泛應(yīng)用。然而,盡管Rail優(yōu)化網(wǎng)絡(luò)在降低局部通信延遲方面表現(xiàn)出色,但它依然依賴于Spine交換機(jī)層來(lái)連接各個(gè)Rail交換機(jī),形成完全二分法的Clos網(wǎng)絡(luò)拓?fù)洹_@種設(shè)計(jì)確保了不同HB域中的GPU能以TB級(jí)別速率進(jìn)行高效通信。
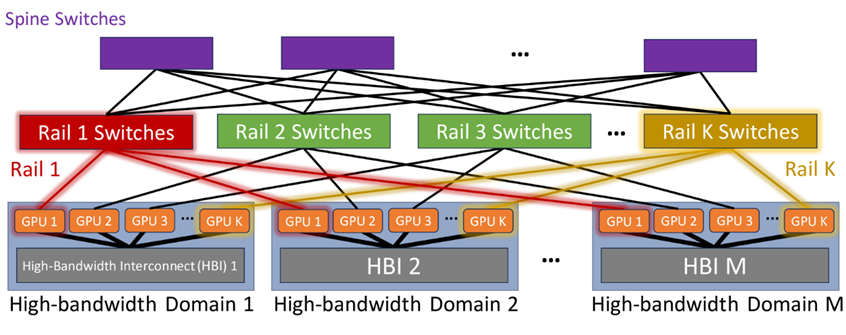
(Source:https://arxiv.org/html/2307.12169v4)
軌道優(yōu)化網(wǎng)絡(luò)的主要優(yōu)勢(shì)是減少網(wǎng)絡(luò)擁塞。因?yàn)橛糜?AI 訓(xùn)練的 GPU 會(huì)定期并行底發(fā)送數(shù)據(jù),通過(guò)集合通信來(lái)在不同GPU之間交換梯度并更新參數(shù)。如果來(lái)自同一服務(wù)器的所有 GPU 都連接到同一個(gè) ToR 交換機(jī),當(dāng)它們將并行流量發(fā)送到網(wǎng)絡(luò),使用相同鏈路造成擁塞的可能性會(huì)非常高。如果追求極致的成本優(yōu)化,可以試用一種Raily-Only單層軌道交換機(jī)網(wǎng)絡(luò)。
Raily-Only單層軌道交換機(jī)網(wǎng)絡(luò)
Meta在近期就發(fā)表過(guò)類(lèi)似的文章,提出了一種革命性思路-拋棄交換機(jī)Spine層。
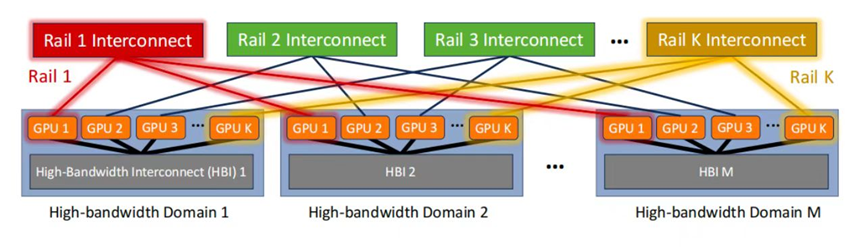
(Source:https://arxiv.org/html/2307.12169v4)
相較于傳統(tǒng)的Rail-optimized GPU集群,Rail-only網(wǎng)絡(luò)保留了HB域和Rail交換機(jī),但巧妙地移除了Spine交換機(jī)。這一變革確保了同一網(wǎng)絡(luò)內(nèi)的GPU對(duì)之間的帶寬保持不變,同時(shí)實(shí)現(xiàn)了網(wǎng)絡(luò)Fabric的精簡(jiǎn)與成本的降低。具體來(lái)說(shuō),通過(guò)移除Spine交換機(jī)并重新配置Rail交換機(jī)與GPU之間的鏈路,他們構(gòu)建了一個(gè)專(zhuān)用且獨(dú)立的Clos網(wǎng)絡(luò),每個(gè)Rail獨(dú)立運(yùn)行。由于Rail交換機(jī)擁有富余的下行端口直接連接GPU,相較于Rail-optimized網(wǎng)絡(luò),Rail-only設(shè)計(jì)顯著減少了所需交換機(jī)的數(shù)量,從而降低了整體網(wǎng)絡(luò)成本。
在Rail-only網(wǎng)絡(luò)中,不同HBD域之間的直接連通性被移除,但數(shù)據(jù)仍可通過(guò)HBD域內(nèi)的轉(zhuǎn)發(fā)實(shí)現(xiàn)跨域通信。例如, GPU 1(Domain 1)向GPU 2(Domain 2)發(fā)送消息時(shí),首先通過(guò)第一個(gè)HBD域到達(dá)Domain 2的某個(gè)GPU,再經(jīng)網(wǎng)絡(luò)傳輸至最終目的地。
確定合適的超額訂閱率 軌道優(yōu)化拓?fù)涞牧硪粋€(gè)好處可以超額訂閱(Oversubscription)。在網(wǎng)絡(luò)架構(gòu)設(shè)計(jì)的語(yǔ)境下,超額訂閱指的是提供更多的下行容量;超額訂閱率即下行容量(到服務(wù)器/存儲(chǔ))和上行帶寬(到上層Spine交換機(jī))的比值,在 Meta 的 24k H100 集群里這個(gè)比率甚至已經(jīng)來(lái)到夸張的7:1。
通過(guò)設(shè)計(jì)超額訂閱,我們可以通過(guò)突破無(wú)阻塞網(wǎng)絡(luò)的限制進(jìn)一步優(yōu)化成本。這點(diǎn)之所以可行是因?yàn)?8 軌的軌道優(yōu)化拓?fù)淅铮蠖鄶?shù)流量傳輸發(fā)生在 pod 內(nèi)部,跨 pod 流量的帶寬要求相對(duì)較低。結(jié)合足夠好的自適應(yīng)路由能力和具備較大緩沖空間的交換機(jī),我們可以規(guī)劃一個(gè)合適的超額訂閱率以減少上層Spine交換機(jī)的數(shù)量。
但值得注意的是,無(wú)論是IB還是RoCEv2,當(dāng)前還沒(méi)有一個(gè)完美的方案規(guī)避擁塞風(fēng)險(xiǎn),兩者應(yīng)對(duì)大規(guī)模集合通信流量時(shí)均有所不足,故超額訂閱不宜過(guò)于激進(jìn)。現(xiàn)階段如果是選用基于以太網(wǎng)的AI網(wǎng)絡(luò)方案, 仍推薦1:1的無(wú)阻塞網(wǎng)絡(luò)設(shè)計(jì)。
多租戶隔離
參考傳統(tǒng)CPU云的經(jīng)驗(yàn),除非客戶長(zhǎng)期租用整個(gè)GPU集群,否則每個(gè)物理集群可能都會(huì)有多個(gè)并發(fā)用戶,所以GPU云算力中心同樣需要隔離前端以太網(wǎng)和計(jì)算網(wǎng)絡(luò),并在客戶之間隔離存儲(chǔ)。基于以太網(wǎng)實(shí)現(xiàn)的多租戶隔離和借助云管平臺(tái)的自動(dòng)化部署已經(jīng)有大量成熟的方案。如采用InfiniBand方案,多租戶網(wǎng)絡(luò)隔離是使用分區(qū)密鑰 (pKeys) 實(shí)現(xiàn)的:客戶通過(guò) pKeys 來(lái)獲得獨(dú)立的網(wǎng)絡(luò),相同 pKeys 的節(jié)點(diǎn)才能相互通信......
關(guān)于我們
AI網(wǎng)絡(luò)全棧式互聯(lián)架構(gòu)產(chǎn)品及解決方案提供商
奇異摩爾,成立于2021年初,是一家行業(yè)領(lǐng)先的AI網(wǎng)絡(luò)全棧式互聯(lián)產(chǎn)品及解決方案提供商。公司依托于先進(jìn)的高性能RDMA 和Chiplet技術(shù),創(chuàng)新性地構(gòu)建了統(tǒng)一互聯(lián)架構(gòu)——Kiwi Fabric,專(zhuān)為超大規(guī)模AI計(jì)算平臺(tái)量身打造,以滿足其對(duì)高性能互聯(lián)的嚴(yán)苛需求。
我們的產(chǎn)品線豐富而全面,涵蓋了面向不同層次互聯(lián)需求的關(guān)鍵產(chǎn)品,如面向北向Scale out網(wǎng)絡(luò)的AI原生智能網(wǎng)卡、面向南向Scale up網(wǎng)絡(luò)的GPU片間互聯(lián)芯粒、以及面向芯片內(nèi)算力擴(kuò)展的2.5D/3D IO Die和UCIe Die2Die IP等。這些產(chǎn)品共同構(gòu)成了全鏈路互聯(lián)解決方案,為AI計(jì)算提供了堅(jiān)實(shí)的支撐。
奇異摩爾的核心團(tuán)隊(duì)匯聚了來(lái)自全球半導(dǎo)體行業(yè)巨頭如NXP、Intel、Broadcom等公司的精英,他們憑借豐富的AI互聯(lián)產(chǎn)品研發(fā)和管理經(jīng)驗(yàn),致力于推動(dòng)技術(shù)創(chuàng)新和業(yè)務(wù)發(fā)展。團(tuán)隊(duì)擁有超過(guò)50個(gè)高性能網(wǎng)絡(luò)及Chiplet量產(chǎn)項(xiàng)目的經(jīng)驗(yàn),為公司的產(chǎn)品和服務(wù)提供了強(qiáng)有力的技術(shù)保障。我們的使命是支持一個(gè)更具創(chuàng)造力的芯世界,愿景是讓計(jì)算變得簡(jiǎn)單。奇異摩爾以創(chuàng)新為驅(qū)動(dòng)力,技術(shù)探索新場(chǎng)景,生態(tài)構(gòu)建新的半導(dǎo)體格局,為高性能AI計(jì)算奠定穩(wěn)固的基石。
-
gpu
+關(guān)注
關(guān)注
28文章
4774瀏覽量
129353 -
AI
+關(guān)注
關(guān)注
87文章
31513瀏覽量
270333 -
云網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
45瀏覽量
9135 -
算力
+關(guān)注
關(guān)注
1文章
1012瀏覽量
14954
原文標(biāo)題:成本優(yōu)化?網(wǎng)絡(luò)拓?fù)鋼駜?yōu)?一文剖析如何構(gòu)建并優(yōu)化AI算力云網(wǎng)絡(luò)
文章出處:【微信號(hào):奇異摩爾,微信公眾號(hào):奇異摩爾】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
GPU云計(jì)算服務(wù)怎么樣
GPU加速云服務(wù)器怎么用的
GPU云服務(wù)器租用費(fèi)用貴嗎
GPU云服務(wù)器租用多少錢(qián)
一文梳理:如何構(gòu)建并優(yōu)化GPU云算力中心?
TI TDA2x SoC上基于GPU的環(huán)視優(yōu)化

【「大模型時(shí)代的基礎(chǔ)架構(gòu)」閱讀體驗(yàn)】+ 未知領(lǐng)域的感受
GPU云服務(wù)器架構(gòu)解析及應(yīng)用優(yōu)勢(shì)
AI云服務(wù)器:開(kāi)啟智能計(jì)算新時(shí)代
應(yīng)用NVIDIA Spectrum-X網(wǎng)絡(luò)構(gòu)建新型主權(quán)AI云
如何構(gòu)建多層神經(jīng)網(wǎng)絡(luò)
恒訊科技的GPU云解決方案有什么特點(diǎn)和優(yōu)勢(shì)?
新手小白怎么學(xué)GPU云服務(wù)器跑深度學(xué)習(xí)?
GPU/TPU集群網(wǎng)絡(luò)組網(wǎng)間的連接方式





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論