 電子發(fā)燒友App
電子發(fā)燒友App


近年來,神經(jīng)網(wǎng)絡(luò)模型規(guī)模呈指數(shù)級增長,從2018年擁有超1億參數(shù)的Bert到2020年擁有1750億個參數(shù)GPT-3,短短兩年模型的參數(shù)量增加了3個數(shù)量級,而且這種增長還看不到盡頭。? 人們剛剛開始發(fā)掘神經(jīng)網(wǎng)絡(luò)的應(yīng)用潛力,但傳統(tǒng)的訓(xùn)練和推理方式已然無法跟上神經(jīng)網(wǎng)絡(luò)規(guī)模的飛速增長速度,無法滿足大規(guī)模機器學(xué)習(xí)所需的內(nèi)存和算力需求。為此,國內(nèi)外諸多創(chuàng)業(yè)公司尋求對軟硬件等進行實質(zhì)性的底層技術(shù)革新來解決這一挑戰(zhàn)。 作為業(yè)內(nèi)備受關(guān)注的AI加速器創(chuàng)業(yè)公司,成立于2016年的Cerebras希望通過構(gòu)建全新AI加速器方案解決AI計算問題,以實現(xiàn)數(shù)量級計算性能:首先,需要改進計算核心架構(gòu),而不只是一味地提升每秒浮點運算次數(shù);其次,需要以超越摩爾定律的速度提高芯片集成度;最后,還要簡化集群連接,大幅度提升集群計算效率。 為了實現(xiàn)上述目標(biāo),Cerebras設(shè)計了一種新的計算核心架構(gòu)。它讓單臺設(shè)備運行超大規(guī)模模型成為可能,此外,它開發(fā)出只需簡單數(shù)據(jù)并行的橫向擴展和本地非結(jié)構(gòu)化稀疏加速技術(shù),使大模型的應(yīng)用門檻大幅降低。

圖1:近年來各SOTA神經(jīng)網(wǎng)絡(luò)模型的內(nèi)存與算力需求 2021年,Cerebras曾推出全球最大AI芯片Wafer Scale Engine 2(WSE-2),面積是46225平方毫米,采用7nm工藝,擁有2.6萬億個晶體管和85萬個AI優(yōu)化核,還推出了世界上第一個人類大腦規(guī)模的AI解決方案CS-2 AI計算機,可支持超過120萬億參數(shù)規(guī)模的訓(xùn)練。今年6月,它又在基于單個WSE-2芯片的CS-2系統(tǒng)上訓(xùn)練了世界上最大的擁有200億參數(shù)的NLP模型,顯著降低了原本需要數(shù)千個GPU訓(xùn)練的成本。? 在近期舉辦的Hot Chips大會上,Cerebras聯(lián)合創(chuàng)始人&首席硬件架構(gòu)師Sean Lie深入介紹了Cerebras硬件,展示了他們在核心架構(gòu)、縱向擴展和橫向擴展方面的創(chuàng)新方法。以下是他的演講內(nèi)容,由OneFlow社區(qū)編譯。?
01?Cerebras計算核心架構(gòu)
計算核心(compute core)是所有計算機架構(gòu)的“心臟”,而Cerebras針對神經(jīng)網(wǎng)絡(luò)的細(xì)粒度動態(tài)稀疏性重新設(shè)計了計算核心。
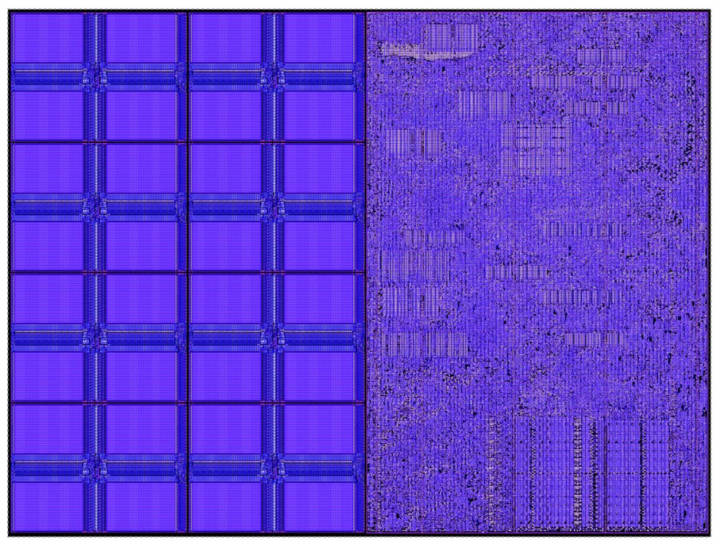
圖2:Cerebras計算核心 圖2是一款小型核心,它只有38,000平方微米,其中一半的硅面積用于48 KB內(nèi)存,另一半是含110,000個標(biāo)準(zhǔn)單元(cell)的計算邏輯。整個計算核心以1.1 GHz的時鐘頻率高效運行,而峰值功率只有30毫瓦。 先從內(nèi)存說起。GPU等傳統(tǒng)架構(gòu)使用共享中央DRAM,但DRAM存取速度較慢,位置也較遠(yuǎn)。即便使用中介層(interposer)和HBM等尖端技術(shù),其內(nèi)存帶寬也遠(yuǎn)低于核心數(shù)據(jù)通路帶寬。例如,數(shù)據(jù)通路帶寬通常是內(nèi)存帶寬的100倍。 這意味著每一個來自內(nèi)存的操作數(shù)(operand)至少要在數(shù)據(jù)通路中被使用100次,才能實現(xiàn)高利用率。要做到這一點,傳統(tǒng)的方法是通過本地緩存和本地寄存器實現(xiàn)數(shù)據(jù)復(fù)用。 然而,有一種方法可以讓數(shù)據(jù)通路以極致性能利用內(nèi)存帶寬,就是將內(nèi)存完全分布在要使用內(nèi)存的單元旁邊。這樣一來,內(nèi)存帶寬就等于核心數(shù)據(jù)通路的操作數(shù)帶寬。 這是一個簡單的物理原理:將比特數(shù)據(jù)從本地內(nèi)存移動到數(shù)據(jù)通路,中間只有幾十微米的距離,相比將它通過數(shù)據(jù)包移動到外部設(shè)備要容易得多。?
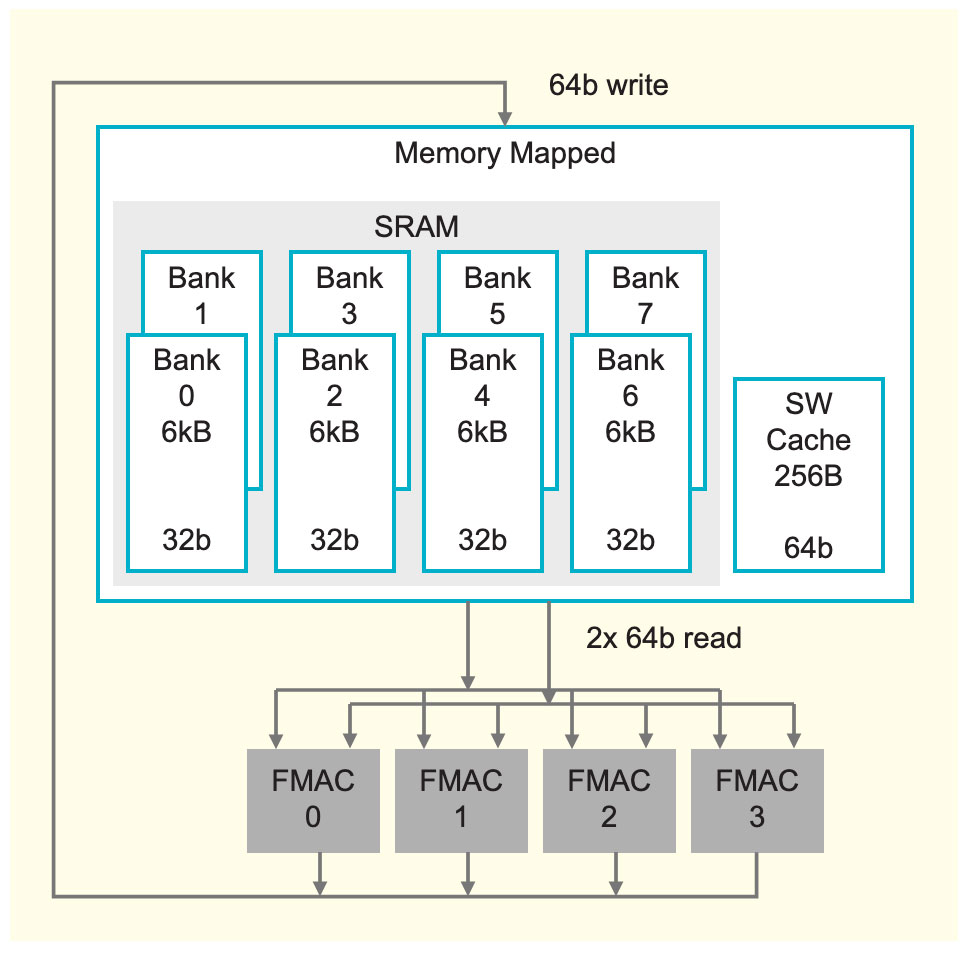
圖3:Cerebras計算核心的內(nèi)存設(shè)計:每個核心配有獨立內(nèi)存。 圖3展示了Cerebras計算核心的內(nèi)存設(shè)計,每個核心配有48 KB本地SRAM,8個32位寬的單端口bank使其具備高密度,同時可保證充分發(fā)揮極致性能,這種級別的bank可提供超出數(shù)據(jù)通路所需的內(nèi)存帶寬。 因此,我們可以從內(nèi)存中提供極致數(shù)據(jù)通路性能,也就是每個循環(huán)只需2個64位讀取,一個64位寫入,因此它可以保證數(shù)據(jù)通路充分發(fā)揮性能。值得注意的是,每個核心的內(nèi)存相互獨立,沒有傳統(tǒng)意義上的共享內(nèi)存。 除了高性能的SRAM以外,Cerebras計算核心還具備一個256字節(jié)的軟件管理緩存,供頻繁訪問的數(shù)據(jù)結(jié)構(gòu)使用,如累加器等。該緩存離數(shù)據(jù)通路非常緊湊,所以消耗的功率極低。上述分布式內(nèi)存架構(gòu)造就了驚人的內(nèi)存帶寬,相當(dāng)于同等面積GPU內(nèi)存帶寬的200倍。
02?所有BLAS級別的極致性能
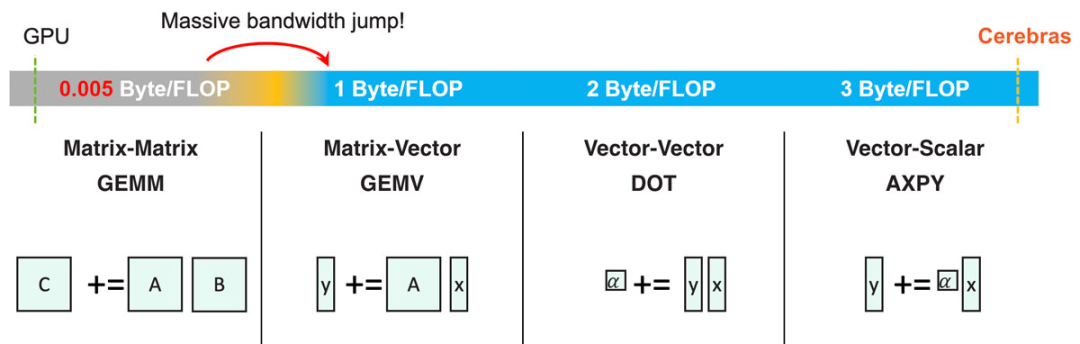
圖4:稀疏GEMM即對每個非零權(quán)重執(zhí)行一次AXPY操作。? 有了極大的內(nèi)存帶寬,就可以實現(xiàn)許多卓越的功能。比如,可以充分發(fā)揮所有BLAS級別(基礎(chǔ)線性代數(shù)程序集,BLAS levels)的極致性能。傳統(tǒng)的CPU和GPU架構(gòu)的片上內(nèi)存帶寬有限,因此只能實現(xiàn)GEMM(通用矩陣乘法)的極致性能,即矩陣-矩陣相乘。? 從圖4可見,在低于矩陣-矩陣相乘的任何BLAS級別都需要比內(nèi)存帶寬的大幅增加,這一點傳統(tǒng)架構(gòu)無法滿足。 但有了足夠的內(nèi)存帶寬后,就可以讓GEMV(矩陣-向量相乘)、DOT(向量-向量相乘)和AXPY(向量-標(biāo)量相乘)均實現(xiàn)極致性能。高內(nèi)存帶寬在神經(jīng)網(wǎng)絡(luò)計算中尤為重要,因為這可以實現(xiàn)非結(jié)構(gòu)化稀疏的充分加速。一個稀疏GEMM操作可看作是多個AXPY操作的合集(對每個非零元素執(zhí)行一次操作)。? Cerebras計算核心的基礎(chǔ)是一個完全可編程的處理器,以適應(yīng)不斷變化的深度學(xué)習(xí)需求。與通用處理器一樣,Cerebras核心處理器支持算術(shù)、邏輯、加載/儲存、比較(compare)、分支等多種指令。這些指令和數(shù)據(jù)一樣儲存在每個核心的48 KB本地內(nèi)存中,這意味著核心之間相互獨立,也意味著整個芯片可以進行細(xì)粒度動態(tài)計算。通用指令在16個通用寄存器上運行,其運行在緊湊的6級流水線中。?
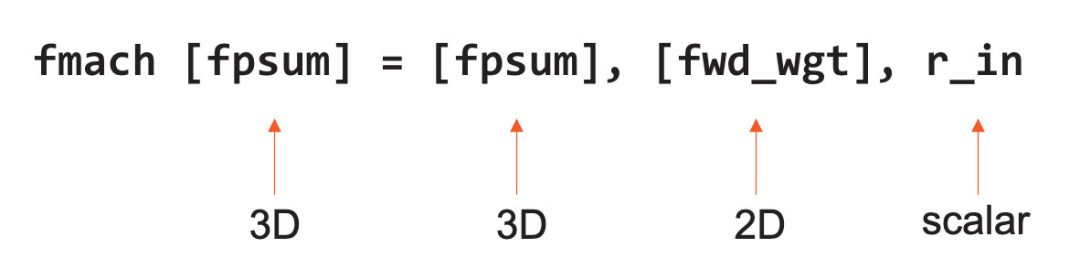
等式1,F(xiàn)MAC指令示例 除此之外,Cerebras核心還在硬件層面支持所有有關(guān)數(shù)據(jù)處理的張量指令。這些張量算子在64-位數(shù)據(jù)通路中執(zhí)行,數(shù)據(jù)通路由4個FP16 FMAC(融合乘積累加運算)單元組成。 為了提升性能與靈活性,Cerebras的指令集架構(gòu)(ISA)將張量視為與通用寄存器和內(nèi)存一樣的一等操作數(shù)(first-class operand)。上圖等式1是一個FMAC指令的例子,它將3D和2D張量視為操作數(shù)直接運行。 之所以可以做到這一點,是因為Cerebras核心使用數(shù)據(jù)結(jié)構(gòu)寄存器(DSR)作為指令的操作數(shù)。Cerebras核心有44個DSR,每個DSR包含一個描述符,里面有指針指向張量及其長度、形狀、大小等信息。 有了DSR后,Cerebras核心的硬件架構(gòu)更靈活,即可以在內(nèi)存中支持內(nèi)存中的4D張量,也可支持織構(gòu)張量(fabric streaming tensors)、FIFO(先進先出算法)和環(huán)形緩沖器。此外,Cerebras核心還配有硬件狀態(tài)機來管理整個張量在數(shù)據(jù)通路中的流動次序。
03?細(xì)粒度數(shù)據(jù)流調(diào)度
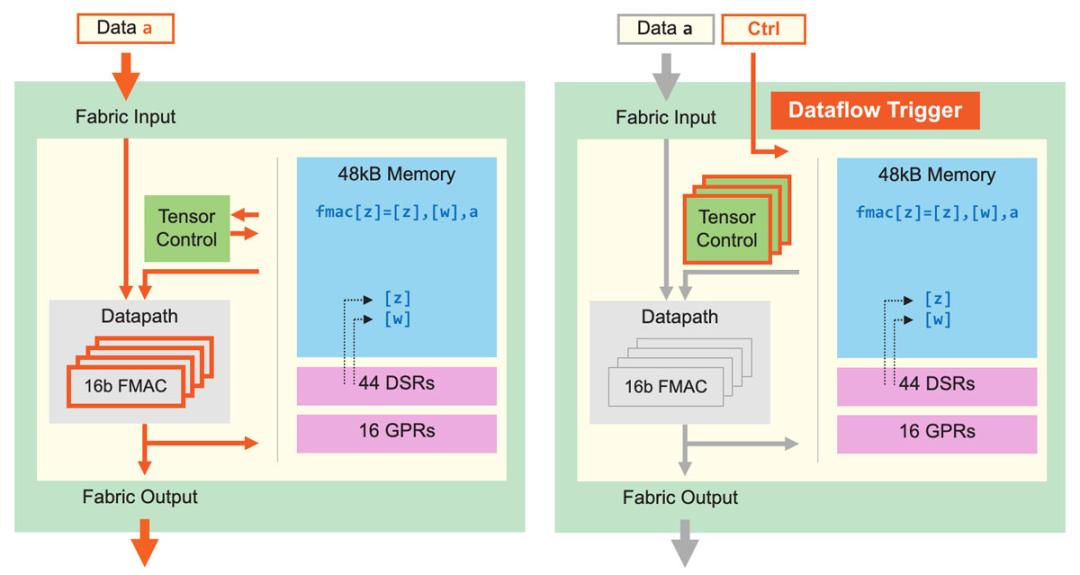
圖5:核心數(shù)據(jù)通路及核心數(shù)據(jù)流調(diào)度。細(xì)粒度動態(tài)計算核心可提升計算性能,稀疏利用率為GPU的10倍。 除了改進張量應(yīng)用,Cerebras核心還可執(zhí)行細(xì)粒度數(shù)據(jù)流調(diào)度。如圖5所示,所有計算都由數(shù)據(jù)觸發(fā)。Fabric直接在硬件中傳輸數(shù)據(jù)和關(guān)聯(lián)控件,一旦核心接收數(shù)據(jù),就開始查找運行指令,查找工作完全基于接收到的數(shù)據(jù)。這一數(shù)據(jù)流機制使整個計算結(jié)構(gòu)變成一個數(shù)據(jù)流引擎,可以支持稀疏加速——因為它只處理非零數(shù)據(jù)。發(fā)送器會過濾所有零值,因此接收器只會接收到非零值,而所有計算都由非零數(shù)據(jù)觸發(fā)。 這樣做不但可以節(jié)省功率,還可以省略不必要的計算,加快運算效率。操作由單個數(shù)據(jù)元素觸發(fā),使得Cerebras核心可以支持超細(xì)粒度、完全非結(jié)構(gòu)化的稀疏性,同時不會造成性能損失。由于數(shù)據(jù)流具有動態(tài)性,所以Cerebras核心還支持8個張量操作同時運行,我們稱之為“微線程(micro-threads)”。 微線程之間相互獨立,每次循環(huán)時硬件可在其間切換。調(diào)度器持續(xù)為所有待處理張量監(jiān)控輸入和輸出是否可用,還具有優(yōu)先處理機制,保證關(guān)鍵任務(wù)得到優(yōu)先處理。當(dāng)不同任務(wù)間的切換產(chǎn)生大量動態(tài)行為時,微線程可以提升利用率,否則這些動態(tài)行為可能會導(dǎo)致流水線出現(xiàn)氣泡。 上述細(xì)粒度、動態(tài)、小型核心架構(gòu)等特點使我們的架構(gòu)具備前所未有的高性能,其非結(jié)構(gòu)化稀疏計算的利用率是GPU的至少10倍。可見,通過對計算核心架構(gòu)的改進,Cerebras可將性能進行數(shù)量級提升。
04?縱向擴展:超越摩爾定律
要縱向擴展芯片,傳統(tǒng)的方法都是從芯片制造方面入手,即提升芯片集成度。過去數(shù)十年,芯片行業(yè)的發(fā)展都符合摩爾定律,芯片集成度越來越高。如今,摩爾定律還在延續(xù),但它的增量不夠大,每一代制程只能將集成度提升約兩倍,不足以滿足神經(jīng)網(wǎng)絡(luò)的計算需求。所以,Cerebras希望可以超越摩爾定律,實現(xiàn)數(shù)量級的性能提升。 為此,我們嘗試過傳統(tǒng)的方法——擴大芯片面積,并在這方面做到了極致,成果就是WSE-2(Wafer-Scale Engine,晶圓級引擎)。如今,WSE-2的應(yīng)用已非常廣泛。它是全世界最大的芯片,尺寸超過46,000平方毫米,是目前最大的CPU的56倍。單塊WSE-2有2.6萬億個晶體管,核心數(shù)達(dá)850,000個。龐大的芯片面積可以實現(xiàn)極大的片上內(nèi)存和極高的性能。 為了讓尺寸驚人的WSE-2也能在標(biāo)準(zhǔn)的數(shù)據(jù)中心環(huán)境中使用,我們還針對性地設(shè)計了Cerebras CS-2系統(tǒng),做到了用單塊芯片實現(xiàn)集群級計算。
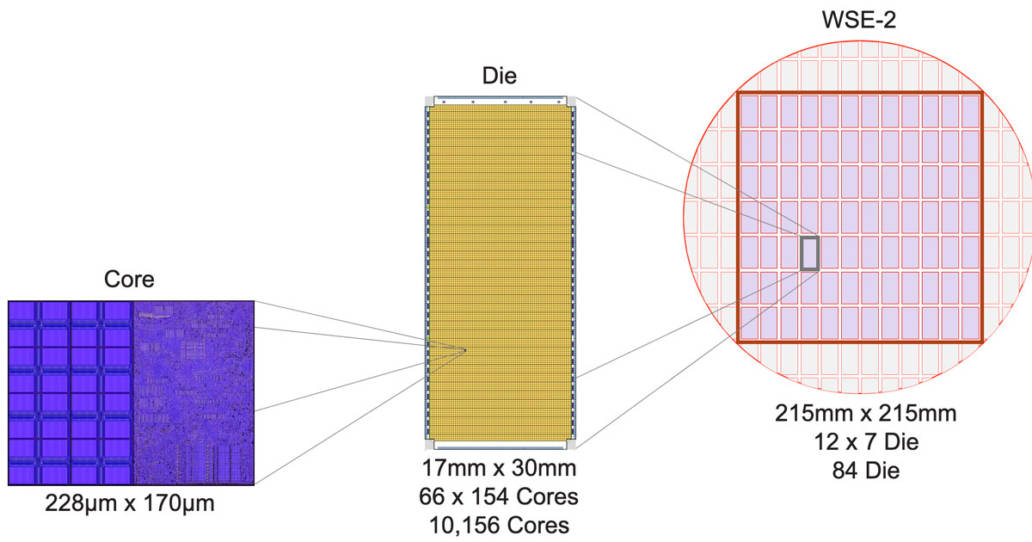
圖6:從小型核心到大型晶圓級引擎 以下是我們從小型核心構(gòu)建大型晶圓級引擎的過程:首先,我們在整片直徑約300毫米的晶圓上做出一個個傳統(tǒng)晶粒(Die),每個晶粒含有約10,000個核心;然后,不同于以往的是,我們不將單個晶粒切割出來做成傳統(tǒng)芯片,而是在整片晶圓內(nèi)切割出一個邊長215毫米的方塊,方塊包含84個晶粒,共有850,000個計算核心(圖6)。
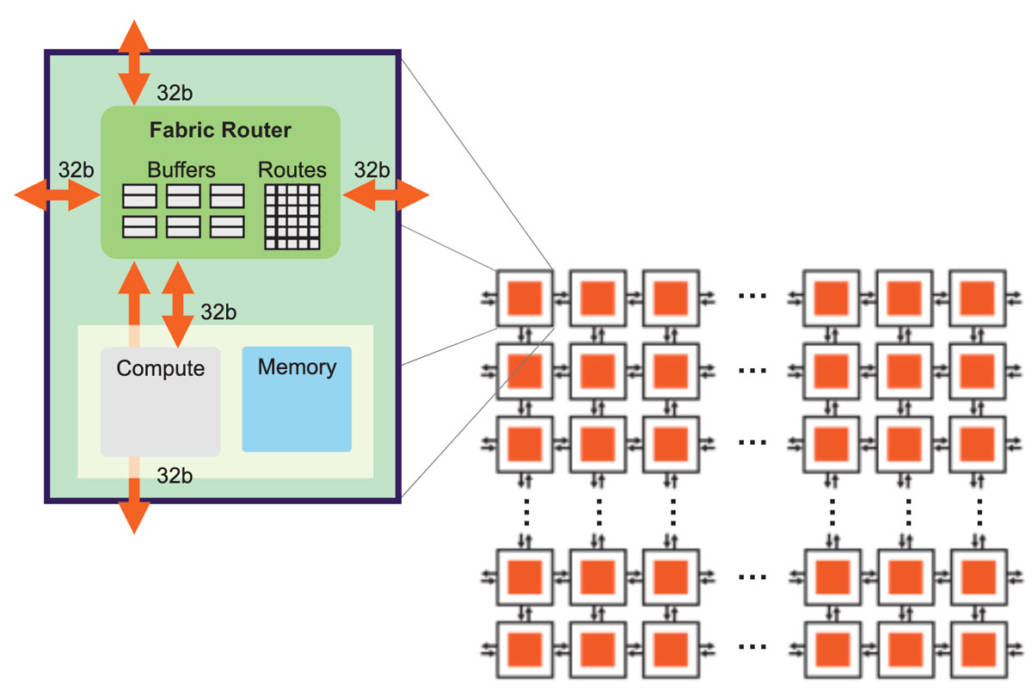
圖7:高帶寬、低延遲的芯片結(jié)構(gòu) 實現(xiàn)這樣的超大芯片尺寸,離不開底層架構(gòu)的配合,底層架構(gòu)必須能使數(shù)據(jù)在整片晶圓上高效、高性能地傳輸(圖7)。Cerebras的芯片結(jié)構(gòu)使用2D網(wǎng)格拓?fù)洌@種結(jié)構(gòu)非常適合擴展,而且只需消耗極低的開銷。 網(wǎng)格拓?fù)鋵⑺泻诵倪B接起來,每個核心在網(wǎng)狀拓?fù)渲杏幸粋€結(jié)構(gòu)路由器(fabric router)。結(jié)構(gòu)路由器有5個端口,4個方向各有1個,還有一個端口面向核心自身,各個端口都有32位的雙向接口。端口數(shù)量較少的好處是可以將節(jié)點間延時保持在一個時鐘周期以內(nèi),從而實現(xiàn)低成本、無損流控和非常低的緩沖。 芯片中的基本數(shù)據(jù)包是針對神經(jīng)網(wǎng)絡(luò)優(yōu)化后的單個FP16數(shù)據(jù)元素,與之伴隨的是16位的控制信息,它們共同組成32位的超細(xì)粒度數(shù)據(jù)包。 為了進一步優(yōu)化芯片結(jié)構(gòu),我們使用了靜態(tài)路由(static routing),效率高,開銷低,而且可以充分利用神經(jīng)網(wǎng)絡(luò)的靜態(tài)連接。為了讓同一物理連接上可以有多條路由,我們提供24條相互獨立的靜態(tài)路由以供配置,路由之間無阻塞,且都可以通過時分復(fù)用(time-multiplexing)技術(shù)在同一物理連接上傳輸。 最后,由于神經(jīng)網(wǎng)絡(luò)傳輸需要高扇出(fan-out),因此Cerebras芯片的每個結(jié)構(gòu)路由器都具有本地廣播(native broadcast)和多播(multi-cast)能力。? 有了上述基礎(chǔ)后,我們就可以進行擴展。在單個晶粒內(nèi)進行擴展比較簡單,但現(xiàn)在需要將晶粒與晶粒連接起來。為了跨越晶粒間不到一毫米寬的劃片槽(scribe line),我們使用了臺積電工藝中的高級金屬層。? 我們將計算核心擴展為2D網(wǎng)格計算結(jié)構(gòu),然后又在整個晶圓上形成了完全同質(zhì)的計算核心陣列。晶粒-晶粒接口是一種高效的源同步并行接口,但是,在如此大的晶圓規(guī)模上,總共有超過一百萬條線路,所以我們的底層協(xié)議必須采用冗余度設(shè)計。我們通過訓(xùn)練和自動校正狀態(tài)機來做到這一點。有了這些接口,即使在制造過程中存在瑕疵,整個晶圓的結(jié)構(gòu)也能做到完全均質(zhì)結(jié)構(gòu)(uniform fabric)。?
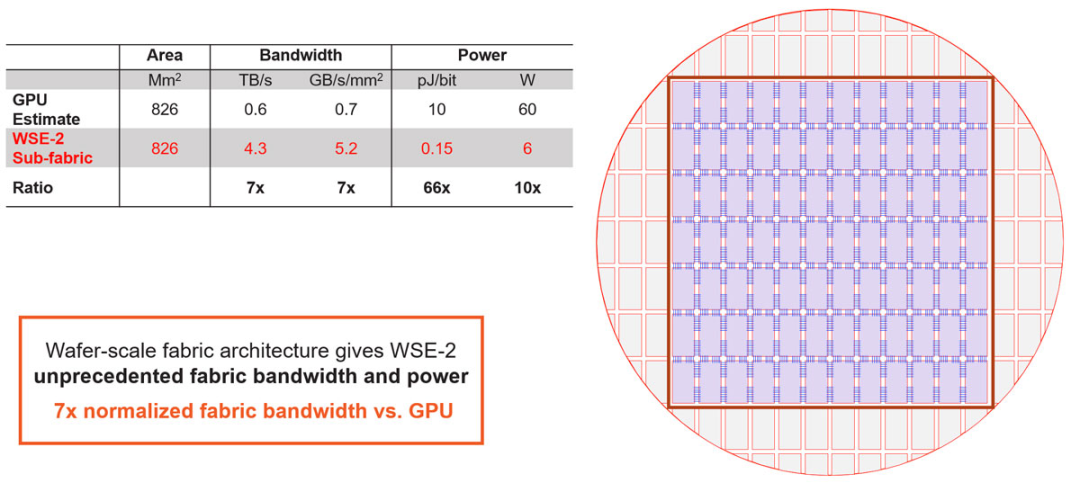
圖8:整個晶圓上的均質(zhì)結(jié)構(gòu)(uniform fabric)。 芯片上看似簡單的短線其實十分重要,它們在硅上的距離不到一毫米。這種線路設(shè)計與傳統(tǒng)的SERDES方法很不一樣。與前面提到的的內(nèi)存設(shè)計相同,短線設(shè)計是出于簡單的物理原理:在芯片上將比特數(shù)據(jù)傳輸不到1毫米的距離,比通過封裝連接器、PCB或者線纜傳輸都更容易。 與傳統(tǒng)IO相比,這種方法帶來了數(shù)量級的改進。從圖8數(shù)據(jù)可看出,WSE-2每單位面積的帶寬比GPU多出約一個數(shù)量級,并且每比特的功率效率提高了近兩個數(shù)量級。這些都表明整個晶圓結(jié)構(gòu)具備了前所未有的高性能。? 如果轉(zhuǎn)化為同等的GPU面積,WSE-2的帶寬是GPU的7倍,而功率僅約5瓦。正是這種級別的全局結(jié)構(gòu)性能,使晶圓能夠作為單個芯片運行。有了如此強大的單芯片,我們就可以解決一些極具挑戰(zhàn)性的問題。
05?通過權(quán)重流式技術(shù)支持超大模型
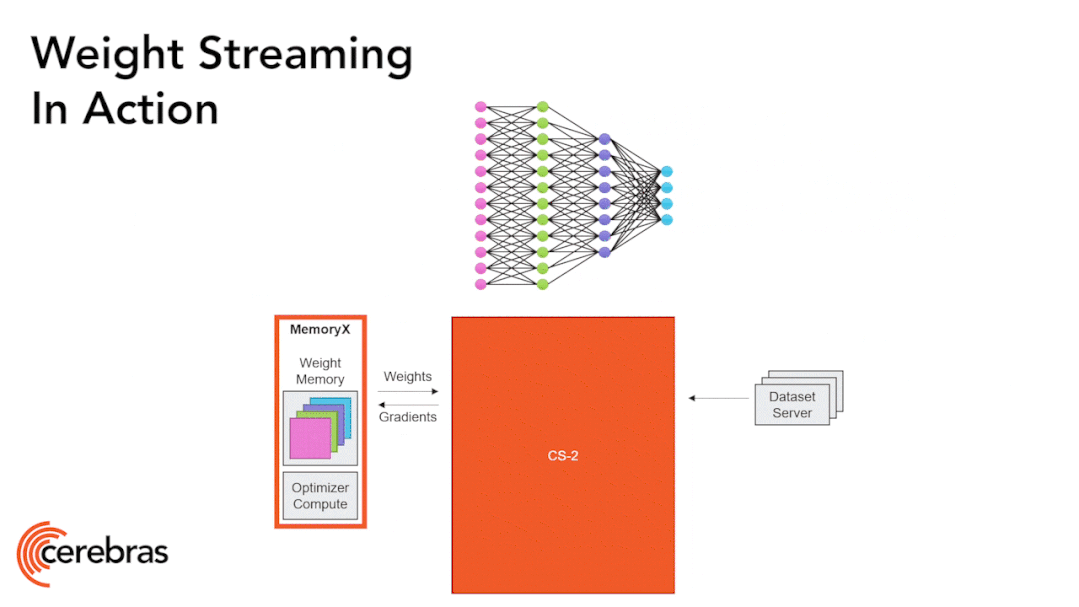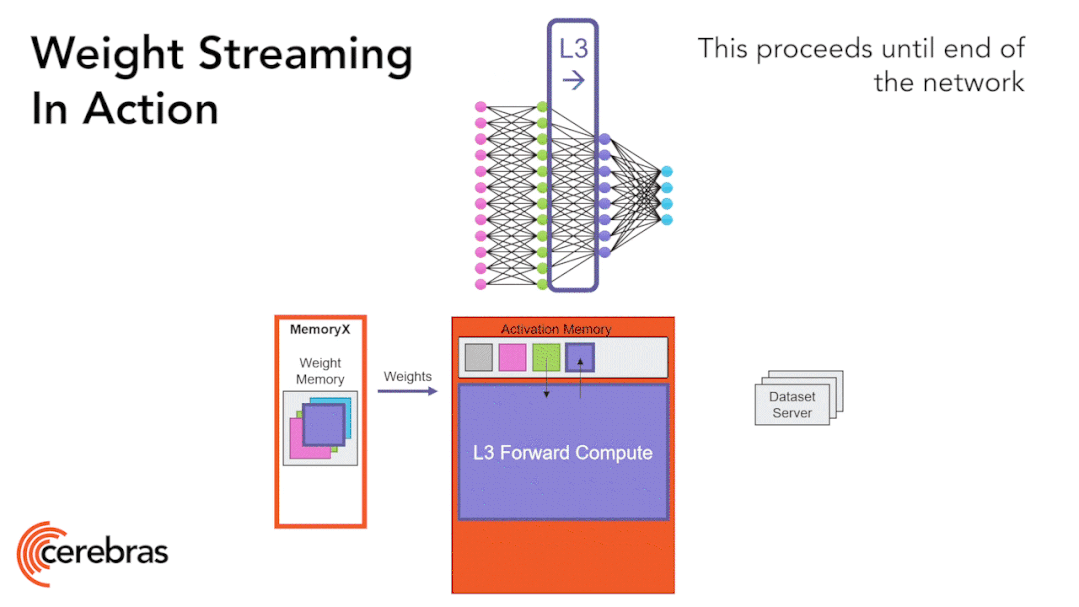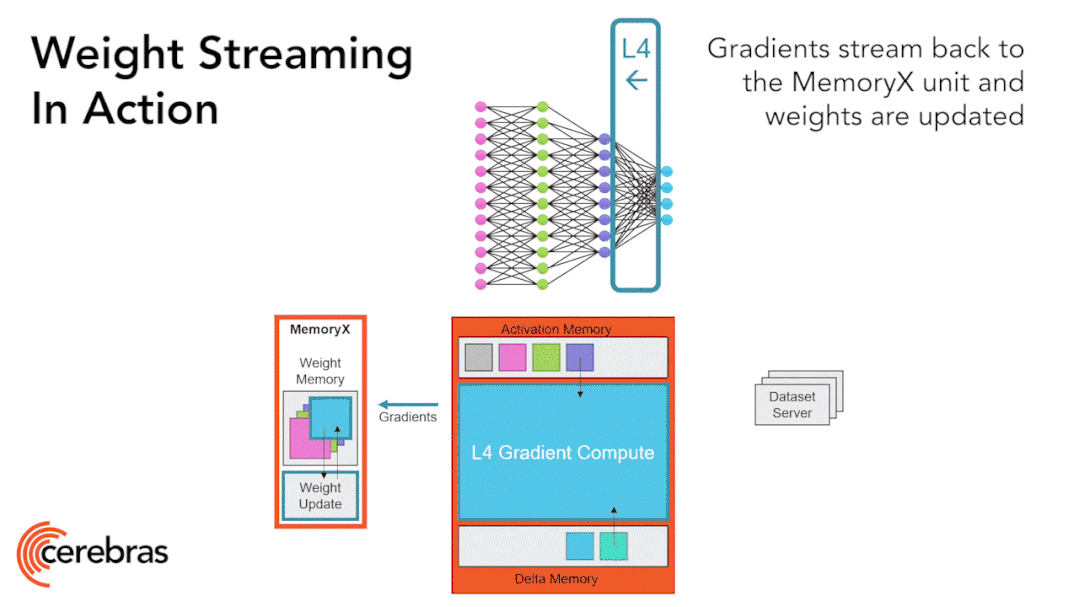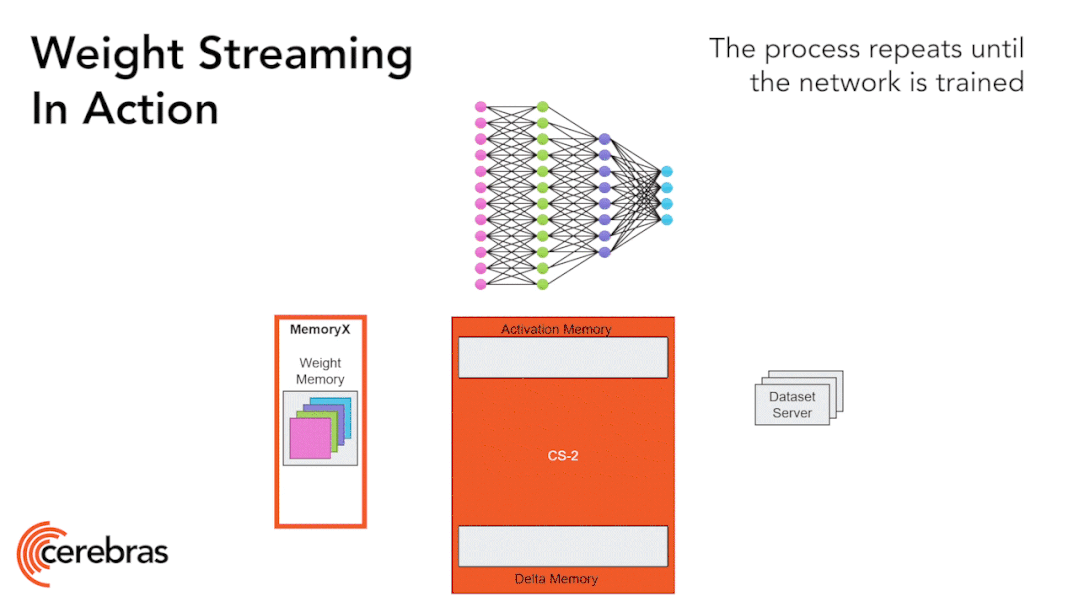
圖9:通過權(quán)重流式(Weight Streaming)技術(shù)可在單個芯片上支持所有模型大小。 高性能的芯片結(jié)構(gòu)可以讓我們在單個芯片上運行大型神經(jīng)網(wǎng)絡(luò)。WSE-2具有足夠高的性能和容量來運行如今最大的模型,且無需分區(qū)或復(fù)雜的分布式處理,這是通過分解神經(jīng)網(wǎng)絡(luò)模型、權(quán)重和計算來完成的。 我們將所有模型權(quán)重存儲在名為MemoryX的外部設(shè)備中,并將這些權(quán)重流式傳輸?shù)紺S-2系統(tǒng)。權(quán)重會在神經(jīng)網(wǎng)絡(luò)各層的計算中用到,而且一次只計算一層。權(quán)重不會存儲在CS-2系統(tǒng)上,哪怕是暫時儲存。CS-2接收到權(quán)重后,使用核心中的底層數(shù)據(jù)流機制執(zhí)行計算(圖9)。? 每個單獨的權(quán)重都會作為單獨的AXPY操作觸發(fā)計算。完成計算后,該權(quán)重就會被丟棄,硬件將繼續(xù)處理下一個元素。由于芯片不需要儲存權(quán)重,所以芯片的內(nèi)存容量不會影響芯片可處理的模型大小。在反向傳播中,梯度以相反的方向流回到MemoryX單元,然后MemoryX單元進行權(quán)重更新。?
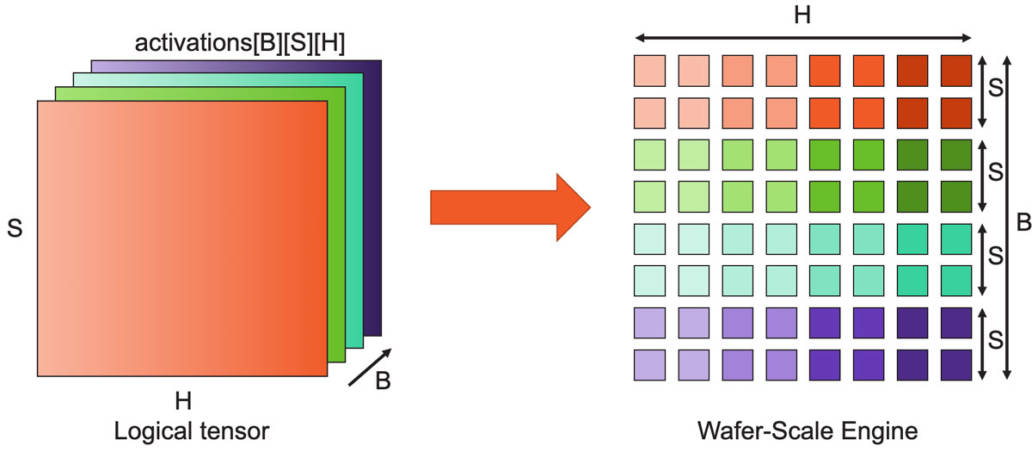
圖10:完整的晶圓是MatMul陣列,可支持超大矩陣。 以下是芯片中執(zhí)行計算的具體方法。神經(jīng)網(wǎng)絡(luò)各層的計算可歸結(jié)為矩陣乘法,由于CS-2的規(guī)模較大,我們能夠?qū)⒕A的85萬個核心用作單個巨型矩陣乘法器。 它是這樣工作的:對于像GPT這樣的Transformer模型,激活張量具有三個邏輯維度:批次(B)、序列(S)和隱藏(H)維度,我們將這些張量維度拆分到晶圓上的二維核心網(wǎng)格上。隱藏維度在芯片結(jié)構(gòu)的x方向上劃分(split),而批次和序列維度在y方向上劃分。這樣可以實現(xiàn)高效的權(quán)重廣播以及序列和隱藏維度的高效歸約。 激活函數(shù)存儲在負(fù)責(zé)執(zhí)行計算工作的核心上,下一步是觸發(fā)這些激活函數(shù)的計算,這是通過使用片上廣播結(jié)構(gòu)來完成的。我們使用片上廣播結(jié)構(gòu)來向每一列發(fā)送權(quán)重、數(shù)據(jù)和命令的方法。 當(dāng)然,在硬件數(shù)據(jù)流機制下,權(quán)重會直接觸發(fā)FMAC操作。這些是AXPY操作。由于廣播發(fā)生在列上,因此包含相同特征子集的所有核心接收相同的權(quán)重。此外,我們發(fā)送命令來觸發(fā)其他計算,例如歸約或非線性操作。
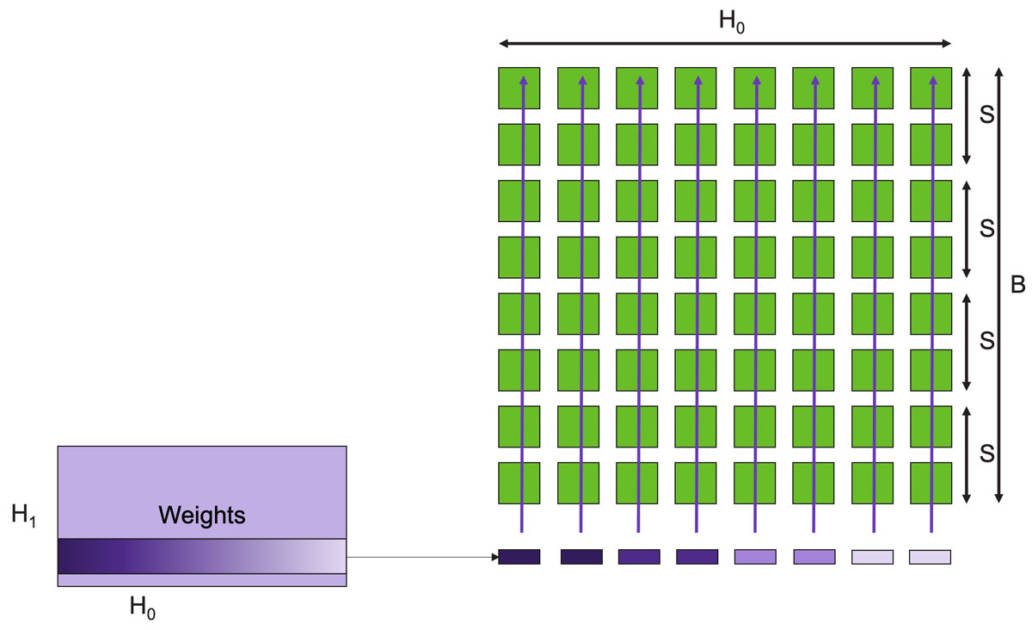
圖11:數(shù)據(jù)流調(diào)度以低開銷實現(xiàn)完全非結(jié)構(gòu)化的稀疏MatMul運算。? 舉個例子,我們首先在整個晶圓上廣播權(quán)重行(圖11)。每行的每個元素都是標(biāo)量,當(dāng)然,在單行中,有多個權(quán)重映射到單個列上,當(dāng)存在稀疏性時,只有非零權(quán)重才會被廣播到列,觸發(fā)FMAC計算。我們跳過所有的零權(quán)重,并輸入下一個非零權(quán)重,這就是產(chǎn)生稀疏加速的原因。?
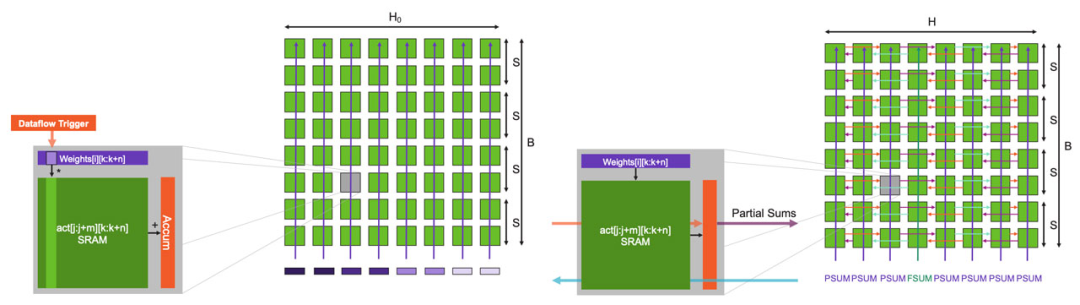
圖12:稀疏輸入的GEMM:乘法和partial sum歸約。 如果我們現(xiàn)在放大一個核心,可以看到核心架構(gòu)是如何進行此操作(圖12)。在數(shù)據(jù)流機制下,權(quán)重抵達(dá)后,就會觸發(fā)核心上的FMAC計算。權(quán)重值與每個激活函數(shù)輸出相乘,然后累加到軟件管理緩存中的本地累加器中。FMAC計算使用張量指令執(zhí)行,將激活函數(shù)輸出視為張量操作數(shù)。上述計算都不會對核心造成額外開銷。 此外,權(quán)重也不會產(chǎn)生內(nèi)存開銷,因為一旦計算完成,核心就會轉(zhuǎn)而計算下一個權(quán)重,不需要存儲任何權(quán)重。若整行核心都接收到權(quán)重,每個核心就都會產(chǎn)生一個partial sum,然后該行核心的所有partial sum將進行歸約。 歸約計算由被廣播到每列所有核心的命令包觸發(fā)。同樣,在數(shù)據(jù)流調(diào)度機制下,一旦核心接收到命令包,它就會觸發(fā)partial sum歸約計算。實際的歸約計算本身是使用核心的張量指令完成,使用的是結(jié)構(gòu)張量操作數(shù)。所有列都接收一個PSUM命令。但是其中一列會收到一個特殊的FSUM命令,它要求內(nèi)核存儲final sum。這樣做是為了使用與輸入特征相同的分布來存儲輸出特征,從而為下一層計算做好準(zhǔn)備。 收到命令后,核心使用結(jié)構(gòu)上的環(huán)形模式進行通信,該模式使用結(jié)構(gòu)靜態(tài)路由設(shè)置。使用微線程,所有歸約都與下一個權(quán)重行的FMAC計算重疊,該種FMAC計算并行開始。當(dāng)所有的權(quán)重行都處理完畢,完整的GEMM操作就完成了,同時所有的激活函數(shù)輸出都已完備,可以進行下一層計算。? 上述設(shè)計能讓各種規(guī)模的神經(jīng)網(wǎng)絡(luò)都可以在單個芯片上高性能運行。獨特的核心內(nèi)存和芯片架構(gòu)使芯片可以無需分塊或分區(qū)即可支持超大矩陣,即使是具有多達(dá)100,000 x 100,000 MatMul層的超大模型也可以在不拆分矩陣的情況下運行。 若使用單個WSE-2芯片運行此模型,F(xiàn)P16稀疏性能可達(dá)75 PetaFLOPS(若稀疏性更高,性能還可更高),F(xiàn)P16密集性能可達(dá)7.5 PetaFLOPS。這就是我們應(yīng)對機器學(xué)習(xí)硬件挑戰(zhàn)的第二個方面,通過擴展進一步帶來一個數(shù)量級的性能提升。
06?橫向擴展:為什么這么難
最后一個方面:集群橫向擴展。如今已經(jīng)存在集群解決方案,但為什么橫向擴展仍然如此困難?
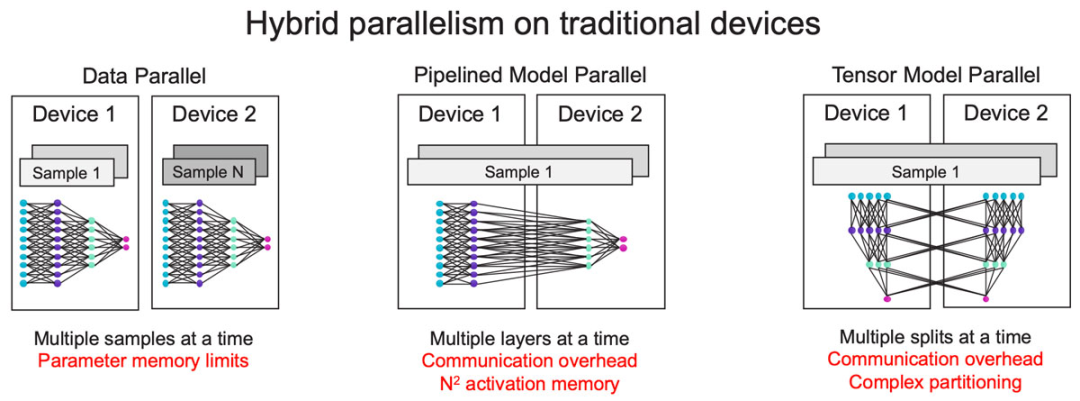
圖13:分布復(fù)雜性隨集群規(guī)模顯著增加。 讓我們看看現(xiàn)有的橫向擴展技術(shù)(圖13)。最常見的是數(shù)據(jù)并行,這也是最簡單的方法,但它不適用于大型模型,因為它要求每個設(shè)備都有足夠的容量容納整個模型。 為了解決這個問題,常見的方法是采用模型并行,即劃分模型,以流水線方式用不同的設(shè)備運行模型的不同層。但隨著流水線變長,激活值內(nèi)存(activation memory)以二次方的速度增長。 為了避免這種情況,另一種常見的模型并行方法是跨設(shè)備劃分層,但這會造成很大的通信開銷,而且劃分單個層非常復(fù)雜。? 由于上述種種限制,今天仍沒有一種萬能的方式來實現(xiàn)橫向擴展。在大多數(shù)情況下,訓(xùn)練海量模型需要數(shù)據(jù)并行和模型并行混合的方法。現(xiàn)存的橫向擴展解決方案仍有許多不足,根本原因很簡單:在傳統(tǒng)的橫向擴展中,內(nèi)存和計算是緊密聯(lián)系的,如果在數(shù)千臺設(shè)備上運行單個模型,擴展內(nèi)存和計算就變成相互依賴的分布式約束問題。
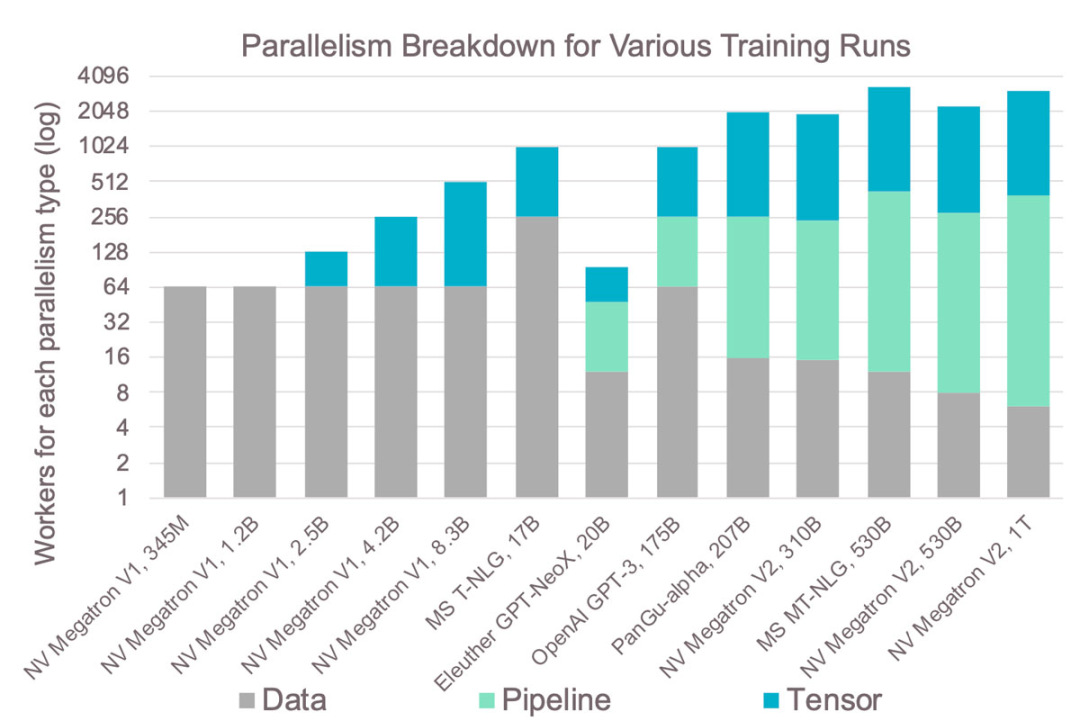
圖14:GPU集群在實踐中的復(fù)雜性。 這種復(fù)雜性導(dǎo)致的結(jié)果是:圖14顯示了過去幾年在GPU上訓(xùn)練的最大模型及其使用的不同并行方法。從中可見,越大的模型需要的并行類型也越多,增加了復(fù)雜性。 例如,張量模型的并行級別始終限制為8,因為在單個服務(wù)器中通常只有8個GPU。因此,大型模型大多采用流水式模型并行,這是最復(fù)雜的方法,原因就是之前提到的內(nèi)存問題。在GPU集群上訓(xùn)練模型需要解決這些分布式系統(tǒng)問題。這種復(fù)雜性導(dǎo)致需要更長的開發(fā)時間,并且往往無法實現(xiàn)最佳擴展。
07?Cerebras架構(gòu)使擴展變得容易
Cerebras架構(gòu)能夠在單個芯片上運行所有模型,無需模型分割,因此擴展變得簡單而自然,可以僅通過數(shù)據(jù)并行進行擴展,不需要任何復(fù)雜的模型并行分割。
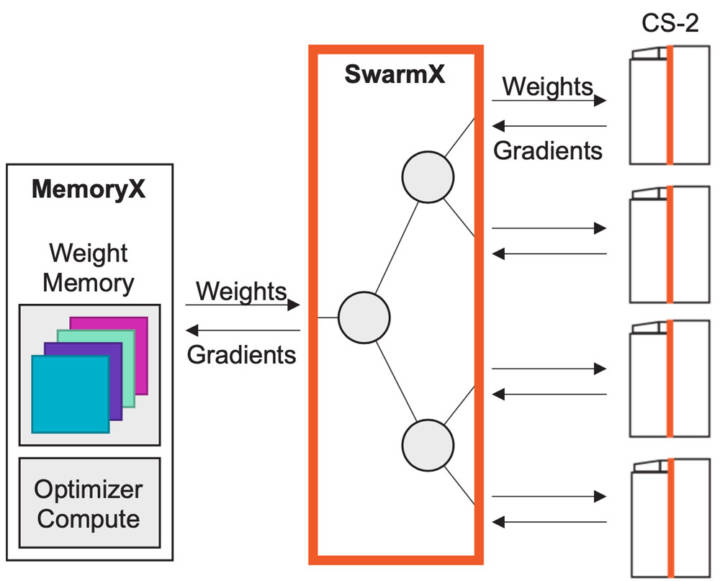
圖15:使用MemoryX和SwarmX進行擴展,只需近線性的數(shù)據(jù)并行。 我們?yōu)閿?shù)據(jù)并行專門設(shè)計了SwarmX(圖15)互聯(lián)技術(shù)。它位于儲存權(quán)重的MemoryX單元和用于計算的CS-2系統(tǒng)之間,但又獨立于兩者。 SwarmX向所有CS-2系統(tǒng)廣播權(quán)重,并減少所有CS-2的梯度,它不僅僅是一個互聯(lián),更是訓(xùn)練過程中的一個活躍組件,專為數(shù)據(jù)并行橫向擴展而構(gòu)建。? 在內(nèi)部,SwarmX使用樹形拓?fù)鋪韺崿F(xiàn)模塊化和低開銷擴展,因為它是模塊化和可分解的,所以擴展到任意數(shù)量的具有與單個系統(tǒng)相同的執(zhí)行模型的CS-2系統(tǒng)。要擴展到更多計算,只需在SwarmX拓?fù)渲刑砑痈喙?jié)點和更多CS-2系統(tǒng)。這就是我們應(yīng)對機器學(xué)習(xí)硬件需求的最后一個方面:改進并大大簡化橫向擴展。?
08?總結(jié)
在過去的幾年里,機器學(xué)習(xí)工作負(fù)載的需求增加了三個數(shù)量級以上,而且沒有放緩的跡象。預(yù)計幾年后將增長到圖16的箭頭位置,我們問自己,可以滿足這種需求嗎?

圖16:各種最先進的神經(jīng)網(wǎng)絡(luò)的內(nèi)存和計算要求。橫、縱坐標(biāo)每一格代表一個數(shù)量級的提升。 Cerebras相信,我們可以,但不是通過傳統(tǒng)技術(shù)做到這一點,而是通過非結(jié)構(gòu)化稀疏加速、晶圓級芯片和集群橫向擴展的結(jié)合將性能提升三個數(shù)量級。神經(jīng)網(wǎng)絡(luò)模型規(guī)模依然呈指數(shù)級增長,可以使用這些大模型的公司很少,而且未來只會更少。? 然而,Cerebras架構(gòu)支持用單個設(shè)備運行超大模型,同時支持只需數(shù)據(jù)并行的橫向擴展,以及本地非結(jié)構(gòu)化稀疏加速,將讓更多人都能使用大模型。??
編輯:黃飛
?









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論