 電子發燒友App
電子發燒友App


1.支持向量機(SVM)的C參數
SVM的C參數為每個錯誤分類的數據點增加了代價。如果c小,則對錯誤分類的點的懲罰較低,因此以較大數量的錯誤分類為代價選擇了具有較大余量的決策邊界。
如果c大,由于高罰分,SVM會嘗試最大程度地減少誤分類示例的數量,從而導致決策邊界的邊距較小。對于所有錯誤分類的示例,懲罰都不相同。它與到決策邊界的距離成正比。
2.具有RBF內核的SVM的Gamma參數
具有RBF內核的SVM的Gamma參數控制單個訓練點的影響距離。 較低的gamma值表示相似半徑較大,這導致將更多點組合在一起。
對于較高的伽瑪值,這些點必須彼此非常接近,以便在同一組(或類)中考慮。因此,具有非常大的伽瑪值的模型往往會過擬合。
3.是什么使邏輯回歸成為線性模型
邏輯回歸的基礎是邏輯函數,也稱為Sigmoid函數,該函數接受任何實數值,并將其映射到0到1之間的一個值。
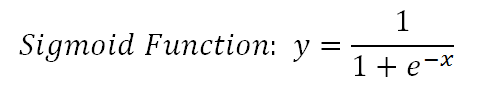
它是一個非線性函數,但邏輯回歸是一個線性模型。
這是我們從S型函數得到線性方程的方法:
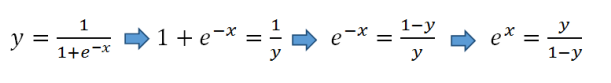
以雙方的自然對數:
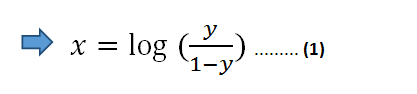
在方程式(1)中,我們可以使用線性方程式z代替x:
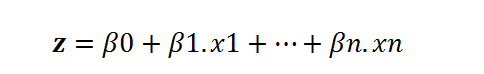
然后,等式(1)變為:
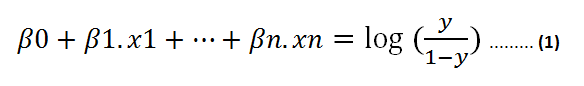
假設y為正分類的概率。 如果為0.5,則上式的右側變為0。
我們現在有一個線性方程要求解。
4. PCA中的主要組成部分
PCA(主成分分析)是一種線性降維算法。 PCA的目標是在減少數據集的維數(要素數量)的同時保留盡可能多的信息。
信息量由方差衡量。具有高方差的特征會告訴我們有關數據的更多信息。
主要成分是原始數據集特征的線性組合。
5.隨機森林
隨機森林是使用稱為裝袋的方法構建的,其中將每個決策樹用作并行估計器。
隨機森林的成功很大程度上取決于使用不相關的決策樹。 如果我們使用相同或非常相似的樹,則總體結果將與單個決策樹的結果相差無幾。 隨機森林通過自舉和特征隨機性來實現具有不相關的決策樹。
6.梯度增強決策樹(GBDT)
GBDT使用提升方法來組合各個決策樹。 增強意味著將一系列學習算法串聯起來,以從許多順序連接的弱學習者中獲得強大的學習者。
每棵樹都適合前一棵樹的殘差。 與裝袋不同,加強不涉及自舉采樣。 每次添加新樹時,它都適合初始數據集的修改版本。
7.增加隨機森林和GBDT中的樹的數量
增加隨機森林中的樹的數量不會導致過度擬合。 在某一點之后,模型的準確性不會因添加更多樹而增加,但也不會因添加過多樹而受到負面影響。 由于計算原因,您仍然不想添加不必要的樹,但是不存在與隨機森林中的樹數相關聯的過擬合風險。
但是,就過度擬合而言,梯度增強決策樹中的樹數非常關鍵。添加過多的樹會導致過擬合,因此一定要停止添加樹,這一點很重要。
8.層次聚類vs K-均值聚類
分層群集不需要預先指定群集數量。必須為k均值算法指定簇數。
它總是生成相同的聚類,而k均值聚類可能會導致不同的聚類,具體取決于質心(聚類中心)的啟動方式。
與k均值相比,分層聚類是一種較慢的算法。特別是對于大型數據集,運行需要很長時間。
9. DBSCAN算法的兩個關鍵參數
DBSCAN是一種聚類算法,可與任意形狀的聚類一起很好地工作。這也是檢測異常值的有效算法。
DBSCAN的兩個關鍵參數:
eps:指定鄰域的距離。 如果兩個點之間的距離小于或等于eps,則將其視為相鄰點。
minPts:定義集群的最小數據點數。
10. DBSCAN算法中的三種不同類型的點
根據eps和minPts參數,將點分為核心點,邊界點或離群值:
· 核心點:如果在其半徑為eps的周圍區域中至少有minPts個點(包括該點本身),則該點為核心點。
· 邊界點:如果一個點可以從核心點到達并且其周圍區域內的點數少于minPts,則它是邊界點。
· 離群點:如果一個點不是核心點并且無法從任何核心點到達,則該點就是離群點。
在這種情況下,minPts為4。紅色點是核心點,因為在其周圍區域內至少有4個半徑為eps的點。 該區域在圖中用圓圈顯示。 黃色點是邊界點,因為它們可以從核心點到達并且在其鄰域內不到4個點。 可到達意味著在核心點的周圍。 點B和C在其鄰域內(即半徑為eps的周圍區域)有兩個點(包括點本身)。 最后,N是一個離群值,因為它不是核心點,無法從核心點獲得。
11.為什么樸素貝葉斯被稱為樸素?
樸素貝葉斯算法假設要素彼此獨立,要素之間沒有關聯。 但是,現實生活中并非如此。 特征不相關的這種樸素假設是將該算法稱為“天真”的原因。
與復雜算法相比,所有特征都是獨立的這一假設使樸素貝葉斯算法非常快。在某些情況下,速度比精度更高。
它適用于高維數據,例如文本分類,電子郵件垃圾郵件檢測。
12.什么是對數損失?
對數損失(即交叉熵損失)是機器學習和深度學習模型廣泛使用的成本函數。
交叉熵量化了兩種概率分布得比較。 在監督學習任務中,我們有一個我們要預測的目標變量。 使用交叉熵比較目標變量的實際分布和我們的預測。 結果是交叉熵損失,也稱為對數損失。
13.如何計算對數損失?
對于每個預測,都會計算真實類別的預測概率的負自然對數。所有這些值的總和使我們損失了對數。
這是一個可以更好地解釋計算的示例。
我們有4個類別的分類問題。 我們針對特定觀測值的模型的預測如下:
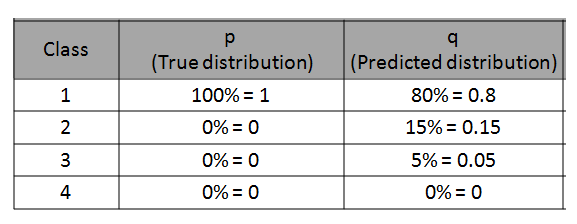
來自此特定觀察值(即數據點或行)的對數損失為-log(0.8)= 0.223。
14.為什么我們使用對數損失而不是分類準確性?
在計算對數損失時,我們采用預測概率的自然對數的負數。我們對預測的確定性越高,對數損失就越低(假設預測正確)。
例如,-log(0.9)等于0.10536,-log(0.8)等于0.22314。因此,確定為90%比確定為80%所導致的日志損失更低。
分類,準確性和召回率等傳統指標通過比較預測的類別和實際類別來評估性能。
下表顯示了在由5個觀測值組成的相對較小的集合上兩個不同模型的預測。
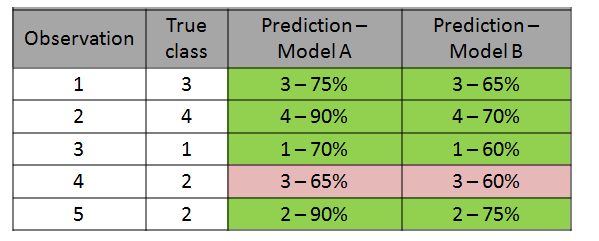
兩種模型都正確地將5個觀測值歸為5個。因此,就分類精度而言,這些模型具有相同的性能。但是,概率表明模型1在預測中更為確定。因此,總體上可能會表現更好。
對數損失(即交叉熵損失)提供了對分類模型的更強大和準確的評估。
15. ROC曲線和AUC
ROC曲線通過組合所有閾值處的混淆矩陣來總結性能。 AUC將ROC曲線轉化為二進制分類器性能的數字表示。 AUC是ROC曲線下的面積,取值介于0到1之間。AUC表示模型在分離陽性和陰性類別方面的成功程度。
16.精度度和召回率
精度度和召回率指標使分類精度進一步提高,使我們對模型評估有了更具體的了解。 首選哪一個取決于任務和我們要實現的目標。
精度衡量的是當預測為正時我們的模型有多好。精度的重點是積極的預測。它表明有多少積極預測是正確的。
回憶度量了我們的模型在正確預測肯定類別方面的表現。 召回的重點是實際的正面課堂。 它指示模型能夠正確預測多少個肯定類別。
結論
我們已經涵蓋了一些基本信息以及有關機器學習算法的一些細節。
有些要點與多種算法有關,例如關于對數損失的算法。 這些也很重要,因為評估模型與實施模型同等重要。
所有機器學習算法在某些任務中都是有用且高效的。根據您正在執行的任務,您可以精通其中的一些。
責任編輯人:CC






















 工商網監
工商網監
評論