 電子發(fā)燒友App
電子發(fā)燒友App


醫(yī)學(xué)圖像是臨床診斷主要依據(jù)之一,對(duì)醫(yī)學(xué)圖像的處理分析具有十分重要的理論和臨床價(jià)值。本文詳細(xì)分析了醫(yī)學(xué)圖像處理面臨的挑戰(zhàn),闡述了醫(yī)學(xué)圖像傳統(tǒng)處理流程以及GPU的作用,總結(jié)了人工智能醫(yī)學(xué)影像發(fā)展現(xiàn)狀、問(wèn)題以及GPU算力加持下深度學(xué)習(xí)醫(yī)學(xué)圖像處理算法的演進(jìn)趨勢(shì)。
醫(yī)學(xué)圖像處理面臨的挑戰(zhàn)
自倫琴1895年開(kāi)創(chuàng)X射線人體成像先河以來(lái),計(jì)算機(jī)斷層掃描 (CT) 、磁共振成像 (MRI) 、正電子發(fā)射斷層成像 (PET) 等醫(yī)學(xué)影像技術(shù)已然成為臨床醫(yī)生最直接、最常用的方法手段,它在整個(gè)臨床應(yīng)用(包括疾病診斷、手術(shù)治療、預(yù)后評(píng)估等)中起著至關(guān)重要的作用。醫(yī)學(xué)圖像的處理分析是醫(yī)學(xué)影像技術(shù)的核心部分,包括圖像重建、增強(qiáng)、配準(zhǔn)、融合、跟蹤、分割、識(shí)別、可視化等技術(shù),不僅可以輔助醫(yī)生閱片分析、自動(dòng)化診療過(guò)程,還是手術(shù)機(jī)器人等圖像引導(dǎo)介入 (Image Guided Interventions,IGI) 手術(shù)的關(guān)鍵技術(shù)。
然而,醫(yī)學(xué)圖像處理面臨諸多挑戰(zhàn)。
1、隨著各類醫(yī)學(xué)影像設(shè)備的迅速發(fā)展和普及,醫(yī)學(xué)圖像數(shù)據(jù)正以前所未有的速度增加。據(jù)統(tǒng)計(jì),美國(guó)的醫(yī)學(xué)圖像數(shù)據(jù)年增長(zhǎng)率為63.1%,我國(guó)圖像數(shù)據(jù)年增長(zhǎng)率也在30%左右。截止2020年,全球醫(yī)學(xué)圖像數(shù)據(jù)量已經(jīng)達(dá)到了驚人的40萬(wàn)億GB[1]。
2、如圖1所示,不同類型的成像設(shè)備,由于成像原理不同,其生成的不同模態(tài)圖像在相同解剖結(jié)構(gòu)位置上并不存在簡(jiǎn)單的線性對(duì)應(yīng)關(guān)系。在臨床應(yīng)用中,醫(yī)生往往需要結(jié)合多種模態(tài)圖像進(jìn)行融合分析、互為補(bǔ)充,以改善臨床診斷、病情監(jiān)測(cè)、外科手術(shù)引導(dǎo)、療效評(píng)估的水平。
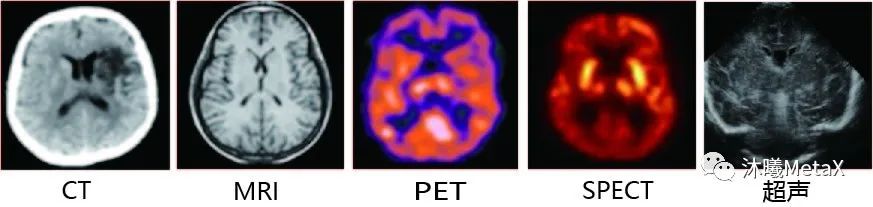
圖1:不同模態(tài)的腦部圖像
來(lái)源:F. E.-Z. A. El-Gamal, M. Elmogy, A. Atwan. Current trends in medical image registration and fusion. Egyptian Informatics Journal, 2016
3、醫(yī)學(xué)圖像個(gè)體差異較大,即使是同一臺(tái)設(shè)備同一病人,由于成像系統(tǒng)的缺陷,不同成像參數(shù)條件和患者呼吸運(yùn)動(dòng)等多種原因,也容易造成醫(yī)學(xué)圖像出現(xiàn)不同程度的偽影和噪聲。
4、醫(yī)學(xué)圖像的解釋并沒(méi)有完全統(tǒng)一的標(biāo)準(zhǔn)。由于經(jīng)驗(yàn)和環(huán)境條件不一樣,即使是同一醫(yī)生在不同時(shí)間段對(duì)同一張圖片都有可能出現(xiàn)不同的解釋和描述。
5、臨床診療對(duì)時(shí)間具有一定敏感性。對(duì)于一些實(shí)時(shí)性要求較高的臨床應(yīng)用,如手術(shù)導(dǎo)航,圖像處理速度要求至少達(dá)到 25-30幀/秒。
醫(yī)學(xué)圖像的這些特點(diǎn),對(duì)醫(yī)學(xué)圖像處理的算法和算力都提出了較高的要求。近年來(lái),隨著人工智能 (artificial intelligence,AI) 核心——深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)處理領(lǐng)域的巨大成功,AI技術(shù)通過(guò)替代或增強(qiáng)醫(yī)學(xué)圖像處理的部分或整體流程,可以顯著提高醫(yī)學(xué)圖像分析的精度和效率,提升健康與診療的效益及價(jià)值。GPU具有高效的并行計(jì)算能力,不僅適合計(jì)算密集型傳統(tǒng)圖像處理任務(wù),而且是人工智能模型訓(xùn)練、預(yù)測(cè)的關(guān)鍵硬件。接下來(lái),我們將分別對(duì)GPU的作用進(jìn)行闡述。
GPU提速醫(yī)學(xué)圖像處理全流程
醫(yī)療成像設(shè)備產(chǎn)生的醫(yī)學(xué)圖像具有多種維度,包括2D、3D、4D圖像,以及2D視頻圖像(內(nèi)窺鏡或顯微鏡視頻)。隨著圖像維度和算法復(fù)雜度的提高,醫(yī)學(xué)圖像處理的計(jì)算量也在大幅增加。對(duì)于大多數(shù)醫(yī)學(xué)圖像處理算法,圖像像素可以作為線程進(jìn)行獨(dú)立處理,具有數(shù)據(jù)并行計(jì)算的特點(diǎn),這是GPU并行加速的基礎(chǔ)。GPU具有高并行、多線程、多流式處理器、高內(nèi)存帶寬的特點(diǎn),可以實(shí)現(xiàn)醫(yī)學(xué)圖像處理全流程的高性能加速計(jì)算。圖2給出了醫(yī)學(xué)圖像處理的基本流程,下文將分別予以介紹。
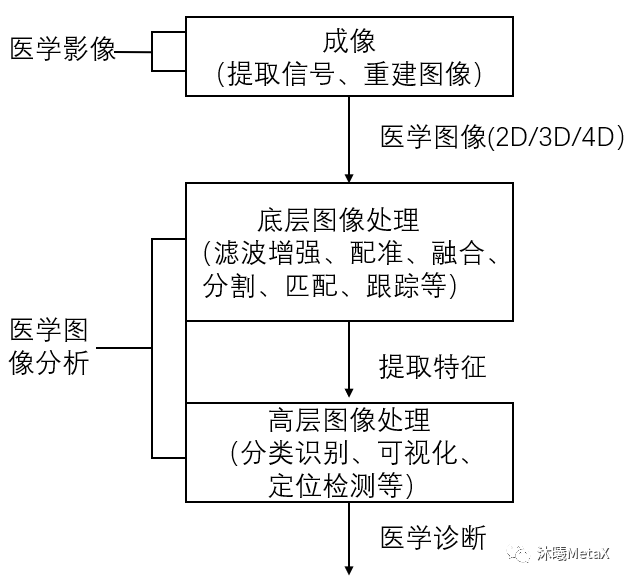
圖2:醫(yī)學(xué)圖像處理基本流程
圖像重建
圖像重建是指利用傳感器或能量源測(cè)量人體數(shù)據(jù),經(jīng)重建算法獲得人體三維結(jié)構(gòu)或功能信息。圖像重建是醫(yī)學(xué)圖像處理中較為耗時(shí)的過(guò)程,為了緩解計(jì)算壓力,研究者過(guò)去常使用較為簡(jiǎn)單的成像模型進(jìn)行直接解析。例如,在CT重建中,F(xiàn)BP (Filtered back projection,濾波反投影) 是解析法中較為常見(jiàn)的算法。在FBP中,將投影數(shù)據(jù)進(jìn)行FFT濾波處理后,利用系統(tǒng)權(quán)重矩陣和投影數(shù)據(jù)的相乘沿投影方向重建三維圖像。CT投影重建模型如圖3所示,探測(cè)器接收的信號(hào)為X射線管源穿過(guò)人體的X射線投影數(shù)據(jù)。為獲得CT完整斷層圖像,需要X射線沿人體中心進(jìn)行至少180°的連續(xù)旋轉(zhuǎn)。
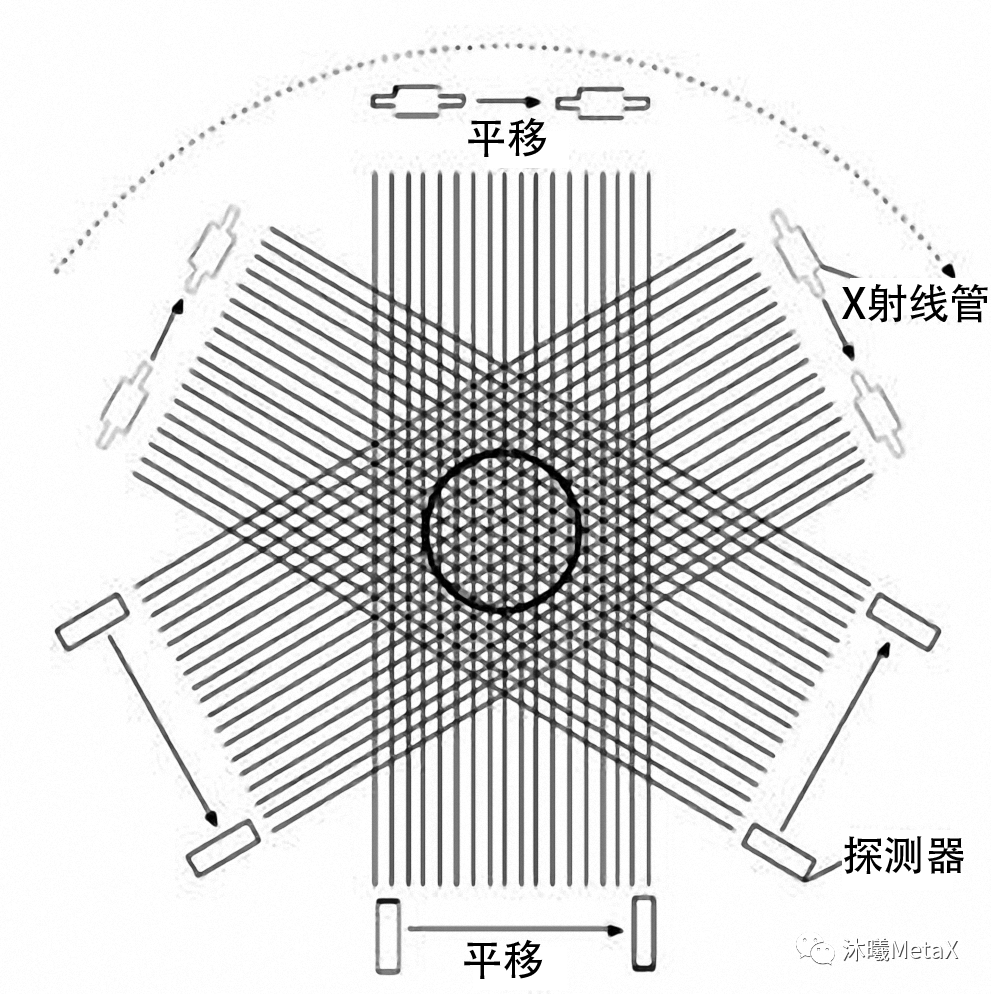
圖3:CT投影重建模型
盡管解析算法簡(jiǎn)單、重建速度快,但由于未引入真實(shí)的成像過(guò)程,如未考慮噪聲等,其成像質(zhì)量較差,且要求較高信噪比的測(cè)量數(shù)據(jù),但這往往受限于放射劑量或系統(tǒng)約束。近年來(lái),迭代法被廣泛用于圖像重建過(guò)程中,可以顯著減少放射劑量、降低噪聲、提高成像質(zhì)量。表1總結(jié)了幾種常用醫(yī)學(xué)成像技術(shù)的重建原理及相關(guān)技術(shù)特點(diǎn)。
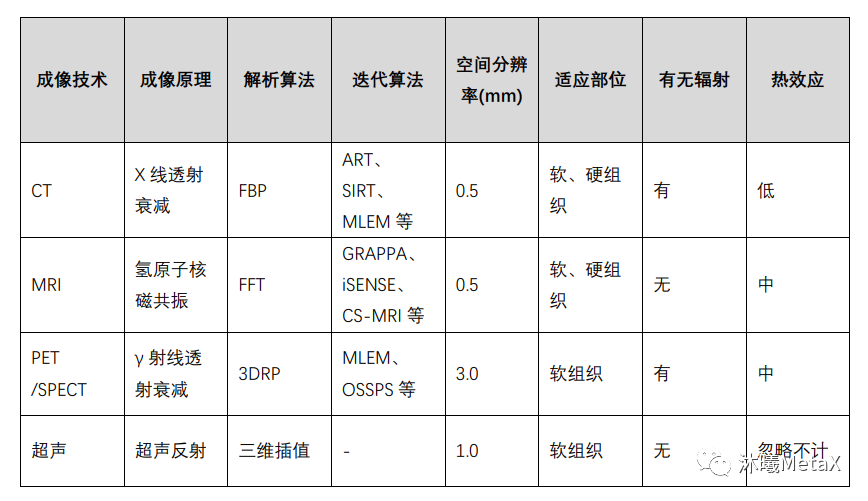
表1:幾種常用醫(yī)學(xué)成像技術(shù)對(duì)比
迭代重建算法的基本原理是估計(jì)初始三維圖像,對(duì)其進(jìn)行前向成像模擬,并與實(shí)際測(cè)量數(shù)據(jù)進(jìn)行比較,根據(jù)誤差結(jié)果校正三維圖像估計(jì),重復(fù)該過(guò)程直至收斂。這一過(guò)程中,需要大量的數(shù)據(jù)計(jì)算。以往,圖像重建常使用ASIC (Application Specific Integrated Circuit,專用集成電路) 、FPGA (Field Programmable Gate Array,現(xiàn)場(chǎng)可編程門(mén)陣列) 、DSP (Digital Signal Processing,數(shù)字信號(hào)處理芯片) 等芯片進(jìn)行加速。相比這些芯片,GPU可以提供更好的編程靈活性和更合理的開(kāi)發(fā)成本性能比。目前,在圖像重建領(lǐng)域有大量使用GPU加速的開(kāi)源軟件和醫(yī)療設(shè)備廠商商用軟件。通過(guò)對(duì)重建過(guò)程任務(wù)并行化、內(nèi)存合并優(yōu)化以及減少線程發(fā)散和競(jìng)爭(zhēng)等手段,GPU的加速性能可以顯著提高。表2給出了MRI重建CS迭代方法的各模塊的GPU加速比,在GPU的加持下,其總加速比可以達(dá)到53.9倍[2]。
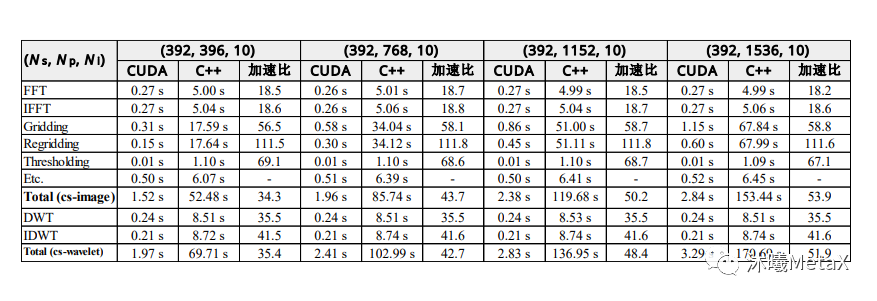
表2:CS-MRI重建中兩種方法的GPU加速比較。
表中給出了執(zhí)行單次迭代的各模塊平均時(shí)間和加速比。
其中,Ns為采樣數(shù),Np為投影數(shù)量,Ni為軌跡數(shù)。
來(lái)源:S. Nam, M. Ak?akaya, T. Basha, C. Stehning, W. J. Manning, V. Tarokh, et al. Compressed sensing reconstruction for whole‐heart imaging with 3D radial trajectories: a graphics processing unit implementation. Magnetic resonance in medicine, 2013, 69(1): 91-102
濾波增強(qiáng)
原始醫(yī)學(xué)圖像受成像設(shè)備和獲取條件等多種因素的影響,易受到噪聲的污染,會(huì)出現(xiàn)圖像質(zhì)量的退化或畸變。對(duì)醫(yī)學(xué)圖像進(jìn)行濾波增強(qiáng),可以抑制噪聲、減少失真、增強(qiáng)圖像信息,以便后續(xù)圖像處理分析。傳統(tǒng)的圖像濾波增強(qiáng)技術(shù)分為空間域和頻域兩種,兩者都可以用來(lái)消除圖像噪聲,并且同時(shí)達(dá)到增強(qiáng)圖像特征的目的。常用中值濾波、高斯濾波、擴(kuò)散濾波和雙邊濾波等方法進(jìn)行處理。這些濾波算法等價(jià)于圖像域的可分解卷積運(yùn)算,或者傅里葉頻域空間的乘積運(yùn)算,因此極其適合GPU并行加速計(jì)算。表3給出了對(duì)三維圖像(512x512x128)進(jìn)行不同參數(shù)非局部均值去噪加速效果比較,其GPU加速比平均可以達(dá)到30多倍[3]。
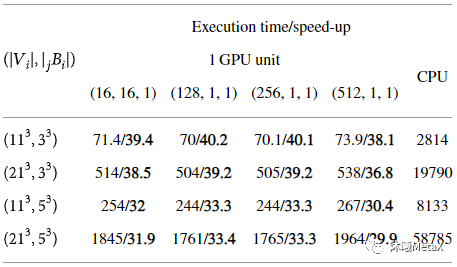
表3:不同參數(shù)三維非局部均值去噪加速效果比較
(執(zhí)行時(shí)間(s)/加速比)
來(lái)源:S. Cuomo, P. De Michele, F. Piccialli. 3D Data Denoising via Nonlocal Means Filter by Using Parallel GPU Strategies. Computational and Mathematical Methods in Medicine, 2014
圖像配準(zhǔn)
醫(yī)學(xué)圖像配準(zhǔn)是指對(duì)同一人的同一解剖部位,利用某些意義不同的成像手段形成的意義不同的兩幅影像,尋求一種(或一系列)空間變換,使這兩幅醫(yī)學(xué)影像的解剖結(jié)構(gòu)對(duì)應(yīng)點(diǎn)達(dá)到空間位置上的盡可能一致。這里的一致是指人體上同一解剖點(diǎn)或者至少是所有具有診斷意義的點(diǎn)以及手術(shù)感興趣點(diǎn)都達(dá)到匹配。醫(yī)學(xué)圖像配準(zhǔn)是圖像分割、圖像融合等后續(xù)圖像處理的基礎(chǔ)。
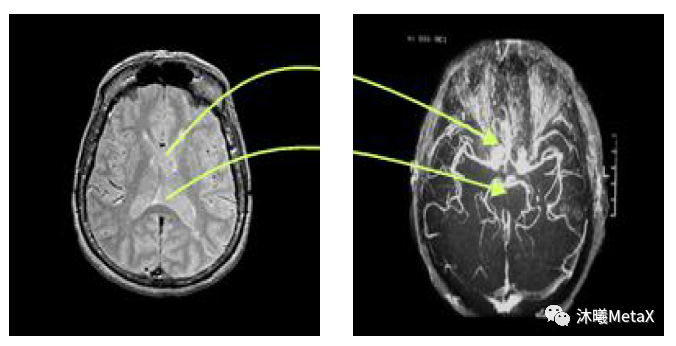
圖4:大腦 MRI和 DSA圖像配準(zhǔn)示意圖
如圖5所示,圖像配準(zhǔn)過(guò)程中,作為配準(zhǔn)目標(biāo)而不發(fā)生變化的待配準(zhǔn)圖像稱為參考圖像R,另一幅要進(jìn)行空間變換的待配準(zhǔn)圖像稱為浮動(dòng)圖像M,整個(gè)配準(zhǔn)過(guò)程可以看作是對(duì)浮動(dòng)圖像M進(jìn)行有限次幾何變換T后,使其變換后圖像同參考圖像R相似度無(wú)限接近的過(guò)程。
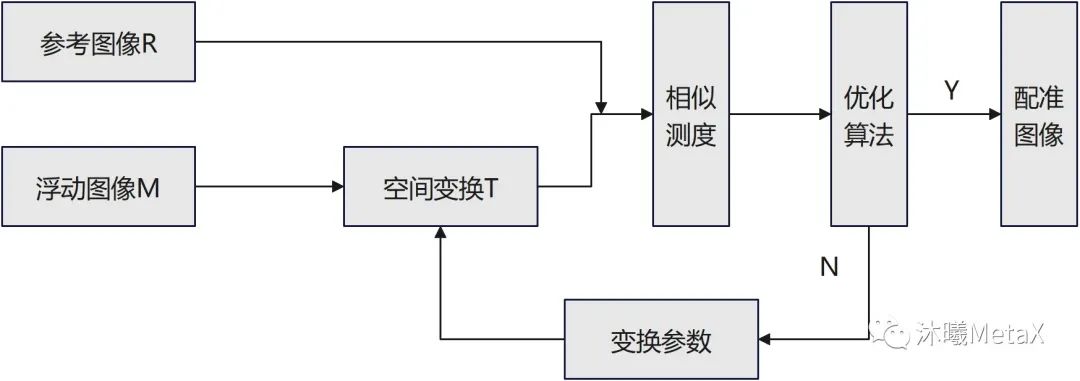
圖5:醫(yī)學(xué)圖像配準(zhǔn)框架示意圖
醫(yī)學(xué)圖像配準(zhǔn)方法的核心包括三個(gè)部分:空間變換、相似測(cè)度、優(yōu)化算法。空間變換主要涉及像素空間的矩陣和插值運(yùn)算,GPU對(duì)矩陣和插值運(yùn)算有內(nèi)置加速設(shè)置;相似性測(cè)度則是利用圖像灰度或特征信息,量化圖像間的匹配相似程度,利用并行、合并算法, 可以實(shí)現(xiàn)GPU的加速;而優(yōu)化算法主要為順序過(guò)程,較難實(shí)現(xiàn)相關(guān)GPU加速。表4給出了一種三維彈性配準(zhǔn)GPU加速情況,可以看出盡管優(yōu)化算法無(wú)法實(shí)現(xiàn)并行加速,GPU整體加速比仍能達(dá)到4.69倍[4]。
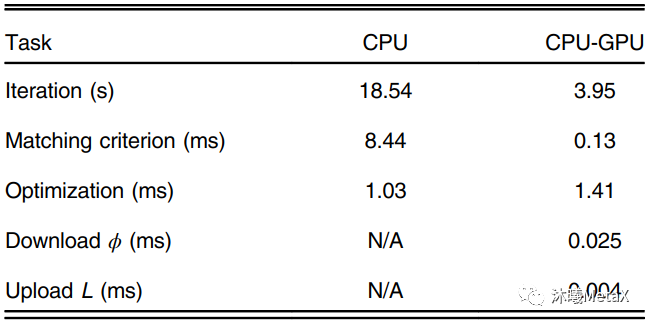
表4:一種三維彈性配準(zhǔn)的各模塊GPU加速情況
來(lái)源:S. Ekstr?m, M. Pilia, J. Kullberg, H. Ahlstr?m, R. Strand, F. J. J. o. M. I. Malmberg. Faster dense deformable image registration by utilizing both CPU and GPU. 2021
圖像匹配
圖像匹配和圖像配準(zhǔn)近似,目的是尋找與一幅圖相似的圖像,但無(wú)需對(duì)尋找到的圖像做空間矯正。根據(jù)匹配時(shí)利用的信息不同,可將匹配算法分為三個(gè)類別,分別是:基于特征描述符的匹配方法、基于空間位置信息的匹配方法和融合了特征信息和位置信息的匹配方法。根據(jù)得到的匹配數(shù)量的多少,又可將匹配算法分為稀疏匹配算法、準(zhǔn)稠密匹配算法和稠密匹配算法。圖像匹配在醫(yī)學(xué)圖像領(lǐng)域中被廣泛用于基于內(nèi)容的圖像檢索 (Content Based Image Retrieval,CBIR) ,通過(guò)從現(xiàn)有醫(yī)學(xué)圖像數(shù)據(jù)庫(kù)中快速查詢圖像相似的臨床醫(yī)學(xué)圖像,醫(yī)生可以參考病理相似病例的診斷方法以輔助其作出正確的臨床診斷。
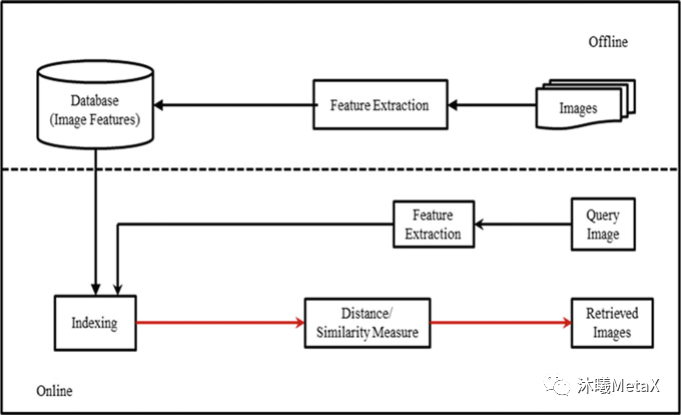
圖6:基于內(nèi)容的圖像檢索系統(tǒng)基本流程
來(lái)源:L. R. Nair, K. Subramaniam, G. K. D. Prasannavenkatesan. A Review on Multiple Approaches to Medical Image Retrieval System. in: Intelligent Computing in Engineering. Singapore, 2020
如圖6所示,CBIR過(guò)程通常分為特征提取、特征索引、相似性度量等過(guò)程。這些過(guò)程都可以利用GPU進(jìn)行并行加速。一項(xiàng)研究表明[5],利用GPU可以實(shí)現(xiàn)4~5倍的加速。
圖像融合
正如前文所述,不同類型的醫(yī)學(xué)影像設(shè)備為患者臨床診療提供了多層面、多角度、多節(jié)點(diǎn)的圖像數(shù)據(jù),不同模態(tài)的數(shù)據(jù)間既存在冗余信息,又充斥著大量的互補(bǔ)信息。多模態(tài)醫(yī)學(xué)圖像融合充分利用不同模態(tài)圖像的互補(bǔ)性和冗余性,對(duì)同一病灶部位不同模態(tài)的醫(yī)學(xué)影像進(jìn)行融合,可以得到比原圖像信息更豐富、更精準(zhǔn)的融合圖像。通常,多模態(tài)醫(yī)學(xué)圖像融合首先需要對(duì)不同模態(tài)的圖像進(jìn)行配準(zhǔn),使得同一解剖部位的像素位置在不同圖像下能夠一一對(duì)應(yīng),之后根據(jù)設(shè)定的策略融合各模態(tài)中的有用信息,生成質(zhì)量更好的圖像。如圖7所示,根據(jù)圖像數(shù)據(jù)處理層次的不同,圖像融合主要分為像素級(jí)融合、特征級(jí)融合和決策級(jí)融合。
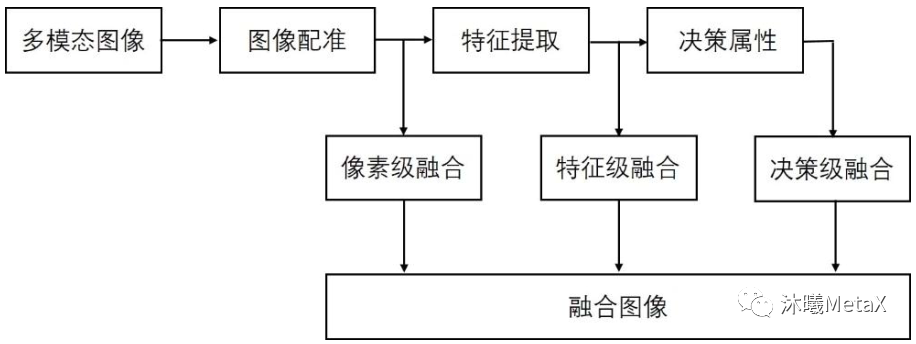
圖7:不同層次圖像融合系統(tǒng)示意圖
其中,像素級(jí)多尺度變換方法是目前圖像融合算法的主流,在圖像精確配準(zhǔn)前提下,對(duì)兩幅或多幅原圖像使用分解變換方法分別進(jìn)行分解,得到不同頻率層次的圖像,然后將兩幅圖像對(duì)應(yīng)的低頻系數(shù)和高頻系數(shù)分別進(jìn)行融合,獲得融合系數(shù),最后將融合后的系數(shù)進(jìn)行傅里葉逆變換,得到最終的融合圖像。利用GPU可以加速傅里葉變換等過(guò)程,從而實(shí)現(xiàn)近10倍的加速[6]。
圖像分割
圖像分割,是指將圖像分成若干不相互重疊的子區(qū)域,使得同一個(gè)子區(qū)域內(nèi)的像素特征具有一定的相似性、不同子區(qū)域之間像素特征呈現(xiàn)較為明顯的差異,常用于分割腦部區(qū)域、血管、器官、腫瘤、骨骼等,是許多基于醫(yī)學(xué)圖像的診斷、治療和分析應(yīng)用的重要基礎(chǔ)步驟。
常用的傳統(tǒng)圖像分割方法包括閾值、聚類、馬爾科夫隨機(jī)場(chǎng)、區(qū)域增長(zhǎng)、分裂合并、三維邊緣檢測(cè)、形態(tài)學(xué)、形變模型、水平集等方法。目前并沒(méi)有單一的方法能解決圖像分割的所有場(chǎng)景,全自動(dòng)的分割方法通常針對(duì)特定器官和場(chǎng)景,當(dāng)先驗(yàn)知識(shí)缺少時(shí),全自動(dòng)方法的效果會(huì)顯著下降。因此,半自動(dòng)的方法被廣泛使用,該方法需要用戶提供初值如輪廓、初始點(diǎn)信息等,并交互結(jié)果。圖8給出了常用醫(yī)學(xué)圖像處理軟件Slicer對(duì)胸部CT圖像進(jìn)行半自動(dòng)分割的標(biāo)注結(jié)果。GPU可以加速整個(gè)圖像分割和可視化過(guò)程,從而提高圖像分割的交互體驗(yàn),進(jìn)而實(shí)現(xiàn)更好的圖像分割效果。
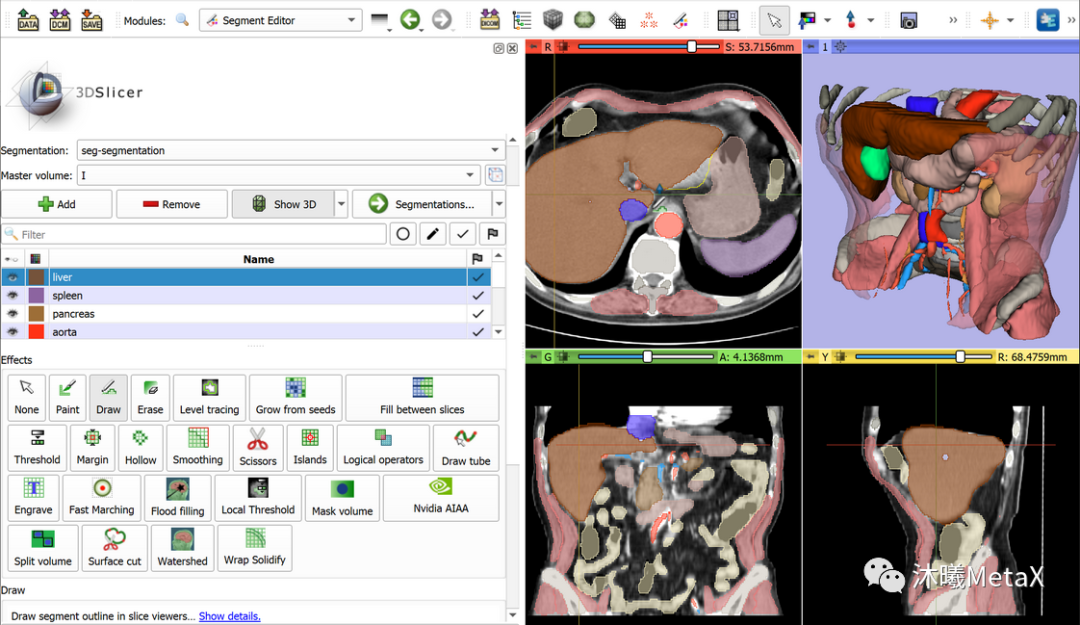
圖8:利用軟件Slicer對(duì)圖像進(jìn)行半自動(dòng)分割標(biāo)注
運(yùn)動(dòng)目標(biāo)檢測(cè)與跟蹤
運(yùn)動(dòng)目標(biāo)檢測(cè)與跟蹤通常分為兩個(gè)階段,首先是利用運(yùn)動(dòng)目標(biāo)檢測(cè)算法從視頻或圖像序列中把場(chǎng)景中的運(yùn)動(dòng)目標(biāo)從背景中區(qū)分并提取出來(lái),然后應(yīng)用目標(biāo)跟蹤算法對(duì)該目標(biāo)的運(yùn)動(dòng)特性及目標(biāo)外觀特征等參數(shù)進(jìn)行分析和預(yù)測(cè)。除廣泛用于智能視頻監(jiān)控領(lǐng)域之外,運(yùn)動(dòng)目標(biāo)檢測(cè)與跟蹤在醫(yī)學(xué)圖像領(lǐng)域主要用于內(nèi)窺鏡視頻中對(duì)微創(chuàng)手術(shù) (Minimally Invasive Surgery) 器械進(jìn)行檢測(cè)與跟蹤[7, 8]、時(shí)空細(xì)胞顯微鏡成像 (Spatial-Temporal Cell microscopy Imaging) 中對(duì)細(xì)胞運(yùn)動(dòng)、增殖的跟蹤分析[9]、心臟磁共振成像 (Cine MRI) 或心動(dòng)超聲 (echocardiography) 中對(duì)心臟運(yùn)動(dòng)跟蹤以檢測(cè)與量化心臟功能[10]以及放射治療4D-CT[11]中對(duì)腫瘤呼吸運(yùn)動(dòng)的跟蹤等。運(yùn)動(dòng)目標(biāo)檢測(cè)與跟蹤涉及大量2D或3D圖像序列的分析計(jì)算,極為耗時(shí),利用GPU并行加速可以實(shí)現(xiàn)較大加速比。圖9展示了時(shí)空細(xì)胞顯微鏡成像分析中不同跟蹤算法的單幀圖像計(jì)算時(shí)長(zhǎng)對(duì)比,可以看出隨著計(jì)算量的增加,經(jīng)過(guò)優(yōu)化的GPU并行算法可以實(shí)現(xiàn)近166倍的加速比[9]。
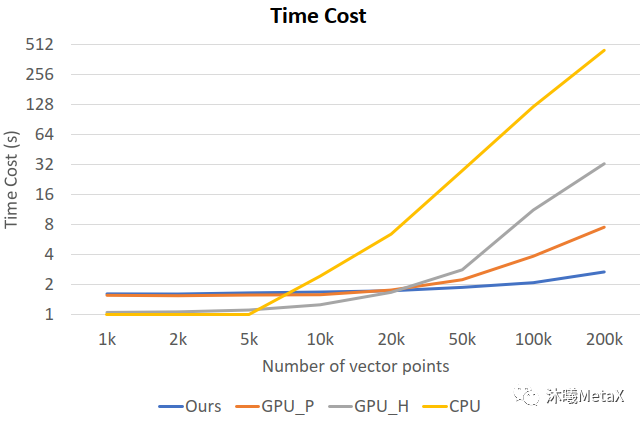
圖9:不同跟蹤算法的單幀圖像計(jì)算時(shí)長(zhǎng)。
橫坐標(biāo)為幀間圖像的向量點(diǎn)數(shù)目,
縱坐標(biāo)為單幀圖像耗時(shí);
GPU_H、CPU為傳統(tǒng)跟蹤算法的GPU、CPU版本,
GPU_P為并行張量加速算法,
Ours為文獻(xiàn)[9]中提到的經(jīng)優(yōu)化的GPU加速算法。
來(lái)源:M. Zhao, A. Jha, Q. Liu, B. A. Millis, A. Mahadevan-Jansen, L. Lu, et al. Faster Mean-shift: GPU-accelerated clustering for cosine embedding-based cell segmentation and tracking. 2021
圖像可視化
醫(yī)學(xué)圖像可視化是指利用醫(yī)學(xué)影像設(shè)備獲取的序列圖像信息,重建三維圖像模型,并將其轉(zhuǎn)換成圖形圖像在屏幕上顯示,為用戶提供具有真實(shí)感并進(jìn)行相互交互的三維醫(yī)學(xué)圖像。醫(yī)學(xué)圖像可視化廣泛應(yīng)用于臨床診斷、放射治療規(guī)劃、手術(shù)導(dǎo)航、醫(yī)學(xué)模擬仿真教學(xué)等方面,對(duì)臨床醫(yī)學(xué)具有很高的應(yīng)用價(jià)值與實(shí)踐意義。
根據(jù)繪制過(guò)程中數(shù)據(jù)描述方法的不同,醫(yī)學(xué)圖像可視化通常分為兩大類——面繪制和體繪制。面繪制是指對(duì)體表面重建,然后用傳統(tǒng)圖形學(xué)技術(shù)實(shí)現(xiàn)表面繪制。面繪制可以有效地繪制出物體表面,但缺乏對(duì)物體內(nèi)部信息的表達(dá)。由于面繪制技術(shù)的缺點(diǎn)和局限,體繪制(體渲染)技術(shù)應(yīng)用更為廣泛,其基本原理是利用光學(xué)模型模擬光線穿越半透明物質(zhì)時(shí)的能量累積變化。具體而言,首先對(duì)每個(gè)體素賦以不透明度 (a) 和顏色值 (R、G、B) ;再根據(jù)各個(gè)體素所在點(diǎn)的梯度以及光照模型計(jì)算相應(yīng)體素的光照強(qiáng)度;然后根據(jù)光照模型,將射線上投射到圖像平面中同一個(gè)像素點(diǎn)的各個(gè)體素的不透明度和顏色值組合在一起,生成最終結(jié)果圖像。
圖像可視化計(jì)算量極大,對(duì)時(shí)間較為敏感,利用GPU的并行加速和紋理內(nèi)存可以提高渲染速度。近年來(lái)隨著虛擬現(xiàn)實(shí) (Virtual Reality,VR) 技術(shù)在醫(yī)學(xué)圖像領(lǐng)域的興起,圖像可視化要求至少60幀每秒的速度和1024的高分辨率,這對(duì)GPU的內(nèi)存和計(jì)算速度都提出了更高的要求。圖10展示了利用VR對(duì)三維醫(yī)學(xué)圖像進(jìn)行操作觀察的示例[12]。
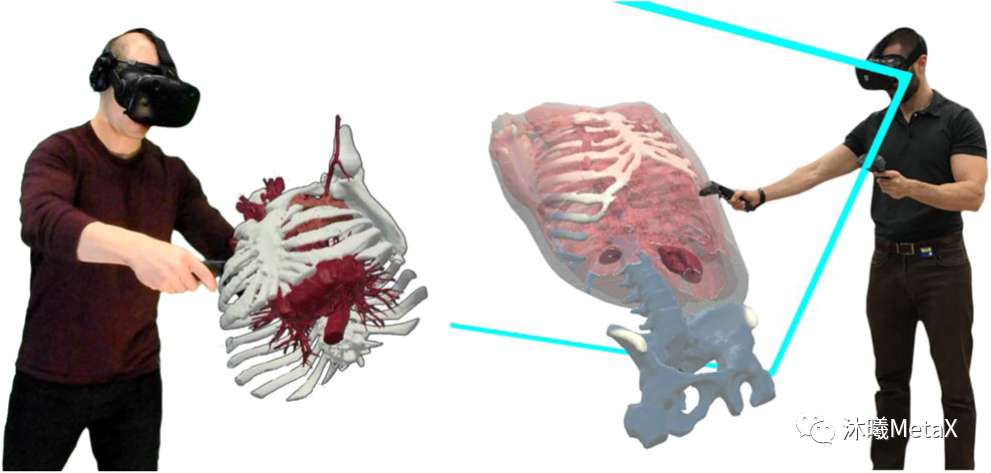
圖10:醫(yī)學(xué)圖像VR操作示例
來(lái)源:J. Sutherland, J. Belec, A. Sheikh, L. Chepelev, W. Althobaity, B. J. Chow, et al. Applying modern virtual and augmented reality technologies to medical images and models. Journal of digital imaging, 2019
其他技術(shù)
醫(yī)學(xué)圖像處理還包括圖像分類與識(shí)別、目標(biāo)定位與檢測(cè)等高層圖像處理技術(shù)。其中,圖像分類與識(shí)別,用于輔助診斷圖像是否有病灶,并對(duì)病灶進(jìn)行量化分級(jí);圖像目標(biāo)定位用于識(shí)別圖像特定目標(biāo),并給出具體物理位置;圖像目標(biāo)檢測(cè)則需要把圖像中所有目標(biāo)識(shí)別出來(lái),并確定其物理位置和類別。
這些處理技術(shù)傳統(tǒng)上通常需要經(jīng)過(guò)圖像預(yù)處理、圖像分割、特征提取、特征選擇、分類器訓(xùn)練等過(guò)程。傳統(tǒng)特征提取技術(shù)包括紋理、邊緣等全局特征和SIFT (Scale-Invariant Feature Transfor,尺度不變特征變換) 、SURF (Speeded Up Robust Features,加速魯棒性特征) 等局部特征。由于醫(yī)學(xué)圖像的多樣性和復(fù)雜性,根據(jù)先驗(yàn)知識(shí)人工設(shè)計(jì)的特征往往只適合特定場(chǎng)景任務(wù)。傳統(tǒng)圖像分類、檢測(cè)等方法不僅耗時(shí)耗力,需要大量的參數(shù)調(diào)節(jié) (parameter hypertuning) 實(shí)驗(yàn),計(jì)算量大,借助GPU加速計(jì)算,可以加快特征提取計(jì)算和相關(guān)算法的調(diào)參訓(xùn)練過(guò)程。
GPU賦能臨床智能醫(yī)療
上文中,醫(yī)學(xué)圖像處理的各個(gè)任務(wù)流程都可以視作映射函數(shù)F的輸入輸出,即y=F(x)?。其中x為單個(gè)或多個(gè)圖像(數(shù)字信號(hào)),y為輸出,其定義取決于任務(wù)流程類型。例如,在圖像重建中,y為高分辨率重建圖像;在濾波增強(qiáng)中,y為圖像質(zhì)量增強(qiáng)圖像;在圖像配準(zhǔn)中,y為配準(zhǔn)參數(shù);在圖像分割中,y為圖像蒙版mask。
在眾多映射函數(shù)F的估計(jì)方法中,深度學(xué)習(xí) (Deep Learning,DL)方法利用深度神經(jīng)網(wǎng)絡(luò) (Deep Neural Network,DNN) 的多層非線性變換能實(shí)現(xiàn)映射函數(shù)F的無(wú)限逼近、表征輸入數(shù)據(jù)分布,具有強(qiáng)大的自動(dòng)特征提取和復(fù)雜模型構(gòu)建能力,在醫(yī)學(xué)圖像處理領(lǐng)域應(yīng)用十分廣泛。其中,GPU是深度學(xué)習(xí)模型訓(xùn)練的算力保障。而一旦模型訓(xùn)練完成,借助GPU的高效前向運(yùn)算,在圖像重建、圖像識(shí)別與分類、圖像定位與檢測(cè)、圖像分割、圖像配準(zhǔn)和融合等方面,深度學(xué)習(xí)算法相比傳統(tǒng)算法可以更為準(zhǔn)確、高效地完成圖像處理任務(wù),輔助醫(yī)生診斷治療和預(yù)后。圖11總結(jié)了深度學(xué)習(xí)在醫(yī)學(xué)圖像處理領(lǐng)域不同層次的分類。
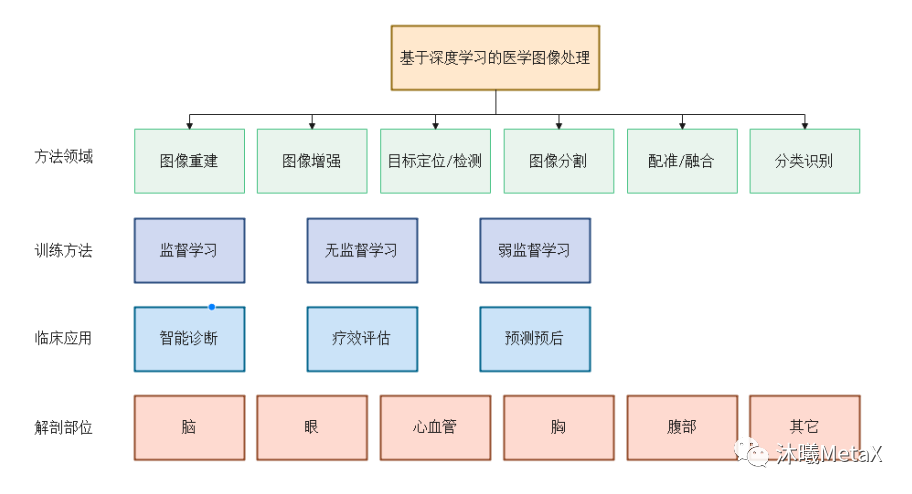
圖11:基于深度學(xué)習(xí)的醫(yī)學(xué)圖像處理分類
深度學(xué)習(xí)在醫(yī)學(xué)圖像領(lǐng)域發(fā)展十分迅速,產(chǎn)生了許多性能優(yōu)異的臨床應(yīng)用。例如,研究人員利用10萬(wàn)多幅惡性黑色素瘤(最致命的皮膚癌)和良性痣的圖像訓(xùn)練了卷積神經(jīng)網(wǎng)絡(luò)(CNN)來(lái)識(shí)別皮膚癌,表現(xiàn)優(yōu)于有經(jīng)驗(yàn)的皮膚科醫(yī)生,其漏診率和誤診率都更低[13]。國(guó)內(nèi)聯(lián)影企業(yè)利用bi-c-GAN模型,從超低劑量的PET/MRI數(shù)據(jù)重建出高分辨率PET圖像[14]。2020年COVID-19爆發(fā)早期,由于檢測(cè)試劑的短缺,歐洲研究人員開(kāi)發(fā)了CORADS-AI系統(tǒng)[15],利用CT圖像篩查和評(píng)價(jià)COVID-19的感染情況,可以近實(shí)時(shí)(<2 s)得出結(jié)果。如圖12所示,第一行為胸部CT圖,第二行為利用CNN模型分割的肺結(jié)節(jié)解剖圖,第三行為利用3D U-Net模型分割的具有毛狀玻璃樣病變的肺部區(qū)域,最下圖為病變區(qū)域在正常結(jié)節(jié)部位的計(jì)算比例,左下圖為基于感染比例得出的COVID-19感染分級(jí)和概率。
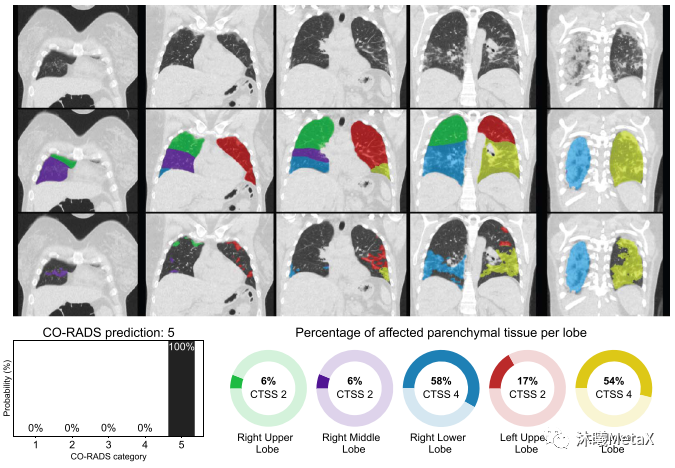
圖12:CORADS-AI系統(tǒng)篩查COVID-19的結(jié)果示意圖
來(lái)源:S. K. Zhou, H. Greenspan, C. Davatzikos, J. S. Duncan, B. Van Ginneken, A. Madabhushi, et al. A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises. Proceedings of the IEEE, 2021
雖然深度學(xué)習(xí)在醫(yī)學(xué)圖像處理領(lǐng)域取得了高速的發(fā)展,但仍存在很多挑戰(zhàn)和限制。除注冊(cè)審批、市場(chǎng)準(zhǔn)入等政策法規(guī)方面的挑戰(zhàn)外,最大的挑戰(zhàn)來(lái)自影像數(shù)據(jù)質(zhì)量問(wèn)題。醫(yī)學(xué)影像數(shù)據(jù)的數(shù)量和質(zhì)量決定了Al模型學(xué)習(xí)的結(jié)果。盡管醫(yī)學(xué)圖像數(shù)據(jù)總量巨大,但針對(duì)不同病種的影像數(shù)據(jù)量和質(zhì)量參差不齊,有些病種的訓(xùn)練數(shù)據(jù)缺乏;健康大數(shù)據(jù)孤島問(wèn)題(即醫(yī)院間醫(yī)療數(shù)據(jù)不能共享和聯(lián)通問(wèn)題)、安全隱私問(wèn)題仍然存在,雖然有所緩解,但仍未達(dá)到深度學(xué)習(xí)的要求。醫(yī)療影像數(shù)據(jù)針對(duì)細(xì)分場(chǎng)景的數(shù)據(jù)量和質(zhì)量仍無(wú)法滿足算法模型的訓(xùn)練需求。影像數(shù)據(jù)處理結(jié)果需要大量影像科專業(yè)醫(yī)師去標(biāo)注,成本、耗時(shí)巨大,而醫(yī)師的經(jīng)驗(yàn)水平、學(xué)習(xí)數(shù)據(jù)的質(zhì)量和典型性都將影響數(shù)據(jù)的標(biāo)注質(zhì)量。針對(duì)這一問(wèn)題,需要建立完善的醫(yī)學(xué)數(shù)據(jù)共享和隱私學(xué)習(xí)平臺(tái),利用大數(shù)據(jù)技術(shù)從海量數(shù)據(jù)中篩選收集研究所需影像數(shù)據(jù),并借助自動(dòng)化技術(shù)輔助醫(yī)師標(biāo)注,其涉及的大量運(yùn)算需要GPU進(jìn)行算力支持。而針對(duì)小樣本數(shù)據(jù)集,可以通過(guò)數(shù)據(jù)增強(qiáng)、遷移學(xué)習(xí) (Transfer Learning) 、生成對(duì)抗網(wǎng)絡(luò) (Generative Adversarial Network,GAN) 、域適應(yīng) (Domain Adaptation) 、自監(jiān)督學(xué)習(xí) (Self-supervised Learning) 、弱監(jiān)督學(xué)習(xí) (Weakly Supervised Learning) 等方法在一定程度上緩解訓(xùn)練樣本不足的問(wèn)題。
目前深度學(xué)習(xí)算法普遍存在魯棒性和泛化性不足的問(wèn)題,其研發(fā)的模型很有可能僅對(duì)訓(xùn)練數(shù)據(jù)表現(xiàn)良好。而由于成像角度、成像噪聲、重建算法等因素的影響造成測(cè)試數(shù)據(jù)集和訓(xùn)練數(shù)據(jù)集具有不同的特點(diǎn),訓(xùn)練模型對(duì)這類數(shù)據(jù)預(yù)測(cè)完全失效。針對(duì)該問(wèn)題,除擴(kuò)大訓(xùn)練數(shù)據(jù)的代表性外,還可以探索模型結(jié)構(gòu),提高模型深度,引入對(duì)抗學(xué)習(xí)、注意力、多任務(wù)等機(jī)制,以提升模型泛化能力。這些復(fù)雜模型的訓(xùn)練和預(yù)測(cè)都依賴更高的GPU算力和顯存。
此外,深度學(xué)習(xí)模型是一個(gè)黑盒子,可解釋性較差。即使經(jīng)過(guò)訓(xùn)練的模型在測(cè)試數(shù)據(jù)集顯示出很高的準(zhǔn)確性,臨床醫(yī)生仍會(huì)對(duì)定期使用它們分析患者數(shù)據(jù)持謹(jǐn)慎懷疑態(tài)度。因此,模型的解釋和不確定性量化研究十分必要。深度學(xué)習(xí)模型的可解釋性主要包括模型結(jié)構(gòu)的可解釋性、特征權(quán)重的統(tǒng)計(jì)分析以及利用可解釋模型如決策樹(shù)近似模擬深度學(xué)習(xí)模型等[16]。而模型的不確定性量化,則是將多種不確定性來(lái)源和個(gè)體差異性融入模型預(yù)測(cè)中,給出模型預(yù)測(cè)準(zhǔn)確程度的置信區(qū)間。模型的解釋和不確定性量化,有助于增強(qiáng)深度學(xué)習(xí)結(jié)果的可信度,從而加速人工智能在醫(yī)學(xué)圖像臨床應(yīng)用的落地。
總結(jié)
醫(yī)學(xué)圖像在疾病診斷、手術(shù)治療、預(yù)后評(píng)估等臨床應(yīng)用中起著舉足輕重的作用,超過(guò)70%的診斷都依賴醫(yī)學(xué)圖像。對(duì)醫(yī)學(xué)圖像的處理分析,有助于促進(jìn)自動(dòng)化診療過(guò)程,是推動(dòng)精準(zhǔn)醫(yī)療和個(gè)性化醫(yī)療的重要工具。由于醫(yī)學(xué)圖像處理任務(wù)的復(fù)雜性和多樣性,以及圖像分辨率的提高,醫(yī)學(xué)圖像處理的算法復(fù)雜且運(yùn)算量巨大,利用GPU可以實(shí)現(xiàn)高性能并行計(jì)算。
近年來(lái),人工智能逐漸成為醫(yī)學(xué)影像發(fā)展的主流方向,相比傳統(tǒng)方法,可以提供更為準(zhǔn)確、高效的處理結(jié)果。但由于圖像數(shù)據(jù)質(zhì)量的問(wèn)題以及模型泛化性的要求,深度學(xué)習(xí)模型的結(jié)構(gòu)和訓(xùn)練也愈發(fā)復(fù)雜,這對(duì)GPU的算力和顯存都提出了更高的要求。
我們預(yù)計(jì),隨著成像設(shè)備的升級(jí)、醫(yī)學(xué)圖像標(biāo)記數(shù)據(jù)的不斷累積以及深度學(xué)習(xí)算法的不斷完善,人工智能和GPU的結(jié)合將在醫(yī)學(xué)圖像處理領(lǐng)域展現(xiàn)更為廣闊的未來(lái)。
[1] J. Wu. The Next Era: Flourish of National Health Care & Medicine with the World Leading Artificial Intelligence. Chinese Medical Sciences Journal, 2019, 34(2): 69-70
[2] S. Nam, M. Ak?akaya, T. Basha, C. Stehning, W. J. Manning, V. Tarokh, et al. Compressed sensing reconstruction for whole‐heart imaging with 3D radial trajectories: a graphics processing unit implementation. Magnetic resonance in medicine, 2013, 69(1): 91-102
[3] S. Cuomo, P. De Michele, F. Piccialli. 3D Data Denoising via Nonlocal Means Filter by Using Parallel GPU Strategies. Computational and Mathematical Methods in Medicine, 2014, 2014: 523862
[4] S. Ekstr?m, M. Pilia, J. Kullberg, H. Ahlstr?m, R. Strand, F. J. J. o. M. I. Malmberg. Faster dense deformable image registration by utilizing both CPU and GPU. 2021, 8(1): 014002
[5] S. A. Mahmoudi, M. A. Belarbi, E. W. Dadi, S. Mahmoudi, M. J. C. Benjelloun. Cloud-based image retrieval using GPU platforms. 2019, 8(2): 48
[6] 曹強(qiáng). 多模醫(yī)學(xué)圖像融合算法及其在放療中的應(yīng)用研究[博士]. 東南大學(xué), 2021
[7] Y. Jin, Y. Yu, C. Chen, Z. Zhao, P.-A. Heng, D. J. I. T. o. M. I. Stoyanov. Exploring Intra-and Inter-Video Relation for Surgical Semantic Scene Segmentation. 2022,
[8] D. Bouget, M. Allan, D. Stoyanov, P. Jannin. Vision-based and marker-less surgical tool detection and tracking: a review of the literature. Medical image analysis, 2017, 35: 633-654
[9] M. Zhao, A. Jha, Q. Liu, B. A. Millis, A. Mahadevan-Jansen, L. Lu, et al. Faster Mean-shift: GPU-accelerated clustering for cosine embedding-based cell segmentation and tracking. 2021, 71: 102048
[10] E. Ferdian, A. Suinesiaputra, K. Fung, N. Aung, E. Lukaschuk, A. Barutcu, et al. Fully Automated Myocardial Strain Estimation from Cardiovascular MRI–tagged Images Using a Deep Learning Framework in the UK Biobank. Radiology: Cardiothoracic Imaging, 2020, 2(1): e190032
[11] P. Jafari, S. Dempsey, D. A. Hoover, E. Karami, S. Gaede, A. Sadeghi-Naini, et al. In-vivo lung biomechanical modeling for effective tumor motion tracking in external beam radiation therapy. Computers in Biology and Medicine, 2021, 130: 104231
[12] J. Sutherland, J. Belec, A. Sheikh, L. Chepelev, W. Althobaity, B. J. Chow, et al. Applying modern virtual and augmented reality technologies to medical images and models. Journal of digital imaging, 2019, 32(1): 38-53
[13] H. A. Haenssle, C. Fink, R. Schneiderbauer, F. Toberer, T. Buhl, A. Blum, et al. Man against machine: diagnostic performance of a deep learning convolutional neural network for dermoscopic melanoma recognition in comparison to 58 dermatologists. Annals of oncology, 2018, 29(8): 1836-1842
[14] H. Sun, Y. Jiang, J. Yuan, H. Wang, D. Liang, W. Fan, et al. High-quality PET image synthesis from ultra-low-dose PET/MRI using bi-task deep learning. Quantitative Imaging in Medicine Surgery, 2022, 12(12): 5326-5342
[15] M. Prokop, W. Van Everdingen, T. van Rees Vellinga, H. Quarles van Ufford, L. St?ger, L. Beenen, et al. CO-RADS: a categorical CT assessment scheme for patients suspected of having COVID-19—definition and evaluation. Radiology, 2020, 296(2): E97-E104
[16] 化盈盈, 張岱墀, 葛仕明. 深度學(xué)習(xí)模型可解釋性的研究進(jìn)展. Journal of Cyber Security 信息安全學(xué)報(bào), 2020, 5(3)
編輯:黃飛














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論