 電子發(fā)燒友App
電子發(fā)燒友App


目前看到的最通俗易懂、由淺入深的圖解機(jī)器學(xué)習(xí)和GPT原理的系列文章,這是第一篇,由我和 GPT-4共同翻譯完成,分享給大家。
原作者:@JayAlammar 翻譯:成江東
我不是一個(gè)機(jī)器學(xué)習(xí)專家,本來(lái)是一名軟件工程師,與人工智能的互動(dòng)很少。我一直渴望深入了解機(jī)器學(xué)習(xí),但一直沒(méi)有找到適合自己的入門方式。這就是為什么,當(dāng)谷歌在2015年11月開(kāi)源TensorFlow時(shí),我非常興奮,知道是時(shí)候開(kāi)始學(xué)習(xí)之旅了。不想過(guò)于夸張,但對(duì)我來(lái)說(shuō),這就像是普羅米修斯從機(jī)器學(xué)習(xí)的奧林匹斯山上將火種贈(zèng)予人類。在我腦海中,整個(gè)大數(shù)據(jù)領(lǐng)域,以及像Hadoop這樣的技術(shù),都得到了極大的加速,當(dāng)谷歌研究人員發(fā)布他們的Map Reduce論文時(shí)。這一次不僅是論文,而是實(shí)際的軟件,是他們?cè)诙嗄甑陌l(fā)展之后所使用的內(nèi)部工具。
因此,我開(kāi)始學(xué)習(xí)機(jī)器學(xué)習(xí)基礎(chǔ)知識(shí),發(fā)現(xiàn)初學(xué)者需要更通俗易懂的資源。這是我嘗試提供的。
從這里開(kāi)始
讓我們從一個(gè)簡(jiǎn)單的例子開(kāi)始。假設(shè)你正在幫助一個(gè)想買房子的朋友。她被報(bào)價(jià)40萬(wàn)美元購(gòu)買一個(gè)2000平方英尺(185平方米)的房子。這個(gè)價(jià)格合適嗎?在沒(méi)有參照物的情況下,這很難判斷。所以你詢問(wèn)了在同一個(gè)社區(qū)購(gòu)買過(guò)房子的朋友們,最后得到了三個(gè)數(shù)據(jù)點(diǎn):
面積(平方英尺)(x) 價(jià)格(y)
2,104 ???????????????????????????399,900
1,600 ???????????????????????????329,900
2,400 ???????????????????????????369,000
就我個(gè)人而言,我的第一反應(yīng)是計(jì)算每平方英尺的平均價(jià)格。這個(gè)價(jià)格是每平方英尺180美元。
歡迎來(lái)到你的第一個(gè)神經(jīng)網(wǎng)絡(luò)!雖然它還沒(méi)有達(dá)到Siri的水平,但現(xiàn)在你已經(jīng)了解了基本的構(gòu)建模塊。它看起來(lái)是這樣的:
這樣的圖表展示了網(wǎng)絡(luò)的結(jié)構(gòu)以及如何計(jì)算預(yù)測(cè)。計(jì)算從左側(cè)的輸入節(jié)點(diǎn)開(kāi)始。輸入值向右流動(dòng)。它乘以權(quán)重,結(jié)果就成為我們的輸出。將2,000平方英尺乘以180,我們得到360,000美元。在這個(gè)層面上,計(jì)算預(yù)測(cè)就是簡(jiǎn)單的乘法。但在此之前,我們需要考慮我們將要乘以的權(quán)重。這里我們從平均值開(kāi)始,稍后我們將研究更好的算法,以便在獲得更多輸入和更復(fù)雜模型時(shí)進(jìn)行擴(kuò)展。找到權(quán)重就是我們的“訓(xùn)練”階段。所以,每當(dāng)你聽(tīng)到有人在“訓(xùn)練”神經(jīng)網(wǎng)絡(luò)時(shí),它只是指找到我們用來(lái)計(jì)算預(yù)測(cè)的權(quán)重。
這是一個(gè)簡(jiǎn)單的預(yù)測(cè)模型,它接受輸入,進(jìn)行計(jì)算,并給出輸出(由于輸出可以是連續(xù)值,我們所擁有的技術(shù)名稱是“回歸模型”)
注:回歸模型是一種用于預(yù)測(cè)因果關(guān)系的統(tǒng)計(jì)模型,它通常用于研究與某些因素有關(guān)的連續(xù)變量。它基于已知數(shù)據(jù)的線性或非線性方程,通過(guò)最小化誤差或損失函數(shù)來(lái)擬合數(shù)據(jù),并通過(guò)該方程對(duì)未知數(shù)據(jù)進(jìn)行預(yù)測(cè)。回歸模型可以用于分析多種因素對(duì)某一變量的影響,例如在經(jīng)濟(jì)學(xué)、社會(huì)學(xué)、醫(yī)學(xué)、工程學(xué)等領(lǐng)域中,它經(jīng)常被用于探索因果關(guān)系和預(yù)測(cè)未來(lái)趨勢(shì)。常見(jiàn)的回歸模型包括線性回歸、多項(xiàng)式回歸、邏輯回歸等。
讓我們將這個(gè)過(guò)程可視化(為了簡(jiǎn)化,讓我們將價(jià)格單位從1美元換成1000美元。現(xiàn)在我們的權(quán)重是0.180而不是180):
更難、更好、更快、更強(qiáng)
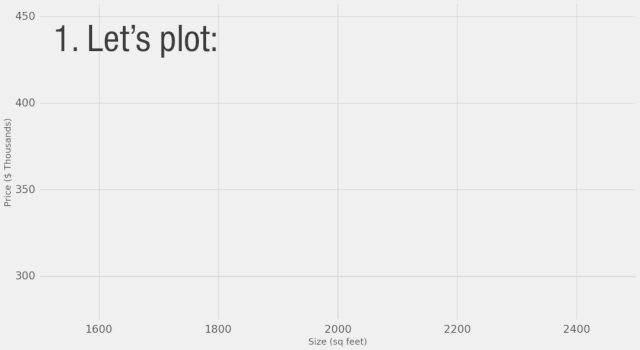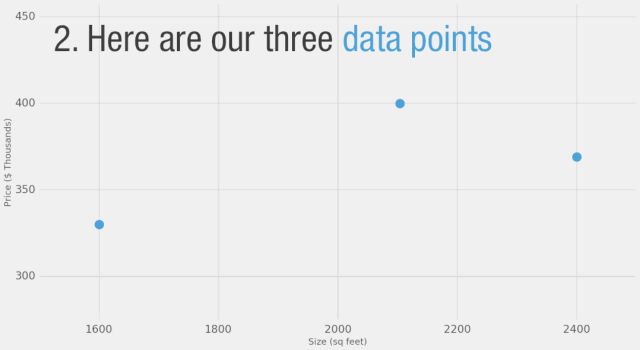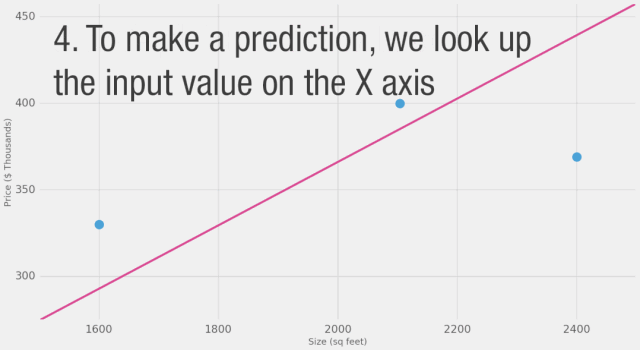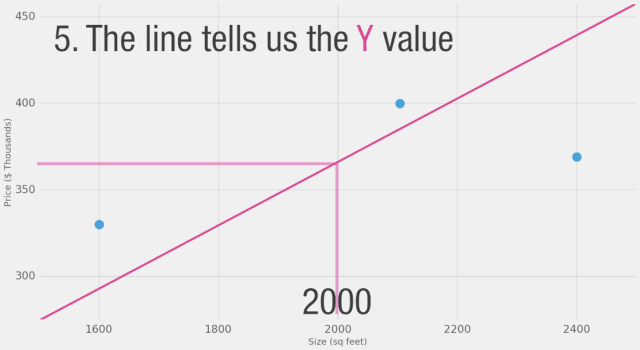
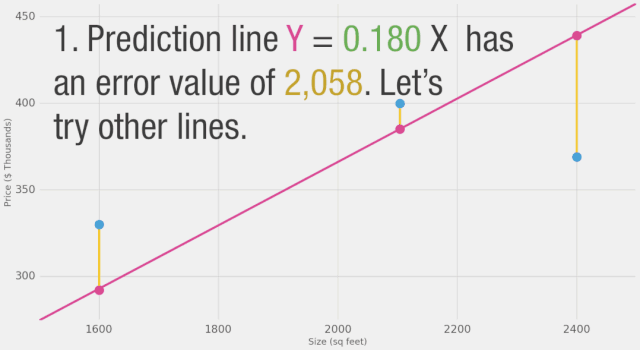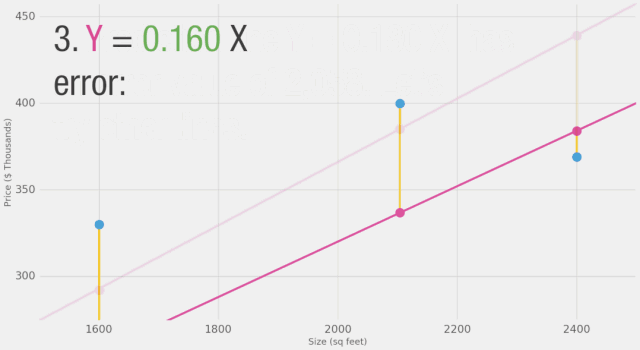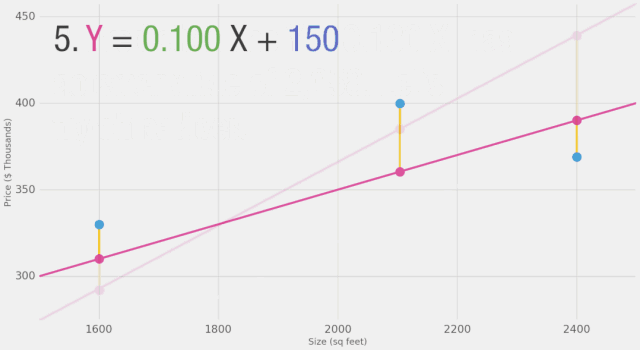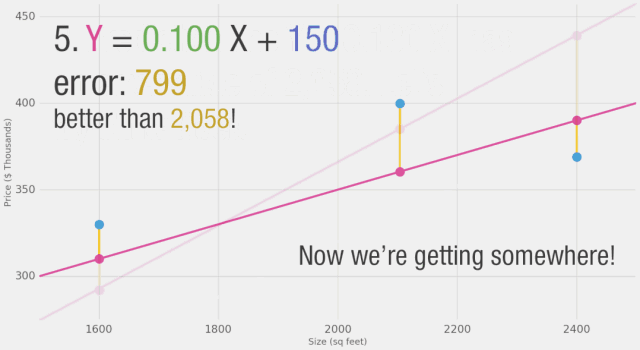
我們能否在估計(jì)價(jià)格方面做得比基于數(shù)據(jù)點(diǎn)平均值更好呢?讓我們?cè)囋嚒J紫龋屛覀兌x在這種情況下更好的意義。如果我們將模型應(yīng)用于我們擁有的三個(gè)數(shù)據(jù)點(diǎn),它會(huì)做得多好?
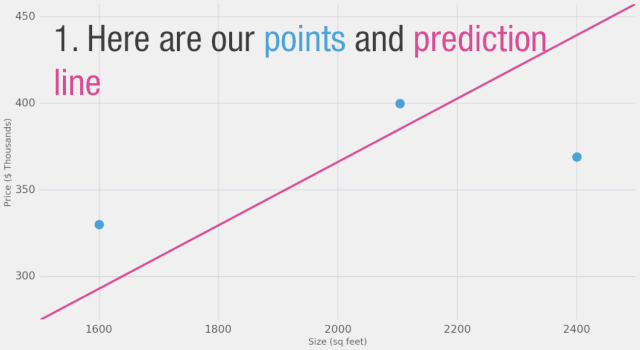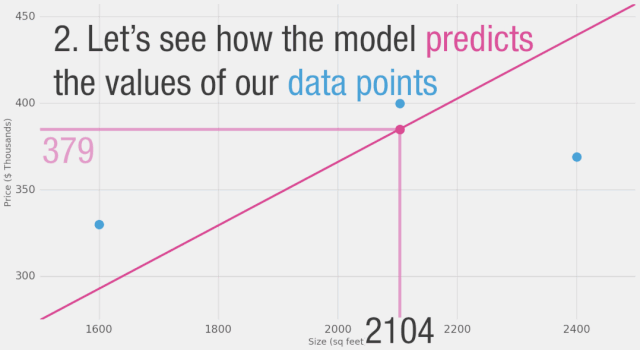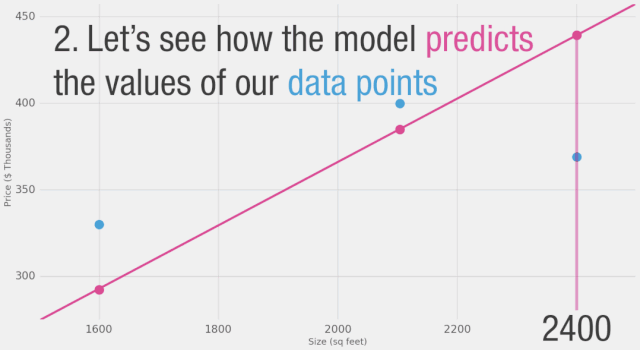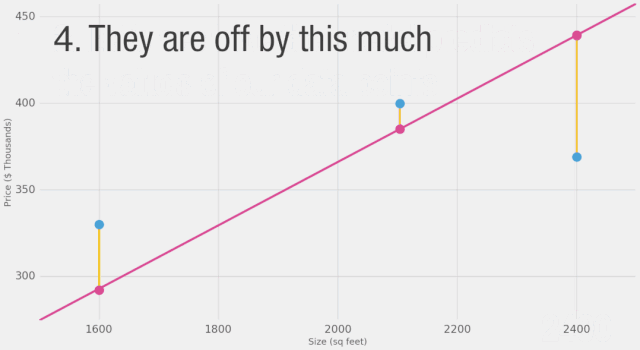
如圖所示,黃線是誤差值,黃線長(zhǎng)是不好的,我們希望盡可能減小黃線的長(zhǎng)度。
面積?(x) 價(jià)格?($1000)?(y_) 預(yù)測(cè)值?(y) y_-y (y_-y)2
2,104 ????399.9 ????????????379 ????????????????21 ?????449
1,600 ????329.9 ????????????288 ????????????????42 ????1756
2,400 ????369 ????????????? ?432 ????????????????-63 ???3969
平均值:2,058
在這里,我們可以看到實(shí)際價(jià)格值、預(yù)測(cè)價(jià)格值以及它們之間的差異。然后我們需要對(duì)這些差異求平均,以便得到一個(gè)表示預(yù)測(cè)模型中有多少錯(cuò)誤的數(shù)字。問(wèn)題是,第3行的值為-63。如果我們想用預(yù)測(cè)值和價(jià)格之間的差異作為衡量誤差的標(biāo)準(zhǔn),我們必須處理這個(gè)負(fù)值。這就是為什么我們引入了一個(gè)額外的列,顯示誤差的平方,從而消除了負(fù)值。這就是我們定義更好模型的標(biāo)準(zhǔn)?-?更好的模型是誤差較小的模型。誤差是數(shù)據(jù)集中每個(gè)點(diǎn)誤差的平均值。對(duì)于每個(gè)點(diǎn),誤差是實(shí)際值和預(yù)測(cè)值之間的差異的平方。這稱為均方誤差。將其作為指導(dǎo)來(lái)訓(xùn)練我們的模型使其成為我們的損失函數(shù)(也稱為成本函數(shù))。

現(xiàn)在我們已經(jīng)定義了衡量更好模型的標(biāo)準(zhǔn),讓我們嘗試一些其它權(quán)重值,并將它們與我們的平均值進(jìn)行比較:
通過(guò)改變權(quán)重,我們無(wú)法在模型上做出太多改進(jìn)。但是,如果我們添加一個(gè)偏置值,我們可以找到改進(jìn)模型的值。現(xiàn)在我們添加了這個(gè)b值到線性公式中,我們的預(yù)測(cè)值可以更好地逼近我們的實(shí)際值。在這種情境下,我們稱之為“偏置”。這使得我們的神經(jīng)網(wǎng)絡(luò)看起來(lái)像這樣:
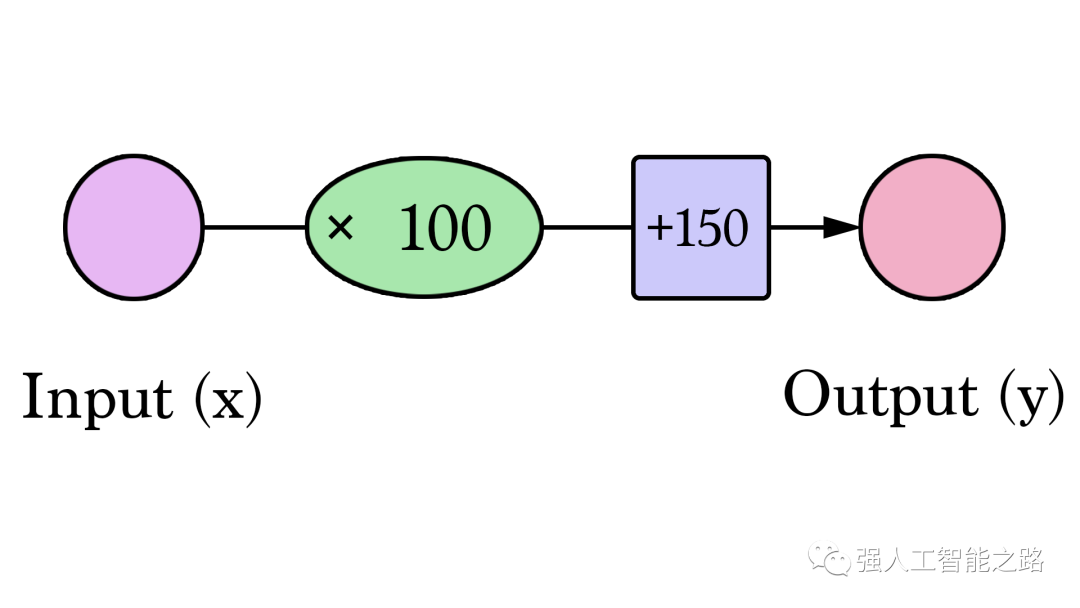
我們可以概括地說(shuō),一個(gè)具有一個(gè)輸入和一個(gè)輸出的神經(jīng)網(wǎng)絡(luò)(劇透警告:沒(méi)有隱藏層)看起來(lái)像這樣:
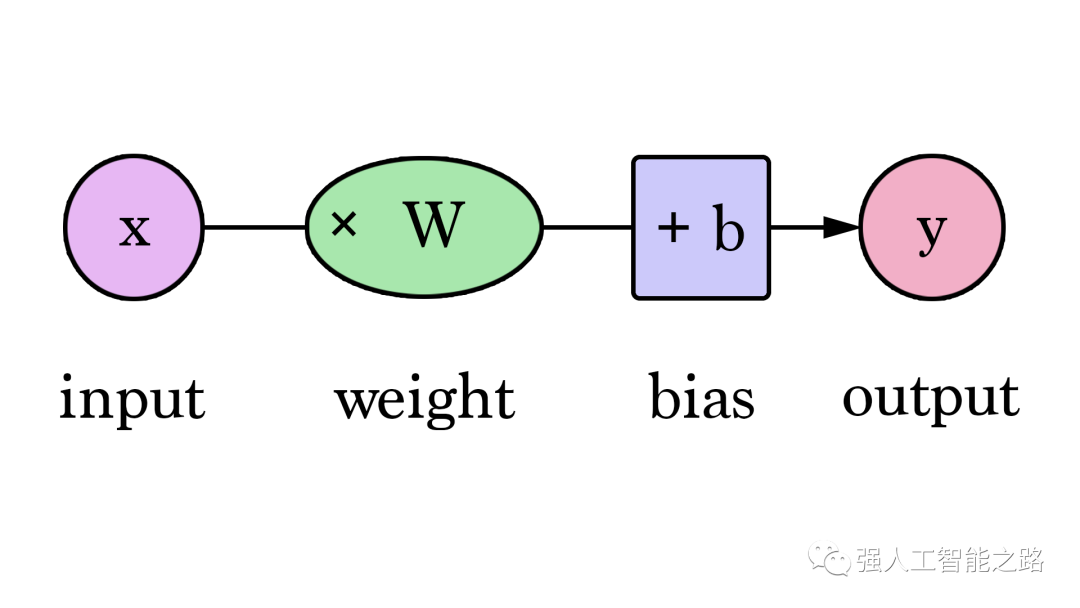
在這個(gè)圖中,W 和 b 是我們?cè)谟?xùn)練過(guò)程中找到的值,X 是我們輸入到公式中的值(例如,我們的示例中的房屋面積(平方英尺))。Y 是預(yù)測(cè)的價(jià)格。現(xiàn)在,計(jì)算預(yù)測(cè)使用這個(gè)公式:
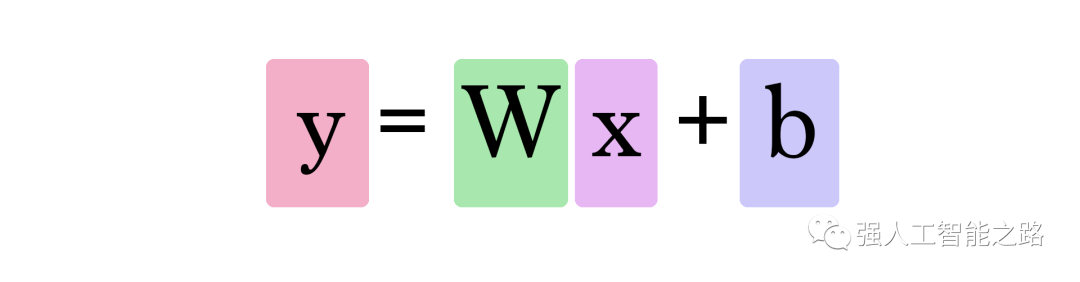
因此,我們當(dāng)前的模型通過(guò)將房屋面積作為 x 插入,使用這個(gè)公式來(lái)計(jì)算預(yù)測(cè):
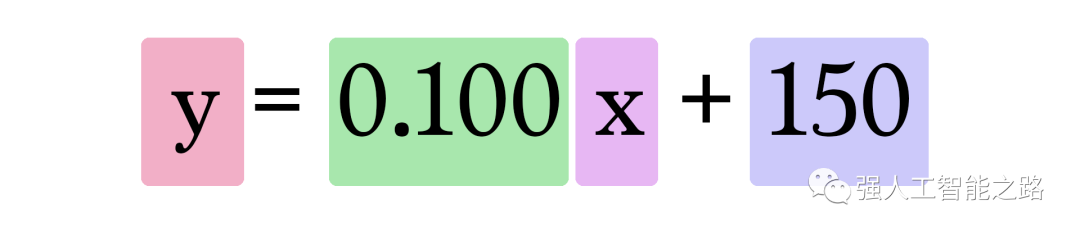
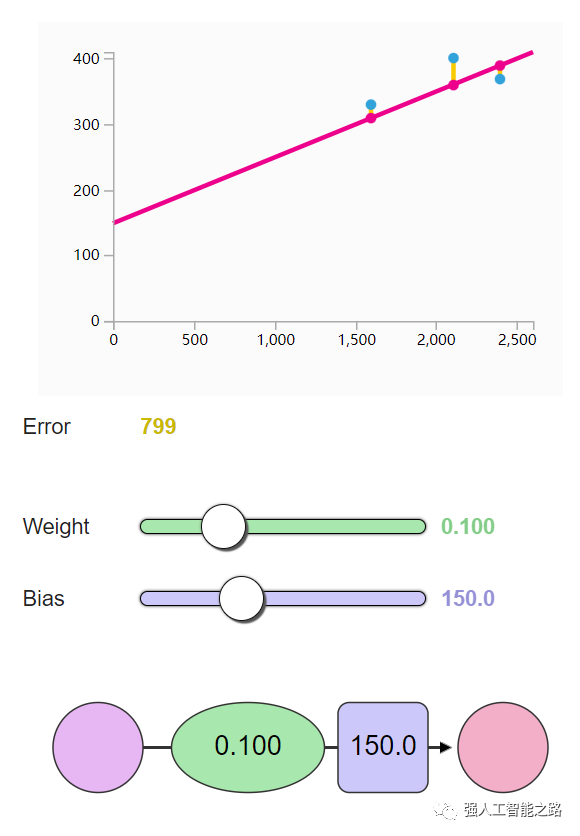
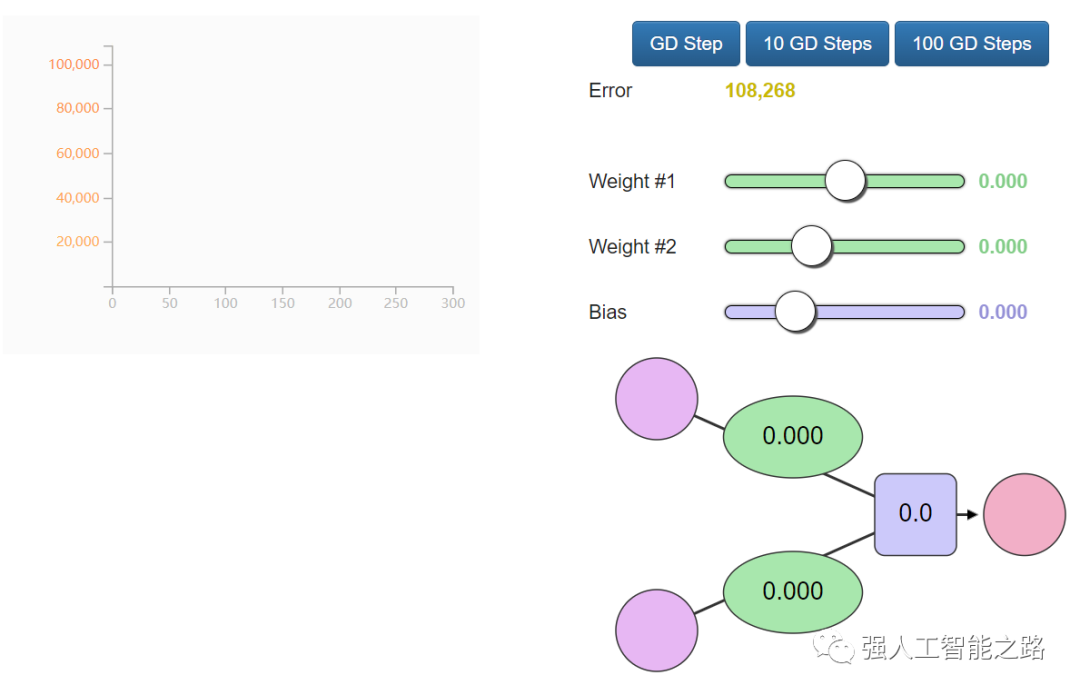
訓(xùn)練? 你想嘗試訓(xùn)練我們的玩具神經(jīng)網(wǎng)絡(luò)嗎?通過(guò)調(diào)整權(quán)重和偏置來(lái)最小化損失函數(shù)。你能讓誤差值低于799嗎?
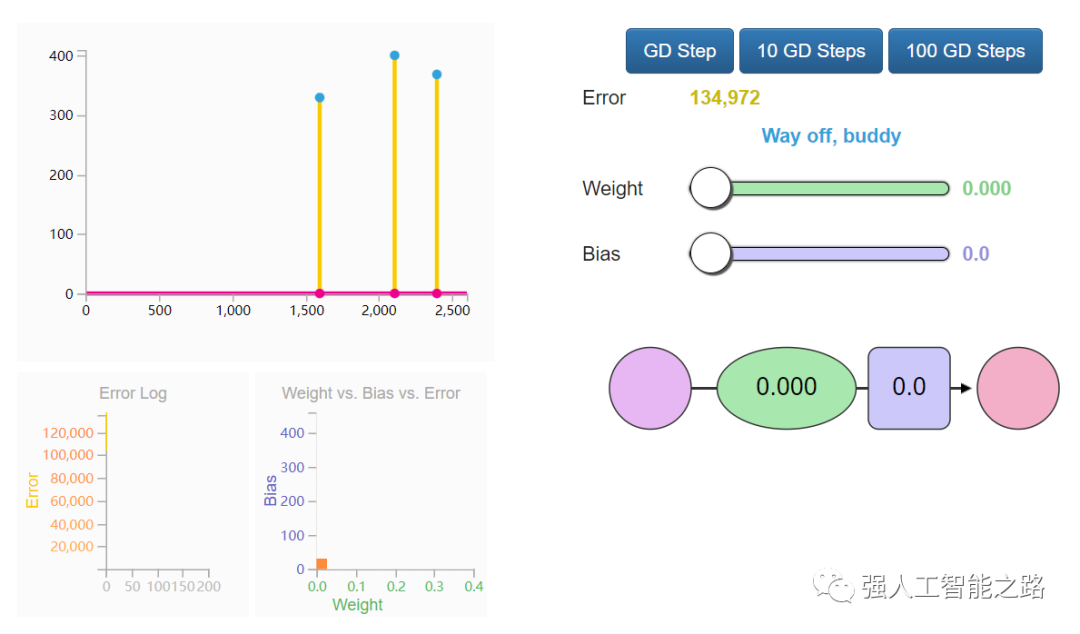
自動(dòng)化?恭喜你手動(dòng)訓(xùn)練了你的第一個(gè)神經(jīng)網(wǎng)絡(luò)!讓我們看看如何自動(dòng)化這個(gè)訓(xùn)練過(guò)程。下面是另一個(gè)帶有自動(dòng)駕駛功能的示例。這些是 GD Step 按鈕。它們使用一種稱為“梯度下降”的算法,嘗試向正確的權(quán)重和偏置值邁進(jìn),以最小化損失函數(shù)。
?

這兩個(gè)新圖表可以幫助你在調(diào)整模型參數(shù)(權(quán)重和偏置)時(shí)跟蹤誤差值。跟蹤誤差非常重要,因?yàn)橛?xùn)練過(guò)程就是盡可能減少這個(gè)誤差。梯度下降如何知道它的下一步應(yīng)該在哪里?可以利用微積分。你看,我們知道我們要最小化的函數(shù)(損失函數(shù),所有數(shù)據(jù)點(diǎn)的(y_?- y)2的平均值),也知道當(dāng)前輸入的值(當(dāng)前的權(quán)重和偏置),損失函數(shù)的導(dǎo)數(shù)告訴我們應(yīng)該如何調(diào)整 W 和 b 以最小化誤差。想了解更多關(guān)于梯度下降以及如何使用它來(lái)計(jì)算新的權(quán)重和偏置的信息,請(qǐng)觀看 Coursera 機(jī)器學(xué)習(xí)課程的第一講。
引入第二變量
房子的大小是決定房?jī)r(jià)的唯一變量嗎?顯然還有很多其他因素。讓我們添加另一個(gè)變量,看看我們?nèi)绾握{(diào)整神經(jīng)網(wǎng)絡(luò)來(lái)適應(yīng)它。假設(shè)你的朋友做了更多的研究,找到了更多的數(shù)據(jù)點(diǎn)。她還發(fā)現(xiàn)了每個(gè)房子有多少個(gè)浴室:
面積(平方英尺)浴室數(shù)量?價(jià)格
2,104 ????????????????? 3 ???????????399,900
1,600 ????????????????? 3 ????????? ?329,900
2,400 ????????????????? 3? ? ? ? ? ? 369,000
1,416 ??????????????????2 ???????????232,000
3,000 ??????????????????4 ????????? ?539,900
1,985 ????????????????? 4? ? ? ? ? ? 299,900
1,534 ????????????? ? ? 3? ? ? ? ? ? 314,900
1,427????????????????? ?3? ? ? ? ? ? 198,999
1,380 ????????????? ? ? 3? ? ? ? ? ? 212,000
1,494 ????????????????? 3? ? ? ? ? ? 242,500
我們的兩變量神經(jīng)網(wǎng)絡(luò)如下所示:
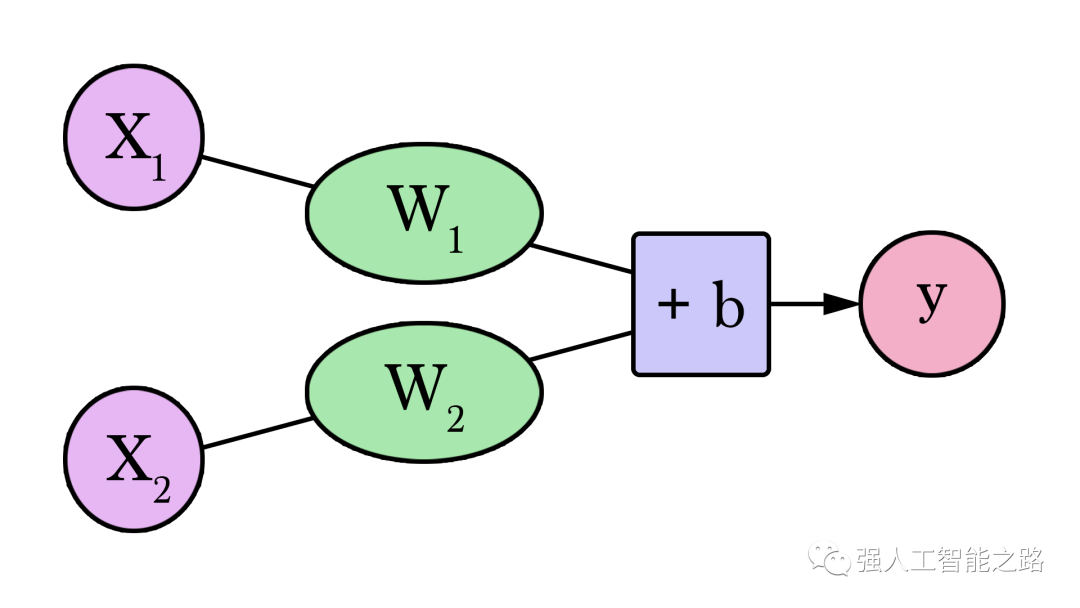
現(xiàn)在我們需要找到兩個(gè)權(quán)重(每個(gè)輸入一個(gè))和一個(gè)偏置來(lái)創(chuàng)建我們的新模型。計(jì)算Y的公式如下:
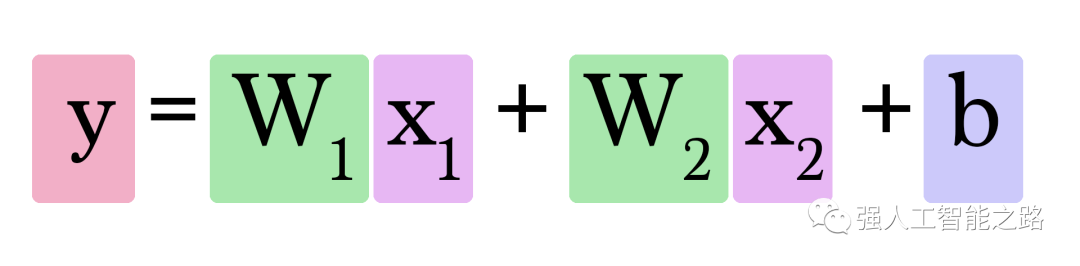
但是我們?nèi)绾握业絯1和w2呢?這比我們只需要考慮一個(gè)權(quán)重值時(shí)要復(fù)雜一些。多一個(gè)浴室對(duì)我們預(yù)測(cè)房?jī)r(jià)的影響有多大呢?嘗試找到合適的權(quán)重和偏置。從這里開(kāi)始,你會(huì)看到隨著輸入數(shù)量的增加,我們面臨的復(fù)雜性也在增加。我們開(kāi)始失去創(chuàng)建簡(jiǎn)單二維形狀的能力,這使得我們不能一眼就能看出模型的特點(diǎn)。相反,我們主要依賴于在調(diào)整模型參數(shù)時(shí),誤差值是如何變化的。
我們?cè)俅我揽靠煽康奶荻认陆捣▉?lái)幫助我們找到合適的權(quán)重和偏置。
特征
現(xiàn)在你已經(jīng)了解了具有一個(gè)和兩個(gè)特征的神經(jīng)網(wǎng)絡(luò),你可以嘗試添加更多特征并使用它們來(lái)計(jì)算預(yù)測(cè)值。權(quán)重的數(shù)量將繼續(xù)增長(zhǎng),當(dāng)我們添加每個(gè)新特征時(shí),我們需要調(diào)整梯度下降的實(shí)現(xiàn),以便它能夠更新與新特征相關(guān)的新權(quán)重。這里需要注意的是,我們不能盲目地將我們所知道的所有信息都輸入到網(wǎng)絡(luò)中。我們必須在輸入模型的特征上有所選擇。特征選擇/處理是一個(gè)擁有自己一套最佳實(shí)踐和注意事項(xiàng)的獨(dú)立學(xué)科。如果你想看一個(gè)關(guān)于檢查數(shù)據(jù)集以選擇輸入預(yù)測(cè)模型的特征的過(guò)程的例子,請(qǐng)查看《泰坦尼克號(hào)之旅》。這是一個(gè)筆記本,Omar EL Gabry在其中講述了他解決Kaggle泰坦尼克挑戰(zhàn)的過(guò)程。Kaggle提供了泰坦尼克號(hào)上乘客的名單,包括姓名、性別、年齡、船艙以及該人是否幸存等數(shù)據(jù)。挑戰(zhàn)的目標(biāo)是建立一個(gè)模型,根據(jù)其他信息預(yù)測(cè)一個(gè)人是否幸存。
分類
讓我們繼續(xù)調(diào)整我們的例子。假設(shè)你的朋友給你一份房子清單。這次,她標(biāo)注了哪些房子在她看來(lái)具有合適的大小和浴室數(shù)量:
面積(平方英尺)浴室數(shù)量 標(biāo)簽
2,104 ????????????????? 3 ????????? ?Good
1,600 ????????????????? 3? ? ? ? ? ? Good
2,400 ????????????????? 3 ???????????Good
1,416 ????????????????? 2 ???????????Bad
3,000 ??????????????????4 ???????????Bad
1,985 ????????????????? 4 ???????????Good
1,534 ????????????????? 3 ???????????Bad
1,427 ????????????????? 3 ???????????Good
1,380 ??????????????????3? ? ? ? ? ? Good
1,494 ????????????? ? ? 3 ????????? ?Good
她需要你使用這個(gè)方法來(lái)創(chuàng)建一個(gè)模型,根據(jù)房子的大小和浴室數(shù)量來(lái)預(yù)測(cè)她是否會(huì)喜歡這個(gè)房子。你將使用上面的列表來(lái)構(gòu)建模型,然后她將使用這個(gè)模型來(lái)對(duì)許多其他房子進(jìn)行分類。在這個(gè)過(guò)程中還有一個(gè)額外的改變,那就是她還有另一個(gè)包含10個(gè)房子的列表,她已經(jīng)對(duì)這些房子進(jìn)行了標(biāo)記,但她沒(méi)有告訴你。這個(gè)另外的列表將在你訓(xùn)練模型后用來(lái)評(píng)估你的模型,從而確保你的模型能夠把握她實(shí)際喜歡的房子特征。我們迄今為止所嘗試的神經(jīng)網(wǎng)絡(luò)都是進(jìn)行“回歸”操作的,它們計(jì)算并輸出一個(gè)“連續(xù)”的值(輸出可以是4,或100.6,或2143.342343)。然而,在實(shí)踐中,神經(jīng)網(wǎng)絡(luò)更常用于“分類”類型的問(wèn)題。在這些問(wèn)題中,神經(jīng)網(wǎng)絡(luò)的輸出必須是一組離散值(或“類別”),如“好”或“壞”。實(shí)踐中的工作原理是,我們將會(huì)得到一個(gè)模型,該模型會(huì)表明某個(gè)房屋是“好”的可能性為75%,而不僅是簡(jiǎn)單地輸出“好”或“壞”。
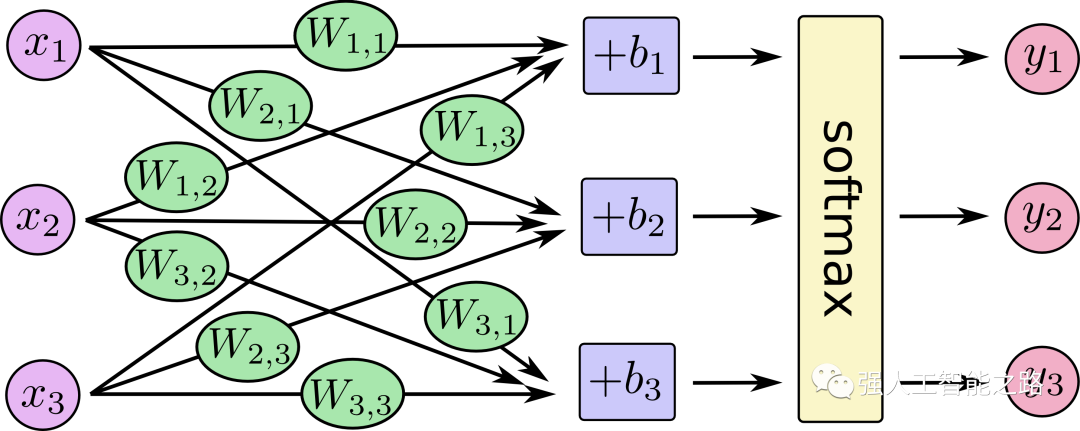
在實(shí)踐中,我們可以將我們已經(jīng)看到的網(wǎng)絡(luò)轉(zhuǎn)換成一個(gè)分類網(wǎng)絡(luò),讓它輸出兩個(gè)值——一個(gè)值代表某個(gè)個(gè)類別(我們現(xiàn)在的類別是“好”和“壞”)。然后我們將這些值通過(guò)一個(gè)叫做“softmax”的操作。softmax的輸出是每個(gè)類別的概率。例如,假設(shè)網(wǎng)絡(luò)的這一層輸出“好”為2,“壞”為4,如果我們將[2, 4]輸入到softmax中,它將返回[0.11, 0.88]作為輸出。這意味著網(wǎng)絡(luò)有88%的把握認(rèn)為輸入的值是“壞”的,我們的朋友可能不喜歡那個(gè)房子。
Softmax函數(shù)接受一個(gè)數(shù)組作為輸入,并輸出一個(gè)相同長(zhǎng)度的數(shù)組。注意到它的輸出都是正數(shù),并且總和為1,這在輸出概率值時(shí)非常有用。另外,盡管4是2的兩倍,但它的概率不僅是2的兩倍,而且是2的八倍。這是一個(gè)有用的特性,它可以夸大輸出之間的差異,從而改善我們的訓(xùn)練過(guò)程。

如您在最后兩行中所看到的,softmax可以擴(kuò)展到任意數(shù)量的輸入。所以現(xiàn)在如果我們的朋友添加了第三個(gè)標(biāo)簽(比如說(shuō)“不錯(cuò),但我得把一間房子租給airbnb”),softmax可以擴(kuò)展以適應(yīng)這種變化。花點(diǎn)時(shí)間探索一下網(wǎng)絡(luò)的形狀,看看當(dāng)您改變特征數(shù)量(x1、x2、x3等)(可以是面積、浴室數(shù)量、價(jià)格、靠近學(xué)校/工作的距離等)和類別數(shù)量(y1、y2、y3等)(可以是“太貴了”、“性價(jià)比高”、“如果我把一間房子租給airbnb就好了”、“太小了”)時(shí),網(wǎng)絡(luò)是如何變化的。
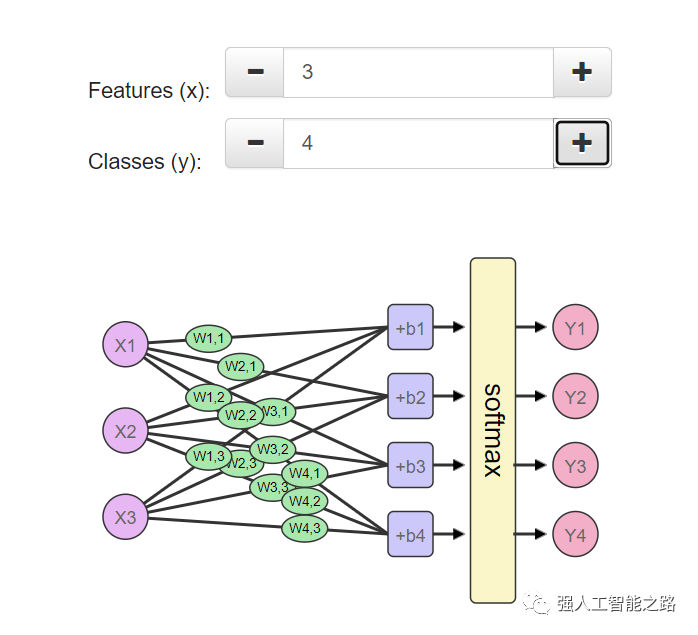
您可以在我為本文創(chuàng)建的這個(gè)筆記本中看到如何使用 TensorFlow 創(chuàng)建和訓(xùn)練這個(gè)網(wǎng)絡(luò)的示例。真正的動(dòng)力?如果您已經(jīng)讀到這里了,我必須向您揭示我寫(xiě)這篇文章的另一個(gè)動(dòng)力。這篇文章旨在作為一個(gè)更加溫和的 TensorFlow 教程入門。如果您現(xiàn)在開(kāi)始學(xué)習(xí)《MNIST 機(jī)器學(xué)習(xí)初學(xué)者》,并遇到了這張圖:
我寫(xiě)這篇文章是為了讓沒(méi)有機(jī)器學(xué)習(xí)經(jīng)驗(yàn)的人們?yōu)?TensorFlow 入門教程中的這張圖做好準(zhǔn)備。這就是為什么我模擬了它的視覺(jué)風(fēng)格。我希望您會(huì)覺(jué)得準(zhǔn)備充分,并且了解這個(gè)系統(tǒng)以及它的工作原理。如果您想開(kāi)始嘗試編寫(xiě)代碼,請(qǐng)隨時(shí)從入門教程開(kāi)始,它教一個(gè)神經(jīng)網(wǎng)絡(luò)如何識(shí)別手寫(xiě)數(shù)字。您還應(yīng)該通過(guò)學(xué)習(xí)我們?cè)谶@里討論的概念的理論和數(shù)學(xué)基礎(chǔ)來(lái)繼續(xù)您的學(xué)習(xí)。現(xiàn)在可以提出的好問(wèn)題包括:
其他類型的損失函數(shù)有哪些?
哪些損失函數(shù)更適用于哪些應(yīng)用?
使用梯度下降實(shí)際計(jì)算新權(quán)重的算法是什么?
在您已經(jīng)了解的領(lǐng)域中,機(jī)器學(xué)習(xí)的應(yīng)用有哪些?
通過(guò)將這個(gè)技能與您技能庫(kù)中的其他技能相結(jié)合,您可以創(chuàng)造出什么新奇的魔法?
以下是一些很好的學(xué)習(xí)資源:
Coursera上的機(jī)器學(xué)習(xí)課程,由Andrew Ng主講。這是我開(kāi)始學(xué)習(xí)的課程。從回歸開(kāi)始,然后轉(zhuǎn)向分類和神經(jīng)網(wǎng)絡(luò)。
Coursera上的神經(jīng)網(wǎng)絡(luò)與機(jī)器學(xué)習(xí)課程,由Geoffrey Hinton主講。更側(cè)重于神經(jīng)網(wǎng)絡(luò)及其視覺(jué)應(yīng)用。
斯坦福大學(xué)的CS231n課程:卷積神經(jīng)網(wǎng)絡(luò)與視覺(jué)識(shí)別,由Andrej Karpathy主講。了解一些高級(jí)概念以及使用深度神經(jīng)網(wǎng)絡(luò)進(jìn)行視覺(jué)識(shí)別的最新技術(shù)。
神經(jīng)網(wǎng)絡(luò)社區(qū)是一個(gè)很好的資源,可以了解不同類型的神經(jīng)網(wǎng)絡(luò)。
致謝:
感謝Yasmine Alfouzan、Ammar Alammar、Khalid Alnuaim、Fahad Alhazmi、Mazen Melibari和Hadeel Al-Negheimish在審查本文的早期版本時(shí)提供的幫助。如有任何更正或反饋,請(qǐng)?jiān)赥witter上聯(lián)系我。
編輯:黃飛
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論