 電子發(fā)燒友App
電子發(fā)燒友App


2017年開(kāi)始阿里HBase走向公有云,我們有計(jì)劃的在逐步將阿里內(nèi)部的高可用技術(shù)提供給外部客戶(hù),目前已經(jīng)上線(xiàn)了同城主備,將作為我們后續(xù)高可用能力發(fā)展的一個(gè)基礎(chǔ)平臺(tái)。本文分四個(gè)部分回顧阿里HBase在高可用方面的發(fā)展:大集群、MTTF&MTTR、容災(zāi)、極致體驗(yàn),希望能給大家?guī)?lái)一些共鳴和思考。
大集群
一個(gè)業(yè)務(wù)一個(gè)集群在初期很簡(jiǎn)便,但隨著業(yè)務(wù)增多會(huì)加重運(yùn)維負(fù)擔(dān),更重要的是無(wú)法有效利用資源。首先每一個(gè)集群都要有Zookeeper、Master、NameNode這三種角色,固定的消耗3臺(tái)機(jī)器。其次有些業(yè)務(wù)重計(jì)算輕存儲(chǔ),有些業(yè)務(wù)重存儲(chǔ)輕計(jì)算,分離模式無(wú)法削峰填谷。因此從2013年開(kāi)始阿里HBase就走向了大集群模式,單集群節(jié)點(diǎn)規(guī)模達(dá)到700+。
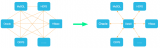
隔離性是大集群的關(guān)鍵難題。保障A業(yè)務(wù)異常流量不會(huì)沖擊到B業(yè)務(wù),是非常重要的能力,否則用戶(hù)可能拒絕大集群模式。阿里HBase引入了分組概念“group”,其核心思想為:共享存儲(chǔ)、隔離計(jì)算
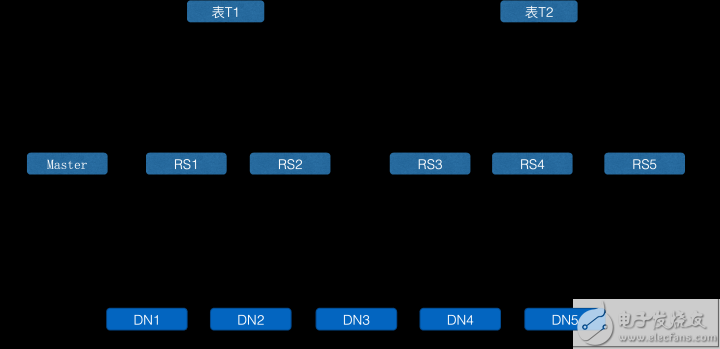
如上圖所示,一個(gè)集群內(nèi)部被劃分成多個(gè)分組,一個(gè)分組至少包含一臺(tái)服務(wù)器,一個(gè)服務(wù)器同一時(shí)間只能屬于一個(gè)分組,但是允許服務(wù)器在分組之間進(jìn)行轉(zhuǎn)移,也就是分組本身是可以擴(kuò)容和縮容的。一張表只能部署在一個(gè)分組上,可以轉(zhuǎn)移表到其它的分組。可以看到,表T1讀寫(xiě)經(jīng)過(guò)的RegionServer和表T2讀寫(xiě)經(jīng)過(guò)的RegionServer是完全隔離的,因此在CPU、內(nèi)存上都物理隔離,但是下層使用的HDFS文件系統(tǒng)是共享的,因此多個(gè)業(yè)務(wù)可以共享一個(gè)大的存儲(chǔ)池子,充分提升存儲(chǔ)利用率。開(kāi)源社區(qū)在HBase2.0版本上引入了RegionServerGroup。
壞盤(pán)對(duì)共享存儲(chǔ)的沖擊:由于HDFS機(jī)制上的特點(diǎn),每一個(gè)Block的寫(xiě)入會(huì)隨機(jī)選擇3個(gè)節(jié)點(diǎn)作為Pipeline,如果某一臺(tái)機(jī)器出現(xiàn)了壞盤(pán),那么這個(gè)壞盤(pán)可能出現(xiàn)在多個(gè)Pipeline中,造成單點(diǎn)故障全局抖動(dòng)。現(xiàn)實(shí)場(chǎng)景中就是一塊盤(pán)壞,同一時(shí)間影響到幾十個(gè)客戶(hù)給你發(fā)信息打電話(huà)!特別如果慢盤(pán)、壞盤(pán)不及時(shí)處理,最終可能導(dǎo)致寫(xiě)入阻塞。阿里HBase目前規(guī)模在1萬(wàn)+臺(tái)機(jī)器,每周大概有22次磁盤(pán)損壞問(wèn)題。我們?cè)诮鉀Q這個(gè)問(wèn)題上做了兩件事,第一是縮短影響時(shí)間,對(duì)慢盤(pán)、壞盤(pán)進(jìn)行監(jiān)控報(bào)警,提供自動(dòng)化處理平臺(tái)。第二是在軟件上規(guī)避單點(diǎn)壞盤(pán)對(duì)系統(tǒng)的影響,在寫(xiě)HDFS的時(shí)候并發(fā)的寫(xiě)三個(gè)副本,只要兩個(gè)副本成功就算成功,如果第三個(gè)副本超時(shí)則將其放棄。另外如果系統(tǒng)發(fā)現(xiàn)寫(xiě)WAL異常(副本數(shù)少于3)會(huì)自動(dòng)滾動(dòng)產(chǎn)生一個(gè)新的日志文件(重新選擇pipeline,大概率規(guī)避壞點(diǎn))。最后HDFS自身在高版本也具備識(shí)別壞盤(pán)和自動(dòng)剔除的能力。
客戶(hù)端連接對(duì)Zookeeper的沖擊:客戶(hù)端訪(fǎng)問(wèn)hbase會(huì)和Zookeeper建立長(zhǎng)連接,HBase自身的RegionServer也會(huì)和Zookeeper建立長(zhǎng)連接。大集群意味著大量業(yè)務(wù),大量客戶(hù)端的鏈接,在異常情況下客戶(hù)端的鏈接過(guò)多會(huì)影響RegionServer與Zookeeper的心跳,導(dǎo)致宕機(jī)。我們?cè)谶@里的應(yīng)對(duì)首先是對(duì)單個(gè)IP的鏈接數(shù)進(jìn)行了限制,其次提供了一種分離客戶(hù)端與服務(wù)端鏈接的方案 HBASE-20159
MTTF&MTTR
穩(wěn)定性是生命線(xiàn),隨著阿里業(yè)務(wù)的發(fā)展,HBase逐步擴(kuò)大在線(xiàn)場(chǎng)景的支持,對(duì)穩(wěn)定性的要求是一年更比一年高。衡量系統(tǒng)可靠性的常用指標(biāo)是MTTF(平均失效時(shí)間)和MTTR(平均恢復(fù)時(shí)間)
MTTF(mean time to failure)
造成系統(tǒng)失效的來(lái)源有: 硬件失效,比如壞盤(pán)、網(wǎng)卡損壞、機(jī)器宕機(jī)等 自身缺陷,一般指程序自身的bug或者性能瓶頸 運(yùn)維故障,由于不合理的操作導(dǎo)致的故障 服務(wù)過(guò)載,突發(fā)熱點(diǎn)、超大的對(duì)象、過(guò)濾大量數(shù)據(jù)的請(qǐng)求 依賴(lài)失效,依賴(lài)的HDFS、Zookeeper組件出現(xiàn)不可用導(dǎo)致HBase進(jìn)程退出
下面我介紹一下阿里云HBase在穩(wěn)定性上遇到的幾個(gè)代表性問(wèn)題:(注:慢盤(pán)、壞盤(pán)的問(wèn)題已經(jīng)在大集群一節(jié)中涉及,這里不再重復(fù))
周期性的FGC導(dǎo)致進(jìn)程退出
在支持菜鳥(niǎo)物流詳情業(yè)務(wù)的時(shí)候,我們發(fā)現(xiàn)機(jī)器大概每隔兩個(gè)月就會(huì)abort一次,因?yàn)閮?nèi)存碎片化問(wèn)題導(dǎo)致Promotion Fail,進(jìn)而引發(fā)FGC。由于我們使用的內(nèi)存規(guī)格比較大,所以一次FGC的停頓時(shí)間超過(guò)了與Zookeeper的心跳,導(dǎo)致ZK session expired,HBase進(jìn)程自殺。我們定位問(wèn)題是由于BlockCache引起的,由于編碼壓縮的存在,內(nèi)存中的block大小是不一致的,緩存的換入換出行為會(huì)逐步的切割內(nèi)存為非常小的碎片。我們開(kāi)發(fā)了BucketCache,很好的解決了內(nèi)存碎片化的問(wèn)題,然后進(jìn)一步發(fā)展了SharedBucketCache,使得從BlockCache里面反序列化出來(lái)的對(duì)象可以被共享復(fù)用,減少運(yùn)行時(shí)對(duì)象的創(chuàng)建,從而徹底的解決了FGC的問(wèn)題。
寫(xiě)入HDFS失敗導(dǎo)致進(jìn)程退出
HBase依賴(lài)倆大外部組件,Zookeeper和HDFS。Zookeeper從架構(gòu)設(shè)計(jì)上就是高可用的,HDFS也支持HA的部署模式。當(dāng)我們假設(shè)一個(gè)組件是可靠的,然后基于這個(gè)假設(shè)去寫(xiě)代碼,就會(huì)產(chǎn)生隱患。因?yàn)檫@個(gè)“可靠的”組件會(huì)失效,HBase在處理這種異常時(shí)非常暴力,立即執(zhí)行自殺(因?yàn)榘l(fā)生了不可能的事情),寄希望于通過(guò)Failover來(lái)轉(zhuǎn)移恢復(fù)。有時(shí)HDFS可能只是暫時(shí)的不可用,比如部分Block沒(méi)有上報(bào)而進(jìn)入保護(hù)模式,短暫的網(wǎng)絡(luò)抖動(dòng)等,如果HBase因此大面積重啟,會(huì)把本來(lái)10分鐘的影響擴(kuò)大到小時(shí)級(jí)別。我們?cè)谶@個(gè)問(wèn)題上的方案是優(yōu)化異常處理,對(duì)于可以規(guī)避的問(wèn)題直接處理掉,對(duì)于無(wú)法規(guī)避的異常進(jìn)行重試&等待。
并發(fā)大查詢(xún)導(dǎo)致機(jī)器停擺
HBase的大查詢(xún),通常指那些帶有Filter的Scan,在RegionServer端讀取和過(guò)濾大量的數(shù)據(jù)塊。如果讀取的數(shù)據(jù)經(jīng)常不在緩存,則很容易造成IO過(guò)載;如果讀取的數(shù)據(jù)大多在緩存中,則很容易因?yàn)榻鈮骸⑿蛄谢炔僮髟斐蒀PU過(guò)載;總之當(dāng)有幾十個(gè)這樣的大請(qǐng)求并發(fā)的在服務(wù)器端執(zhí)行時(shí),服務(wù)器load會(huì)迅速飆升,系統(tǒng)響應(yīng)變慢甚至表現(xiàn)的像卡住了。這里我們研發(fā)了大請(qǐng)求的監(jiān)控和限制,當(dāng)一個(gè)請(qǐng)求消耗資源超過(guò)一定閾值就會(huì)被標(biāo)記為大請(qǐng)求,日志會(huì)記錄。一個(gè)服務(wù)器允許的并發(fā)大請(qǐng)求存在上限,如果超過(guò)這個(gè)上限,后來(lái)的大請(qǐng)求就會(huì)被限速。如果一個(gè)請(qǐng)求在服務(wù)器上運(yùn)行了很久都沒(méi)有結(jié)束,但客戶(hù)端已經(jīng)判斷超時(shí),那么系統(tǒng)會(huì)主動(dòng)中斷掉這個(gè)大請(qǐng)求。該功能的上線(xiàn)解決了支付寶賬單系統(tǒng)因?yàn)闊狳c(diǎn)查詢(xún)而導(dǎo)致的性能抖動(dòng)問(wèn)題。
大分區(qū)Split緩慢
在線(xiàn)上我們偶爾會(huì)遇到某個(gè)分區(qū)的數(shù)量在幾十GB到幾個(gè)TB,一般都是由于分區(qū)不合理,然后又在短時(shí)間內(nèi)灌入了大量的數(shù)據(jù)。這種分區(qū)不但數(shù)據(jù)量大,還經(jīng)常文件數(shù)量超級(jí)多,當(dāng)有讀落在這個(gè)分區(qū)時(shí),一定會(huì)是一個(gè)大請(qǐng)求,如果不及時(shí)分裂成更小的分區(qū)就會(huì)造成嚴(yán)重影響。這個(gè)分裂的過(guò)程非常慢,HBase只能從1個(gè)分區(qū)分裂為2個(gè)分區(qū),并且要等待執(zhí)行一輪Compaction才能進(jìn)行下一輪分裂。假設(shè)分區(qū)大小1TB,那么分裂成小于10GB的128個(gè)分區(qū)需要分裂7輪,每一輪要執(zhí)行一次Compaction(讀取1TB數(shù)據(jù),寫(xiě)出1TB數(shù)據(jù)),而且一個(gè)分區(qū)的Compaction只能由一臺(tái)機(jī)器執(zhí)行,所以第一輪最多只有2臺(tái)機(jī)器參與,第二輪4臺(tái),第三輪8臺(tái)。。。,并且實(shí)際中需要人為干預(yù)balance。整個(gè)過(guò)程做下來(lái)超過(guò)10小時(shí),這還是假設(shè)沒(méi)有新數(shù)據(jù)寫(xiě)入,系統(tǒng)負(fù)載正常。面對(duì)這個(gè)問(wèn)題我們?cè)O(shè)計(jì)了“級(jí)聯(lián)分裂”,可以不執(zhí)行Compaction就進(jìn)入下一次分裂,先快速的把分區(qū)拆分完成,然后一把執(zhí)行Compaction。
前面講的都是點(diǎn),關(guān)于如何解決某個(gè)頑疾。導(dǎo)致系統(tǒng)失效的情況是多種多樣的,特別一次故障中可能交叉著多個(gè)問(wèn)題,排查起來(lái)異常困難。現(xiàn)代醫(yī)學(xué)指出醫(yī)院應(yīng)當(dāng)更多投入預(yù)防而不是治療,加強(qiáng)體檢,鼓勵(lì)早就醫(yī)。早一步也許就是個(gè)感冒,晚一步也許就變成了癌癥。這也適用于分布式系統(tǒng),因?yàn)橄到y(tǒng)的復(fù)雜性和自愈能力,一些小的問(wèn)題不會(huì)立即造成不可用,比如內(nèi)存泄漏、Compaction積壓、隊(duì)列積壓等,但終將在某一刻引發(fā)雪崩。應(yīng)對(duì)這種問(wèn)題,我們提出了“健康診斷”系統(tǒng),用來(lái)預(yù)警那些暫時(shí)還沒(méi)有使系統(tǒng)失效,但明顯超過(guò)正常閾值的指標(biāo)。“健康診斷”系統(tǒng)幫助我們攔截了大量的異常case,也在不停的演進(jìn)其診斷智能。
MTTR(mean time to repair)
百密終有一疏,系統(tǒng)總是會(huì)失效,特別的像宕機(jī)這種Case是低概率但一定會(huì)發(fā)生的事件。我們要做的是去容忍,降低影響面,加速恢復(fù)時(shí)間。HBase是一個(gè)可自愈的系統(tǒng),單個(gè)節(jié)點(diǎn)宕機(jī)觸發(fā)Failover,由存活的其它節(jié)點(diǎn)來(lái)接管分區(qū)服務(wù),在分區(qū)對(duì)外服務(wù)之前,必須首先通過(guò)回放日志來(lái)保證數(shù)據(jù)讀寫(xiě)一致性。整個(gè)過(guò)程主要包括Split Log、Assign Region、Replay Log三個(gè)步驟。hbase的計(jì)算節(jié)點(diǎn)是0冗余,所以一個(gè)節(jié)點(diǎn)宕機(jī),其內(nèi)存中的狀態(tài)必須全部回放,這個(gè)內(nèi)存一般可以認(rèn)為在10GB~20GB左右。我們假設(shè)整個(gè)集群的數(shù)據(jù)回放能力是 R GB/s,單個(gè)節(jié)點(diǎn)宕機(jī)需要恢復(fù) M GB的數(shù)據(jù),那么宕機(jī)N個(gè)節(jié)點(diǎn)就需要 M * N / R 秒,這里表達(dá)的一個(gè)信息是:如果R不足夠大,那么宕機(jī)越多,恢復(fù)時(shí)間越不可控,那么影響R的因素就至關(guān)重要,在Split Log、Assign Region、Replay Log三個(gè)過(guò)程中,通常Split Log、Assign Region的擴(kuò)展性存在問(wèn)題,核心在于其依賴(lài)單點(diǎn)。Split Log是把WAL文件按分區(qū)拆分成小的文件,這個(gè)過(guò)程中需要?jiǎng)?chuàng)建大量的新文件,這個(gè)工作只能由一臺(tái)NameNode來(lái)完成,并且其效率也并不高。Assign Region是由HBase Master來(lái)管理,同樣是一個(gè)單點(diǎn)。阿里HBase在Failover方面的核心優(yōu)化是采用了全新的MTTR2架構(gòu),取消了Split Log這一步驟,在Assign Region上也做了優(yōu)先Meta分區(qū)、Bulk Assign、超時(shí)優(yōu)化等多項(xiàng)優(yōu)化措施,相比社區(qū)的Failover效率提升200%以上
從客戶(hù)角度看故障,是2分鐘的流量跌零可怕還是10分鐘的流量下降5%可怕?我想可能是前者。由于客戶(hù)端的線(xiàn)程池資源有限,HBase的單機(jī)宕機(jī)恢復(fù)過(guò)程可能造成業(yè)務(wù)側(cè)的流量大跌,因?yàn)榫€(xiàn)程都阻塞在訪(fǎng)問(wèn)異常機(jī)器上了,2%的機(jī)器不可用造成業(yè)務(wù)流量下跌90%是很難接受的。我們?cè)诳蛻?hù)端開(kāi)發(fā)了一種Fast Fail的機(jī)制,可以主動(dòng)發(fā)現(xiàn)異常服務(wù)器,并快速拒絕發(fā)往這個(gè)服務(wù)器的請(qǐng)求,從而釋放線(xiàn)程資源,不影響其它分區(qū)服務(wù)器的訪(fǎng)問(wèn)。項(xiàng)目名稱(chēng)叫做DeadServerDetective
容災(zāi)
容災(zāi)是重大事故下的求生機(jī)制,比如地震、海嘯等自然災(zāi)害造成毀滅性打擊,比如軟件變更等造成完全不可控的恢復(fù)時(shí)間,比如斷網(wǎng)造成服務(wù)癱瘓、恢復(fù)時(shí)間未知。從現(xiàn)實(shí)經(jīng)驗(yàn)來(lái)看,自然災(zāi)害在一個(gè)人的一生中都難遇到,斷網(wǎng)一般是一個(gè)年級(jí)別的事件,而軟件變更引發(fā)的問(wèn)題可能是月級(jí)別的。軟件變更是對(duì)運(yùn)維能力、內(nèi)核能力、測(cè)試能力等全方位的考驗(yàn),變更過(guò)程的操作可能出錯(cuò),變更的新版本可能存在未知Bug。另一個(gè)方面為了不斷滿(mǎn)足業(yè)務(wù)的需求又需要加速內(nèi)核迭代,產(chǎn)生更多的變更。
容災(zāi)的本質(zhì)是基于隔離的冗余,要求在資源層面物理隔離、軟件層面版本隔離、運(yùn)維層面操作隔離等,冗余的服務(wù)之間保持最小的關(guān)聯(lián)性,在災(zāi)難發(fā)生時(shí)至少有一個(gè)副本存活。阿里HBase在幾年前開(kāi)始推進(jìn)同城主備、異地多活,目前99%的集群至少有一個(gè)備集群,主備集群是HBase可以支持在線(xiàn)業(yè)務(wù)的一個(gè)強(qiáng)保障。主備模式下的兩個(gè)核心問(wèn)題是數(shù)據(jù)復(fù)制和流量切換
數(shù)據(jù)復(fù)制
選擇什么樣的復(fù)制方式,是同步復(fù)制還是異步復(fù)制,是否要保序?主要取決于業(yè)務(wù)對(duì)系統(tǒng)的需求,有些要求強(qiáng)一致,有些要求session一致,有些可以接受最終一致。占在HBase的角度上,我們服務(wù)的大量業(yè)務(wù)在災(zāi)難場(chǎng)景下是可以接受最終一致性的(我們也研發(fā)了同步復(fù)制機(jī)制,但只有極少的場(chǎng)景),因此本文主要專(zhuān)注在異步復(fù)制的討論上。很長(zhǎng)一段時(shí)間我們采用社區(qū)的異步復(fù)制機(jī)制(HBase Replication),這是HBase內(nèi)置的同步機(jī)制。
同步延遲的根因定位是第一個(gè)難題,因?yàn)橥芥溌飞婕鞍l(fā)送方、通道、接受方3個(gè)部分,排查起來(lái)有難度。我們?cè)鰪?qiáng)了同步相關(guān)的監(jiān)控和報(bào)警。
熱點(diǎn)容易引發(fā)同步延遲是第二個(gè)難題。HBase Replication采用推的方式進(jìn)行復(fù)制,讀取WAL日志然后進(jìn)行轉(zhuǎn)發(fā),發(fā)送線(xiàn)程和HBase寫(xiě)入引擎是在同一臺(tái)RegionServer的同一個(gè)進(jìn)程里。當(dāng)某臺(tái)RegionServer寫(xiě)入熱點(diǎn)時(shí),就需要更多的發(fā)送能力,但寫(xiě)入熱點(diǎn)本身就擠占了更多的系統(tǒng)資源,寫(xiě)入和同步資源爭(zhēng)搶。阿里HBase做了兩個(gè)方面的優(yōu)化,第一提高同步性能,減少單位MB同步的資源消耗;第二研發(fā)了遠(yuǎn)程消耗器,使其它空閑的機(jī)器可以協(xié)助熱點(diǎn)機(jī)器同步日志。
資源需求、迭代方式的不匹配是第三個(gè)難題。數(shù)據(jù)復(fù)制本身是不需要磁盤(pán)IO的,只消耗帶寬和CPU,而HBase對(duì)磁盤(pán)IO有重要依賴(lài);數(shù)據(jù)復(fù)制的worker本質(zhì)上是無(wú)狀態(tài)的,重啟不是問(wèn)題,可以斷點(diǎn)續(xù)傳,而HBase是有狀態(tài)的,必須先轉(zhuǎn)移分區(qū)再重啟,否則會(huì)觸發(fā)Failover。一個(gè)輕量級(jí)的同步組件和重量級(jí)的存儲(chǔ)引擎強(qiáng)耦合在一起,同步組件的每一次迭代升級(jí)必須同時(shí)重啟HBase。一個(gè)重啟就可以解決的同步問(wèn)題,因?yàn)橥瑫r(shí)要重啟hbase而影響線(xiàn)上讀寫(xiě)。一個(gè)擴(kuò)容CPU或者總帶寬的問(wèn)題被放大到要擴(kuò)容hbase整體。
綜上所述,阿里HBase最終將同步組件剝離了出來(lái)作為一個(gè)獨(dú)立的服務(wù)來(lái)建設(shè),解決了熱點(diǎn)和耦合的問(wèn)題,在云上這一服務(wù)叫做BDS Replication。隨著異地多活的發(fā)展,集群之間的數(shù)據(jù)同步關(guān)系開(kāi)始變得復(fù)雜,為此我們開(kāi)發(fā)了一個(gè)關(guān)于拓?fù)潢P(guān)系和鏈路同步延遲的監(jiān)控,并且在類(lèi)環(huán)形的拓?fù)潢P(guān)系中優(yōu)化了數(shù)據(jù)的重復(fù)發(fā)送問(wèn)題。
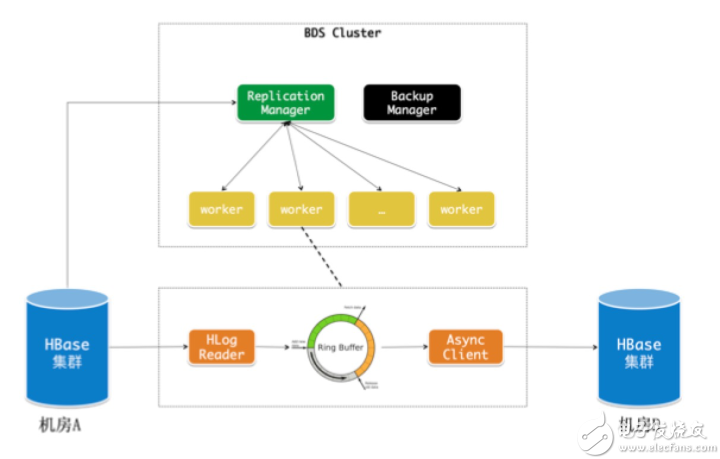
BDS Replication
流量切換
在具備主備集群的前提下,災(zāi)難期間需要快速的把業(yè)務(wù)流量切換到備份集群。阿里HBase改造了HBase客戶(hù)端,流量的切換發(fā)生在客戶(hù)端內(nèi)部,通過(guò)高可用的通道將切換命令發(fā)送給客戶(hù)端,客戶(hù)端會(huì)關(guān)閉舊的鏈接,打開(kāi)與備集群的鏈接,然后重試請(qǐng)求。

阿里云同城主備
切換瞬間對(duì)Meta服務(wù)的沖擊:hbase客戶(hù)端首次訪(fǎng)問(wèn)一個(gè)分區(qū)前需要請(qǐng)求Meta服務(wù)來(lái)獲取分區(qū)的地址,切換瞬間所有客戶(hù)端并發(fā)的訪(fǎng)問(wèn)Meta服務(wù),現(xiàn)實(shí)中并發(fā)可能在幾十萬(wàn)甚至更多造成服務(wù)過(guò)載,請(qǐng)求超時(shí)后客戶(hù)端又再次重試,造成服務(wù)器一直做無(wú)用功,切換一直無(wú)法成功。針對(duì)這個(gè)問(wèn)題我們改造了Meta表的緩存機(jī)制,極大地提高了Meta表的吞吐能力,可以應(yīng)對(duì)百萬(wàn)級(jí)別的請(qǐng)求。同時(shí)在運(yùn)維上隔離了Meta分區(qū)與數(shù)據(jù)分區(qū),防止相互影響。
從一鍵切換走向自動(dòng)切換。一鍵切換還是要依賴(lài)報(bào)警系統(tǒng)和人工操作,現(xiàn)實(shí)中至少也要分鐘級(jí)別才能響應(yīng),如果是晚上可能要10分鐘以上。阿里HBase在演進(jìn)自動(dòng)切換過(guò)程中有兩個(gè)思路,最早是通過(guò)增加一個(gè)第三方仲裁,實(shí)時(shí)的給每一個(gè)系統(tǒng)打健康分?jǐn)?shù),當(dāng)系統(tǒng)健康分低于一個(gè)閾值,并且其備庫(kù)是健康的情況下,自動(dòng)執(zhí)行切換命令。這個(gè)仲裁系統(tǒng)還是比價(jià)復(fù)雜的,首先其部署上要保持網(wǎng)絡(luò)獨(dú)立,其次其自身必須是高可靠的,最后健康分的正確性需要保證。仲裁系統(tǒng)的健康判斷是從服務(wù)器視角出發(fā)的,但從客戶(hù)端角度來(lái)講,有些時(shí)候服務(wù)器雖然活著但是已經(jīng)不正常工作了,可能持續(xù)的FGC,也可能出現(xiàn)了持續(xù)網(wǎng)絡(luò)抖動(dòng)。所以第二個(gè)思路是在客戶(hù)端進(jìn)行自動(dòng)切換,客戶(hù)端通過(guò)失敗率或其它規(guī)則來(lái)判定可用性,超過(guò)一定閾值則執(zhí)行切換。
極致體驗(yàn)
在風(fēng)控和推薦場(chǎng)景下,請(qǐng)求的RT越低,業(yè)務(wù)在單位時(shí)間內(nèi)可以應(yīng)用的規(guī)則就越多,分析就越準(zhǔn)確。要求存儲(chǔ)引擎高并發(fā)、低延遲、低毛刺,要高速且平穩(wěn)的運(yùn)行。阿里HBase團(tuán)隊(duì)在內(nèi)核上研發(fā)CCSMAP優(yōu)化寫(xiě)入緩存,SharedBucketCache優(yōu)化讀取緩存,IndexEncoding優(yōu)化塊內(nèi)搜索,加上無(wú)鎖隊(duì)列、協(xié)程、ThreadLocal Counter等等技術(shù),再結(jié)合阿里JDK團(tuán)隊(duì)的ZGC垃圾回收算法,在線(xiàn)上做到了單集群P999延遲小于15ms。另一個(gè)角度上,風(fēng)控和推薦等場(chǎng)景并不要求強(qiáng)一致,其中有一些數(shù)據(jù)是離線(xiàn)導(dǎo)入的只讀數(shù)據(jù),所以只要延遲不大,可以接受讀取多個(gè)副本。如果主備兩個(gè)副本之間請(qǐng)求毛刺是獨(dú)立事件,那么理論上同時(shí)訪(fǎng)問(wèn)主備可以把毛刺率下降一個(gè)數(shù)量級(jí)。我們基于這一點(diǎn),利用現(xiàn)有的主備架構(gòu),研發(fā)了DualService,支持客戶(hù)端并行的訪(fǎng)問(wèn)主備集群。在一般情況下,客戶(hù)端優(yōu)先讀取主庫(kù),如果主庫(kù)一定時(shí)間沒(méi)有響應(yīng)則并發(fā)請(qǐng)求到備庫(kù),然后等待最先返回的請(qǐng)求。DualService的應(yīng)用獲得的非常大的成功,業(yè)務(wù)接近零抖動(dòng)。
主備模式下還存在一些問(wèn)題。切換的粒度是集群級(jí)別的,切換過(guò)程影響大,不能做分區(qū)級(jí)別切換是因?yàn)橹鱾浞謪^(qū)不一致;只能提供最終一致性模型,對(duì)于一些業(yè)務(wù)來(lái)講不好寫(xiě)代碼邏輯;加上其它因素(索引能力,訪(fǎng)問(wèn)模型)的推動(dòng),阿里HBase團(tuán)隊(duì)基于HBase演進(jìn)了自研的Lindorm引擎,提供一種內(nèi)置的雙Zone部署模式,其數(shù)據(jù)復(fù)制采用推拉組合的模式,同步效率大大提升;雙Zone之間的分區(qū)由GlobalMaster協(xié)調(diào),絕大部分時(shí)間都是一致的,因此可以實(shí)現(xiàn)分區(qū)級(jí)別切換;Lindorm提供強(qiáng)一致、Session一致、最終一致等多級(jí)一致性協(xié)議,方便用戶(hù)實(shí)現(xiàn)業(yè)務(wù)邏輯。目前大部分阿里內(nèi)部業(yè)務(wù)已經(jīng)切換到Lindorm引擎。
零抖動(dòng)是我們追求的最高境界,但必須認(rèn)識(shí)到導(dǎo)致毛刺的來(lái)源可以說(shuō)無(wú)處不在,解決問(wèn)題的前提是定位問(wèn)題,對(duì)每一個(gè)毛刺給出解釋既是用戶(hù)的訴求也是能力的體現(xiàn)。阿里HBase開(kāi)發(fā)了全鏈路Trace,從客戶(hù)端、網(wǎng)絡(luò)、服務(wù)器全鏈路監(jiān)控請(qǐng)求,豐富詳盡的Profiling將請(qǐng)求的路徑、資源訪(fǎng)問(wèn)、耗時(shí)等軌跡進(jìn)行展示,幫助研發(fā)人員快速定位問(wèn)題。
總結(jié)
本文介紹了阿里HBase在高可用上的一些實(shí)踐經(jīng)驗(yàn),結(jié)尾之處與大家分享一些看可用性建設(shè)上的思考,拋磚引玉希望歡迎大家討論。
從設(shè)計(jì)原則上
1 面向用戶(hù)的可用性設(shè)計(jì),在影響面、影響時(shí)間、一致性上進(jìn)行權(quán)衡 MTTF和MTTR是一類(lèi)衡量指標(biāo),但這些指標(biāo)好不一定滿(mǎn)足用戶(hù)期望,這些指標(biāo)是面向系統(tǒng)本身而不是用戶(hù)的。
2 面向失敗設(shè)計(jì),你所依賴(lài)的組件總是會(huì)失敗 千萬(wàn)不要假設(shè)你依賴(lài)的組件不會(huì)失敗,比如你確信HDFS不會(huì)丟數(shù)據(jù),然后寫(xiě)了一個(gè)狀態(tài)機(jī)。但實(shí)際上如果多個(gè)DN同時(shí)宕機(jī)數(shù)據(jù)就是會(huì)丟失,此時(shí)可能你的狀態(tài)機(jī)永遠(yuǎn)陷入混亂無(wú)法推進(jìn)。再小概率的事件總是會(huì)發(fā)生,對(duì)中標(biāo)的用戶(hù)來(lái)講這就是100%。
從實(shí)現(xiàn)過(guò)程上
完善的監(jiān)控體系 監(jiān)控是基礎(chǔ)保障,是最先需要投入力量的地方。100%涵蓋故障報(bào)警,先于用戶(hù)發(fā)現(xiàn)問(wèn)題是監(jiān)控的第一任務(wù)。其次監(jiān)控需要盡可能詳細(xì),數(shù)據(jù)展示友好,可以極大的提高問(wèn)題定位能力。
基于隔離的冗余 冗余是可用性上治本的方法,遇到未知問(wèn)題,單集群非常難保障SLA。所以只要不差錢(qián),一定至少來(lái)一套主備。
精細(xì)的資源控制 系統(tǒng)的異常往往是因?yàn)橘Y源使用的失控,對(duì)CPU、內(nèi)存、IO的精細(xì)控制是內(nèi)核高速穩(wěn)定運(yùn)行的關(guān)鍵。需要投入大量的研發(fā)資源去迭代。
系統(tǒng)自我保護(hù)能力 在請(qǐng)求過(guò)載的情況下,系統(tǒng)應(yīng)該具備類(lèi)如Quota這樣的自我保護(hù)能力,防止雪崩發(fā)生。系統(tǒng)應(yīng)該能識(shí)別一些異常的請(qǐng)求,進(jìn)行限制或者拒絕。
Trace能力 實(shí)時(shí)跟蹤請(qǐng)求軌跡是排查問(wèn)題的利器,需要把Profiling做到盡量詳細(xì)
本文為云棲社區(qū)原創(chuàng)內(nèi)容,未經(jīng)允許不得轉(zhuǎn)載。

























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論