 電子發燒友App
電子發燒友App


集成電路(IC)的單個元件非常小,其生產要求達到原子級的精度。集成電路是通過在由半導體材料(通常是硅)制成的晶圓上創建電路結構。為了生產高密度集成電路,晶圓表面必須非常干凈,而且在前一個晶圓上制作的電路層應該是對齊的。如果這些條件沒有得到滿足,高密度結構可能會坍塌。
為了防止這種情況的發生,必須不斷地清洗晶圓以避免污染,并清除以前的工藝步驟的殘留物。然后,自動缺陷分類(ADC)被用來使用掃描電子顯微鏡圖像來識別和分類晶圓表面缺陷。然而,目前ADC系統的分類性能很差。如果缺陷可以被正確分類,那么制造問題的根源就可以被識別并最終解決。
機器學習技術已被廣泛接受,并且很適合此類分類問題。基于卷積神經網絡的雙重特征提取方法。提出的模型使用Radon拉冬變換進行第一次特征提取,然后將此特征輸入卷積層進行第二次特征提取。用真實的數據集進行的實驗驗證了所提方法取得了較高的缺陷分類性能,缺陷模式識別準確率高達98.5%,我們證實了所提特征提取技術的有效性。
對于集成電路的制造來說,Wafer Map上顯示的缺陷圖案包含了工程師尋找缺陷原因的關鍵信息,以提高良率。因此,分析晶圓圖缺陷的根本原因對于提高良率和最大限度地提高良好芯片的產量至關重要。然而,分析wafer map的傳統方法很耗時,而且準確度低。基于人工的方法的準確率低于45%。
近年來,許多都對晶圓缺陷模式識別問題進行了研究。應用決策樹和神經網絡對晶圓級芯片級封裝圖像進行缺陷分類。對無監督學習的神經網絡來構建晶圓圖的聚類。根據特定的故障模式對集群進行了標注,而wafer map則根據其與集群的接近程度進行分類。這種方法的優點是可以引入新的故障模式來識別表現出未知故障模式的wafer map。
wafer map可以轉換為圖像,wafer map故障模式識別適合于深度學習,這是一種強大的監督學習技術,不需要人工設計特征。深度學習可以達到很高的分類精度,特別是在主要包括圖像分類的任務中。一種基于新型人工神經網絡(ANN)架構的快速而準確的解決方案,使用卷積神經網絡(CNN)采用最先進的技術進行精確的光刻熱點檢測。將CNN用于缺陷模式分類和晶圓圖檢索任務,證明了通過只使用合成數據進行網絡訓練,真實的wafer map可以以高精確度進行分類使用CNN和極端梯度提升技術對ADI(After Deveroper Inspection)缺陷進行分類。CNN和極端梯度提升的測試數據集的總體分類精度分別為99.2%和98.1%。證明了這種技術在識別半導體晶圓的缺陷模式方面的成功。
方法
建議的方法有三個貢獻。首先,該方法只需要有和沒有目標故障圖案的晶圓圖來識別,而不需要手動設計故障圖案的特征來識別。第二,能夠在雙重特征提取的基礎上實現高識別精度。在這個模型中,使用Radon拉東變換進行第一次特征提取,然后將此特征輸入卷積層進行第二次特征提取。在這個過程中,可以在每一層學到豐富的特征,這些特征可以作為圖像檢索的良好描述符。最后,我們的方法可以擴展到多類分類,以同時識別各種類型的故障模式。使用半導體制造的真實數據證實了框架的有效性。
A. 研究過程
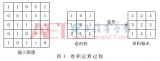
有六個步驟(如圖1所示)。首先,探索了缺陷圖像的數據。其次,用以下方法對圖像進行預處理:調整圖像大小、反轉像素強度等。然后,進行特征提取。同時使用兩種方法來提取特征,Radon拉東變換和CNN。在模型的訓練和測試中,將80%用于訓練集,20%用于測試集。最后,用準確率、精確度、召回率和F1-Score來評估所提出的方法的性能。
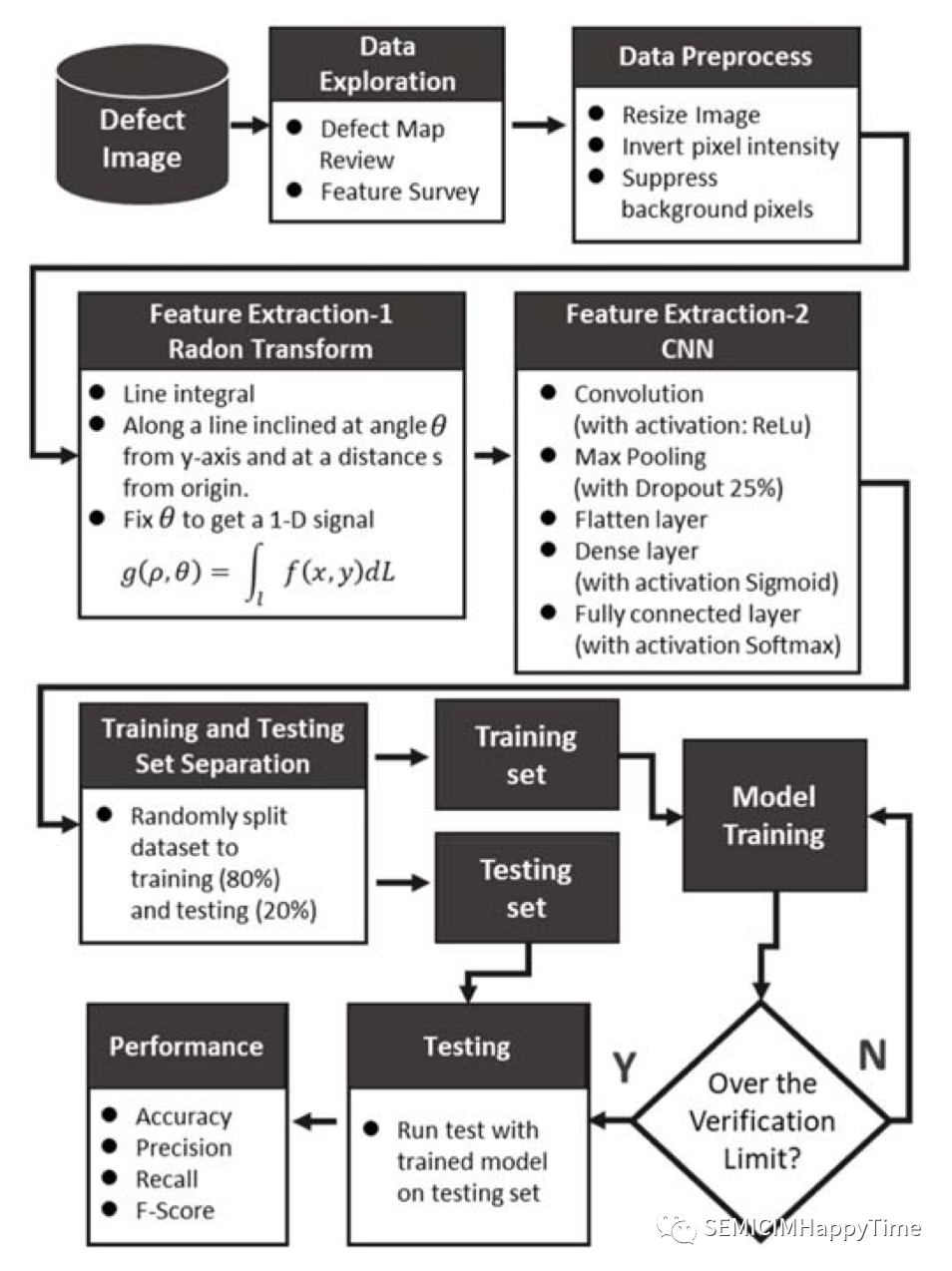
圖1. 模型訓練和測試的工作流程
B. 數據探索
共有11種缺陷類型,包括殘留、劃痕、球狀、瓶狀、法隆、絲狀、多點、小顆粒、橢圓形和顏色標記(如表一所示)。每個缺陷都有不同的特點和要素。例如,"Flask "的缺陷類型由鋁(Al)和氧(O)組成,"Falon "的缺陷類型由鐵(Fe)和鎳(Ni)組成,而 "Oval "的缺陷類型則由氟(F)組成。不同機器零件的老化會導致不同的缺陷。例如,"Flask"的缺陷包含鋁(Al)和氧(O)元素,主要來自化學氣相沉積(CVD)工藝腔室的靜電吸盤(ESC)(圖2)。

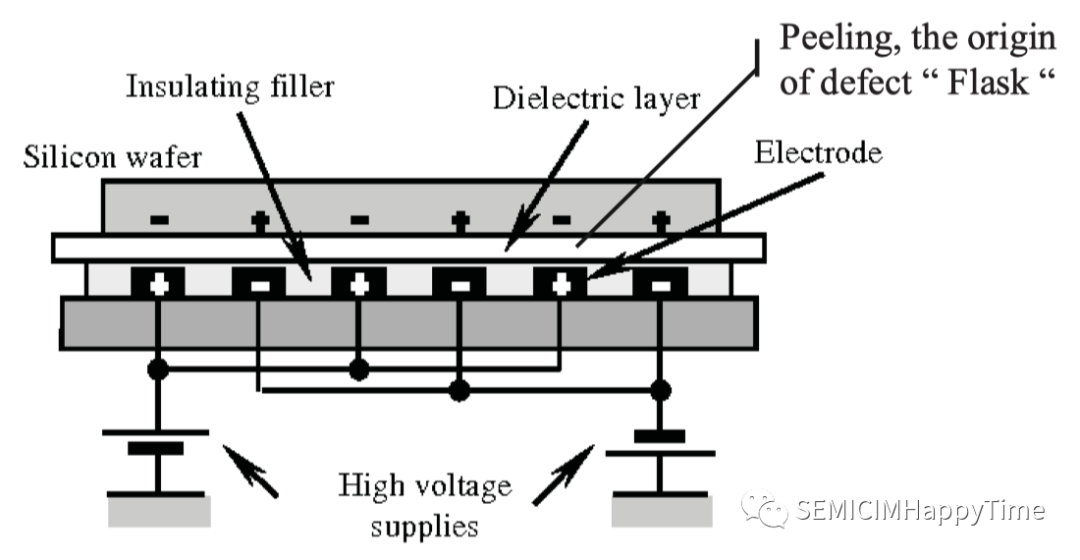
圖2. 靜電吸盤(ESC)的結構
靜電吸盤是一種在施加于電極的電壓下在電極和物體之間產生吸引力的裝置。在CVD工藝的高溫高壓環境下,隨著靜電吸盤的老化,顆粒會落在晶圓表面。當檢測到這種缺陷時,這意味著CVD設備的腔體需要維護,并以新的部件替換老化的部件。同樣,當檢測到其他類型的缺陷時,他們必須有自己的失控行動計劃(OCAP),以確保半導體制造的質量。
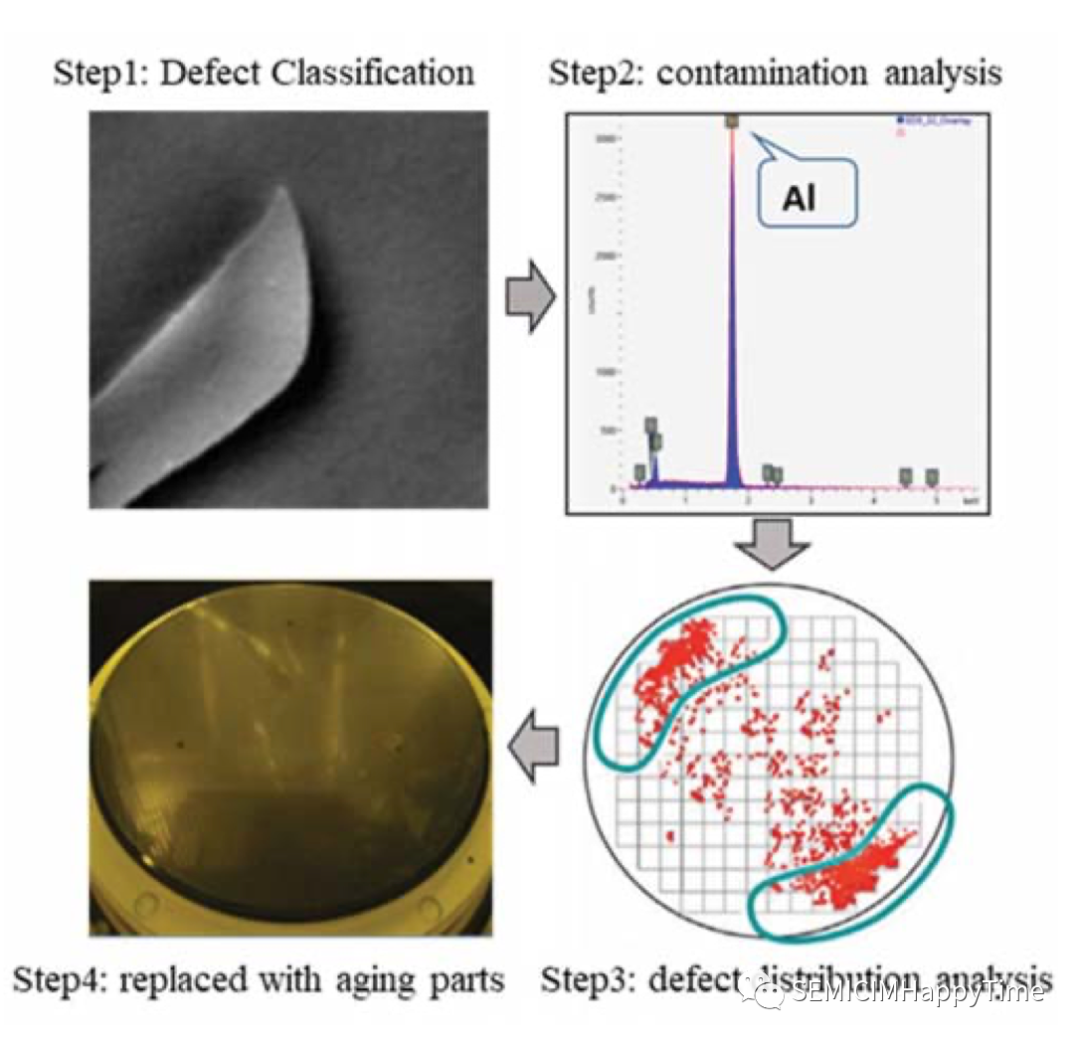
圖3. 缺陷 "Flask"的失控行動方案
C. CNN的特征提取
卷積神經網絡是受生物啟發的動物視覺皮層的變體。有兩種類型的細胞:簡單細胞和復雜細胞,其中簡單細胞提取特征,而復雜細胞從空間鄰域結合幾個這樣的局部特征。CNN試圖模仿這種結構,以類似的方式從輸入空間提取特征,然后進行分類。網絡中的每個卷積層包含許多特征圖。一個特征圖中的神經元被約束為共享相同的權重。
參數共享的理念允許不同的神經元共享相同的參數。為了完成這一任務,隱藏的神經元被組織成共享參數的特征圖。覆蓋圖像不同塊的特征圖中的隱藏單元共享相同的參數,并從不同塊中提取相同類型的特征。一個圖像的每個區塊都與多個特征圖相關聯,不同特征圖中的神經元從同一區塊中提取不同的特征。圖4幫助我們清楚地理解了參數共享的過程:特征圖中的每個隱藏單元與圖像的不同塊相連,并提取相同類型的特征。不同特征圖中的隱藏單元從同一塊中提取不同的特征。
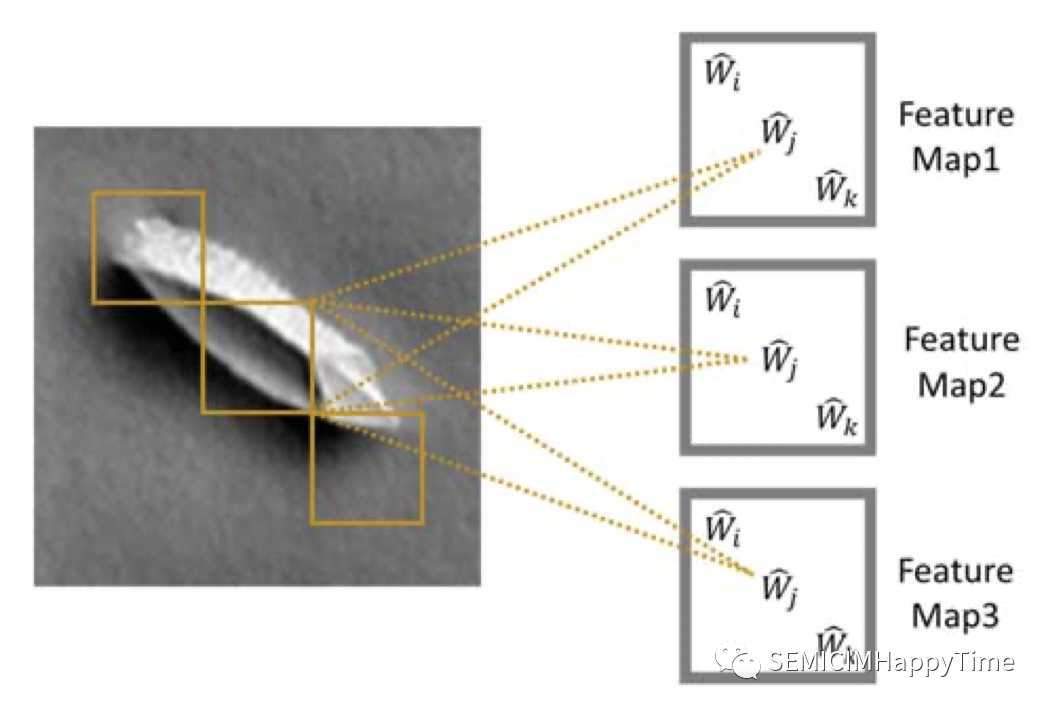
圖4. CNN中的參數共享
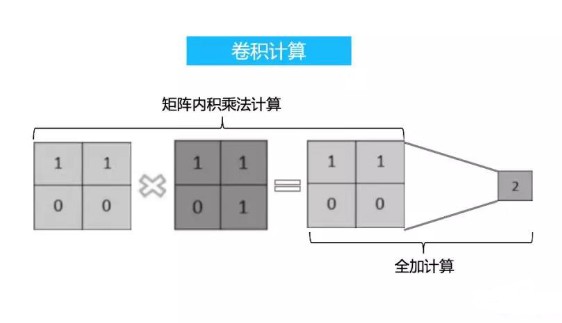
在一幅圖像中,區塊可以重疊。為了獲得每個隱藏單元的激活值,連接到特征圖的輸入通道的權重要乘以輸入向量。這種操作被稱為卷積。基本上,我們專注于離散卷積。離散卷積操作可以定義為:
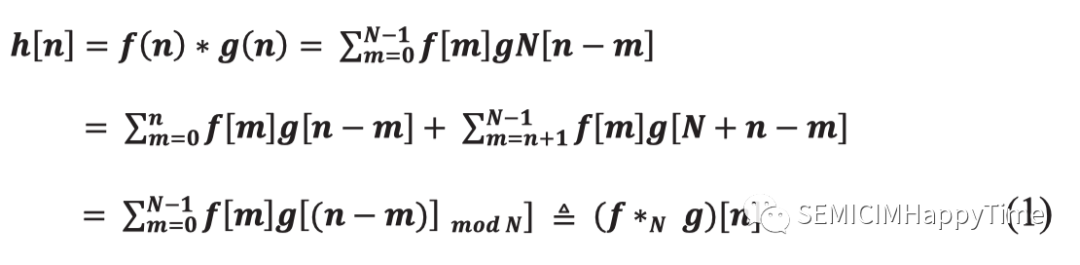
和是兩個函數。離散卷積是移位、乘法和加法運算的組合。在這里,卷積操作是通過將權重矩陣與圖像的某些塊相加,然后將權重矩陣移到其他重疊的塊上。
D. Radon拉東變換的特征提取
Radon拉東變換是用于檢測圖像內特征的技術之一。它基于圖像域直線的參數化和沿這些直線的圖像積分的評估。由于Radon拉東變換的固有特性,它是捕捉圖像方向性特征的一個有用工具。此外,Radon拉東變換是平移和旋轉不變的,所以它可以保留像素強度的變化。二維圖像函數在平面上的Radon拉東變換定義為:
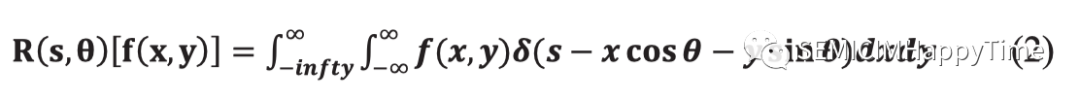
其中是狄拉克函數,是直線與原點的垂直距離,是距離向量形成的角度。
Radon拉東變換已被廣泛用于檢索邊緣檢測、紋理分類和計算機斷層成像中的圖像局部特征。圖5展示了一個缺陷圖像的Radon拉東變換的例子。在此,提出了一種新的方法,通過使用Radon拉東變換和卷積神經網絡的組合來識別缺陷圖案。。

圖5. 原始圖像和Radon拉東變換在各自角度為0-170°時的比較
E. 模型架構
使用卷積神經網絡(CNN)作為分類器的主要架構。CNN是一個非線性過濾器的堆棧,它逐漸減少圖像的空間范圍,同時增加描述每個位置的圖像的過濾器輸出數量。在堆棧的頂部是一個多叉邏輯回歸分類器,它將表征映射到每個輸出類別("剩余"、"劃痕"、"球"、"駝峰 "等)的概率值。整個網絡通過反向傳播共同優化,這通常是通過隨機梯度下降實現的 。
圖6. CNN模型結構
嘗試將不同的卷積神經網絡與Radon拉東變換相結合,作為缺陷模式識別的分類器,包括VGG16、Inception和ResNet。如圖7所示,RadonNet有兩個主要架構。第一個是原始圖像的CNN。它基于卷積層和ReLU修正線性單元激活提取特征,然后通過參數共享將結果輸出到扁平化層。第二個是Radon拉東變換后的圖像的CNN。它可以在每個卷積層學習豐富的特征。最后,將這兩個結果結合起來,輸出到具有sigmoid函數激活的全連接層。模型平均后,加入另一個具有通道11(缺陷類的數量)的全連接層。輸出是用于計算類別概率的softmax層。
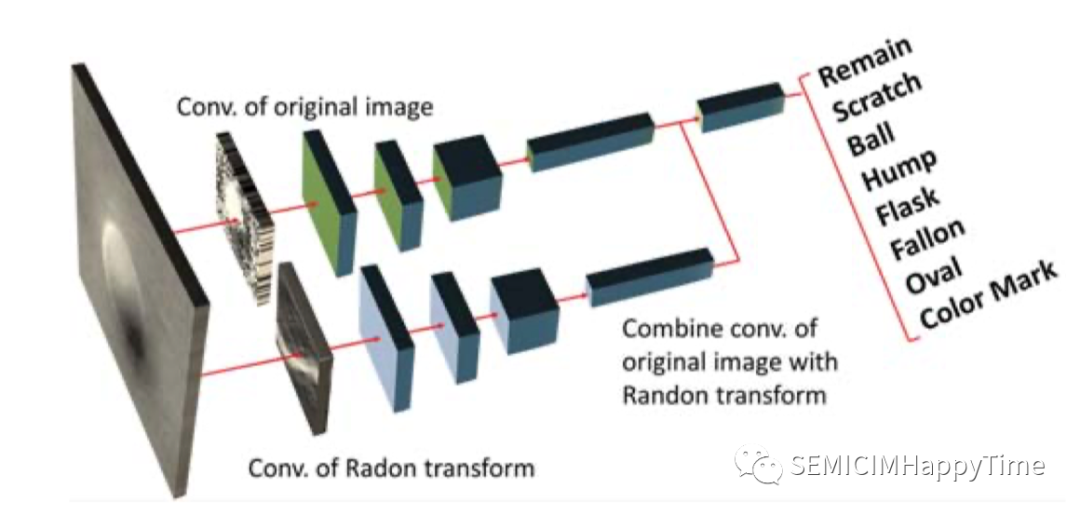
圖7. RadonNet的結構
F. 算法設計
RadonNet使用小批量隨機梯度下降法進行訓練(圖8)。在每次迭代中,隨機抽取n個圖像來計算梯度,然后更新網絡參數(W)。它在數據集中經過次后停止。算法中的所有函數和超參數都可以在后面介紹的不同神經網絡中實現。

圖8. CNN模型結構
學習率
在訓練任何深度學習模型時,最難設置的參數之一是學習率。如果數值很大,模型的權重就會開始振蕩,它們會有很大的變化,使模型無法適應誤差的變化。如果學習率太小,會使模型的學習成本增加,很可能卡在局部最小值。在訓練深度網絡時,隨著時間的推移使學習率退火通常是有幫助的。在這里使用用Cosine decay作為學習率的函數,它實證研究了CIFAR-10和CIFAR-100數據集的性能,這些數據集已經被證明是最先進的新結果。計算步驟如下:

其中可以被看作是一個基線,以確保學習率不會低于某個值。
2. 輸出設計
輸出層是一個全連接層,其隱藏大小等于所代表的標簽數量,以輸出預測的置信度分數()。如公式7所示,給定一個圖像,用表示類的預測分數。這些分數可以通過softmax算子進行歸一化,得到預測的概率。讓表示softmax算子的輸出,類的概率可以通過以下公式計算:
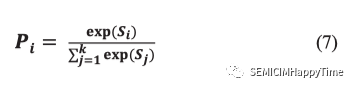
其中,并且?,是一個有效的概率分布。
3. 損失函數
在訓練過程中,使用負交叉熵損失函數的最小化來更新模型參數,使這兩個概率分布彼此相似。如公式8所示,假設圖像的真實標簽是,的真實概率分布()可以構造為,否則可以構造為0。
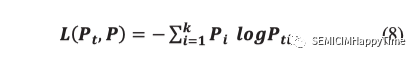
特別是,通過的構造方式,我們知道?。最佳解決方案是?= 無限大,同時保持其他的足夠小。它可以促使輸出的分數大大地與眾不同。
G. 數據擴增
在深度學習中,我們經常需要大量的數據來保證訓練過程中不會出現過擬合。事實證明,數據擴增可以解決數據不足的問題,提高系統訓練的準確性。它是通過轉換訓練數據來生成樣本的過程,目的是提高分類器的準確性和魯棒性。我們使用以下方法作為數據增強:隨機裁剪(512中的±64),隨機翻轉(±90°x i ,),隨機亮度(255中的±32),隨機飽和度(從50%到150%),隨機色調(0.5中的±0.2),以及隨機對比度(從50%到150%)。做完這些工作后,我們的眼睛也許還能認出它是同一張圖片,但對機器來說,它是一張完全不同的新圖片。
結果
將這個方法與最先進的深度學習方法在先進的半導體工藝(5納米芯片)缺陷模式分類上進行評估和比較。
A. 訓練程序
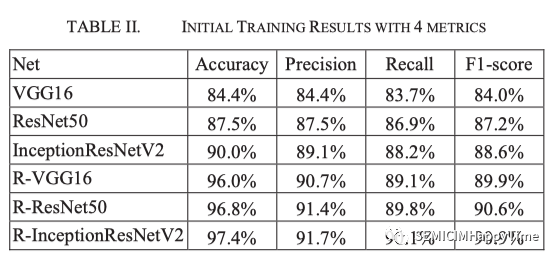
首先,我們使用SGD優化器訓練模型,并將所有實驗的批次大小設置為32。我們將初始學習率設置為10-4。使用準確性、精確性、召回率和F1-score作為評價指標。初始訓練結果見表二。R-VGG16/ResNet50/R-InceptionResNetV2是與Radon拉東變換相結合的改進模型。根據結果,RadonNet比原始模型有明顯的改進。
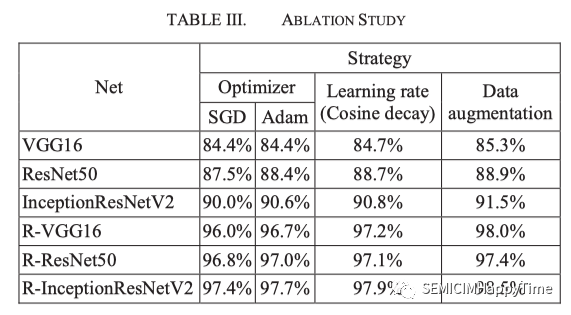
B. 消融學習
為了證明RadonNet的實用性,進行了嚴格的消融學習,并在表三中顯示了定量比較。優化器 "的策略顯示了使用SGD(隨機梯度下降)和Adam(自適應矩估計)作為優化器的準確性。Adam結合了SGD和RMSprop(Root Mean Square Propagation)的功能,保留了動量來調整過去梯度方向的梯度速度,同時也調整了梯度值平方的學習率。這將使參數更新更加穩定,以獲得更好的訓練效果。
“學習率"的策略通過Cosine decay來顯示訓練結果。在使用Cosine decay的情況下,訓練結果比使用固定的學習率要好。最后,帶有數據增強的R-InceptionResNetV2是最好的模型,準確率為98.5%。
C. 主要結果
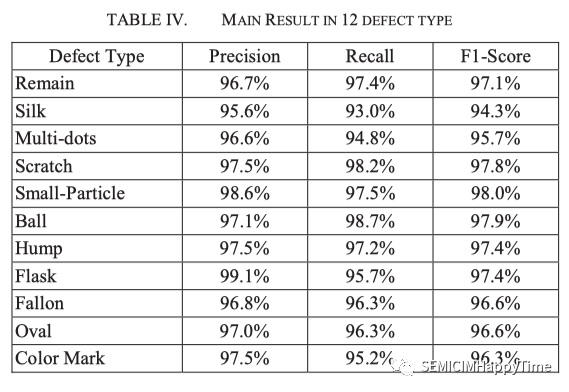
用三個評價指標驗證了所提模型的有效性:精度、召回率和F1-score。表四顯示了11種缺陷類型的驗證模型的性能。所有缺陷類型的精確度都在95%以上。除了 "Silk "和 "Multi-dots "的缺陷類型,其他兩個指標也都高于95%。這可能是由于其結構不確定,容易與其他缺陷形狀相混淆。
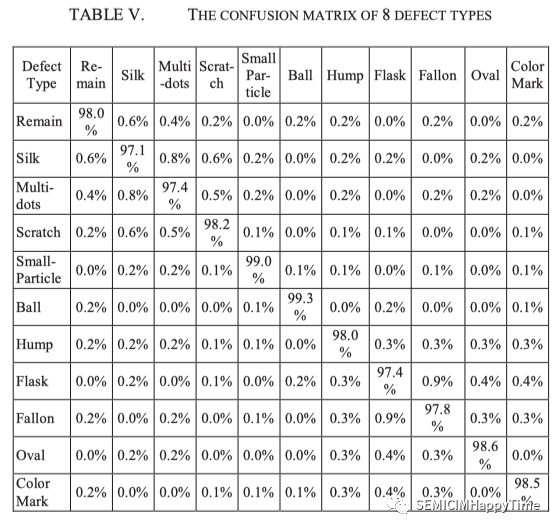
表五是混淆矩陣,它顯示了以百分比表示的每類分類的準確性。由于保密的原因,只能提供每類的準確性,而不是晶圓的絕對數量。在這個表格中,標簽(基礎事實)顯示在左列,而建議的方法的預測結果在最上面一行。對角線上的元素代表每種類型的識別率。大多數缺陷類型的準確率都大于97%。總體準確率為98.5%。
成功地將雙特征提取技術用于晶圓缺陷分類。提出了一種新的ADC方法,結合了Radon拉東變換和卷積神經網絡。Radon拉東變換可以從晶圓表面缺陷圖像中提取有效特征。CNN將圖像轉換為深度維度,用于第二次特征提取。然后,神經網絡可以學習這個豐富的特征來識別什么類型的缺陷。使用真實的缺陷圖像數據集進行的性能評估實驗得出的分類準確率平均為98.5%。證明了新的ADC方法對晶圓圖故障模式識別是有效的。
編輯:黃飛
?




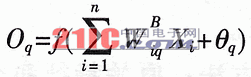










 工商網監
工商網監
評論