 電子發燒友App
電子發燒友App


基于深度強化學習的區域化視覺導航方法
人工智能技術與咨詢?
本文來自《上海交通大學學報》,作者李鵬等
關注微信公眾號:人工智能技術與咨詢。了解更多咨詢!
?
在環境中高效導航是智能行為的基礎,也是機器人控制領域研究的熱點之一.實現自主導航的傳統方法是結合一系列硬件和算法解決同步定位和建圖、路徑規劃及動作控制等問題,該類方法在實際應用中取得了良好效果,但需人工設計特征和預先構造地圖[1].通過對空間認知行為的研究,動物神經學家發現,哺乳動物可基于視覺輸入和環境信息(食物、巢穴、配偶等)在海馬體內形成認知地圖[2],從而實現大范圍導航.在探索環境過程中,端到端的學習方法可建立視覺到動作的直接映射,使得動作不會與視覺信息分離,而是在一起相互學習,以此獲得與任務相關的空間表征.近年來備受關注的深度強化學習[3]具有類似的學習方法,可通過構建表征完成具有挑戰性的導航任務.
當機器人與環境交互時,導航被看作一個尋優過程[4],而隨著深度模型的發展和異步優勢訓練方法的應用,深度強化學習在導航領域展現出強大的生命力.Zhu等[5]將預先訓練好的ResNet與Actor-Critic(AC)算法結合,并在根據實際場景設計的3D仿真環境下進行測試,實現了目標驅動的視覺導航,同時證明該方法具有更好的目標泛化能力.Mirowski[4]等提出Nav A3C模型,且在訓練過程中增加深度預測和閉環檢測任務,使得在同樣訓練數據下可兩次更新網絡參數.Jaderberg等[6]則研究了關于非監督輔助任務對訓練的影響,這兩種方法為提升導航性能提供了新的思路.為適應大比例地圖,Oh等[7]在探索過程中將重要環境信息存儲在外部記憶體中,待需要時再進行調用,但當處于非常大或終身學習場景中時,該系統的內存容量會隨探索周期的持續而線性增長.面對這種情況,可考慮通過分割環境緩解模型記憶壓力,類似的區域劃分方法已在多個領域發揮作用.黃健等[8]在標準粒子群算法的基礎上加入區域劃分方法,針對不同區域的粒子采用不同策略自適應調整粒子的慣性權重和學習因子,達到尋優與收斂的平衡,降低了由聲速不確定性引發的水下定位誤差.張俊等[9]將邊指針和區域劃分結合,提高了大規模數據處理效率.Ruan等[10]則利用局部區域提高了數據關聯準確性.在醫學研究中,區域劃分是研究腦片圖像中不同腦區分子表達、細胞數目及神經網絡連接模式量化和比較的基礎[11],而在航空運輸領域,區域劃分更是與航線規劃密切相關.同樣,在利用深度強化學習實現導航的方法中,也有涉及區域劃分的研究.Kulkarni等[12]在框架中應用繼承表征(SR)實現深度繼承強化學習(DSR),并在兩個簡單的導航任務中進行實驗.與深度Q網絡(DQN)[13]相比,DSR能更快適應末端獎勵值變化,且對于多區域環境可進行子目標提取.Shih等[14]提出一種分布式深度強化學習模型,可用于室內不同區域間的導航.Tessler等[15]模仿動物學習方式提出一種終身學習模型,在模型中可重復使用和同化其他任務中學習到的技巧,其中就包括某一環境下的導航策略,通過技巧之間的組合,可實現區域間導航.
本文研究在終身學習模型的基礎上展開,面對分布式環境,不再使用單一模型在整個環境中導航,而是利用子模塊在各區域內獨立學習控制策略,并通過區域化模型集成控制策略實現大范圍導航.與此同時,在訓練方法上做出兩點改進:① 在子模塊中增加獎勵預測任務,緩解導航任務固有的獎勵稀疏性,構建對獎勵敏感的空間表征.② 在原有探索策略基礎上結合深度信息躲避障礙物,防止遍歷停滯.實驗在第一人稱視角的3D環境下進行.
1 深度強化學習簡介
深度強化學習是深度學習和強化學習的結合,利用深度學習可自動抽象高維數據(圖像、文本、音頻等)的特性,解決了強化學習由于內存、計算及樣本復雜度等引發的維數災難問題,這給人工智能領域帶來了革命性的變化,預示對視覺世界具有更高層次理解的端到端系統的建立.其中,典型架構為深度Q網絡[13]及深度遞歸Q網絡[16].
1.1 深度Q網絡
深度Q網絡是第一個被證明的可以在多種環境中直接通過視覺輸入學習控制策略的強化學習算法,其模型如圖1所示,其輸入是4個連續串聯的狀態幀.
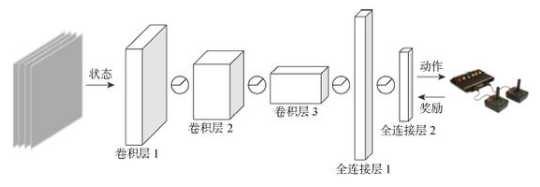
圖1?? DQN模型
?
Fig.1?? DQN model
?
標準的強化學習通過與環境交互實現,在每一個時間步t,智能體會根據當前環境狀態st和策略π選擇一個動作at,在執行動作以后,將獲得一個獎勵信號rt,并進入下一狀態st+1.定義Rt為每一個時間步的累積折扣獎勵:
Rt=?[Math Processing Error]∑t'=tTγt'-trt'
(1)
式中:T為回合的最大步數;γ∈[0, 1]為折扣因子;t'為下一時間步;rt'為下一時間步的獎勵.DQN使用動作值函數學習控制策略,在給定策略π的情況下,動作值函數Qπ定義為狀態s下執行動作a后的期望回報:
Qπ(s,?a)=E[Rt|st=s,?at=a]
(2)
在定義Qπ的同時定義最優動作值函數Q*,即Q*(s,?a)=?[Math Processing Error]maxπQπ(s,?a),借助貝爾曼方程可迭代更新動作值函數:
Qi+1(s,?a)=Es'[r+γ[Math Processing Error]maxa'Qi(s',?a')]
(3)
式中:s'及a'分別為下一時間步的狀態和動作.當i→∞時,Qi→Q*.DQN使用一個參數為θ的深度卷積神經網絡擬合Q值,此時同樣可以利用貝爾曼等式更新參數θ,定義均方誤差損失函數:
Lt(θt)=Es,a,r,s'[(yt-?[Math Processing Error]Qθt(s,?a))2]
(4)
式中:yt=r+γ[Math Processing Error]maxa'[Math Processing Error]Qθt(s',?a')代表目標,通過微分損失函數可得梯度更新值:
[Math Processing Error]ΔθtLt(θt)=Es,a,r,s'[(yt-?[Math Processing Error]Qθt(s,a))?[Math Processing Error]ΔθtQθt(s,?a)]
(5)
通過在環境中學習不斷減小損失函數,使得Q(s,?a;θ)≈Q*(s,?a).其實DQN并不是第一個嘗試利用神經網絡實現強化學習的模型,它的前身是神經擬合Q迭代(NFQ)[17],并且DQN架構與Lange等[18]提出的模型密切相關,而DQN之所以能達到與專業游戲測試人員相當的分數,是因為應用了兩種關鍵改進:① 目標網絡,與標準的Q-learning相比,這種方法使用一組參數滯后的網絡生成目標,可在更新Q(st,?at)和yt的時間點之間增加延遲,從而降低策略發散或振蕩的可能性.② 經驗回放,這是一種受生物學啟發的機制,通過對經驗池中樣本均勻采樣,可有效打破數據的時間相關性,同時平滑數據分布.從訓練角度看,經驗池的使用可大大減少與環境所需的交互量,并且能夠提高批量數據吞吐量.目標網絡和經驗回放在隨后的深度強化學習方法中也得到了應用和發展[19].
1.2 深度遞歸Q網絡
DQN已被證明能夠從原始屏幕像素輸入學習人類級別的控制策略,正如其名字一樣,DQN根據狀態中每一個可能動作的Q值(或回報)選擇動作,在Q值估計足夠準確的情況下,可通過在每個時間步選擇Q值最大的動作獲取最優策略.然而,由1.1節可知,DQN的輸入是由智能體遇到的4個狀態組成的,這種從有限狀態學習的映射,本身也是有限的,因此,它無法掌握那些要求玩家記住比過去4個狀態更遠事件的游戲.換句話說,任何需要超過4幀內存的游戲都不會出現馬爾可夫式,此時游戲不再是一個馬爾可夫決策過程(MDP),而是一個部分可見的馬爾可夫決策過程(POMDP)[20].當使用DQN在POMDP中學習控制策略時,DQN的性能會有所下降,因為在狀態部分可觀察的情況下,智能體需記住以前的狀態才能選擇最優動作.為此,Hausknecht等[16]將具有記憶功能的長短時記憶網絡(LSTM)[21]與DQN結合,提出深度遞歸Q網絡(DRQN),其模型如圖2所示.

圖2?? DRQN模型
?
Fig.2?? DRQN model
?
為隔離遞歸性影響,對DQN結構進行最小程度修改,只將DQN中第一個全連接層替換為相同大小的LSTM層,使LSTM輕易與DQN結合.實驗中設計了多種環境測試DRQN處理部分可觀測狀態的效果:① 當使用完整觀察狀態進行訓練并使用部分觀察狀態進行評估時,DRQN可更好地應對信息丟失帶來的影響.② 在每個時間步只有一個狀態幀輸入時,DRQN 仍可跨幀集成信息學習控制策略.
2 區域化導航方法
基于對分布式環境的分析,以深度強化學習為基礎,在各區域內學習控制策略,同時通過區域化模型結合控制策略完成復雜環境下的導航任務.在學習過程中,為提高訓練效率及導航性能,在子模塊中增加獎勵預測任務,并結合深度信息躲避障礙物.
2.1 景深避障
高效探索未知環境是導航的基礎,以哺乳動物為例,當將其置于一個陌生環境時,它會根據環境中的顏色、氣味及光照等特征快速遍歷空間,以便于后續的目的性行為.在設計機器人探索策略時,同樣力求高效遍歷狀態空間,并盡量減少與障礙物碰撞,但由于傳感器限制,機器人并不能獲得如此多的環境信息,因此在探索起始階段需使用啟發式的探索策略,并結合硬件輔助完成遍歷過程.比較典型的探索方案是DQN以及DRQN所使用的ε-greedy[12,?15]策略,該策略在每一個時間步t選擇動作at的方法如下式所示:
at=?[Math Processing Error]random(at∈A),εargmaxa∈AQ(st,a),1-ε
(6)
其中,ε在探索開始時設置為1,并隨探索步數的增加線性減少,最后固定為一個比較小的值.在訓練階段,機器人主要通過視覺信息在區域內自主學習.因此,當撞到障礙物時,如果此時沒有較好的避障措施,那么將長時間停留在一個地點.為了防止遍歷停滯,提高探索效率,本文在ε-greedy探索策略基礎上,結合狀態深度信息為探索動作添加限制,單個回合的探索流程如圖3所示.
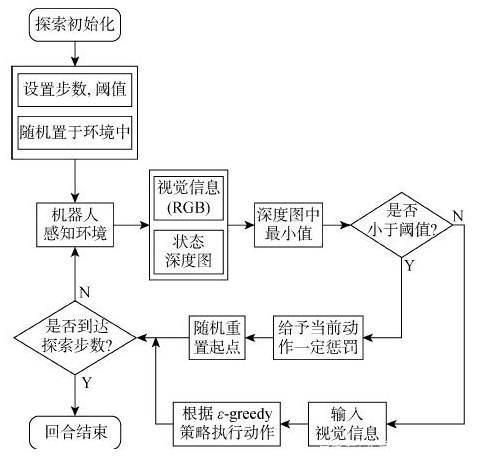
圖3?? 探索流程
Fig.3?? Exploration process
從流程圖可以看出,景深避障需在執行動作之前完成,即當機器人獲取視覺信息后,并不立即使用視覺信息選取動作,而是先通過狀態深度圖中的最小值與閾值相比較,在判斷是否撞到障礙物后再執行下一步動作.
2.2 獎勵預測
在學習導航策略過程中,機器人需識別出具有高回報或高獎勵的狀態,以便于更高效地學習值函數和策略.然而,環境中的獎勵往往是稀疏分布的,目標也只有一個,這就提出一個問題:在不包含獎勵的狀態下,智能體應通過什么學習以及如何學習.
其實除獎勵外,環境中還包含大量可以用來學習的目標,例如當前或后續幀中的某些特征,傳統的無監督學習就是通過重建這些特征實現加速學習的.相反,在輔助任務[6]中,機器人的目標是預測和控制環境中的特征,并把它們當作強化學習中的偽獎勵,在缺少獎勵的情況下進行學習.在狀態空間中,獎勵一般代表環境中的長期目標,而偽獎勵代表環境中的短期目標,當偽獎勵的目標與獎勵的目標緊密相關時,將有助于形成對目標敏感的空間表征.導航的目標是最大化獎勵,為緩解獎勵稀疏性和促進表征學習,在區域導航子模塊中增加獎勵預測任務,其模型如圖4所示.
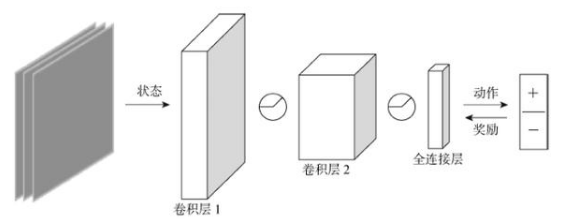
圖4?? 獎勵預測模型
Fig.4?? Reward prediction model
模型中通過前饋網絡連接被卷積編碼的狀態實現獎勵預測,其中有兩點值得注意:① 獎勵預測主要針對感知環境的卷積部分進行優化,除用于獲取對獎勵敏感的表征外,不會影響控制策略的學習,所以獎勵預測使用與動作選取不同的體系結構.② 在模型訓練方面,雖然獎勵預測與動作選取同步更新,但前者沒有使用在線學習方法,而是利用經驗池更新.在訓練過程中,獎勵預測需通過3幀連續序列Sτ={sτ-3,?sτ-2,?sτ-1}預測在隨后觀測中的獎勵rτ,但不要求其給出具體數值,所用損失函數為交叉熵分類:
LRP=-?[Math Processing Error]rτlgr^τ+(1-rτ)lg(1-r^τ)
(7)
式中:?[Math Processing Error]r^τ為預測值.此外,為提高表征構建效率,不再使用隨機方式采樣訓練樣本,而是以P=0.5的概率從經驗池中抽取包含獎勵的序列,經驗池中數據也會隨策略π產生的數據更新.
2.3 區域化導航模型
哺乳動物具有非凡的空間探索和創造能力,通過感知不斷變化的環境可準確地回到幾百米,甚至上千米以外的巢穴,但對于移動機器人,隨著狀態和動作空間的擴張,導航性能會隨之下降,特別是當面對具有多區域特性的大比例環境時,往往會陷入無限探索困境.受終身學習模型啟發,本文提出一種區域化導航方法,面對分布式環境,該方法使用單獨的子模塊在各區域內學習控制策略,模塊結構如圖5所示,圖中價值函數Vπ定義為在給定策略π的情況下以狀態s為起點的期望回報:
[Math Processing Error]Vmπ(s)=ERt|st=s
(8)
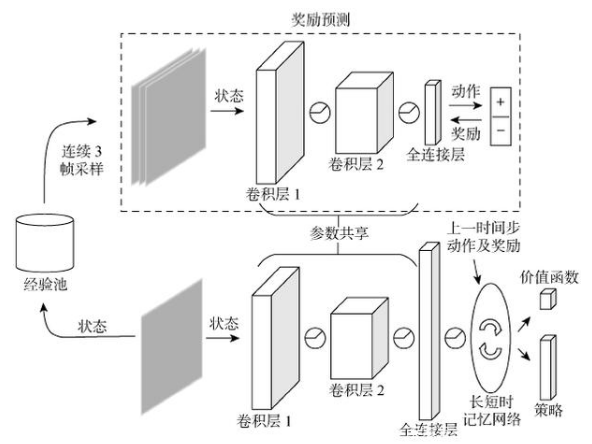
圖5?? 區域導航子模塊
Fig.5?? Submodule of region navigation
式中:m為區域編號.模塊中包括動作選取和獎勵預測兩部分.在整個學習過程中,動作選取和獎勵預測既相互獨立又相輔相成,它們會按照各自的方式更新參數:動作選取部分通過與環境交互不斷優化導航策略,獎勵預測部分則利用經驗池中的數據構建表征.同時它們又相互聯系:當執行更優導航策略后,經驗池中包含獎勵的狀態會增多,有助于形成對獎勵敏感的表征,而表征會以參數共享的方式傳遞到動作選取部分,進一步提升導航性能.
當所有區域控制策略訓練完成時,按照收斂的先后順序將策略集成到模型內部,模型中的每一層代表一個區域的控制策略.環境控制策略由相同的子模塊在整個環境中學習獲得,主要起中繼作用,因此不要求其收斂,當所有區域策略收斂后,環境控制策略也停止訓練,并以當前參數集成到模型中.本文策略選取的方法是基于動作Q值實現的,為更好地分辨區域,不再使用單一觀測選取策略,而是綜合考慮機器人在環境中某一位置前后左右4個方向的觀測值:
Qv=?[Math Processing Error]Q(s,a)+Q90(s,a)+Q180(s,a)+Q270(s,a)4
(9)
式中:Qv為動作均值;Q(s,?a)、Q90(s,?a)、Q180(s,?a)及Q270(s,?a)為機器人在起始位置每向右旋轉90°?度所選動作的Q值.同時定義?[Math Processing Error]Qv0,用于表示環境控制策略的動作均值,([Math Processing Error]Qv1,?[Math Processing Error]Qv2, …,?[Math Processing Error]QvN)用于表示各區域控制策略的動作均值.計算出的各策略動作均值存儲在緩沖區,在結合最大值函數后,可選出擁有最大動作均值的控制策略:
[Math Processing Error]I=max{Qv0,Qv1,…,QvN}
(10)
式中:I為最優策略編號.如果此時選取的是某一區域的控制策略,那么執行該策略直到區域內目標,然后將策略選取權交回.如果此時選取的是環境控制策略,只執行單步動作就將策略選取權交回,其流程如圖6所示.
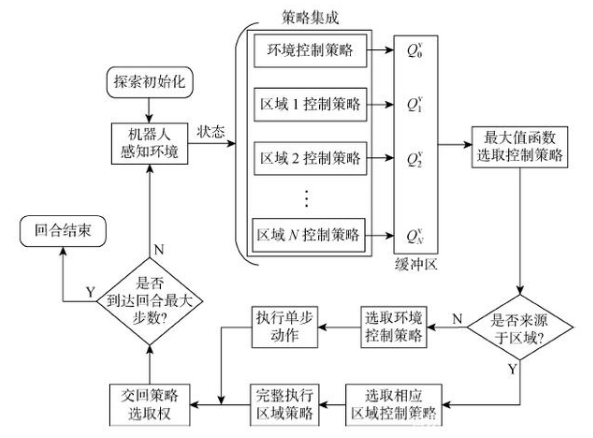
圖6?? 多區域導航流程
Fig.6?? Multi-area navigation process
3 實驗結果與分析
3.1 實驗環境及參數設置
實驗在第一人稱3D游戲平臺DeepMind Lab[22]內進行,在實驗過程中,仿真環境以60幀/s的速度運行,部分運行畫面如圖7所示.動作空間是離散的,但允許細微控制,智能體可執行向前、向后或側向加速,并以小幅度增量旋轉.獎勵通過在環境到達目標獲得,每次接觸目標后,智能體都將被隨機重置到一個新的起點,同時開始下一輪探索.構建測試環境如圖8所示,其中包括單區域和多區域環境.在每個單區域環境中,包含1個目標(+10)和4個促進探索的稀疏獎勵(蘋果,+1).
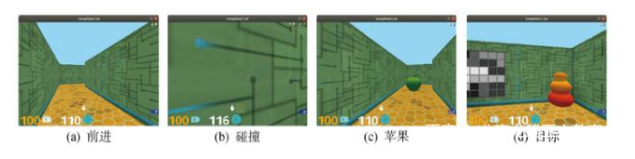
圖7?? 仿真環境運行畫面
Fig.7?? Running screens of simulation environment
?
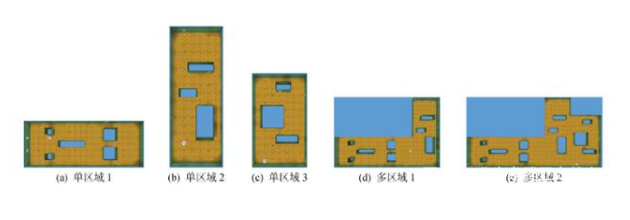
圖8?? 測試環境
Fig.8?? Test environment
區域導航子模塊結構已在2.3節給出,在該模塊中使用具有遺忘門的LSTM[23],除接受卷積編碼的狀態外,LSTM還融合上一時間步的動作和獎勵信息,策略和值函數可由LSTM輸出線性預測所得.卷積層和全連接層后緊接ReLU非線性單元,卷積層濾波器數量、尺寸、跨度以及全連接層和LSTM層參數如表1所示.學習過程中使用8線程異步優勢演員評論(A3C)方法[24]優化參數,ε在探索環境的前106步由1線性降低到0.1,并固定為0.1,學習率從[10-4,5×10-3]區間內按對數均勻分布取樣,折扣因子γ=0.99.機器人學習導航的過程主要以獎勵分值-時間(S-t)圖呈現,獎勵為1 h內(虛擬時間)機器人所獲獎勵與完成回合數的平均值,每個回合機器人執行 4500 步動作.
表1?? 神經網絡參數
Tab.1? Neural network parameters
| 網絡部分 | 動作選取 | 獎勵預測 |
|---|---|---|
| 卷積層1 | 16, 8, 4 | 16, 8, 4 |
| 卷積層2 | 32, 4, 2 | 32, 4, 2 |
| 全連接層 | 256 | 128 |
| LSTM | 256 | 無 |
3.2 訓練方法實驗
3.2.1 景深避障實驗 在結合深度信息探索環境時,需預先設定碰撞閾值,所以在實驗過程中首先研究不同約束值對訓練的影響,然后對比使用不同深度信息探索環境的方法.在測試景深避障過程中只執行導航子模塊中的動作選取部分,不執行獎勵預測部分,實驗在3個單區域環境中進行.
使用不同約束值避障實驗結果如圖9所示,數據為3個單區域平均所得.由圖9可知,當閾值取?[Math Processing Error]0,3區間內不同值時,機器人探索效率和學習效果也各不相同.如果閾值設置為0,也就是只有在機器人撞到障礙物后才給予懲罰,會導致探索效率低下.而當閾值較大時,機器人將過早執行避障措施,間接干擾了導航動作,致使需要更多步數才能獲取獎勵.當閾值為1或2時,機器人既能有效避障,又可維持較高獎勵的導航行為,但由于閾值為2時控制策略缺乏穩定性,因此文中閾值設定為1.
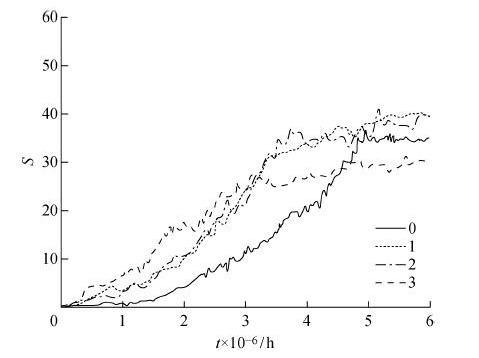
圖9?? 不同閾值實驗結果
Fig.9?? Experiment results of different thresholds
結合不同深度信息探索環境的實驗結果如圖10所示,其中Nav A3C+D2參考文獻[4],深度圖認知參考文獻[25].由圖10可知,Nav A3C+D2通過預測環境深度信息,高效利用學習樣本,可在短時間內掌握控制策略,但該模型中包含兩層LSTM且結合深度預測任務,訓練過程中需消耗更多計算量.而深度圖認知以環境深度信息作為輸入,易于形成景深趨向的控制策略,可高效探索未知環境,但只利用深度信息,忽略了環境的顏色特征,導致機器人無法進一步理解環境.景深避障則是利用深度信息作為碰撞判別依據,使機器人在探索環境過程中有效避障,且不會給訓練帶來額外負擔,不過對目標導向行為沒有實質性的幫助,這也是本文后續增加獎勵預測的原因.
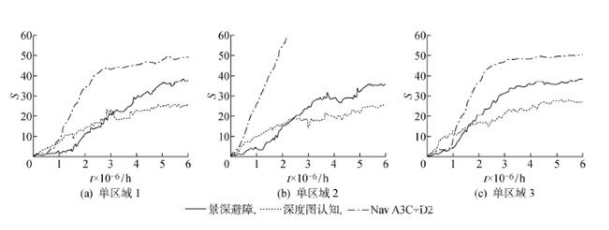
圖10?? 探索方法實驗結果
Fig.10?? Experiment results of exploration method
3.2.2 獎勵預測實驗 在獎勵預測任務中,要求機器人在給定連續3幀的情況下,預測在隨后不可見幀中的獎勵,但無需預測獎勵的具體數值,只需給出有無獎勵即可.同時,使用經驗池抽取樣本,忽略原始數據中獎勵序列的概率分布,以更高的概率抽取獎勵事件.實驗在單區域環境中進行,在測試獎勵預測過程中不使用景深避障,實驗結果如圖11所示.由圖11可知,在增加獎勵預測后,機器人可在相同時間內,學習到更高獎勵的導航策略,并在一定程度上穩定學習過程.
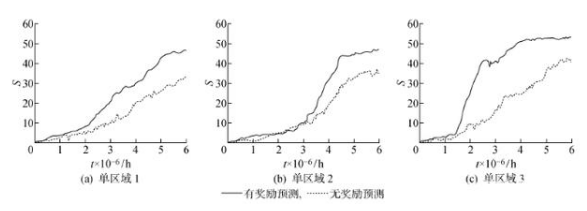
圖11?? 獎勵預測實驗結果
Fig.11?? Experiment results of reward prediction
為進一步證明獎勵預測對空間表征的影響,抽取[4×106,5×106] h區間內的一個動作序列構建價值函數-時間圖(v-t圖),其結果如圖12所示.由圖12可知,在首次找到目標后,具有獎勵預測的機器人可在隨后的探索中以更少的動作再次到達目標,從而提高單個回合內所獲獎勵.由此可知,共享卷積層對模型性能起著決定性作用,同時訓練動作選取和獎勵預測,可使卷積層內核捕捉到獎勵的相關信息,并將包含獎勵存在和位置的特征給予LSTM,形成對獎勵敏感的空間表征,促進目標導向的控制策略.
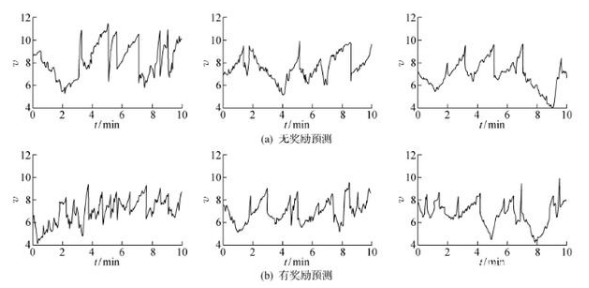
圖12?? 價值函數-時間圖
Fig.12?? Value functions versus time
3.3 區域導航實驗
3.3.1 單區域導航實驗 為驗證區域化模型在分布式環境中的性能,分別在單區域及多區域環境中進行測試.在單區域環境中,并不涉及策略的切換與結合,因此只使用區域導航子模塊在環境中學習控制策略,并使用Nav A3C+D2和終身學習模型中的深度技巧模塊進行對比.
單區域環境導航實驗結果如圖13所示,由圖13可知,由于本身以DQN模型為基礎,深度技巧模塊難以適應部分可見環境,在所有單區域環境中均表現出學習時間長,所獲獎勵少的缺陷.而在結合景深避障和獎勵預測后,區域導航子模塊在單區域1和單區域3中展現出與Nav A3C+D2類似的學習能力,但在單區域2內,由于環境特性,Nav A3C+D2具有更好的控制策略.
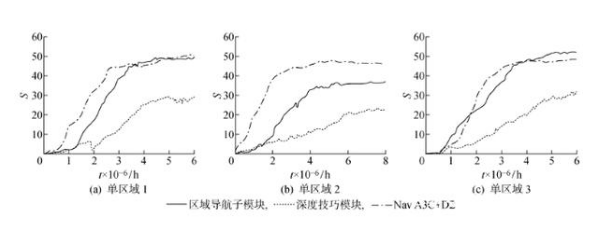
圖13?? 單區域導航實驗結果
Fig.13?? Experiment result of single-area navigation
3.3.2 多區域導航實驗 多區域環境由單區域環境組合而成,圖8(d)中包含兩個區域,圖8(e)中包含3個區域.在訓練過程中,無論環境中包含幾個區域,區域化模型和終身學習模型都會根據人工劃分的區域分配相應的子模塊在各區域內獨立學習,而Nav A3C+D2需在整個環境內學習控制策略.與單區域不同,在多區域環境中,當機器人接觸到目標后,將被隨機重置到分布式環境中的任一位置,而不再局限于單個區域.
多區域導航實驗結果如圖14所示,其中,在各區域策略穩定收斂前,區域化模型和終身學習模型獎勵為同一時間內各子模塊所獲獎勵的平均值.待策略集成后,獎勵為區域間導航所得.由圖14可知,在分布式環境中,隨著區域數量的增加,受神經網絡記憶能力限制,使用單一模型的Nav A3C+D2和區域導航子模塊的性能會隨之降低,雖然增加LSTM層數可在一定程度上減緩性能下降,但無法解決根本問題,且增加的訓練難度也是難以承受的.區域化模型利用子模塊在各區域內學習控制策略,并通過策略的切換和結合實現區域間導航,受區域數量的影響較小.與此同時,由于使用了改進的訓練方法,維持了較高的學習效率和導航性能.終身學習模型同樣可實現策略的切換和結合,但由于模型本身限制,難以形成高獎勵的控制策略.同時可以看出,區域之間策略的切換和結合并不完美,這也是圖中策略集成后獎勵降低的原因.
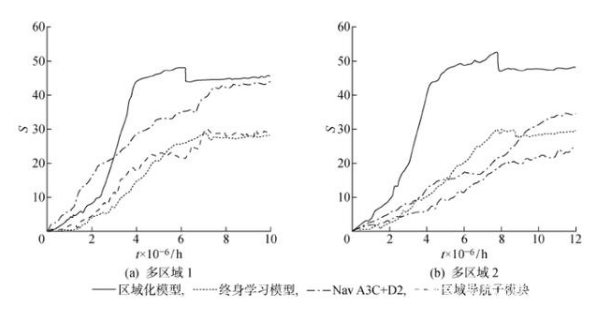
圖14?? 多區域導航實驗結果
Fig.14?? Experiment results of multi-area navigation
4 結語
本文提出一種區域化視覺導航方法,面對分布式環境,該方法使用子模塊在各區域內獨立學習控制策略,并通過區域化模型集成控制策略完成大范圍導航.經實驗驗證,相比單一模型,區域化模型受神經網絡記憶能力和區域數量影響較小,可更好地完成多區域環境下的導航任務,且在訓練過程中結合景深避障和獎勵預測,使得子模塊可高效探索環境,同時獲取良好導航策略.實際上,區域化并不是一個陌生的詞語,它早已出現在生活的方方面面,如人類居住的環境就是根據區域劃分.此外,區域劃分還在道路規劃、災害救援和無人機導航等領域發揮作用,其中最具代表性的是醫學圖片研究中的區域分割,該方法是分辨病變位置和種類的基礎.本文提出的區域化導航方法可應用于倉儲機器人、無人駕駛車輛、無人機及無人船等無人智能系統.但文中環境分割通過人工實現,未來將在自主區域劃分做出進一步研究.
?
關注微信公眾號:人工智能技術與咨詢。了解更多咨詢!
編輯:fqj

































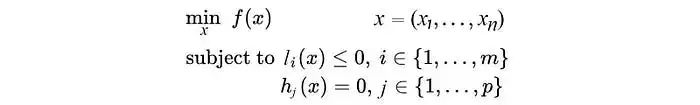













 工商網監
工商網監
評論