 攜程信息安全部在web攻擊識別方面的機器學習實踐之路
攜程信息安全部在web攻擊識別方面的機器學習實踐之路
背景
通俗地講,任何一個的機器學習問題都可以等價于一個尋找合適變換函數的問題。例如語音識別,就是在求取合適的變換函數,將輸入的一維時序語音信號變換到語義空間;而近來引發全民關注的圍棋人工智能AlphaGo則是將輸入的二維布局圖像變換到決策空間以決定下一步的最優走法;相應的,人臉識別也是在求取合適的變換函數,將輸入的二維人臉圖像變換到特征空間,從而唯一確定對應人的身份。
在web應用攻擊檢測的發展歷史中,到目前為止,基本是依賴于規則的黑名單檢測機制,無論是web應用防火墻或ids等等,主要依賴于檢測引擎內置的正則,進行報文的匹配。雖說能夠抵御絕大部分的攻擊,但我們認為其存在以下幾個問題:
規則庫維護困難,人員交接工作,甚至時間一長,原作者都很難理解當初寫的規則,一旦有誤報發生,上線修改都很困難。
規則寫的太寬泛易誤殺,寫的太細易繞過。
例如一條檢測sql注入的正則語句如下:
Stringinj_str = “’|and|exec|insert|select|delete|update|count|*|%|chr|mid|master|truncate|char|declare|;|or|-|+|,”;
一條正常的評論,“我在selected買的襯衫臟了”,遭到誤殺。
正則引擎嚴重影響性能,尤其是正則條數過多時,比如我們之前就遇到kafka中待檢測流量嚴重堆積的現象。
那么該如何解決以上問題呢?尤其在大型互聯網公司,如何在海量請求中又快又準地識別出惡意攻擊請求,成為擺在我們面前的一道難題。
近來機器學習在信息安全方面的應用引起了人們的大量關注,我們認為信息安全領域任何需要對數據進行處理,做出分析預測的地方都可以用到機器學習。本文將介紹攜程信息安全部在web攻擊識別方面的機器學習實踐之路。
惡意攻擊檢測系統nile架構介紹

圖1: 攜程nile 攻擊檢測系統架構第一版
首先我們簡單介紹一下攜程攻擊檢測系統nile的最初架構,如上圖1所示,我們在流量進入規則引擎(這里指正則匹配引擎)之前,先用白名單過濾掉大于97%的正常流量(我們認為如http://ctrip.com/flight?Search?key=value,只要value參數值里面沒有英文標點和控制字符的都是“正常流量”,另外還有攜程的出口ip流量等等)。
剩下的3%流量過正則規則引擎,如果結果為黑(惡意攻擊),就會發到漏洞自動化驗證系統hulk(hulk介紹可以參考https://zhuanlan.zhihu.com/p/28115732),例如調用sqlmap去重放流量,復驗攻擊者能否真的攻擊成功。
目前nile系統我們改進到了第五版,架構如下圖2,其中最重要的改變是在規則引擎之前加入了spark機器學習引擎,目前使用的是spark mllib庫來建模和預測。如果機器學習引擎為黑,則會繼續拋給正則規則引擎做二次檢查,若復驗依然為黑,則會拋給hulk漏洞驗證系統。

圖2:攜程nile 攻擊檢測系統架構最新版
這么做帶來了以下好處:
機器學習的處理速度比較快,能夠過濾掉大部分流量再扔給正則引擎。解決了過去正則導致kafka堆積嚴重的問題(即使是原始流量中的3%也存在此問題)。
可以對比正則引擎和機器學習引擎的結果,互相查缺補漏。例如我們可以發現正則的漏報或誤報,手工修改或補充已有的正則庫。若是機器學習誤報,白流量識別為黑,首先想到的是否黑樣本不純,另外就是特征提取有問題。
如果機器學習漏報,那怎么辦呢?按圖2的流程我們根本不知道我們漏報了哪些。最直接的想法就是并列機器學習引擎和正則引擎,來查缺補漏,但這樣違背了我們追求效率的前提。
最近的一個版本我們加入了動態ip黑名單,時間窗口內多次命中的的高風險ip重點關注,直接忽略storm白名單。在實踐中,我們借鑒了此部分黑ip的流量來補充我們的學習樣本(黑ip的流量99%以上都是攻擊流量),我們發現了referer,ua注入等,其他還發現了其他邏輯攻擊的痕跡,比如訂單遍歷等等。
有人可能會問,根據上面的架構,如果對方拿新流出的攻擊poc來攻擊你,只攻擊1次,那不是檢測不出來了么?首先如果poc中還是有很多的特殊英文標點和敏感單詞的話,我們還是能檢測出來的;另一種情況如果真的漏了,那怎么辦,這時候只能人肉寫新的正則加入檢測邏輯中,如圖2中我們加入了“規則引擎(新上規則)”直接進行檢測,經過不斷的打標簽吐到es日志,新型攻擊的日志又可以作為學習用的黑樣本了,如此循環。
加入機器學習前后的效果對比:kafka消費流量:1萬/分鐘->400萬+,白名單之后的檢測量:1萬/分鐘->10萬+。
我們設置了一分鐘一個批次消費,每分鐘有10萬+數據從storm過來,只花了10秒鐘左右處理完,所以如果我們縮短消費批次窗口,理論上還可以提高5-6倍的吞吐,如下圖3。

圖3:新架構下storm處理速度
我們先看一個機器學習的識別結果,如下圖4:

圖4:機器學習es記錄日志
rule_result標簽是正則的識別結果,由于當時我們沒有添加struts2攻擊的正則,但是由ES日志結果可知,機器學習引擎依然檢測出了攻擊。
介紹了完了架構,回歸機器學習本身,下面將介紹如何建立一個web攻擊檢測的機器學習模型。而一般來講,應用機器學習解決實際問題分為以下4個步驟:
定義目標問題
收集數據和特征工程
訓練模型和評估模型效果
線上應用和持續優化
定義目標問題
核心的目標問題:
二分類問題,預測流量是攻擊或者正常
漏報率必須<10%以上(在這里,我們認為漏報比誤報問題更嚴重,誤報我們還可以通過第二層的正則引擎去糾正)
模型預測速度必須快,例如knn最近鄰這種帶排序的算法被我們剔除在外
機器學習應用于信息安全領域,第一道難關就是標簽數據的缺乏,得益于我們的ES日志中已有正則打上標簽的真實生產流量,所以這里我們決定使用基于監督學習的二分類來建模。監督學習的目的是通過學習許多有標簽的樣本,然后對新的數據做出預測。當然也有人提出過無監督的思路,建立正常流量模型,不符合模型的都識別為惡意,比如使用聚類分析,本文不做進一步討論。
沒有一個機器學習模型可以解決所有的問題, 我們可以借鑒前人的經驗,比如貝葉斯適用垃圾郵件識別,HMM適用語音識別。具體的算法對比可參考https://s3-us-west-2.amazonaws.com/mlsurveys/54.pdf
明確了我們需要達到的目標,下面開始考慮“收集數據和特征工程 ”,也是我們認為模型成敗最關鍵的一步。
收集數據和特征工程
我們寫段腳本,分別按天分時間段取ES黑白數據,并將其分開存儲,再加上自研waf的告警日志,以及網上收集的poc,至此我們的訓練原始材料準備好了 。另外特別需要注意的是:get請求和post請求我們分開提取特征,分開建模,至于為什么請讀者自行思考。
一開始本地實驗時,我是選用的python的sklearn庫,訓練樣本黑白數據分別為10w+條數據,達到1比1的平衡占比。項目上線的時候,我們采用的是spark mllib來做的。本文為了介紹方便,還是以python+sklean來進行介紹。
再來聊聊“特征工程”。我們認為“特征工程”是機器模型中最重要的一部分,其更像是一門藝術,往往依賴于專家的“直覺”和專業領域經驗,更甚者有人調侃機器學習其實就是特征工程。你能相信一個從來不看NBA的人建模出來的NBA總決賽預測結果模型么?
限于篇幅,這里主要介紹我們認為項目中比較重要的“特征工程”的步驟:
特征提煉:
核心需求:從訓練數據中提取哪些有效信息,需要這些信息如何組織?
我們觀察一下ES日志中攻擊語句和正常語句的區別,如下:
攻擊語句:flights.ctrip.com/Process/checkinseat/index?tpl_content=&name=test404.php&dir=index/../../../..¤t_dir=tpl
正常語句:flights.ctrip.com/Process/checkinseat/index?tpl_content=hello,world!
明顯我們看到攻擊語句里面最明顯的特征是,含有eval, ../等字符、標點,而正常語句我們看到含有英文逗號,感嘆號等等,所以我們可以將例如eval的個數列出來作為一個特征維度。在實際處理中我們忽略了uri,只取value參數中的值來提特征。比如上面的2條語句flights.ctrip.com/Process/checkinseat/index?tpl_content部分都被我們忽略了。
defget_evil_eval(url):
returnlen(re.findall("(eval)",url,re.IGNORECASE))
如果不存在value,例如是敏感目錄猜測攻擊,那怎么辦,我們的做法是分開對待,剔除掉例如flights.ctrip.com等無效數據,取整個uri來提特征。
假設我們規定取5種特征,分別是script,eval,單引號,雙引號,左括號的個數,那么上面攻擊語句就轉換為[0,1,0,0,2]
最后我們得到一個攻擊語句的特征是5維的,打上標簽label=1 ,正常流量label=0做區分。這樣,一個請求就轉換成一個1*n的矩陣,m個訓練樣本就是m*n的輸入建模。
但是上線了第一版后,雖然消息隊列消費速度大幅提升,識別率也基本都還可以,但我們還是放棄了這種正則匹配語句的特征提取方法,這里說下原因:
這樣用正則來提取特征,總會有遺漏的關鍵詞,又會陷入查缺補漏的怪圈
優化特征較麻煩,例如加上某個特征維度后,會增加誤報,去掉后又會增加漏報
預測的時候,還是要將請求語句過一遍正則,轉化為數字向量特征,降低了引擎效率
我們得到了使用機器學習來做情感二分類的啟發,查證了資料1https://github.com/jeonglee/ML后,決定替換掉正則提取特征的方式,采用tfidf來提取特征。
我們認為本質上情感二分類和黑白流量分類是比較相似的問題,前者是給出一句話例如“Tom,you are not a good boy!”來判斷是否正面評價,而我們的語句中沒那么多正面或負面的情感詞,更多的是英文標點和和一些疑似高危詞語如select,那我們概念替換一下,高危英文標點是否就像是負面情感詞,其他詞就像是中性詞,從而我們的問題就變成了二分類“中性語句和惡意語句”。
這里簡單介紹下tfidf,更詳盡的可以參考https://en.wikipedia.org/wiki/Tfidf。
例如我們有1000條get請求語句,第一條語句共計10個單詞,其中單引號有3個,from也有3個。1000條語句中有10條語句包含單引號,100條包含from,tfidf計算如下(在進行tfidf計算之前,我們需要對句子中的標點和特殊字符做處理,比如轉為string類型,具體參考資料1):

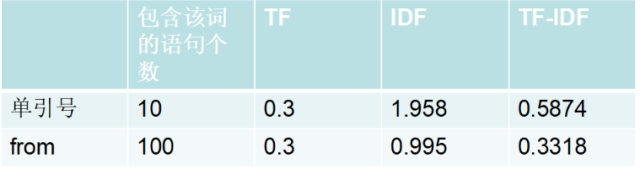
計算結果:單引號的tfidf=0.587 > from的tfidf=0.3318
TFIDF的主要思想是:如果某個詞或短語在一篇文章中出現的頻率,并且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。這里和我們的大腦判斷基本一致,單引號的tfidf值對比之下更大,比from更能代表一句話是否是攻擊語句。
代碼demo如下:

之所以取ngram_range={1,3},是因為我們想保存前后單詞間的順序關系作為特征的一部分,例如前面的“Tom,you are not a good boy!”中的一個維度特征是[not, a , good],然后計算得到這個“集合詞”的tfidf 。當然你可以基于char來取特征,具體的參數取值寬度都需要實驗來證明哪一種效果最好。至于去停用詞,標點怎么轉換等等,大家可以參考https://github.com/jeonglee/ML/blob/master/spark/NaiveBayes/src/main/java/WordParser.java,這里就不贅述。
樣本數據清洗:
雖然我們已經明確了如何提取特征,建模貌似也ok了,這時我們問自己一個問題:訓練數據覆蓋率怎么樣,原始訓練數據的標簽是否準確?如果我們本身的訓練樣本就不純凈,結果一定也不盡如人意。下面說一下我們在樣本清洗中做過的工作:
優化已有的檢測正則:當打開white.txt和black.txt,我們肉眼觀察了一下,發現不少的錯誤歸類,所以說明我們的正則引擎本身就存在優化的需要。
加入動態ip黑名單,收集其攻擊日志,加入黑樣本。經過我們觀察,發現這種持續拿掃描器掃描的ip,其黑流量占比99%以上
關于白樣本,我們可以直接按時間段取原始流量作為白樣本數據,因為畢竟白樣本占鏡像流量的99.99%以上
樣本去重,相同請求內容語句進行去重
一些加密請求,根據參數名稱,從樣本中剔除
自建黑詞庫,放到白樣本去中去匹配是否命中詞庫內容,查找標簽明顯錯誤的樣本。舉個例子,建立一個黑詞庫[base64_decode, onglcontext, img script, struts2....],然后放到白樣本里去查找匹配中的句子,剔除之。其實這種方法可應用的地方很多,例如旅游業的機器人客服,就可以用酒店的關鍵詞去火車票的樣本中去清洗數據,我們也是受此啟發。
特征清洗大概占我們工作量的60%以上,也是不可避免的持續優化的過程,屬于體力活,無法避免。
特征歸一化:由于這里我們采取了tfidf,所以這里就沒有使用歸一化處理了,因為詞頻tf就帶了防止偏向長句子的歸一化效果。這里再提一下,如果用第一版正則取特征的方式就必須使用特征歸一化,具體原因和歸一化介紹請參考http://blog.csdn.net/leiting_imecas/article/details/54986045 。
訓練模型和評估模型效果
初步評判sklearn訓練模型很簡單,這里我們交叉訓練下,拿50%的數據訓練,50%的數據做測試,看下效果是否符合預期。
如果此時交叉訓練的結果不盡如人意,一般原因有3個,且一般是下列第一、二種原因導致偏離預期結果較遠,我們認為算法只是錦上添花,特征工程和樣本的質量才是準確率高低的關鍵。
特征提取有問題,這個沒辦法,完全基于個人特定范圍的知識領域經驗
訓練樣本有問題,錯誤標簽較多,或者樣本不平衡
算法和選取的訓練參數需要優化
前面2個都介紹過了,下面我們講一下參數如何優化,這里我們介紹使用sklearn里面的GridSearchCV,其基本原理是系統地遍歷多種參數組合,通過交叉驗證確定最佳效果參數,參考官方使用示例http://scikit-learn.org/dev/modules/generated/sklearn.grid_search.GridSearchCV.html。
交叉訓練達到心理預期之后,我們就將訓練得到的本地模型存儲到硬盤上,方便下次直接load使用。
訓練和在線預測的demo代碼如下,首先我們將黑白樣本存儲在trainData.csv,分別存在uri和label標簽下,
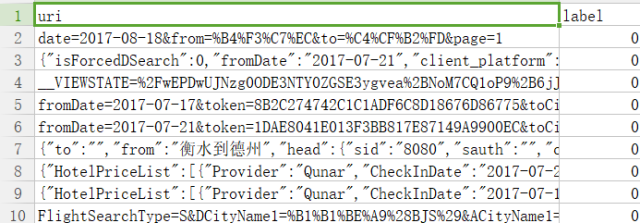
圖5:訓練樣本數據csv存儲格式
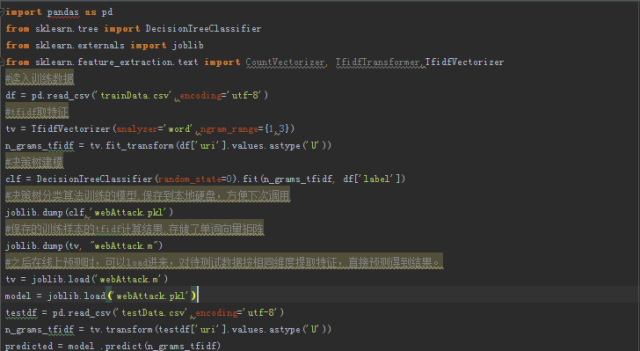
此時,如果用已知標簽的驗證數據來評估我們的機器學習模型,我們推薦使用混淆矩陣作為評判標準,
#expected是標簽值,predicted是模型預測的結果
print("Confusionmatrix:\n%s"%metrics.confusion_matrix(expected,predicted))
輸出:
Confusion matrix:
[[ 1 0]
[ 4226 65867]]
大概解釋下混淆矩陣的結果:
| 真實情況 | 預測結果 | |
| 正例 | 反例 | |
| 正例 | TP,實際為正預測為正 | FN,實際為正預測為負 |
| 反例 | FP,實際為負預測為正 | TN,實際為負預測為負 |
由于此次我們的驗證數據集只有1條正常流量,所以我們看到FN為0 。我們更關心惡意流量被識別為正常流量的情況(漏報),我們看到這里漏報達到4226條,如果要計算漏報率,可以使用以下指標
print("Classificationreportforclassifier%s:\n%s\n"%(model,metrics.classification_report(expected,predicted)))
輸出:

召回率:Recall=TP/ (TP+FN)
準確率:Accuracy=(TP+TN)/ (TP+FP+TN+FN)
精準率:Precision=TP/ (TP+FP) ,
f1-score是召回率和準確率的調和平均數,并假設兩者一樣重要,計算公式:
f1-score=(2*Recall*Accuracy) / (Recall+Accuracy)
很明顯,我們這里的召回率0.94,代表我們的漏報率為6%,勉強屬于可接納的范圍內,還需持續優化。
線上應用和持續優化
線上應用,也就是將建好的模型嵌入到我們已有的nile框架中去,且需要設置好一鍵開關機器學習引擎,還有正則的一鍵開關,對于某些經常漏報的就直接先進正則引擎了,當然正則個數需要約束,不然又走回了正則檢測的死胡同了。后面我們就需要持續的觀察輸出,不斷的自動化補充規則,自動訓練新的模型。
參考前面提到的nile框架,目前遇到的最大的問題:我們如何面對遺漏了的攻擊流量,是否可接受這部分風險。目前還沒有想到一個好的方案。
歸根結底,我們還是認為特征提取是對模型準確率影響最大的因素,特征工程是一個臟活累活,花在上面的時間遠遠大于其他步驟,對工程師的要求更高,往往要求大量的專業知識經驗和敏銳的直覺,外加一些“靈感”。可以這樣說,好特征即使配上較差的算法或參數,依然可以獲得較好的結果。因為好的特征就意味著離現實問題的本質更加接近。另外就缺一個勤勤懇懇洗數據的工程師了。
未來展望
目前我們在機器學習方面的信息安全應用還存在以下可以更進一步的地方:
對非標準的json,xml數據包的判斷,因為這些數據中內容長,標點多,且有的是非標準結構,例如json結構體無法順利拆開,造成預測結果有誤差。
加入多分類,可以識別出不同web攻擊的類型,從而更好的和hulk結合。
在其他方面的應用,例如隨機域名檢測,ugc惡意評論,色情圖片識別等等,目前這方面我們也已經陸續展開了實踐。
將spark mllib庫替換為spark ml庫。
最后一句話總結,路才剛剛開始。
-
Web
+關注
關注
2文章
1269瀏覽量
69727 -
安防
+關注
關注
9文章
2260瀏覽量
62880 -
機器學習
+關注
關注
66文章
8438瀏覽量
133078
原文標題:機器學習在web攻擊檢測中的應用實踐
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論