 電子發(fā)燒友App
電子發(fā)燒友App


序列到序列模型在端到端語音處理中被廣泛應(yīng)用,例如自動語音識別(ASR)、語音翻譯(ST)和文本轉(zhuǎn)語音(TTS)。本文著重研究一種新興的序列到序列模型,稱為變壓器(Transformer),它在神經(jīng)機(jī)器翻譯和其他自然語言處理應(yīng)用中取得了最先進(jìn)的性能。我們進(jìn)行了深入的研究,通過實(shí)驗(yàn)比較和分析了變壓器和傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)在總共15個(gè)自動語音識別(ASR)、一個(gè)多語種ASR、一個(gè)語音翻譯(ST)和兩個(gè)文本轉(zhuǎn)語音(TTS)基準(zhǔn)任務(wù)中的表現(xiàn)。我們的實(shí)驗(yàn)揭示了各種訓(xùn)練技巧以及變壓器在每個(gè)任務(wù)中所取得的顯著性能優(yōu)勢,其中包括與RNN相比在13/15個(gè)ASR基準(zhǔn)任務(wù)中的出人意料的優(yōu)越性。我們正在準(zhǔn)備發(fā)布Kaldi風(fēng)格的可重現(xiàn)配方,使用開源和公開可用的數(shù)據(jù)集,為所有的ASR、ST和TTS任務(wù)提供給社區(qū),以便能夠在我們激動人心的成果基礎(chǔ)上取得成功。
1. 引言
Transformer是一種序列到序列(S2S)架構(gòu),最初用于神經(jīng)機(jī)器翻譯(NMT)[1],并在自然語言處理任務(wù)中迅速取代了循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)。本文對其在語音應(yīng)用領(lǐng)域(自動語音識別(ASR)、語音翻譯(ST)和文本轉(zhuǎn)語音(TTS))的性能與RNN進(jìn)行了深入比較。
將Transformer應(yīng)用于語音應(yīng)用的一個(gè)主要困難在于,它需要比傳統(tǒng)基于RNN的模型更復(fù)雜的配置(例如,優(yōu)化器、網(wǎng)絡(luò)結(jié)構(gòu)、數(shù)據(jù)增強(qiáng))。我們的目標(biāo)是分享有關(guān)在語音任務(wù)中使用變壓器的知識,以便社區(qū)可以借助可重現(xiàn)的開源工具和配方充分取得我們激動人心的成果。
目前,現(xiàn)有的基于Transformer的語音應(yīng)用[2]–[4]仍缺乏開源工具包和可重現(xiàn)的實(shí)驗(yàn),而在之前的神經(jīng)機(jī)器翻譯研究[5]、[6]中已經(jīng)提供了這些資源。因此,我們正在進(jìn)行一個(gè)開放的社區(qū)驅(qū)動項(xiàng)目,使用變壓器和循環(huán)神經(jīng)網(wǎng)絡(luò),為端到端語音應(yīng)用提供支持,借鑒了基于隱馬爾可夫模型(HMM)的ASR領(lǐng)域的Kaldi的成功經(jīng)驗(yàn)[7]。具體而言,我們的實(shí)驗(yàn)提供了實(shí)用指南,用于調(diào)整語音任務(wù)中的變壓器,以實(shí)現(xiàn)最先進(jìn)的結(jié)果。
在我們的語音應(yīng)用實(shí)驗(yàn)中,我們研究了變壓器和基于循環(huán)神經(jīng)網(wǎng)絡(luò)的系統(tǒng)的幾個(gè)方面。例如,我們測量了與參考標(biāo)準(zhǔn)相比的詞/字符/回歸誤差,訓(xùn)練曲線以及在多個(gè)GPU上的可擴(kuò)展性。這項(xiàng)工作的貢獻(xiàn)包括:
? 我們進(jìn)行了一項(xiàng)大規(guī)模的比較研究,對比了變壓器和循環(huán)神經(jīng)網(wǎng)絡(luò),在ASR相關(guān)任務(wù)中取得了顯著的性能提升。
? 我們解釋了在語音應(yīng)用(ASR、TTS和ST)中使用變壓器的訓(xùn)練技巧。
? 我們在我們的開源工具包ESPnet [8]中提供了可重現(xiàn)的端到端配方和在大量公開可用數(shù)據(jù)集上預(yù)訓(xùn)練的模型。
相關(guān)研究
由于變壓器最初被提出作為NMT系統(tǒng)[1],它已經(jīng)在NMT任務(wù)中得到廣泛研究,包括超參數(shù)搜索[9]、并行實(shí)現(xiàn)[5]以及與RNN的比較[10]。然而,語音處理任務(wù)在ASR [2]、ST [3]和TTS [4]方面只提供了初步的結(jié)果。因此,本文旨在匯集以前的基礎(chǔ)研究,并在我們的實(shí)驗(yàn)中探索更廣泛的主題(例如準(zhǔn)確性、速度、訓(xùn)練技巧)。
2.序列到序列循環(huán)神經(jīng)網(wǎng)絡(luò)
2.1 序列到序列的統(tǒng)一公式
S2S(序列到序列)是一種神經(jīng)網(wǎng)絡(luò)的變種,它學(xué)習(xí)將源序列X轉(zhuǎn)換為目標(biāo)序列Y [12]。在圖1中,我們展示了用于ASR、TTS和ST任務(wù)的常見S2S結(jié)構(gòu)。S2S包括兩個(gè)神經(jīng)網(wǎng)絡(luò):一個(gè)編碼器(encoder)
(1)
(2)
和一個(gè)解碼器
(3)
? ?(4)
? ?(5)
其中,X是源序列(例如,語音特征序列(用于ASR和ST)或字符序列(用于TTS)),e是EncBody中的層數(shù),d是DecBody中的層數(shù),t是目標(biāo)幀的索引,上述方程中的所有函數(shù)都由神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)。對于解碼器的輸入Y [1 : t - 1],在訓(xùn)練階段我們使用了一個(gè)基于真實(shí)數(shù)據(jù)的前綴,而在解碼階段我們使用了一個(gè)生成的前綴。在訓(xùn)練過程中,S2S模型學(xué)習(xí)最小化標(biāo)量損失值。
(6)
在生成的序列和目標(biāo)序列之間的損失值。
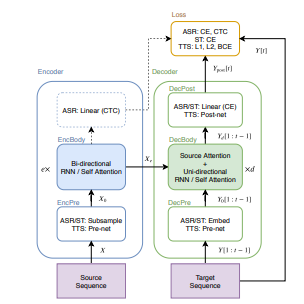
圖1 在語音應(yīng)用中的序列到序列架構(gòu)
本節(jié)的其余部分描述了基于RNN的通用模塊:“EncBody”和“DecBody”。我們將“EncPre”、“DecPre”、“DecPost”和“Loss”視為特定任務(wù)的模塊,并在后面的部分中對它們進(jìn)行描述。
2.2 循環(huán)神經(jīng)網(wǎng)絡(luò)解碼器
在方程(4)中,DecBody(·)使用編碼序列和目標(biāo)前綴生成下一個(gè)目標(biāo)幀。在序列生成中,解碼器通常是單向的。例如,基于循環(huán)神經(jīng)網(wǎng)絡(luò)的DecBody(·)實(shí)現(xiàn)中經(jīng)常使用帶有注意力機(jī)制的單向LSTM [13]。該注意力機(jī)制通過發(fā)出源幀權(quán)重,將編碼的源幀 ?按目標(biāo)幀進(jìn)行求和,得到一個(gè)與前綴一起進(jìn)行轉(zhuǎn)換的目標(biāo)幀向量。我們將這種類型的注意力稱為“編碼器-解碼器注意力”。
3. 變壓器
變壓器通過自注意力機(jī)制學(xué)習(xí)序列信息,而不是RNN中使用的循環(huán)連接。本節(jié)詳細(xì)描述了變壓器中基于自注意力的模塊。
3.1 多頭注意力
變壓器由多個(gè)點(diǎn)注意力層[18]組成。
? ?(7)
其中 和 是這個(gè)注意力層的輸入, 是特征維度的數(shù)量, 是 的長度, 是 和 的長度。我們將 稱為 “注意力矩陣" 。Vaswani等人[1]將這些輸入 和 分別視為查詢 (query) 和一組鍵值對 (key-value pairs)。
此外,為了使模型能夠并行處理多個(gè)注意力,Vaswani等人[1]將方程(7)中的注意力層擴(kuò)展為多頭注意力(MHA):
?(8)
? ?(9)
其中 和 是這個(gè)多頭注意力層的輸入, 是第 個(gè)注意力層的輸出和是可學(xué)習(xí)的權(quán)重矩陣, 是該層中的注意力數(shù)目。
3.2 自注意力編碼器
我們定義了基于變壓器的EncBody(·),用于方程(2),與第2.2節(jié)中的RNN編碼器不同,定義如下:
? ?(10)
其中, 是編碼器層的索引,而 是第 個(gè)雙層前饋網(wǎng)絡(luò):
? ?(11)
其中 是輸入序列 的第幀,是可學(xué)習(xí)的權(quán)重矩陣,而是可學(xué)習(xí)的偏置向量。我們將方程 中的 稱為 "自注意力" (self attention)。
3.3 自注意力解碼器
用于方程(4)的基于變壓器的DecBody(·)由兩個(gè)注意力模塊組成:
? ?(12)
其中,是解碼器層的索引。我們將中解碼器輸入和編碼器輸出之間的注意力矩陣稱為“編碼器-解碼器注意力”,與第2.3節(jié)中的RNN中的注意力相同。由于單向解碼器在序列生成中很有用,因此在第t個(gè)目標(biāo)幀處,將其注意力矩陣進(jìn)行掩碼處理,以防止它們與后續(xù)幀(大于t)發(fā)生連接。可以使用逐元素乘法與一個(gè)三角形二進(jìn)制矩陣并行地對序列進(jìn)行掩碼操作。由于它不需要順序操作,因此比RNN提供更快的實(shí)現(xiàn)。
3.4 位置編碼
為了在非循環(huán)模型中表示時(shí)間位置,變壓器采用了正弦位置編碼:
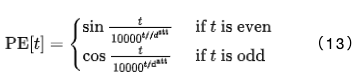
在應(yīng)用EncBody(.)和DecBody(()模塊之前,輸入序列會與 進(jìn)行拼接。
4. ASR擴(kuò)展
在我們的ASR框架中,序列到序列(S2S)模型從輸入序列(使用對數(shù)梅爾濾波器組成的語音特征)中預(yù)測出目標(biāo)字符序列或SentencePiece [19]序列。
4.1 ASR編碼器架構(gòu)
在ASR中,源序列 被表示為一個(gè)由83維對數(shù)梅爾濾波器幀和音高特征[20]組成的序列。首先,EncPre(.)使用具有256個(gè)通道、步幅為2和卷積核大小為 3 的兩層CNN或類似于VGG的最大池化[21],將源序列 轉(zhuǎn)換為一個(gè)子采 樣序列 。這里, 是CNN輸出序列的長度。這個(gè)CNN對應(yīng)于方程 (1) 中的 EncPre 。然后,EncBody 將 轉(zhuǎn)換為一系列編碼特征 ,用于CTC和解碼器網(wǎng)絡(luò)。
4.2 ASR解碼器架構(gòu)
解碼器網(wǎng)絡(luò)接收編碼序列Xe和目標(biāo)序列Y [1:t?1]的前綴,這些前綴由令牌ID(字符或SentencePiece [19])組成。首先,方程(3)中的DecPre(·)將令牌嵌入到可學(xué)習(xí)的向量中。接下來,DecBody(·)和單線性層DecPost(·)使用Xe和Y [1:t?1]預(yù)測下一個(gè)令牌Ypost[t]的后驗(yàn)分布。
4.3 ASR訓(xùn)練和解碼
在ASR訓(xùn)練過程中,解碼器和CTC模塊分別預(yù)測給定相應(yīng)源序列 的 的逐幀后驗(yàn)分布:和。我們簡單地使用這些負(fù)對數(shù)似然值的加權(quán)和:
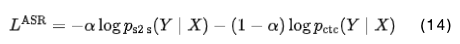
其中,α是一個(gè)超參數(shù)。
在解碼階段,解碼器使用束搜索(beam search)預(yù)測給定語音特征和先前預(yù)測的令牌的下一個(gè)令牌。在束搜索中,結(jié)合S2S、CTC和RNN語言模型(LM)[22]的得分,計(jì)算如下:
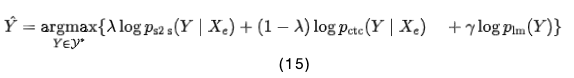
其中,是目標(biāo)序列的一組假設(shè),而和是超參數(shù)。
5. ST擴(kuò)展
在語音翻譯(ST)中,S2S接收與ASR相同的源語音特征和目標(biāo)令牌序列,但源語言和目標(biāo)語言不同。它的模塊定義方式與ASR中的相同。然而,ST無法與第4.3節(jié)介紹的CTC模塊合作,因?yàn)榕cASR不同,翻譯任務(wù)不能保證源序列和目標(biāo)序列的單調(diào)對齊[23]。
6. TTS擴(kuò)展
在TTS框架中,序列到序列(S2S)模型生成一系列對數(shù)梅爾濾波器特征,并預(yù)測給定輸入字符序列的序列結(jié)束(EOS)的概率[15]。
6.1 TTS編碼器架構(gòu)
在TTS中,編碼器的輸入是與輸入字符和EOS符號對應(yīng)的ID序列。首先,字符ID序列通過嵌入層轉(zhuǎn)換為字符向量序列,然后通過一個(gè)可學(xué)習(xí)的標(biāo)量參數(shù)對向量進(jìn)行縮放的位置編碼被添加到向量中[4]。這個(gè)過程是方程(1)中EncPre(·)的TTS實(shí)現(xiàn)。最后,編碼器EncBody(·)在方程(2)中將這個(gè)輸入序列轉(zhuǎn)換為解碼器網(wǎng)絡(luò)的一系列編碼特征。
6.2 TTS解碼器架構(gòu)
在TTS中,解碼器的輸入是一系列編碼器特征和一系列對數(shù)梅爾濾波器特征。在訓(xùn)練中,采用了“teacher-forcing”方式使用真實(shí)的對數(shù)梅爾濾波器特征,而在推理階段,采用了自回歸(autoregressive)的方式使用預(yù)測的特征。
首先,將80維對數(shù)梅爾濾波器特征的目標(biāo)序列通過Prenet [15]轉(zhuǎn)換為一系列隱藏特征,作為方程(3)中DecPre(·)的TTS實(shí)現(xiàn)。該網(wǎng)絡(luò)由兩個(gè)具有256個(gè)單元的線性層、一個(gè)ReLU激活函數(shù)、以及dropout層組成,最后是一個(gè)具有個(gè)單元的投影線性層。由于預(yù)期Prenet轉(zhuǎn)換的隱藏表示與編碼器特征的特征空間類似,Prenet有助于學(xué)習(xí)到一個(gè)對角的編碼器-解碼器注意力[4]。然后,方程(4)中的解碼器DecBody(·),其架構(gòu)與編碼器相同,將編碼器特征序列和隱藏特征序列轉(zhuǎn)換為解碼器特征序列。對于的每一幀,應(yīng)用了兩個(gè)線性層,分別用于計(jì)算目標(biāo)特征和EOS的概率。最后,將預(yù)測的目標(biāo)特征序列應(yīng)用于Postnet [15],以詳細(xì)預(yù)測其各個(gè)組成部分。Postnet是一個(gè)五層CNN,每一層都是一個(gè)具有256個(gè)通道和大小為5的卷積核的1D卷積層,隨后進(jìn)行批量歸一化、tanh激活函數(shù)和dropout處理。這些模塊是方程(5)中DecPost(·)的TTS實(shí)現(xiàn)。
6.3 TTS訓(xùn)練和解碼
在TTS訓(xùn)練中,整個(gè)網(wǎng)絡(luò)被優(yōu)化以最小化兩個(gè)損失函數(shù):1)目標(biāo)特征的L1損失和2)EOS概率的二元交叉熵(BCE)損失。為了解決BCE計(jì)算中的類別不平衡問題,對于正樣本,使用一個(gè)常數(shù)權(quán)重(例如5)[4]。
此外,我們應(yīng)用了引導(dǎo)式注意力損失(guided attention loss)[24],以加速對只有兩個(gè)頭部的兩個(gè)層的對角注意力的學(xué)習(xí)。這是因?yàn)橐阎幋a器-解碼器注意力矩陣僅在來自目標(biāo)側(cè)的少數(shù)頭部中呈對角形式[4]。我們沒有引入任何用于平衡這三個(gè)損失值的超參數(shù),只是將它們簡單地相加。
在推理階段,網(wǎng)絡(luò)以自回歸的方式預(yù)測下一幀的目標(biāo)特征。如果EOS的概率超過了一定閾值(例如0.5),網(wǎng)絡(luò)將停止預(yù)測。
7. ASR實(shí)驗(yàn)
7.1 數(shù)據(jù)集
在表格1中,我們總結(jié)了我們在ASR實(shí)驗(yàn)中使用的15個(gè)數(shù)據(jù)集。我們的實(shí)驗(yàn)涵蓋了ASR中的各種主題,包括錄音(清晰的、嘈雜的、遠(yuǎn)場的等)、語言(英語、日語、普通話、西班牙語、意大利語)和規(guī)模(10-960小時(shí))。除了JSUT [25]和Fisher-CALLHOME西班牙語外,我們的數(shù)據(jù)準(zhǔn)備腳本基于Kaldi的“s5x”配方[7]。在技術(shù)上,我們調(diào)整了所有配置(例如特征提取、SentencePiece [19]、語言建模、解碼、數(shù)據(jù)增強(qiáng)[26],[27]),除了訓(xùn)練階段的配置,使其達(dá)到現(xiàn)有基于RNN的系統(tǒng)的最佳性能。我們對幾個(gè)語料庫使用了數(shù)據(jù)增強(qiáng)。例如,我們對CSJ、CHiME4、Fisher CALLHOME西班牙語、HKUST和TED-LIUM2/3應(yīng)用了速度擾動[27],擾動比率為0.9、1.0和1.1;我們還對Aurora4、LibriSpeech、TED-LIUM2/3和WSJ應(yīng)用了SpecAugment [26]。
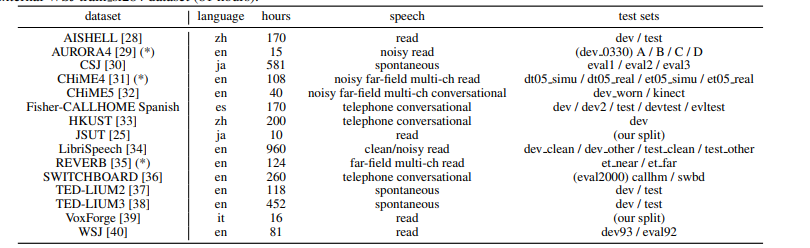
表1 ASR數(shù)據(jù)集描述。在“測試集”中列出的名稱對應(yīng)于表2中的ASR結(jié)果。我們通過外部的WSJ train si284數(shù)據(jù)集(81小時(shí))擴(kuò)大了標(biāo)有(*)的語料庫。
7.2 設(shè)置
我們采用了與[41]中相同的變壓器架構(gòu),適用于除最大的LibriSpeech外的每個(gè)語料庫。對于RNN,我們遵循先前研究[17],[42]中針對每個(gè)語料庫配置的最佳架構(gòu)。
由于Transformer的訓(xùn)練迭代速度是RNN的八倍,更新更精細(xì),因此Transformer需要與RNN不同的優(yōu)化器配置。對于RNN,我們采用了Adadelta [43]并使用早停策略的每個(gè)語料庫的最佳系統(tǒng)配置。為了訓(xùn)練Transformer,我們基本上遵循了先前的文獻(xiàn)[2](例如,dropout、學(xué)習(xí)率、熱身步驟)。在Transformer中,我們沒有使用開發(fā)集進(jìn)行早停策略。我們只是運(yùn)行了20-200個(gè)epoch(大多數(shù)為100個(gè)epoch),并將最后10個(gè)epoch存儲的模型參數(shù)取平均作為最終模型。
我們在單個(gè)GPU上對較大的語料庫(如LibriSpeech、CSJ和TED-LIUM3)進(jìn)行了訓(xùn)練。我們還確認(rèn)了使用多個(gè)前向/后向步驟上的梯度累積[5]來模擬多個(gè)GPU的效果,可以獲得與這些語料庫相似的性能。在解碼階段,Transformer和RNN在每個(gè)語料庫上共享相同的配置,例如束搜索大小(例如,20-40),CTC權(quán)重λ(例如,0.3)和LM權(quán)重γ(例如,0.3-1.0),這些在第4.3節(jié)中介紹。
7.3 結(jié)果
表2總結(jié)了每個(gè)語料庫的ASR結(jié)果,以字符錯(cuò)誤率(CER)和詞錯(cuò)誤率(WER)衡量。結(jié)果顯示,在我們的實(shí)驗(yàn)中,Transformer在13個(gè)語料庫中優(yōu)于RNN。雖然我們的系統(tǒng)不像Kaldi那樣具有發(fā)音字典、詞性標(biāo)記和基于對齊的數(shù)據(jù)清理,但我們的Transformer在7個(gè)語料庫上提供了與基于HMM的系統(tǒng)Kaldi可比的CER/WER。我們得出結(jié)論,Transformer在低資源(JSUT)、大資源(LibriSpeech、CSJ)、嘈雜(AURORA4)和遠(yuǎn)場(REVERB)任務(wù)中,甚至能夠超越基于RNN的端到端系統(tǒng)和基于DNN/HMM的系統(tǒng)。表3還總結(jié)了LibriSpeech ASR基準(zhǔn)測試的結(jié)果,包括我們的結(jié)果和其他報(bào)告,因?yàn)檫@是一個(gè)最具競爭力的任務(wù)。我們的Transformer結(jié)果與[26]、[44]、[45]中的最佳表現(xiàn)可媲美。
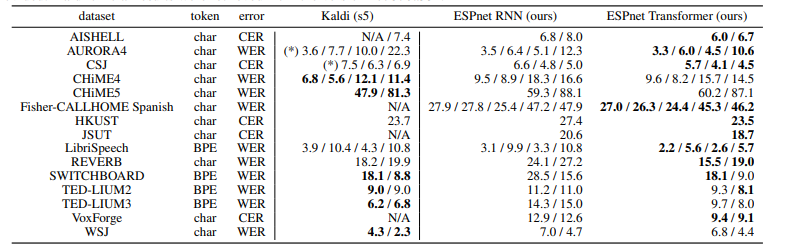
表2 字符/詞錯(cuò)誤率的ASR結(jié)果。帶有(*)標(biāo)記的結(jié)果是在我們的環(huán)境中進(jìn)行評估的,因?yàn)闆]有提供官方結(jié)果。Kaldi的官方結(jié)果是從版本“c7876a33”中提取的。
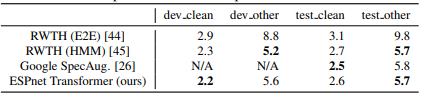
表3 Librispeech ASR基準(zhǔn)測試的比較如表所示
圖2展示了在LibriSpeech上使用多個(gè)GPU訓(xùn)練得到的ASR訓(xùn)練曲線。我們觀察到,使用較大的小批量訓(xùn)練的Transformer的準(zhǔn)確性更高,而RNN則沒有這種趨勢。另一方面,當(dāng)我們對Transformer使用較小的小批量時(shí),在熱身步驟之后通常會出現(xiàn)欠擬合的情況。在這個(gè)任務(wù)中,相比使用單個(gè)GPU的RNN,Transformer以大約八倍的速度實(shí)現(xiàn)了與RNN相當(dāng)?shù)淖罴褱?zhǔn)確性。
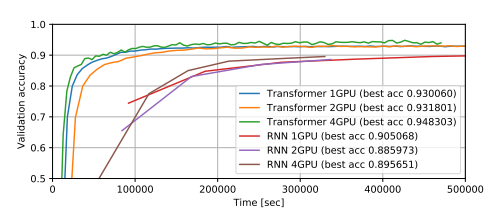
圖2. 使用LibriSpeech數(shù)據(jù)集進(jìn)行ASR訓(xùn)練的曲線。在GPU上,每個(gè)模型的小批量中包含最大數(shù)量的語音段。
7.4 討論
我們總結(jié)了我們在實(shí)驗(yàn)中觀察到的訓(xùn)練技巧:
當(dāng)Transformer出現(xiàn)欠擬合時(shí),我們建議增加小批量的大小,因?yàn)檫@不僅可以加快訓(xùn)練速度,同時(shí)也可以提高準(zhǔn)確性,這與其他超參數(shù)不同。
如果沒有多個(gè)GPU可用,可以采用梯度累積策略[5]來模擬較大的小批量。
雖然對于RNN并沒有改善結(jié)果,但對于Transformer來說,使用dropout是必不可少的,可以避免過擬合的問題。
我們嘗試了幾種數(shù)據(jù)增強(qiáng)方法[26],[27]。它們極大地改善了Transformer和RNN的性能。
對于RNN而言,最佳的解碼超參數(shù)γ和λ通常也適用于Transformer。
Transformer在解碼方面存在一些弱點(diǎn)。它比Kaldi系統(tǒng)要慢得多,這是因?yàn)樽宰⒁饬C(jī)制在樸素實(shí)現(xiàn)中的時(shí)間復(fù)雜度為,其中n是語音的長度。為了直接與基于DNN-HMM的ASR系統(tǒng)進(jìn)行性能比較,我們需要為Transformer開發(fā)一種更快的解碼算法。
8. 多語種ASR實(shí)驗(yàn)
這一部分在多語種設(shè)置中比較了RNN和Transformer在ASR性能上的表現(xiàn),考慮到Transformer在前一部分的單語種ASR任務(wù)中的成功。根據(jù)[46]的方法,我們準(zhǔn)備了10種不同的語言,包括WSJ(英語)、CSJ(日語)[30]、HKUST(普通話)[33]和VoxForge(德語、西班牙語、法語、意大利語、荷蘭語、葡萄牙語、俄語)。模型基于一個(gè)單一的多語種模型,其中參數(shù)在所有語言之間共享,輸出單元包括所有10種語言的字母(共計(jì)5,297個(gè)字母和特殊符號)。我們在RNN和Transformer上都使用了本節(jié)介紹的默認(rèn)設(shè)置,沒有使用RNNLM淺融合[21]。
圖3清楚地顯示出我們的Transformer在9種語言中明顯優(yōu)于我們的RNN。它在8種語言中實(shí)現(xiàn)了超過10%的相對改進(jìn),其中在VoxForge意大利語中的相對改進(jìn)最大,達(dá)到了28.0%。與[46]中使用了更深的BLSTM(7層)和RNNLM的RNN結(jié)果相比,我們的Transformer在9種語言中仍然提供了更優(yōu)秀的性能。從這個(gè)結(jié)果可以得出結(jié)論,Transformer在多語種端到端ASR中也優(yōu)于RNN。
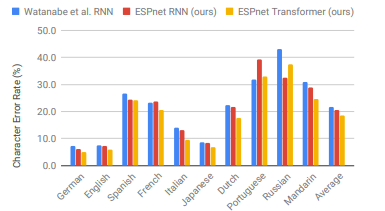
圖3 多語種端到端ASR與Watanabe等人的RNN[46]、ESPnet RNN和ESPnet Transformer的比較。
9. 語音翻譯實(shí)驗(yàn)
我們基線的端到端ST RNN基于[23],它與我們ASR系統(tǒng)中使用的RNN結(jié)構(gòu)類似,但我們沒有在原始論文中使用卷積LSTM層。我們的ST Transformer的配置與我們的ASR系統(tǒng)相同。
我們在Fisher-CALLHOME英西語語料庫[47]上進(jìn)行了語音翻譯實(shí)驗(yàn)。我們的Transformer將BLEU分?jǐn)?shù)從我們的RNN基準(zhǔn)值16.5提高到了17.2,應(yīng)用于CALLHOME的“evltest”數(shù)據(jù)集上。在訓(xùn)練Transformer時(shí),我們觀察到比RNN更嚴(yán)重的欠擬合問題。解決這個(gè)問題的方法是使用我們在ASR實(shí)驗(yàn)中使用的預(yù)訓(xùn)練編碼器,因?yàn)镾T數(shù)據(jù)集中包含了我們在ASR實(shí)驗(yàn)中使用的Fisher-CALLHOME西班牙語語料庫。
10. TTS實(shí)驗(yàn)
10.1 設(shè)置
我們的基準(zhǔn)線是基于RNN的TTS模型Tacotron 2 [15]。我們按照其模型和優(yōu)化器的設(shè)置進(jìn)行實(shí)驗(yàn)。我們重新使用現(xiàn)有的TTS配方,包括數(shù)據(jù)準(zhǔn)備和波形生成,這些配方我們已經(jīng)配置為最適合RNN。我們在第3節(jié)中介紹的Transformer配置如下:。兩個(gè)系統(tǒng)的輸入都是字符序列。
10.2 結(jié)果
我們使用兩個(gè)語料庫進(jìn)行了Transformer和基于RNN的TTS的比較:M-AILABS [48](意大利語,16 kHz,31小時(shí))和LJSpeech [49](英語,22 kHz,24小時(shí))。在M-AILABS的情況下,我們使用了一位意大利男性發(fā)音者(Riccardo)。圖4和圖5顯示了這兩個(gè)語料庫中的訓(xùn)練曲線。從這些圖中可以看出,Transformer和RNN在L1損失收斂方面提供了類似的結(jié)果。與ASR中觀察到的情況類似,我們發(fā)現(xiàn)較大的迷你批處理對于Transformer來說可以獲得更好的驗(yàn)證集L1損失和更快的訓(xùn)練速度,而對于RNN來說對L1損失會產(chǎn)生負(fù)面影響。我們還在圖6和 7中提供了生成的語音梅爾頻譜圖。我們得出結(jié)論,基于Transformer的TTS幾乎可以達(dá)到與基于RNN的TTS相同的性能水平。
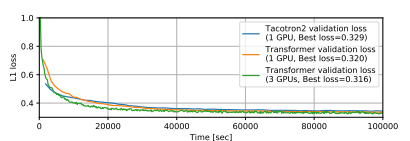
圖4 M-AILABS數(shù)據(jù)集上的TTS訓(xùn)練曲線。
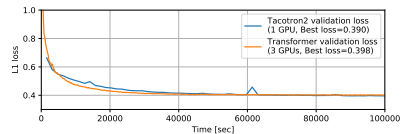
圖5 LJSpeech數(shù)據(jù)集上的TTS訓(xùn)練曲線。
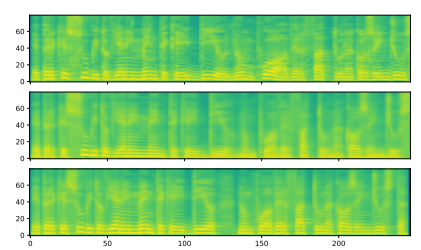
圖6 M-AILABs數(shù)據(jù)集上的梅爾頻譜圖樣本。(頂部) 真實(shí)值,(中間) Tacotron 2樣本,(底部) Transformer樣本。輸入文本為“E PERCHE SUBITO VIENE IN MENTE CHE 'IDDIO NON PUO AVER FATTO UNA COSA INGIUSTA”。
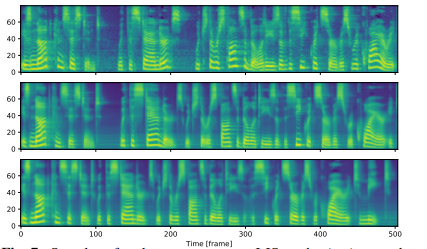
圖7 LJSpeech數(shù)據(jù)集上的梅爾頻譜圖樣本。(頂部) 真實(shí)值,(中間) Tacotron 2樣本,(底部) Transformer樣本。輸入文本為“IS NOT CONSISTENT WITH THE STANDARDS WHICH THE RESPONSIBILITIES OF THE SECRET SERVICE REQUIRE IT TO MEET.”
10.3 討論
我們在TTS中訓(xùn)練Transformer的經(jīng)驗(yàn)教訓(xùn)如下:
如果有大量的GPU可用,使用大批量訓(xùn)練可以加快TTS的訓(xùn)練速度,就像在ASR中一樣。
對于Transformer,驗(yàn)證損失值,特別是BCE損失,更容易出現(xiàn)過擬合。我們建議在檢查其收斂性時(shí)監(jiān)控注意力圖而不是損失值。
在Transformer中,注意力圖的某些頭部并不總是像Tacotron 2中那樣是對角線的。因此,我們需要選擇在哪些位置應(yīng)用引導(dǎo)性注意力損失[24]。-使用Transformer進(jìn)行解碼的速度也比使用RNN慢(每幀6.5毫秒 vs 單線程CPU上每幀78.5毫秒)。我們還嘗試了FastSpeech [50],它實(shí)現(xiàn)了基于Transformer的非自回歸TTS。它極大地提高了解碼速度(每幀0.6毫秒,單線程CPU上),并生成了與自回歸Transformer相媲美的語音質(zhì)量。-在Transformer中,引入的減少因子[51]也是有效的。它可以極大地減少訓(xùn)練和推理時(shí)間,但會稍微降低質(zhì)量。
未來的工作,我們需要進(jìn)一步研究訓(xùn)練速度和質(zhì)量之間的權(quán)衡,并引入ASR技術(shù)(例如數(shù)據(jù)增強(qiáng)、語音增強(qiáng))來改進(jìn)TTS系統(tǒng)。
11. 總結(jié)
我們在語音應(yīng)用中對Transformer和RNN進(jìn)行了比較性研究,使用了各種語料庫,包括ASR(15個(gè)單語種+一個(gè)多語種)、ST(一個(gè)語料庫)和TTS(兩個(gè)語料庫)。在這些任務(wù)的實(shí)驗(yàn)中,我們?nèi)〉昧肆钊似诖慕Y(jié)果,包括在許多ASR任務(wù)中的巨大改進(jìn),并解釋了我們?nèi)绾胃倪M(jìn)模型。我們相信本文中描述的可重現(xiàn)的配方、預(yù)訓(xùn)練模型和訓(xùn)練技巧將加速Transformer在語音應(yīng)用中的研究方向。
編輯:黃飛










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論