 電子發(fā)燒友App
電子發(fā)燒友App


WeTest騰訊質量開放平臺(wetest.qq.com),是由騰訊游戲官方推出的一站式游戲測試平臺。本著開放共贏的精神將騰訊游戲沉淀十余年,歷經千款游戲錘煉的優(yōu)秀測試方案和工具,陸續(xù)開放給廣大游戲開發(fā)者,助力提高用戶的研發(fā)效率和產品品質。
你被爬蟲侵擾過么?當你看到“爬蟲”兩個字的時候,是不是已經有點血脈賁張的感覺了?千萬要忍耐,稍稍做點什么,就可以在名義上讓他們勝利,實際上讓他們受損失。
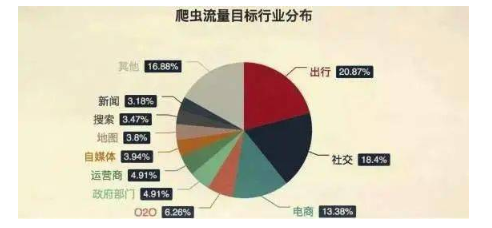
一、為什么要反爬蟲1. 爬蟲占總PV比例較高,這樣浪費錢(尤其是三月份爬蟲)
三月份爬蟲是個什么概念呢?每年的三月份我們會迎接一次爬蟲高峰期。
最初我們百思不得其解。直到有一次,四月份的時候,我們刪除了一個url,然后有個爬蟲不斷的爬取url,導致大量報錯,測試開始找我們麻煩。我們只好特意為這個爬蟲發(fā)布了一次站點,把刪除的url又恢復回去了。
但是當時我們的一個組員表示很不服,說,我們不能干掉爬蟲,也就罷了,還要專門為它發(fā)布,這實在是太沒面子了。于是出了個主意,說:url可以上,但是,絕對不給真實數(shù)據(jù)。
于是我們就把一個靜態(tài)文件發(fā)布上去了。報錯停止了,爬蟲沒有停止,也就是說對方并不知道東西都是假的。這個事情給了我們一個很大的啟示,也直接成了我們反爬蟲技術的核心:變更。
后來有個學生來申請實習。我們看了簡歷發(fā)現(xiàn)她爬過攜程。后來面試的時候確認了下,果然她就是四月份害我們發(fā)布的那個家伙。不過因為是個妹子,技術也不錯,后來就被我們招安了。現(xiàn)在已經快正式入職了。
后來我們一起討論的時候,她提到了,有大量的碩士在寫論文的時候會選擇爬取OTA數(shù)據(jù),并進行輿情分析。因為五月份交論文,所以嘛,大家都是讀過書的,你們懂的,前期各種DotA,LOL,到了三月份了,來不及了,趕緊抓數(shù)據(jù),四月份分析一下,五月份交論文。
就是這么個節(jié)奏。
2. 公司可免費查詢的資源被批量抓走,喪失競爭力,這樣少賺錢。
OTA的價格可以在非登錄狀態(tài)下直接被查詢,這個是底線。如果強制登陸,那么可以通過封殺賬號的方式讓對方付出代價,這也是很多網站的做法。但是我們不能強制對方登錄。那么如果沒有反爬蟲,對方就可以批量復制我們的信息,我們的競爭力就會大大減少。
競爭對手可以抓到我們的價格,時間長了用戶就會知道,只需要去競爭對手那里就可以了,沒必要來攜程。這對我們是不利的。
3. 爬蟲是否涉嫌違法?如果是的話,是否可以起訴要求賠償?這樣可以賺錢。
這個問題我特意咨詢了法務,最后發(fā)現(xiàn)這在國內還是個擦邊球,就是有可能可以起訴成功,也可能完全無效。所以還是需要用技術手段來做最后的保障。
二、反什么樣的爬蟲1. 十分低級的應屆畢業(yè)生
開頭我們提到的三月份爬蟲,就是一個十分明顯的例子。應屆畢業(yè)生的爬蟲通常簡單粗暴,根本不管服務器壓力,加上人數(shù)不可預測,很容易把站點弄掛。
順便說下,通過爬攜程來獲取offer這條路已經行不通了。因為我們都知道,第一個說漂亮女人像花的人,是天才。而第二個。。。你們懂的吧?
2. 十分低級的創(chuàng)業(yè)小公司
現(xiàn)在的創(chuàng)業(yè)公司越來越多,也不知道是被誰忽悠的然后大家創(chuàng)業(yè)了發(fā)現(xiàn)不知道干什么好,覺得大數(shù)據(jù)比較熱,就開始做大數(shù)據(jù)。
分析程序全寫差不多了,發(fā)現(xiàn)自己手頭沒有數(shù)據(jù)。
怎么辦?寫爬蟲爬埃于是就有了不計其數(shù)的小爬蟲,出于公司生死存亡的考慮,不斷爬取數(shù)據(jù)。
3. 不小心寫錯了沒人去停止的失控小爬蟲
攜程上的點評有的時候可能高達60%的訪問量是爬蟲。我們已經選擇直接封鎖了,它們依然孜孜不倦地爬齲
什么意思呢?就是說,他們根本爬不到任何數(shù)據(jù),除了httpcode是200以外,一切都是不對的,可是爬蟲依然不停止這個很可能就是一些托管在某些服務器上的小爬蟲,已經無人認領了,依然在辛勤地工作著。
4. 成型的商業(yè)對手
這個是最大的對手,他們有技術,有錢,要什么有什么,如果和你死磕,你就只能硬著頭皮和他死磕。
5. 抽風的搜索引擎
大家不要以為搜索引擎都是好人,他們也有抽風的時候,而且一抽風就會導致服務器性能下降,請求量跟網絡攻擊沒什么區(qū)別。
三。 什么是爬蟲和反爬蟲
因為反爬蟲暫時是個較新的領域,因此有些定義要自己下。我們內部定義是這樣的:
爬蟲:使用任何技術手段,批量獲取網站信息的一種方式。關鍵在于批量。
反爬蟲:使用任何技術手段,阻止別人批量獲取自己網站信息的一種方式。關鍵也在于批量。
誤傷:在反爬蟲的過程中,錯誤的將普通用戶識別為爬蟲。誤傷率高的反爬蟲策略,效果再好也不能用。
攔截:成功地阻止爬蟲訪問。這里會有攔截率的概念。通常來說,攔截率越高的反爬蟲策略,誤傷的可能性就越高。因此需要做個權衡。
資源:機器成本與人力成本的總和。
這里要切記,人力成本也是資源,而且比機器更重要。因為,根據(jù)摩爾定律,機器越來越便宜。而根據(jù)IT行業(yè)的發(fā)展趨勢,程序員工資越來越貴。因此,讓對方加班才是王道,機器成本并不是特別值錢。
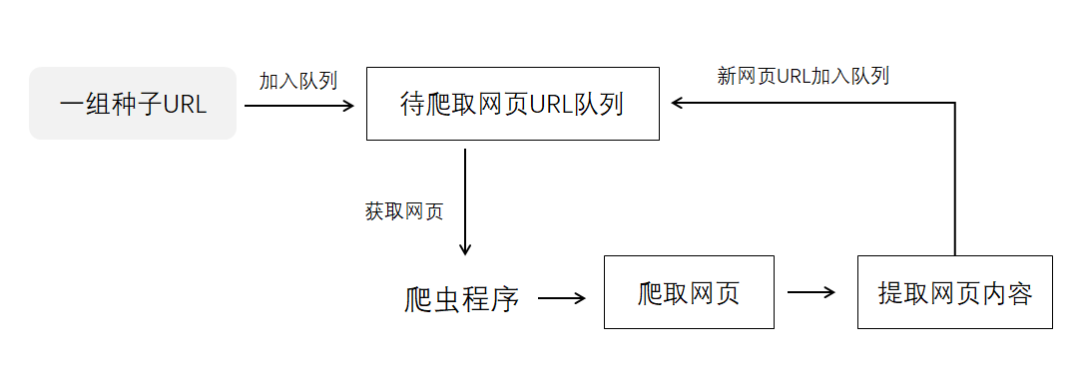
四、知己知彼:如何編寫簡單爬蟲
要想做反爬蟲,我們首先需要知道如何寫個簡單的爬蟲。
目前網絡上搜索到的爬蟲資料十分有限,通常都只是給一段python代碼。python是一門很好的語言,但是用來針對有反爬蟲措施的站點做爬蟲,真的不是最優(yōu)選擇。
更諷刺的是,通常搜到的python爬蟲代碼都會使用一個lynx的user-agent。你們應該怎么處理這個user-agent,就不用我來說了吧?
通常編寫爬蟲需要經過這么幾個過程:
分析頁面請求格式
創(chuàng)建合適的http請求
批量發(fā)送http請求,獲取數(shù)據(jù)
舉個例子,直接查看攜程生產url。在詳情頁點擊“確定”按鈕,會加載價格。假設價格是你想要的,那么抓出網絡請求之后,哪個請求才是你想要的結果呢?
答案出乎意料的簡單,你只需要用根據(jù)網絡傳輸數(shù)據(jù)量進行倒序排列即可。因為其他的迷惑性的url再多再復雜,開發(fā)人員也不會舍得加數(shù)據(jù)量給他。
五、知己知彼:如何編寫高級爬蟲
那么爬蟲進階應該如何做呢?通常所謂的進階有以下幾種:
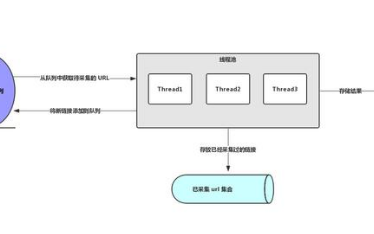
1. 分布式
通常會有一些教材告訴你,為了爬取效率,需要把爬蟲分布式部署到多臺機器上。這完全是騙人的。分布式唯一的作用是:防止對方封IP。封IP是終極手段,效果非常好,當然,誤傷起用戶也是非常爽的。
有些教程會說,模擬javascript,抓取動態(tài)網頁,是進階技巧。但是其實這只是個很簡單的功能。因為,如果對方沒有反爬蟲,你完全可以直接抓ajax本身,而無需關心js怎么處理的。如果對方有反爬蟲,那么javascript必然十分復雜,重點在于分析,而不僅僅是簡單的模擬。
換句話說:這應該是基本功。
3. PhantomJs
這個是一個極端的例子。這個東西本意是用來做自動測試的,結果因為效果很好,很多人拿來做爬蟲。但是這個東西有個硬傷,就是:效率。此外PhantomJs也是可以被抓到的,出于多方面原因,這里暫時不講。
六、不同級別爬蟲的優(yōu)缺點
越是低級的爬蟲,越容易被封鎖,但是性能好,成本低。越是高級的爬蟲,越難被封鎖,但是性能低,成本也越高。
當成本高到一定程度,我們就可以無需再對爬蟲進行封鎖。經濟學上有個詞叫邊際效應。付出成本高到一定程度,收益就不是很多了。
那么如果對雙方資源進行對比,我們就會發(fā)現(xiàn),無條件跟對方死磕,是不劃算的。應該有個黃金點,超過這個點,那就讓它爬好了。畢竟我們反爬蟲不是為了面子,而是為了商業(yè)因素。
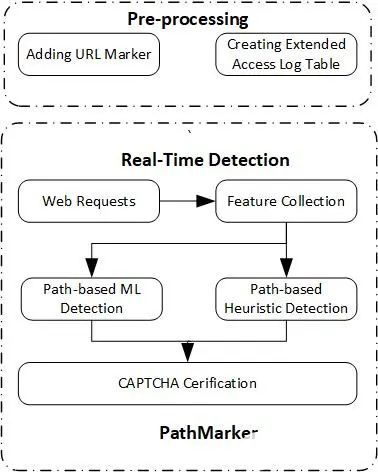
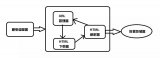
七、如何設計一個反爬蟲系統(tǒng)(常規(guī)架構)
有個朋友曾經給過我這樣一個架構:
對請求進行預處理,便于識別;
識別是否是爬蟲;
針對識別結果,進行適當?shù)奶幚恚?/p>
當時我覺得,聽起來似乎很有道理,不愧是架構,想法就是和我們不一樣。后來我們真正做起來反應過來不對了。因為:
如果能識別出爬蟲,哪還有那么多廢話?想怎么搞它就怎么搞它。如果識別不出來爬蟲,你對誰做適當處理?
三句話里面有兩句是廢話,只有一句有用的,而且還沒給出具體實施方式。那么:這種架構(師)有什么用?
因為當前存在一個架構師崇拜問題,所以很多創(chuàng)業(yè)小公司以架構師名義招開發(fā)。給出的title都是:初級架構師,架構師本身就是個高級崗位,為什么會有初級架構。這就相當于:初級將軍/初級司令。
最后去了公司,發(fā)現(xiàn)十個人,一個CTO,九個架構師,而且可能你自己是初級架構師,其他人還是高級架構師。不過初級架構師還不算坑爹了,有些小創(chuàng)業(yè)公司還招CTO做開發(fā)呢。
傳統(tǒng)反爬蟲手段
后臺對訪問進行統(tǒng)計,如果單個IP訪問超過閾值,予以封鎖。
這個雖然效果還不錯,但是其實有兩個缺陷,一個是非常容易誤傷普通用戶,另一個就是,IP其實不值錢,幾十塊錢甚至有可能買到幾十萬個IP。所以總體來說是比較虧的。不過針對三月份呢爬蟲,這點還是非常有用的。
后臺對訪問進行統(tǒng)計,如果單個session訪問超過閾值,予以封鎖。
這個看起來更高級了一些,但是其實效果更差,因為session完全不值錢,重新申請一個就可以了。
后臺對訪問進行統(tǒng)計,如果單個userAgent訪問超過閾值,予以封鎖。
這個是大招,類似于抗生素之類的,效果出奇的好,但是殺傷力過大,誤傷非常嚴重,使用的時候要非常小心。至今為止我們也就只短暫封殺過mac下的火狐。
以上的組合
組合起來能力變大,誤傷率下降,在遇到低級爬蟲的時候,還是比較好用的。
由以上我們可以看出,其實爬蟲反爬蟲是個游戲,RMB玩家才最牛逼。
因為上面提到的方法,效果均一般,所以還是用JavaScript比較靠譜。
也許有人會說:javascript做的話,不是可以跳掉前端邏輯,直接拉服務嗎?怎么會靠譜呢?因為啊,我是一個標題黨埃JavaScript不僅僅是做前端。跳過前端不等于跳過JavaScript。也就是說:我們的服務器是nodejs做的。
思考題:我們寫代碼的時候,最怕碰到什么代碼?什么代碼不好調試?
eval
eval已經臭名昭著了,它效率低下,可讀性糟糕。正是我們所需要的。
goto
js對goto支持并不好,因此需要自己實現(xiàn)goto。
混淆
目前的minify工具通常是minify成abcd之類簡單的名字,這不符合我們的要求。我們可以minify成更好用的,比如阿拉伯語。為什么呢?因為阿拉伯語有的時候是從左向右寫,有的時候是從右向左寫,還有的時候是從下向上寫。除非對方雇個阿拉伯程序員,否則非頭疼死不可。
不穩(wěn)定代碼
什么bug不容易修?不容易重現(xiàn)的bug不好修。因此,我們的代碼要充滿不確定性,每次都不一樣。
代碼演示
下載代碼本身,可以更容易理解。這里簡短介紹下思路:
純JAVASCRIPT反爬蟲DEMO,通過更改連接地址,來讓對方抓取到錯誤價格。這種方法,簡單,但是如果對方針對性的來查看,十分容易被發(fā)現(xiàn)。
純JAVASCRIPT反爬蟲DEMO,更改key。這種做法簡單,不容易被發(fā)現(xiàn)。但是可以通過有意爬取錯誤價格的方式來實現(xiàn)。
純JAVASCRIPT反爬蟲DEMO,更改動態(tài)key。這種方法可以讓更改key的代價變?yōu)?,因此代價更低。
純JAVASCRIPT反爬蟲DEMO,十分復雜的更改key。這種方法,可以讓對方很難分析,如果加了后續(xù)提到的瀏覽器檢測,更難被爬齲
到此為止。
前面我們提到了邊際效應,就是說,可以到此為止了。后續(xù)再投入人力就得不償失了。除非有專門的對手與你死磕。不過這個時候就是為了尊嚴而戰(zhàn),不是為了商業(yè)因素了。
瀏覽器檢測
針對不同的瀏覽器,我們的檢測方式是不一樣的。
IE,檢測bug;
FF,檢測對標準的嚴格程度;
Chrome,檢測強大特性。
八、我抓到你了——然后該怎么辦不會引發(fā)生產事件——直接攔截
可能引發(fā)生產事件——給假數(shù)據(jù)(也叫投毒)
此外還有一些發(fā)散性的思路。例如是不是可以在響應里做SQL注入?畢竟是對方先動的手。不過這個問題法務沒有給具體回復,也不容易和她解釋。因此暫時只是設想而已。
1. 技術壓制
我們都知道,DotAAI里有個de命令,當AI被擊殺后,它獲取經驗的倍數(shù)會提升。因此,前期殺AI太多,AI會一身神裝,無法擊殺。
正確的做法是,壓制對方等級,但是不擊殺。反爬蟲也是一樣的,不要一開始就搞太過分,逼人家和你死磕。
2. 心理戰(zhàn)
挑釁、憐憫、嘲諷、猥瑣。
以上略過不提,大家領會精神即可。
3. 放水
這個可能是是最高境界了。
程序員都不容易,做爬蟲的尤其不容易。可憐可憐他們給他們一小口飯吃吧。沒準過幾天你就因為反爬蟲做得好,改行做爬蟲了。












 工商網監(jiān)
工商網監(jiān)
評論