 電子發燒友App
電子發燒友App


一、TCP概念
TCP(Transmission Control Protocol 傳輸控制協議)是一種面向連接(連接導向)的、可靠的、 基于IP的傳輸層協議。
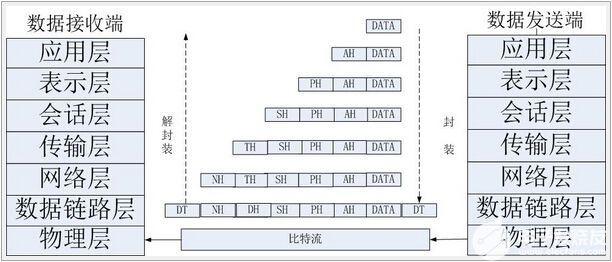
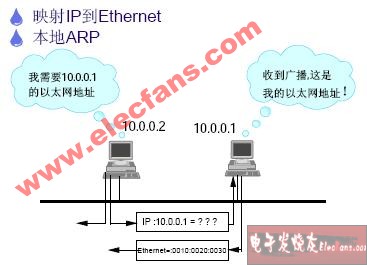
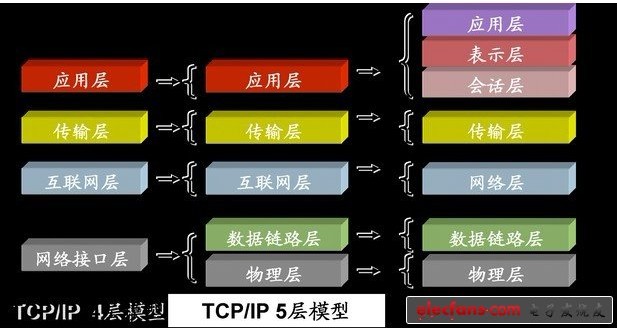
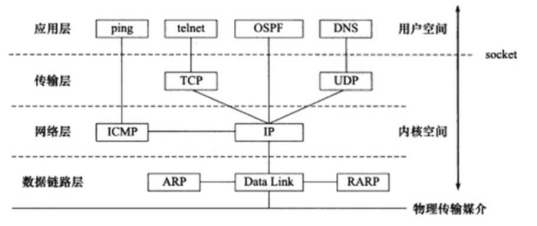
首先來看看OSI的七層模型
?
?
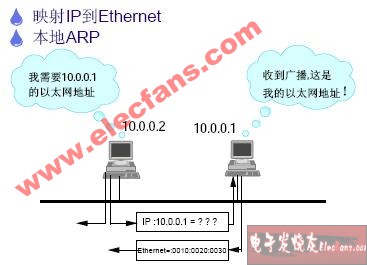
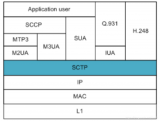
我們需要知道TCP工作在網絡OSI的七層模型中的第四層——傳輸層,IP在第三層——網絡層,ARP 在第二層——數據鏈路層;同時,我們需要簡單的知道,數據從
應用層發下來,會在每一層都會加上頭部信息,進行 封裝,然后再發送到數據接收端。這個基本的流程你需要知道,就是每個數據都會經過數據的封裝和解封 裝的過程。
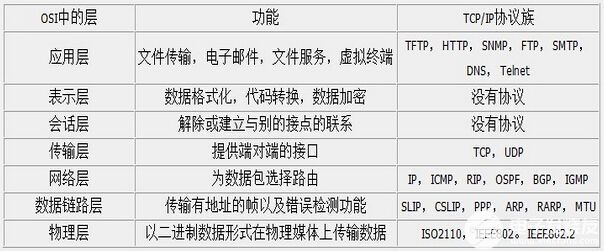
在OSI七層模型中,每一層的作用和對應的協議如下:
?
?
?
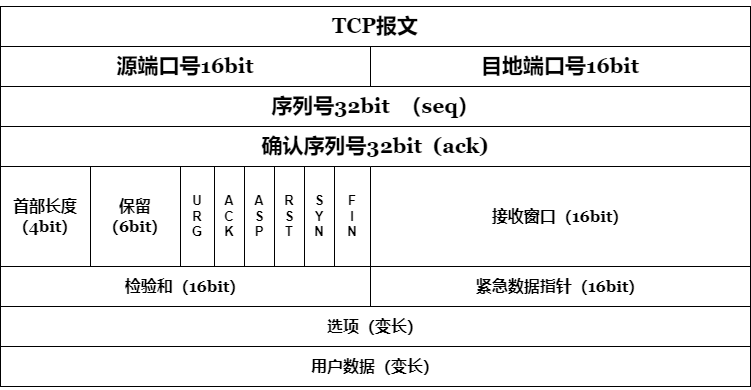
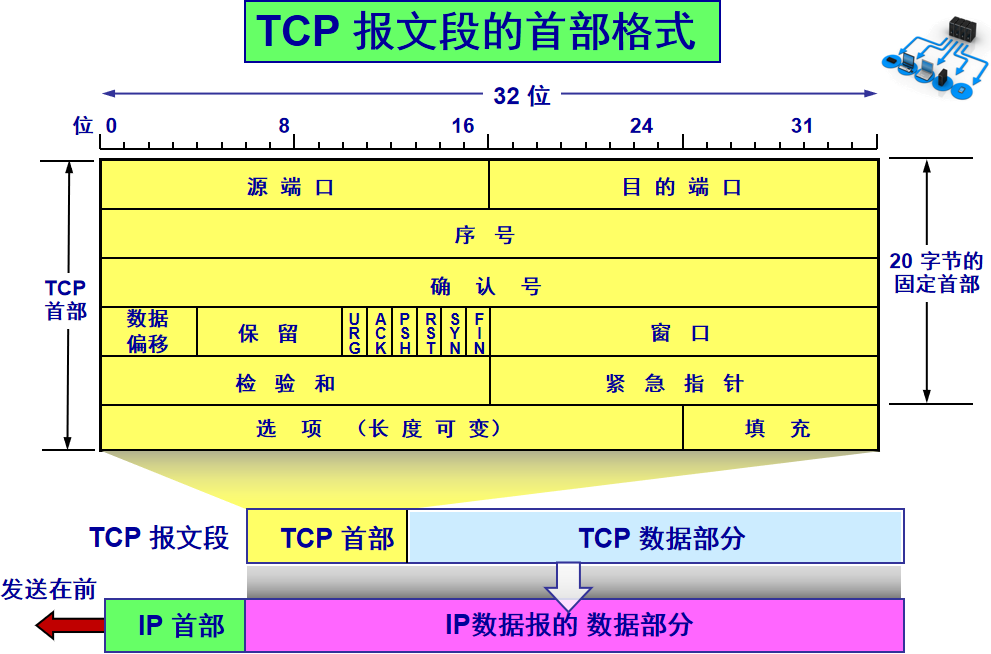
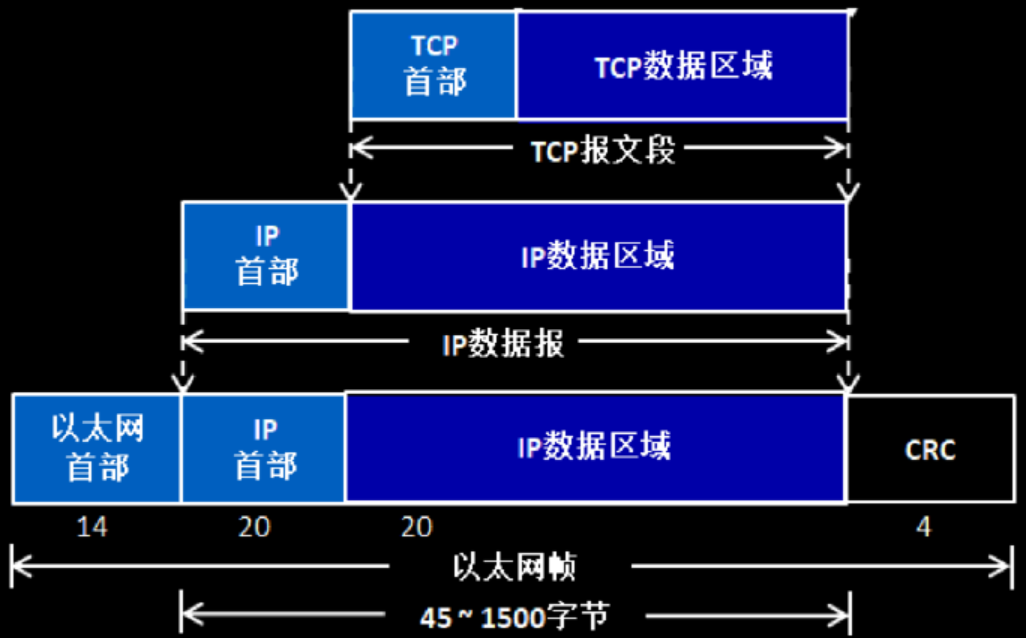
二、TCP頭部結構和字段介紹
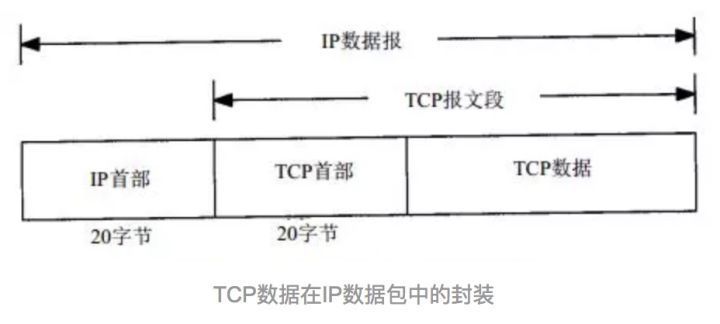
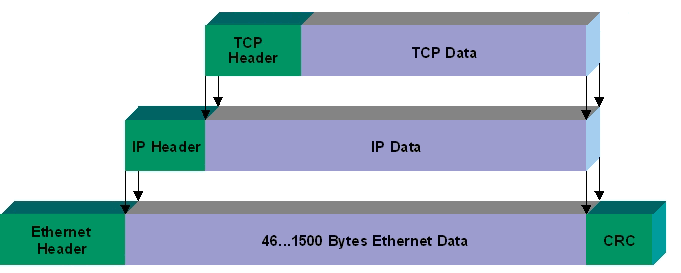
從上面圖片可以看出,TCP協議是封裝在IP數據包中。
?
?
?
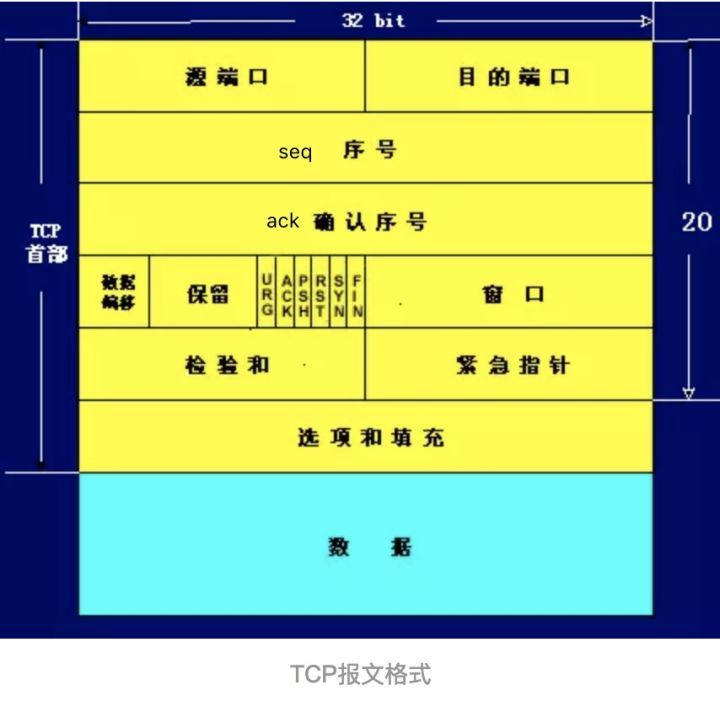
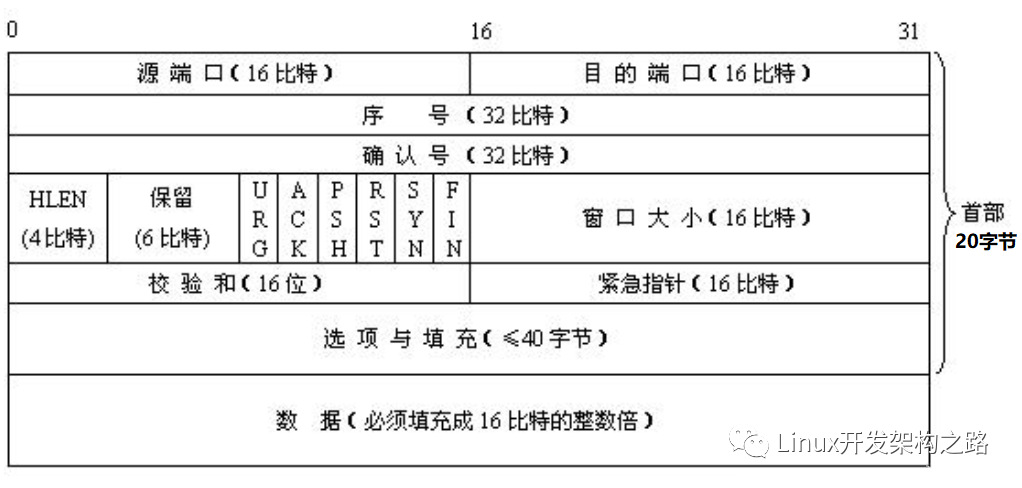
下圖是TCP報文數據格式。TCP首部如果不計選項和填充字段,它通常是20個字節。
?
?
下面分別對其中的字段進行介紹:
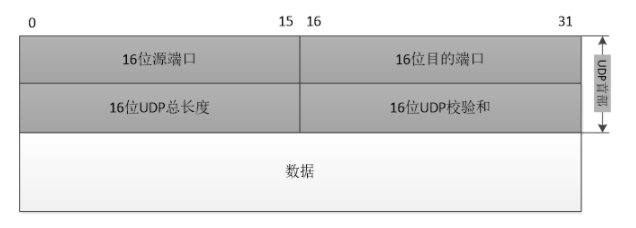
源端口和目的端口
各占2個字節,這兩個值加上IP首部中的源端IP地址和目的端IP地址唯一確定一個TCP連接。有時一個IP地址和一個端口號也稱為socket(插口)。
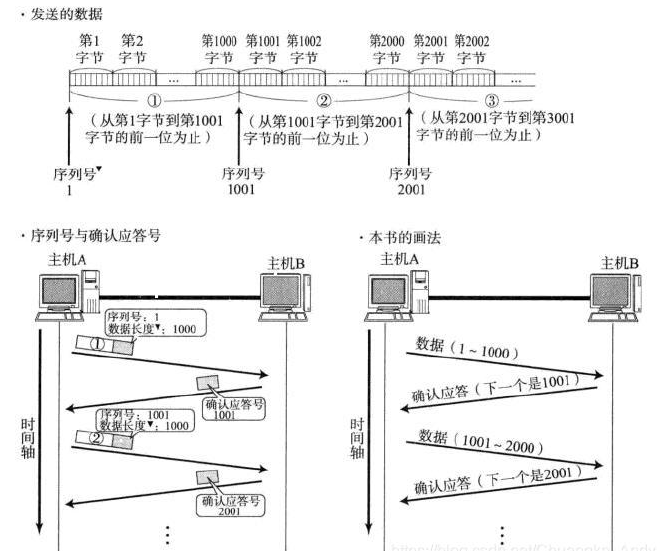
序號(seq)
占4個字節,是本報文段所發送的數據項目組第一個字節的序號。在TCP傳送的數據流中,每一個字節都有一個序號。例如,一報文段的序號為300,而且數據共100字節,
則下一個報文段的序號就是400;序號是32bit的無符號數,序號到達2^32-1后從0開始。
確認序號(ack)
占4字節,是期望收到對方下次發送的數據的第一個字節的序號,也就是期望收到的下一個報文段的首部中的序號;確認序號應該是上次已成功收到數據字節序號+1。
只有ACK標志為1時,確認序號才有效。
數據偏移
占4比特,表示數據開始的地方離TCP段的起始處有多遠。實際上就是TCP段首部的長度。由于首部長度不固定,因此數據偏移字段是必要的。數據偏移以32位為長度單位,
也就是4個字節,因此TCP首部的最大長度是60個字節。即偏移最大為15個長度單位=1532位=154字節。
保留
6比特,供以后應用,現在置為0。
6個標志位比特
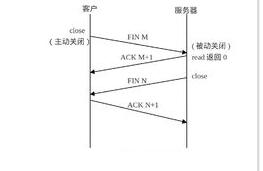
1、URG:當URG=1時,注解此報文應盡快傳送,而不要按本來的列隊次序來傳送。與“緊急指針”字段共同應用,緊急指針指出在本報文段中的緊急數據的最后一個字節的序號, 使接管方可以知道緊急數據共有多長。 2、ACK:只有當ACK=1時,確認序號字段才有效; 3、PSH:當PSH=1時,接收方應該盡快將本報文段立即傳送給其應用層。 4、RST:當RST=1時,表示出現連接錯誤,必須釋放連接,然后再重建傳輸連接。復位比特還用來拒絕一個不法的報文段或拒絕打開一個連接; 5、SYN:SYN=1,ACK=0時表示請求建立一個連接,攜帶SYN標志的TCP報文段為同步報文段; 6、FIN:發端完成發送任務。
窗口
TCP通過滑動窗口的概念來進行流量控制。設想在發送端發送數據的速度很快而接收端接收速度卻很慢的情況下,為了保證數據不丟失,顯然需要進行流量控制, 協調好
通信雙方的工作節奏。所謂滑動窗口,可以理解成接收端所能提供的緩沖區大小。TCP利用一個滑動的窗口來告訴發送端對它所發送的數據能提供多大的緩 沖區。窗口大小為
字節數起始于確認序號字段指明的值(這個值是接收端正期望接收的字節)。窗口大小是一個16bit字段,因而窗口大小最大為65535字節。
檢驗和
檢驗和覆蓋了整個TCP報文段:TCP首部和數據。這是一個強制性的字段,一定是由發端計算和存儲,并由收端進行驗證。
緊急指針
只有當URG標志置1時緊急指針才有效。緊急指針是一個正的偏移量,和序號字段中的值相加表示緊急數據最后一個字節的序號。
三、TCP流量控制(滑動窗口協議)
TCP流量控制主要是針對接收端的處理速度不如發送端發送速度快的問題,消除發送方使接收方緩存溢出的可能性。
TCP流量控制主要使用滑動窗口協議,滑動窗口是接受數據端使用的窗口大小,用來告訴發送端接收端的緩存大小,以此可以控制發送端發送數據的大小,從而達到流量
控制的目的。這個窗口大小就是我們一次傳輸幾個數據。對所有數據幀按順序賦予編號,發送方在發送過程中始終保持著一個發送窗口,只有落在發送窗口內的幀才允許被發送;
同時接收方也維持著一個接收窗口,只有落在接收窗口內的幀才允許接收。這樣通過調整發送方窗口和接收方窗口的大小可以實現流量控制。
我們可以通過下圖來分析:
?

?
?
?
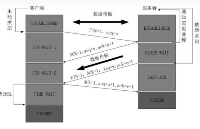
1.發送方接收到了對方發來的報文 ack = 33, win = 10,知道對方收到了 33 號前的數據,現在期望接收 [33, 43) 號數據。那我們開始發送[33, 43) 號的數據。 2.[33, 43) 號的數據你是已經發送了,但接受方并沒有接受到[36,37]數據。所以接收方發送回對報文段 A 的確認:ack = 35, win = 10。 3.發送方收到了 ack = 35, win = 10,對方期望接收 [35, 45) 號數據。那么發送方在發送[35, 45) 。
這里面需要思考一個問題?
第一步發送了[33, 43),如果這次發送[35, 45),那中間重疊部分不是發送了兩次,所以這里要思考: 是全部重新發送還是只發送接收端沒有收到的數據,如果全部發送那么重復
發送的數據接收端怎么處理。這個下面快速重傳會講。
4.接收方接收到了報文段 [35, 41),接收方發送:ack = 41, win = 10. (這是一個累積確認) 5.發送方收到了 ack = 41, win = 10,對方期望接收 [41, 51) 號數據。 6. .......
這樣一直傳輸數據,直到數據發送完成。這么一來就保證數據數據的可靠性,因為如果某數據沒有獲取到,那么ack永遠不會跳過它。
這里也要思考一個問題,如果某一數據一只沒有獲取到,總不能一直這樣堵塞在這里吧,這里就要講接下來有關堵塞的解決方法。
四、TCP擁塞控制
流量控制是通過接收方來控制流量的一種方式;而擁塞控制則是通過發送方來控制流量的一種方式。
TCP發送方可能因為IP網絡的擁塞而被遏制,TCP擁塞控制就是為了解決這個問題(注意和TCP流量控制的區別)。
TCP擁塞控制的幾種方法:慢啟動,擁塞避免,快重傳和快恢復。
這里先理解一個概念: 擁塞窗口
擁塞窗口:發送方維持一個叫做擁塞窗口 cwnd的狀態變量。擁塞窗口的大小取決于網絡的擁塞程度,并且動態變化。
發送方的讓自己的發送窗口=min(cwnd,接受端接收窗口大小)。說明: 發送方取擁塞窗口與滑動窗口的最小值作為發送的上限。
發送方控制擁塞窗口的原則是:只要網絡沒有出現擁塞,擁塞窗口就增大一些,以便把更多的分組發送出去。但只要網絡出現擁塞,擁塞窗口就減小一些,以減少
注入到網絡中的分組數。
下面將討論擁塞窗口cwnd的大小是怎么變化的。
1、慢啟動
TCP在連接過程的三次握手完成后,開始傳數據,并不是一開始向網絡通道中發送大量的數據包。因為假如網絡出現問題,很多這樣的大包會積攢在路由器上,很容易導致網
絡中路由器緩存空間耗盡,從而發生擁塞。因此現在的TCP協議規定了,新建立的連接不能夠一開始就發送大尺寸的數據包,而只能從一個小尺寸的包開始發送,在發送和數據被
對方確認的過程中去計算對方的接收速度,來逐步增加每次發送的數據量(最后到達一個穩定的值,進入高速傳輸階段。相應的,慢啟動過程中,TCP通道處在低速傳輸階段),
以避免上述現象的發生。這個策略就是慢啟動。
畫個簡單的圖從原理上粗略描述一下
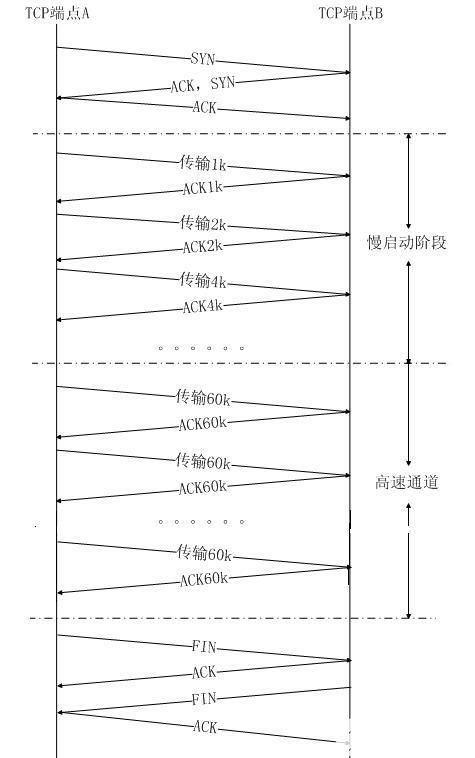
?
?
?
我們思考一個慢啟動引起的性能問題?
在海量用戶高并發訪問的大型網站后臺,有一些基本的系統維護需求。比如遷移海量小文件,就是從一些機器拷貝海量小碎文件到另一些機器,來完成一些系統維護的基本需求。
慢啟動為什么會對拷貝海量小文件的需求造成重大性能損失?
舉個簡單的例子,我們對每個文件都采用獨立的TCP連接來傳輸(循環使用scp拷貝就是這個例子的實際場景,很常見的用法)。那么工作過程應該是,每傳輸一個文件建立一個連接,然后連接處于慢啟動階段,傳輸小文件,每個小文件幾乎都處于獨立連接的慢啟動階段被傳輸,這樣傳輸過程所用的TCP包的總量就會增多。更細致的說一說這個事,如果在慢啟動過程中傳輸一個小文件,我們可能需要2至3個小包,而在一個已經完成慢啟動的TCP通道中(TCP通道已進入在高速傳輸階段),我們傳輸這個文件可能只需要1個大包。
網絡拷貝文件的時間基本上全部消耗都在網絡傳輸的過程中(發數據過去等對端ACK,ACK確認歸來繼續再發,這樣的數據來回交互相比較本機的文件讀寫非常耗時間),撇開三次握手和四次握手那些包,如果文件的數量足夠大,這個總時間就會被放大到需求難以忍受的地步。
因此,在遷移海量小文件的需求下,我們不能使用“對每個文件都采用獨立的TCP連接來傳輸(循環使用scp拷貝)“這樣的策略,它會使每個文件的傳輸都處于在一個獨立TCP的慢啟動階段。
?
如何避免慢啟動,進而提升性能?
很簡單,盡量把大量小文件放在一個TCP連接中排隊傳輸。起初的一兩個文件處于慢啟動過程傳輸,后續的文件傳輸全部處于高速通道中傳輸,用這樣的方式來減少發包的數目,進而降低時間消耗。同樣,實際上這種傳輸策略帶來的性能提升的功勞不僅僅歸于避免慢啟動,事實上也避免了大量的3次握手和四次握手,這個對海量小文件傳輸的性能消耗也非常致命。
2、擁塞避免
先補充下: 慢啟動中擁塞窗口的cwnd值,開始是1,接下開是指數型增漲的。1、2、4、8、16.....這樣漲太快了吧。那么就有了堵塞避免。
cwnd不能一直這樣無限增長下去,一定需要某個限制。TCP使用了一個叫慢啟動門限(ssthresh)的變量,一旦cwnd>=ssthresh(大多數TCP的實現,通常大小都是65536),慢啟動過程結束,擁塞避免階段開始;
擁塞避免:cwnd的值不再指數級往上升,開始加法增加。此時當窗口中所有的報文段都被確認時,cwnd的大小加1,cwnd的值就隨著RTT開始線性增加,這樣就可以避免增長過快導致網絡擁塞,慢慢的增加調整到網絡的最佳值。(它邏輯很簡單就是到一定值后,cwnd不在是指數增長,而是+1增長。這樣顯然慢多了)。
非ECN環境下的擁塞判斷,發送方RTO超時,重傳了一個報文段,它的邏輯如下:
把ssthresh降低為cwnd值的一半。
把cwnd重新設置為1。
重新進入慢啟動過程。
?
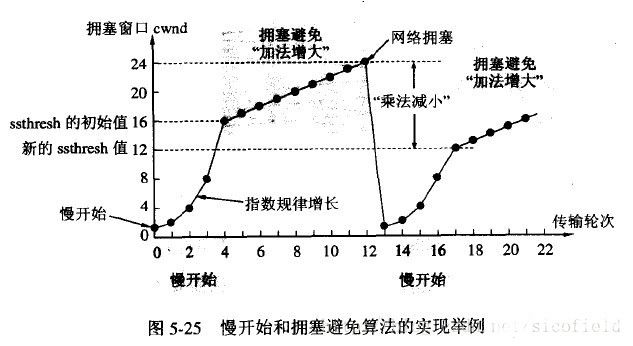
?
?
上面的圖還是蠻好理解的。
3、快速重傳
TCP要保證所有的數據包都可以到達,所以,必需要有重傳機制。
注意: 接收端給發送端的Ack確認只會確認最后一個連續的包,比如,發送端發了1,2,3,4,5一共五份數據,接收端收到了1,2,于是回ack 3,然后收到了4(注意此時3沒收到)此時的TCP會怎么辦?我們要知道,因為正如前面所說的,SeqNum和Ack是以字節數為單位,所以ack的時候,不能跳著確認,只能確認最大的連續收到的包,不然,發送端就以為之前的都收到了。
3.1)超時重傳機制
一種是不回ack,死等3,當發送方發現收不到3的ack超時后,會重傳3。一旦接收方收到3后,會ack 回 4——意味著3和4都收到了。
但是,這種方式會有比較嚴重的問題,那就是因為要死等3,所以會導致4和5即便已經收到了,而發送方也完全不知道發生了什么事,因為沒有收到Ack,所以,發送方可能會悲觀地認為也丟了,所以有可能也會導致4和5的重傳。
對此有兩種選擇:
一種是僅重傳timeout的包。也就是第3份數據。
另一種是重傳timeout后所有的數據,也就是第3,4,5這三份數據。
這兩種方式有好也有不好。第一種會節省帶寬,但是慢,第二種會快一點,但是會浪費帶寬,也可能會有無用功。但總體來說都不好。因為都在等timeout,timeout可能會很長。
3.2)快速重傳機制
于是,TCP引入了一種叫Fast Retransmit的算法,不以時間驅動,而以數據驅動重傳。也就是說,如果,包沒有連續到達,就ack最后那個可能被丟了的包,如果發送方連續收到3次相同的ack,就重傳。Fast Retransmit的好處是不用等timeout了再重傳,而是只是三次相同的ack就重傳。
比如:如果發送方發出了1,2,3,4,5份數據,第一份先到送了,于是就ack回2,結果2因為某些原因沒收到,3到達了,于是還是ack回2,后面的4和5都到了,但是還是ack回2因為2還是沒有收到,于是發送端收到了三個ack=2的確認,知道了2還沒有到,于是就馬上重轉2。然后,接收端收到了2,此時因為3,4,5都收到了,于是ack回6。
示意圖如下
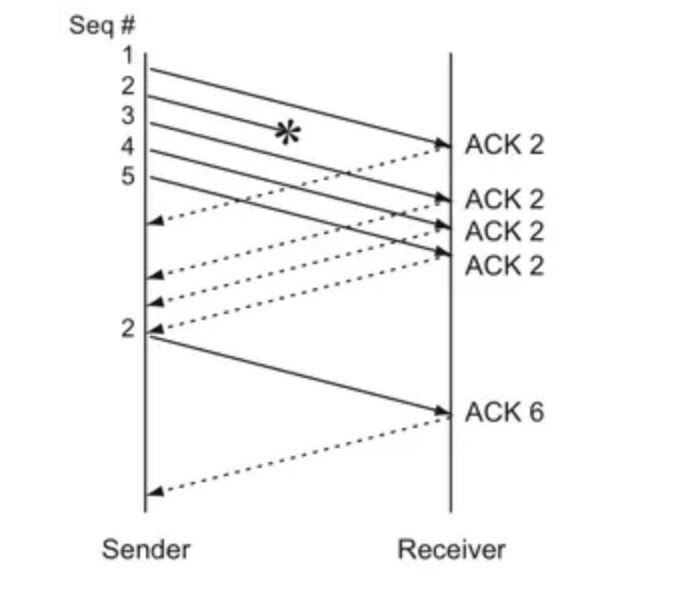
?
?
Fast Retransmit只解決了一個問題,就是timeout的問題,它依然面臨一個艱難的選擇,就是重轉之前的一個還是重裝所有的問題。對于上面的示例來說,是重傳#2呢還是重傳#2,#3,#4,#5呢?因為發送端并不清楚這連續的3個ack(2)是誰傳回來的?也許發送端發了20份數據,是#6,#10,#20傳來的呢。這樣,發送端很有可能要重傳從#2到#20的這堆數據(這就是某些TCP的實際的實現)。可見,這是一把雙刃劍。
總結: 不管是超時重傳還是快速重傳確實能保證數據的可靠性,但它無法解決的問題就是:比如發送端發了1、2、3、4、5,而接收端收到了1、3、4、5,那么這個時候它發送的ack是2。那么發送端發送的是重傳#2呢還是重傳#2,#3,#4,#5的問題。如果在發送#2,#3,#4,#5,本身資源是一種浪費,因為接受方#3,#4,#5已經緩存下來,只需#2,所以在發一遍是無意義的。















 工商網監
工商網監
評論