 電子發(fā)燒友App
電子發(fā)燒友App


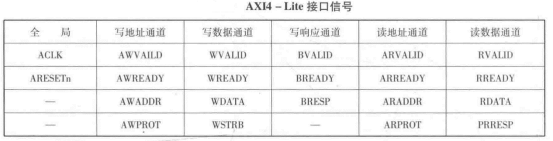
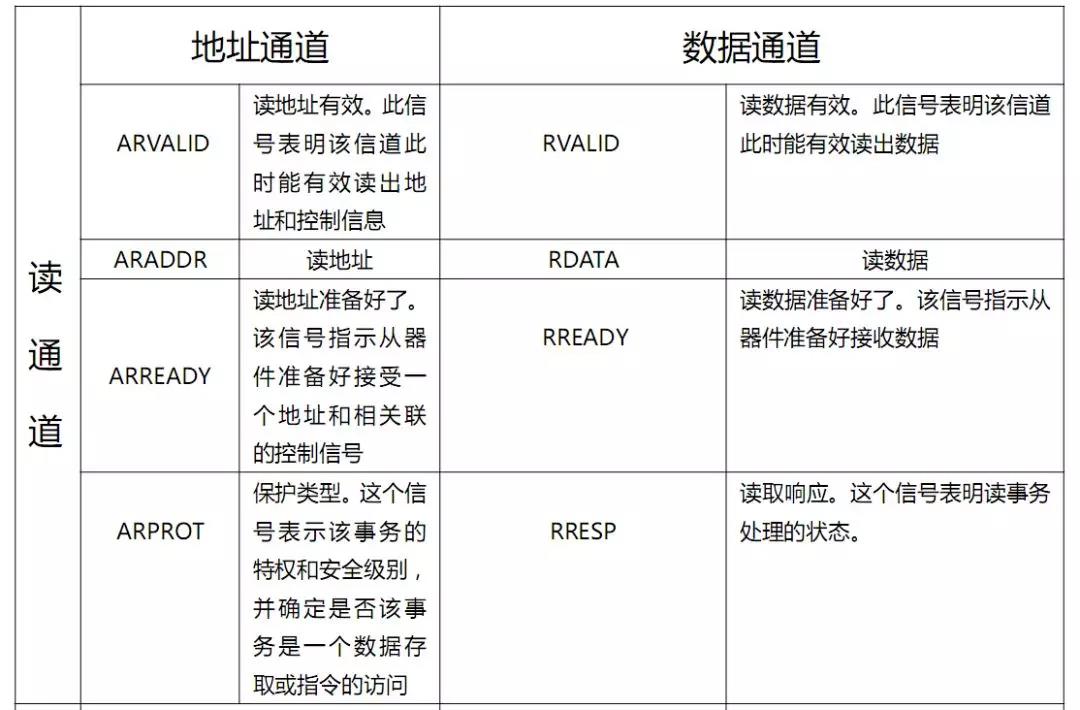
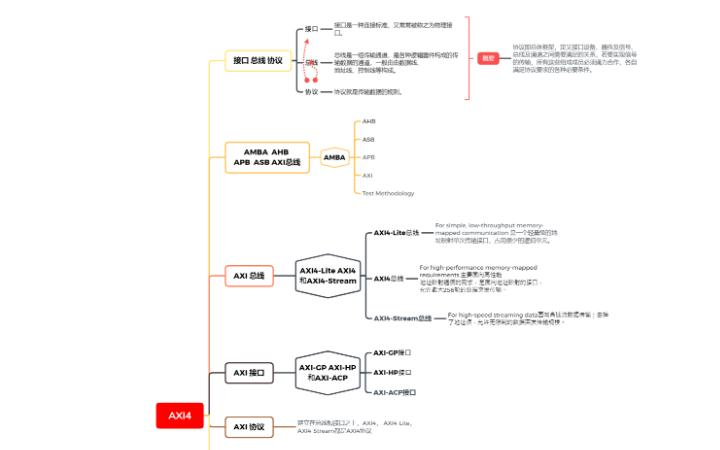
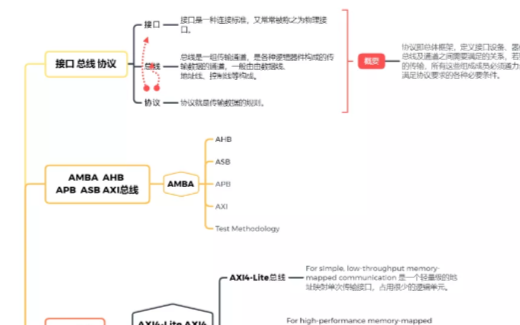
AXI總線協(xié)議
(一)、概述
AXI (高性能擴展總線接口,Advanced eXtensible Interface)是ARM AMBA 單片機總線系列中的一個協(xié)議,是計劃用于高性能、高主頻的系統(tǒng)設計的。AXI協(xié)議是被優(yōu)化用于通過使用Xilinx進行的相應的開發(fā)來做FPGA實現(xiàn),它被用作FPGA 設計的IP 核之間的一種通信方式。
關鍵特性
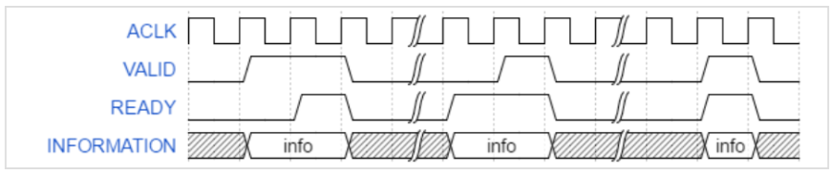
1、地址/控制階段和數(shù)據(jù)階段是分開的,即master(主機)和slave(從機)之間有專門的地址/控制通道,還有專門的數(shù)據(jù)通道。
2、有字節(jié)閘來實現(xiàn)對非對齊數(shù)據(jù)的傳輸。
3、只需發(fā)布起始地址就能做批量數(shù)據(jù)傳輸
4、數(shù)據(jù)的讀寫通道是分離的,可以用來實現(xiàn)低成本的DMA(直接存儲訪問,Direct Memory Access)。除了地址和數(shù)據(jù)通道是分離的之外,讀寫數(shù)據(jù)的通道還是分開的,由此可以看出AXI總線的高速性。
5、可以指定多個需要處理的地址。
6、通信會話可以亂序完成,主要是指的數(shù)據(jù)的亂序,亂序發(fā)送需要有主機的ID進行支撐。
7、為了實現(xiàn)時序收斂,可以方便的加入寄存器,即在用戶logic和user interface處加入想要觀察和處理的用戶邏輯與端口。
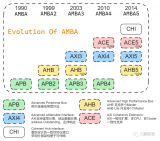
(二)、AXI總線類型
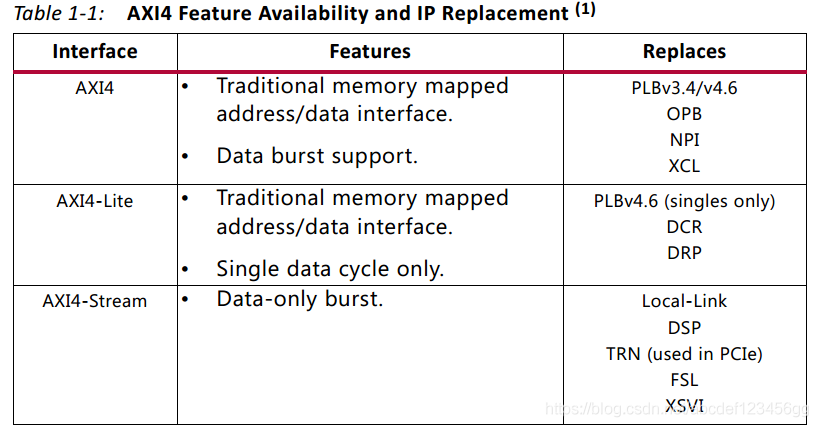
自從2003年AXI1.0版本發(fā)布以后,目前的AXI版本是4.0,AXI接口類型有三種,即AXI4類型、AXI4-Lite類型,AXI4-Stream類型。
AXI4類型:最高性能的接口,適合存儲器映射的通信,支持每個地址階段256個數(shù)據(jù)傳輸周期的批量傳輸,存在于PS-PL之間。
AXI4_Lite類型:AXI4接口類型中輕量級版本,用于存儲器映射的單次數(shù)據(jù)通信會話,簡化了的接口占用較少的邏輯部分面積,不支持批量數(shù)據(jù),只支持每次傳輸單個數(shù)據(jù),存在于PS-PL之間。
AXI4-Stream類型:沒有地址階段,不是存儲地址映射,僅僅存在與PL側,可以實現(xiàn)無限制的數(shù)據(jù)批量大小,為流式數(shù)據(jù)傳輸定義單個專用通道,連接只能是從主機到從機。為了實現(xiàn)雙向傳輸,兩個外圍設備都必須是主機/從機兼容類型。
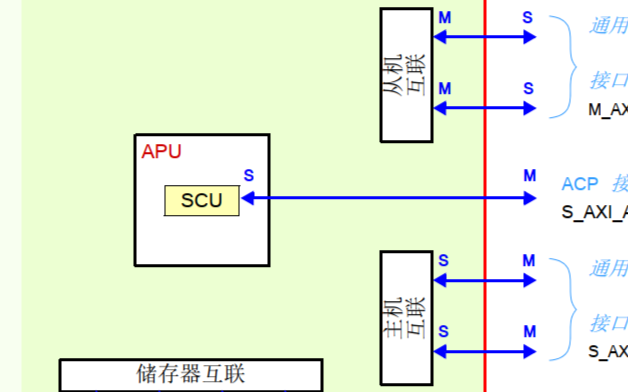
(三)、AXI架構
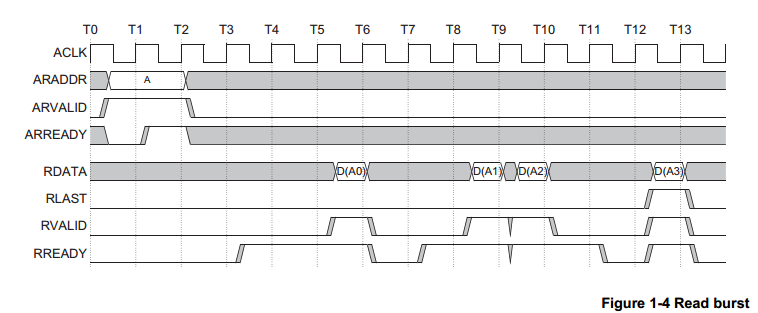
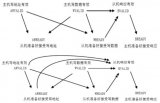
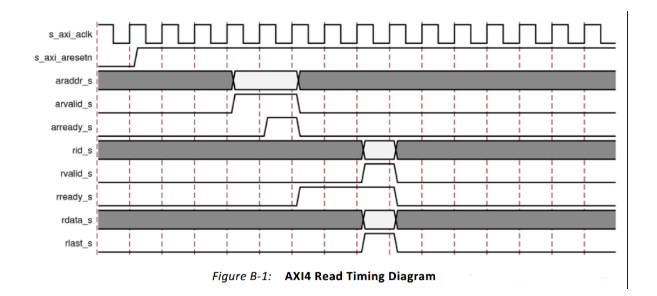
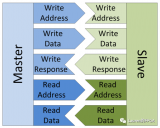
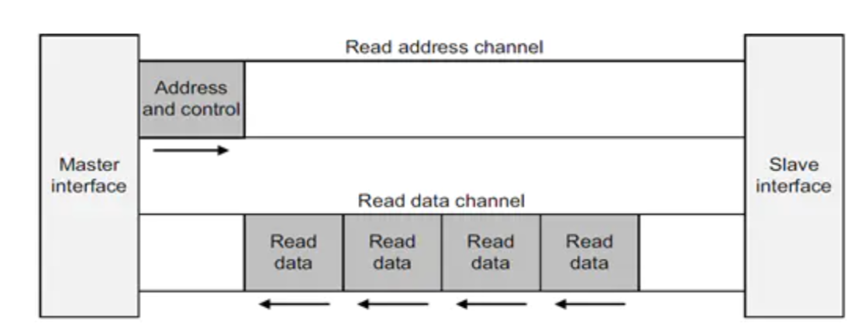
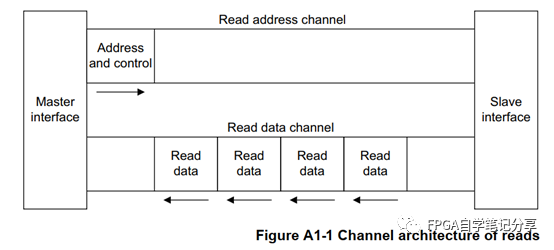
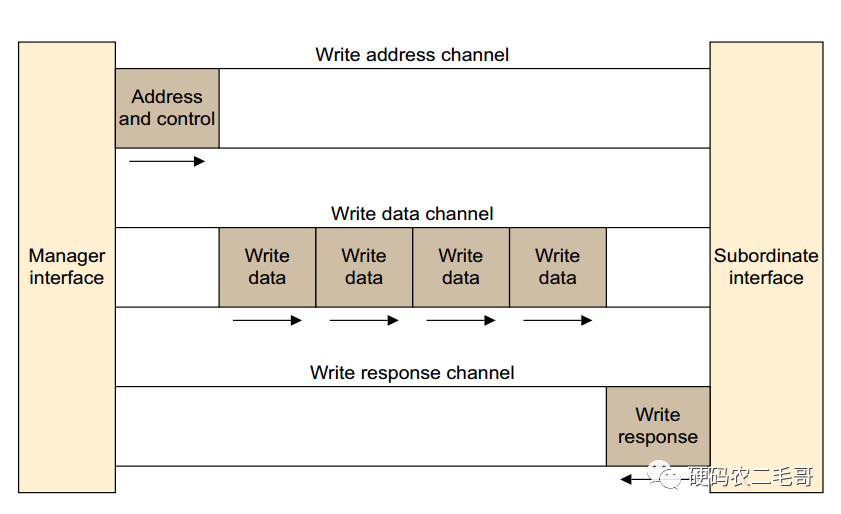
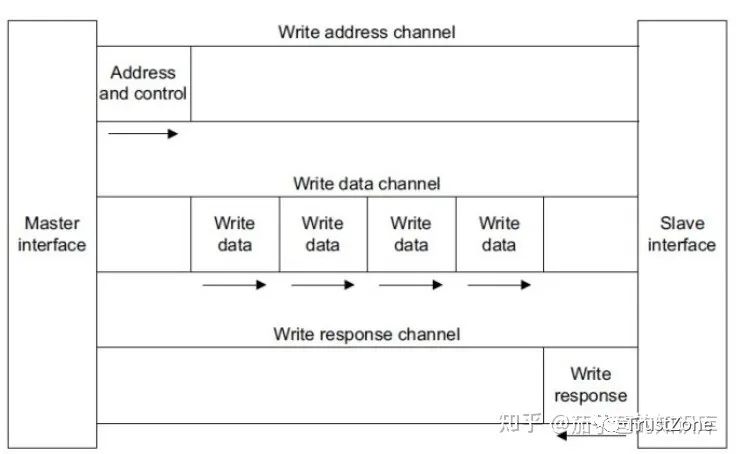
AXI協(xié)議規(guī)定一個AXI主機可以用寫數(shù)據(jù)通道通過AXI總線互聯(lián)將數(shù)據(jù)傳送給一個AXI從機(或者通過讀取數(shù)據(jù)通道從從機傳送到主機),寫數(shù)據(jù)傳輸會話會有一個額外的響應通道,但是讀取時并沒有,這時考慮到數(shù)據(jù)的流向。在進行數(shù)據(jù)讀取時,數(shù)據(jù)流向:Slave to Master,從機可以直接通過讀數(shù)據(jù)通道向主機返回信息。在進行數(shù)據(jù)寫入時,數(shù)據(jù)流向:Master to Slave,數(shù)據(jù)流向是單向的,需要有一個專門的響應通道。
無論是
讀還是寫,地址和控制數(shù)據(jù)都是在數(shù)據(jù)的發(fā)送/接收之前:
特別注意AXI互聯(lián)(AXI Interconnect):
(1)、主機AXI從處理器系統(tǒng)和處理器時鐘各自流向從機輸出S00_AXI和S00_AXLK。
(2)、AXI互聯(lián)的輸出都是主機通道,每個通道驅動對應的設備。
一、DMA簡介
DMA是一種內(nèi)存訪問技術,允許某些計算機內(nèi)部的硬件子系統(tǒng)可以獨立的直接讀寫內(nèi)存,而不需要CPU介入處理,從而不需要CPU的大量中斷負載,否則,CPU需要從來源把每一片段的數(shù)據(jù)復制到寄存器,然后在把他們再次寫回到新的地方,在這個時間里,CPU就無法執(zhí)行其他的任務。
DMA是一種快速數(shù)據(jù)傳送方式,通常用來傳送數(shù)據(jù)量較多的數(shù)據(jù)塊。使用DMA時,CPU向DMA控制器發(fā)送一個存儲器傳輸請求,這樣當DMA控制器在傳輸?shù)臅r候,CPU執(zhí)行其他的操作,傳輸完成時DMA以中斷的方式通知CPU。
DMA傳輸過程的示意圖為:
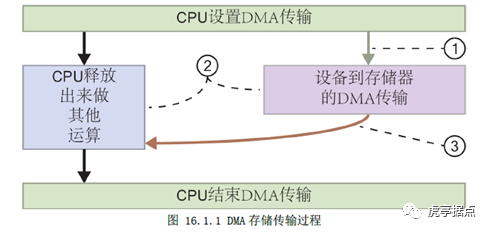
DMA的傳輸過程為:
1、為了配置用DMA傳輸數(shù)據(jù)到存儲器,處理器(Cortex-A9)發(fā)出一條指令。
2、DMA控制器把數(shù)據(jù)從外設傳輸?shù)酱鎯ζ骰蛘邚拇鎯ζ鱾鬏數(shù)酱鎯ζ鳎瑥亩^少CPU處理的事務量。
3、輸出傳輸完成后,向CPU發(fā)出一個中斷通知DMA傳輸可以關閉。
為了發(fā)起傳輸事務,DMA控制器必須得到以下信息:
(1)、源地址——數(shù)據(jù)被讀出的地址
(2)、目的地址——數(shù)據(jù)被寫入的地址
(3)、傳輸長度——應傳輸?shù)淖止?jié)數(shù)
DMA控制器架構原理
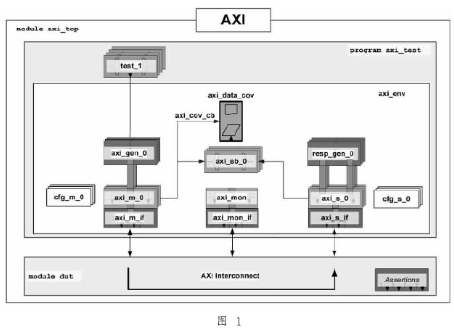
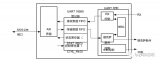
AXIDMA:官方解釋是為內(nèi)存與AXI4-Stream外設之間提供高帶寬的直接存儲訪問,其可選的scatter/gather功能可以將CPU從數(shù)據(jù)搬移任務中解放出來,在ZYNQ中,AXIDMA就是FPGA訪問DDR3的橋梁,不過該過程受ARM的監(jiān)控和管理。使用其他的IP(也是AXI4-Stream轉AXI4-MM)可以不需要ARM管理。AXIDMA IP有6個接口,S_AXI_LITE是ARM配置DMA寄存器的接口,M_AXI_SG是從存儲器加載buffer descriptor的接口,剩下4個接口構成兩對,S2MM和MM2S表示數(shù)據(jù)的方向,AXI存儲器一側的接口,AXIS是FPGA一側的接口。AXIDMA IP和ARM自帶的DMA是很像的,只不過不具備從存儲器到存儲器的功能,當然也可以將S2MM和MM2S接口與AXIS接口直接相連,其結構如圖1所示。

圖1,AXI_DMA的IP結構
AXIDMA工作模式可以分為兩種,Direct Register Mode和Scatter/Gather Mode。
Direct Register Mode具備DMA的基本功能,除了控制寄存器和狀態(tài)寄存器之外,給出目的地址和傳輸長度之后就可以開啟一次傳輸了。但是Direct Register Mode模式配置完一次寄存器之后只能完成存儲器連續(xù)地址空間的讀寫,如果有需求往不同空間搬運數(shù)據(jù)的話,那就需要重新配置寄存器開啟一次新的傳輸。
Scatter/Gather Mode配置靈活,其工作模式復雜很多。Scatter/Gather Mode把關于傳輸?shù)幕?a target="_blank">參數(shù)(起始地址,傳輸長度,包信息等)存儲在存儲器中,一套參數(shù)稱之為Buffer Descriptor(BD),在工作過程中通過上面提到的SG接口來加載BD且更新BD中的狀態(tài)。Scatter/Gather Mode下的寄存器沒有Address、Length相關寄存器了,取而代之的是CURDESC、TAILDESC。非多通道模式下的BD,主要有四部分內(nèi)容:NXTDESC、BUFFER_ADDRESS、CONTROL、STATUS。NXTDESC指定下一個BD的地址,由此可以構成一個BD鏈條,AXIDMA可以順著該鏈條依次fetch BD,BUFFER_ADDRESS指定傳輸?shù)脑吹刂坊蚰康牡刂罚珻ONTROL主要是length和包信息,STATUS反映該BD完成后的狀態(tài)。AXIDMA啟動后,首先從CURDESC指定的位置加載BD,完成當前BD的傳輸任務后根據(jù)BD鏈條找到下一個BD,依次完成BD指定的傳輸,知道遇到TALDESC指定的BD才停止。
Multichannel模式:在Scatter/Gather Mode下S2MM和MM2S都支持多個通道,Direct Register Mode不支持多通道,多通道相比非多通道,BD中增加了TID和TDEST,用來區(qū)分不同的通道。多通道支持2D-Transfer,從buffer address開始,讀寫HSIZE后跳過剩余的Stride – HSIZE個地址單元,下一次從buffer address + Stride位置開始,此過程迭代VSIZE此后結束該BD指定的傳輸。在Multichannel模式下S2MM有16個通道,每個通道都有獨立的CURDESC和TAILDESC寄存器,而CR和SR則是共用的。而MM2S的多個通道共用一個CURDESC和TAILDESC寄存器,MM2S端只能等當前包傳輸完成才能開始下一次的傳輸,可能這與CPU不太容易同時操縱多個通道的數(shù)據(jù)包發(fā)送有關系。所以在實際使用時只能先執(zhí)行一個通道的發(fā)送任務再執(zhí)行另一個通道的發(fā)送任務。
Cyclic DMA:循環(huán)模式是在Scatter/Gather Mode模式下的一種獨特工作方式,在Multichannel Mode下不可用。正常情況下的Scatter/Gather Mode模式在遇到Tail BD就應該結束當前的傳輸,但是如果使能了Cyclic模式的話,在遇到Tail BD時會忽略completed位,并且回到First BD,這一過程會一直持續(xù)直到遇到錯誤或者人為終止。Cyclic模式只需要在開啟傳輸前設置好BD鏈條,工作之后就再不需要管了。
Data Cache:在zynq內(nèi)部AMR CPU和DDR3之間存在兩級緩存區(qū),分別是L1 I/D Cache和L2 Cache,它們都是32-byte line size。Data Cache的使用帶來了一個問題,DMA和CPU都與DDR3有數(shù)據(jù)往來,可CPU的Cache是不知道DMA對DDR3的數(shù)據(jù)讀寫過程的,也就是說CPU得到的數(shù)據(jù)很可能是“假的”,這就是Cache一致性問題。解決該問題的辦法是在程序中使用flush函數(shù)(invalid函數(shù))及時將Cache的數(shù)據(jù)寫入到DDR3(從DDR3讀取數(shù)據(jù)到Cache),也就是說要避免該問題就需要注意編碼時加上flush函數(shù)。
審核編輯:湯梓紅
?















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論