 電子發(fā)燒友App
電子發(fā)燒友App


作者:Lianne & Justin? ?
在擬合機(jī)器學(xué)習(xí)或統(tǒng)計(jì)模型之前,我們通常需要清洗數(shù)據(jù)。用雜亂數(shù)據(jù)訓(xùn)練出的模型無法輸出有意義的結(jié)果。
數(shù)據(jù)清洗:從記錄集、表或數(shù)據(jù)庫中檢測(cè)和修正(或刪除)受損或不準(zhǔn)確記錄的過程。它識(shí)別出數(shù)據(jù)中不完善、不準(zhǔn)確或不相關(guān)的部分,并替換、修改或刪除這些臟亂的數(shù)據(jù)。
「數(shù)據(jù)清洗」光定義就這么長,執(zhí)行過程肯定既枯燥又耗時(shí)。 ? ? ? ? 為了將數(shù)據(jù)清洗簡(jiǎn)單化,本文介紹了一種新型完備分步指南,支持在 Python 中執(zhí)行數(shù)據(jù)清洗流程。讀者可以學(xué)習(xí)找出并清洗以下數(shù)據(jù)的方法:
缺失數(shù)據(jù);
不規(guī)則數(shù)據(jù)(異常值);
不必要數(shù)據(jù):重復(fù)數(shù)據(jù)(repetitive data)、復(fù)制數(shù)據(jù)(duplicate data)等;
不一致數(shù)據(jù):大寫、地址等;
該指南使用的數(shù)據(jù)集是 Kaggle 競(jìng)賽 Sberbank 俄羅斯房地產(chǎn)價(jià)值預(yù)測(cè)競(jìng)賽數(shù)據(jù)(該項(xiàng)目的目標(biāo)是預(yù)測(cè)俄羅斯的房?jī)r(jià)波動(dòng))。本文并未使用全部數(shù)據(jù),僅選取了其中的一部分樣本。 ? ? ? ? 在進(jìn)入數(shù)據(jù)清洗流程之前,我們先來看一下數(shù)據(jù)概況。
# import packages
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import matplotlib
plt.style.use('ggplot')
from matplotlib.pyplot import figure
%matplotlib inline
matplotlib.rcParams['figure.figsize'] = (12,8)
pd.options.mode.chained_assignment = None
# read the data
df = pd.read_csv('sberbank.csv')
# shape and data types of the data
print(df.shape)
print(df.dtypes)
# select numeric columns
df_numeric = df.select_dtypes(include=[np.number])
numeric_cols = df_numeric.columns.values
print(numeric_cols)
# select non numeric columns
df_non_numeric = df.select_dtypes(exclude=[np.number])
non_numeric_cols = df_non_numeric.columns.values
print(non_numeric_cols)
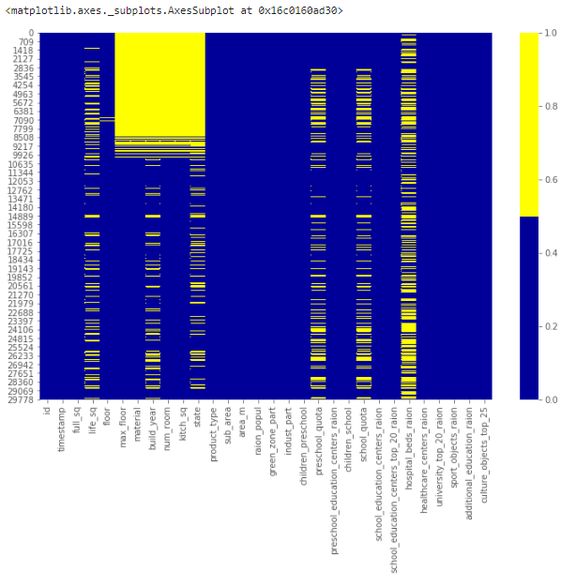
cols = df.columns[:30] # first 30 columns colours = ['#000099', '#ffff00'] # specify the colours - yellow is missing. blue is not missing. sns.heatmap(df[cols].isnull(), cmap=sns.color_palette(colours))下表展示了前 30 個(gè)特征的缺失數(shù)據(jù)模式。橫軸表示特征名,縱軸表示觀察值/行數(shù),黃色表示缺失數(shù)據(jù),藍(lán)色表示非缺失數(shù)據(jù)。 ? 例如,下圖中特征 life_sq 在多個(gè)行中存在缺失值。而特征 floor 只在第 7000 行左右出現(xiàn)零星缺失值。 ?
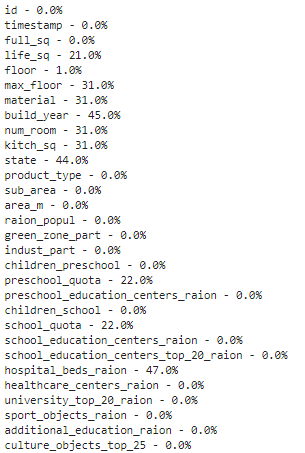
# if it's a larger dataset and the visualization takes too long can do this. # % of missing. for col in df.columns: pct_missing = np.mean(df[col].isnull()) print('{} - {}%'.format(col, round(pct_missing*100)))? 得到如下列表,該表展示了每個(gè)特征的缺失值百分比。 ? 具體而言,我們可以從下表中看到特征 life_sq 有 21% 的缺失數(shù)據(jù),而特征 floor 僅有 1% 的缺失數(shù)據(jù)。該列表有效地總結(jié)了每個(gè)特征的缺失數(shù)據(jù)百分比情況,是對(duì)熱圖可視化的補(bǔ)充。 ?
# first create missing indicator for features with missing data
for col in df.columns:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0:
print('created missing indicator for: {}'.format(col))
df['{}_ismissing'.format(col)] = missing
# then based on the indicator, plot the histogram of missing values
ismissing_cols = [col for col in df.columns if 'ismissing' in col]
df['num_missing'] = df[ismissing_cols].sum(axis=1)
df['num_missing'].value_counts().reset_index().sort_values(by='index').plot.bar(x='index', y='num_missing')
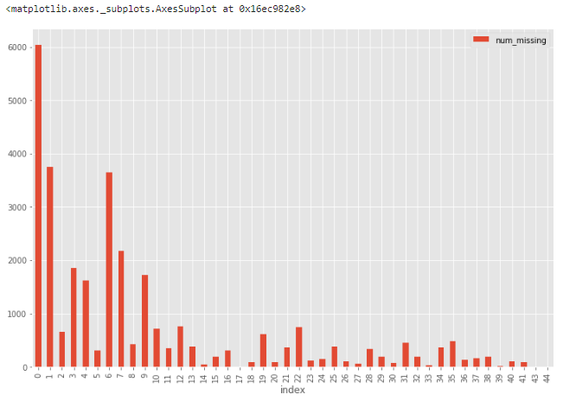
? 直方圖可以幫助在 30,471 個(gè)觀察值中識(shí)別缺失值狀況。 ? 例如,從下圖中可以看到,超過 6000 個(gè)觀察值不存在缺失值,接近 4000 個(gè)觀察值具備一個(gè)缺失值。 ?
# drop rows with a lot of missing values. ind_missing = df[df['num_missing'] > 35].index df_less_missing_rows = df.drop(ind_missing, axis=0)? 解決方案 2:丟棄特征 ? 與解決方案 1 類似,我們只在確定某個(gè)特征無法提供有用信息時(shí)才丟棄它。 ? 例如,從缺失數(shù)據(jù)百分比列表中,我們可以看到 hospital_beds_raion 具備較高的缺失值百分比——47%,因此我們丟棄這一整個(gè)特征。 ?
# hospital_beds_raion has a lot of missing. # If we want to drop. cols_to_drop = ['hospital_beds_raion'] df_less_hos_beds_raion = df.drop(cols_to_drop, axis=1)? 解決方案 3:填充缺失數(shù)據(jù) ? 當(dāng)特征是數(shù)值變量時(shí),執(zhí)行缺失數(shù)據(jù)填充。對(duì)同一特征的其他非缺失數(shù)據(jù)取平均值或中位數(shù),用這個(gè)值來替換缺失值。 ? 當(dāng)特征是分類變量時(shí),用眾數(shù)(最頻值)來填充缺失值。 ? 以特征 life_sq 為例,我們可以用特征中位數(shù)來替換缺失值。 ?
# replace missing values with the median. med = df['life_sq'].median() print(med) df['life_sq'] = df['life_sq'].fillna(med)? 此外,我們還可以對(duì)所有數(shù)值特征一次性應(yīng)用同樣的填充策略。 ?
# impute the missing values and create the missing value indicator variables for each numeric column.
df_numeric = df.select_dtypes(include=[np.number])
numeric_cols = df_numeric.columns.values
for col in numeric_cols:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0: # only do the imputation for the columns that have missing values.
print('imputing missing values for: {}'.format(col))
df['{}_ismissing'.format(col)] = missing
med = df[col].median()
df[col] = df[col].fillna(med)
?
# impute the missing values and create the missing value indicator variables for each non-numeric column.
df_non_numeric = df.select_dtypes(exclude=[np.number])
non_numeric_cols = df_non_numeric.columns.values
for col in non_numeric_cols:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0: # only do the imputation for the columns that have missing values.
print('imputing missing values for: {}'.format(col))
df['{}_ismissing'.format(col)] = missing
top = df[col].describe()['top'] # impute with the most frequent value.
df[col] = df[col].fillna(top)
解決方案 4:替換缺失值 ? 對(duì)于分類特征,我們可以添加新的帶值類別,如 _MISSING_。對(duì)于數(shù)值特征,我們可以用特定值(如-999)來替換缺失值。 ? 這樣,我們就可以保留缺失值,使之提供有價(jià)值的信息。??
# categorical df['sub_area'] = df['sub_area'].fillna('_MISSING_') # numeric df['life_sq'] = df['life_sq'].fillna(-999)? 不規(guī)則數(shù)據(jù)(異常值) ? 異常值指與其他觀察值具備顯著差異的數(shù)據(jù),它們可能是真的異常值也可能是錯(cuò)誤。 ? 如何找出異常值? ? 根據(jù)特征的屬性(數(shù)值或分類),使用不同的方法來研究其分布,進(jìn)而檢測(cè)異常值。 ? 方法 1:直方圖/箱形圖 ? 當(dāng)特征是數(shù)值變量時(shí),使用直方圖和箱形圖來檢測(cè)異常值。 ? 下圖展示了特征 life_sq 的直方圖。 ?
# histogram of life_sq. df['life_sq'].hist(bins=100)? 由于數(shù)據(jù)中可能存在異常值,因此下圖中數(shù)據(jù)高度偏斜。 ?
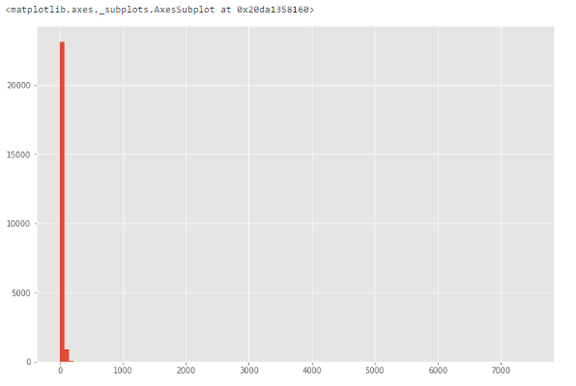
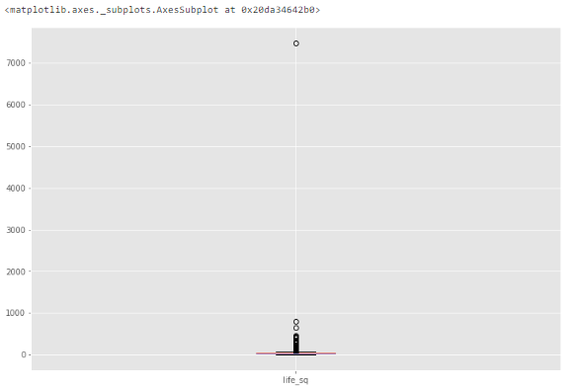
# box plot. df.boxplot(column=['life_sq'])? 從下圖中我們可以看到,異常值是一個(gè)大于 7000 的數(shù)值。 ?
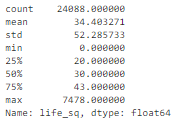
df['life_sq'].describe()?
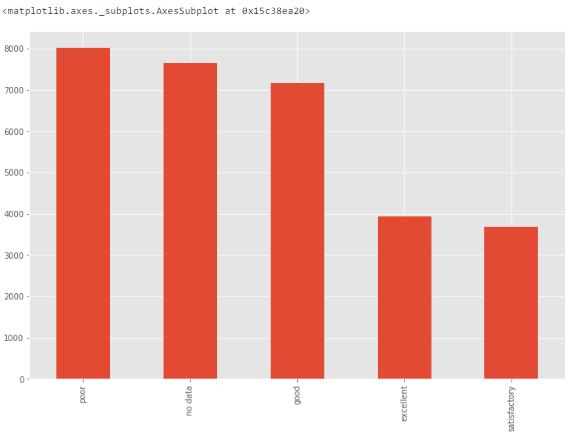
 ? 方法 3:條形圖 ? 當(dāng)特征是分類變量時(shí),我們可以使用條形圖來了解其類別和分布。 ? 例如,特征 ecology 具備合理的分布。但如果某個(gè)類別「other」僅有一個(gè)值,則它就是異常值。 ?
? 方法 3:條形圖 ? 當(dāng)特征是分類變量時(shí),我們可以使用條形圖來了解其類別和分布。 ? 例如,特征 ecology 具備合理的分布。但如果某個(gè)類別「other」僅有一個(gè)值,則它就是異常值。 ?
# bar chart?-? distribution of a categorical variable df['ecology'].value_counts().plot.bar()?
num_rows = len(df.index)
low_information_cols = [] #
for col in df.columns:
cnts = df[col].value_counts(dropna=False)
top_pct = (cnts/num_rows).iloc[0]
if top_pct > 0.95:
low_information_cols.append(col)
print('{0}: {1:.5f}%'.format(col, top_pct*100))
print(cnts)
print()
? 我們可以逐一查看這些變量,確認(rèn)它們是否提供有用信息。(此處不再詳述。) ?
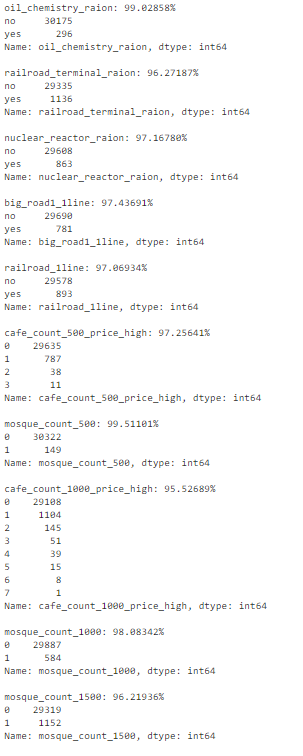
# we know that column 'id' is unique, but what if we drop it?
df_dedupped = df.drop('id', axis=1).drop_duplicates()
# there were duplicate rows
print(df.shape)
print(df_dedupped.shape)
? 我們發(fā)現(xiàn),有 10 行是完全復(fù)制的觀察值。 ? 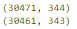 ? 如何處理基于所有特征的復(fù)制數(shù)據(jù)? ? 刪除這些復(fù)制數(shù)據(jù)。 ? 復(fù)制數(shù)據(jù)類型 2:基于關(guān)鍵特征 ? 如何找出基于關(guān)鍵特征的復(fù)制數(shù)據(jù)? ? 有時(shí)候,最好的方法是刪除基于一組唯一標(biāo)識(shí)符的復(fù)制數(shù)據(jù)。 ? 例如,相同使用面積、相同價(jià)格、相同建造年限的兩次房產(chǎn)交易同時(shí)發(fā)生的概率接近零。 ? 我們可以設(shè)置一組關(guān)鍵特征作為唯一標(biāo)識(shí)符,比如 timestamp、full_sq、life_sq、floor、build_year、num_room、price_doc。然后基于這些特征檢查是否存在復(fù)制數(shù)據(jù)。 ?
? 如何處理基于所有特征的復(fù)制數(shù)據(jù)? ? 刪除這些復(fù)制數(shù)據(jù)。 ? 復(fù)制數(shù)據(jù)類型 2:基于關(guān)鍵特征 ? 如何找出基于關(guān)鍵特征的復(fù)制數(shù)據(jù)? ? 有時(shí)候,最好的方法是刪除基于一組唯一標(biāo)識(shí)符的復(fù)制數(shù)據(jù)。 ? 例如,相同使用面積、相同價(jià)格、相同建造年限的兩次房產(chǎn)交易同時(shí)發(fā)生的概率接近零。 ? 我們可以設(shè)置一組關(guān)鍵特征作為唯一標(biāo)識(shí)符,比如 timestamp、full_sq、life_sq、floor、build_year、num_room、price_doc。然后基于這些特征檢查是否存在復(fù)制數(shù)據(jù)。 ?
key = ['timestamp', 'full_sq', 'life_sq', 'floor', 'build_year', 'num_room', 'price_doc'] df.fillna(-999).groupby(key)['id'].count().sort_values(ascending=False).head(20)? 基于這組關(guān)鍵特征,我們找到了 16 條復(fù)制數(shù)據(jù)。 ?
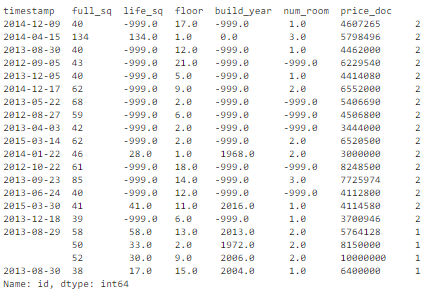
# drop duplicates based on an subset of variables. key = ['timestamp', 'full_sq', 'life_sq', 'floor', 'build_year', 'num_room', 'price_doc'] df_dedupped2 = df.drop_duplicates(subset=key) print(df.shape) print(df_dedupped2.shape)? 刪除 16 條復(fù)制數(shù)據(jù),得到新數(shù)據(jù)集 df_dedupped2。 ?
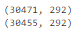 ? 不一致數(shù)據(jù) ? 在擬合模型時(shí),數(shù)據(jù)集遵循特定標(biāo)準(zhǔn)也是很重要的一點(diǎn)。我們需要使用不同方式來探索數(shù)據(jù),找出不一致數(shù)據(jù)。大部分情況下,這取決于觀察和經(jīng)驗(yàn)。不存在運(yùn)行和修復(fù)不一致數(shù)據(jù)的既定代碼。 ? 下文介紹了四種不一致數(shù)據(jù)類型。 ? 不一致數(shù)據(jù)類型 1:大寫 ? 在類別值中混用大小寫是一種常見的錯(cuò)誤。這可能帶來一些問題,因?yàn)?Python 分析對(duì)大小寫很敏感。 ? 如何找出大小寫不一致的數(shù)據(jù)? ? 我們來看特征 sub_area。 ?
? 不一致數(shù)據(jù) ? 在擬合模型時(shí),數(shù)據(jù)集遵循特定標(biāo)準(zhǔn)也是很重要的一點(diǎn)。我們需要使用不同方式來探索數(shù)據(jù),找出不一致數(shù)據(jù)。大部分情況下,這取決于觀察和經(jīng)驗(yàn)。不存在運(yùn)行和修復(fù)不一致數(shù)據(jù)的既定代碼。 ? 下文介紹了四種不一致數(shù)據(jù)類型。 ? 不一致數(shù)據(jù)類型 1:大寫 ? 在類別值中混用大小寫是一種常見的錯(cuò)誤。這可能帶來一些問題,因?yàn)?Python 分析對(duì)大小寫很敏感。 ? 如何找出大小寫不一致的數(shù)據(jù)? ? 我們來看特征 sub_area。 ?
df['sub_area'].value_counts(dropna=False)? 它存儲(chǔ)了不同地區(qū)的名稱,看起來非常標(biāo)準(zhǔn)化。 ?

# make everything lower case. df['sub_area_lower'] = df['sub_area'].str.lower() df['sub_area_lower'].value_counts(dropna=False)?

df?

df['timestamp_dt'] = pd.to_datetime(df['timestamp'], format='%Y-%m-%d') df['year'] = df['timestamp_dt'].dt.year df['month'] = df['timestamp_dt'].dt.month df['weekday'] = df['timestamp_dt'].dt.weekday print(df['year'].value_counts(dropna=False)) print() print(df['month'].value_counts(dropna=False))?
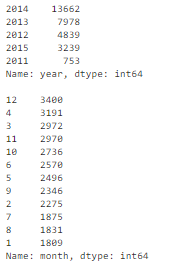 ? 相關(guān)文章:https://towardsdatascience.com/how-to-manipulate-date-and-time-in-python-like-a-boss-ddea677c6a4d ? 不一致數(shù)據(jù)類型 3:類別值 ? 分類特征的值數(shù)量有限。有時(shí)由于拼寫錯(cuò)誤等原因可能出現(xiàn)其他值。 ? 如何找出類別值不一致的數(shù)據(jù)? ? 我們需要觀察特征來找出類別值不一致的情況。舉例來說: ? 由于本文使用的房地產(chǎn)數(shù)據(jù)集不存在這類問題,因此我們創(chuàng)建了一個(gè)新的數(shù)據(jù)集。例如,city 的值被錯(cuò)誤輸入為「torontoo」和「tronto」,其實(shí)二者均表示「toronto」(正確值)。 ? 識(shí)別它們的一種簡(jiǎn)單方式是模糊邏輯(或編輯距離)。該方法可以衡量使一個(gè)值匹配另一個(gè)值需要更改的字母數(shù)量(距離)。 ? 已知這些類別應(yīng)僅有四個(gè)值:「toronto」、「vancouver」、「montreal」和「calgary」。計(jì)算所有值與單詞「toronto」(和「vancouver」)之間的距離,我們可以看到疑似拼寫錯(cuò)誤的值與正確值之間的距離較小,因?yàn)樗鼈冎挥袔讉€(gè)字母不同。 ?
? 相關(guān)文章:https://towardsdatascience.com/how-to-manipulate-date-and-time-in-python-like-a-boss-ddea677c6a4d ? 不一致數(shù)據(jù)類型 3:類別值 ? 分類特征的值數(shù)量有限。有時(shí)由于拼寫錯(cuò)誤等原因可能出現(xiàn)其他值。 ? 如何找出類別值不一致的數(shù)據(jù)? ? 我們需要觀察特征來找出類別值不一致的情況。舉例來說: ? 由于本文使用的房地產(chǎn)數(shù)據(jù)集不存在這類問題,因此我們創(chuàng)建了一個(gè)新的數(shù)據(jù)集。例如,city 的值被錯(cuò)誤輸入為「torontoo」和「tronto」,其實(shí)二者均表示「toronto」(正確值)。 ? 識(shí)別它們的一種簡(jiǎn)單方式是模糊邏輯(或編輯距離)。該方法可以衡量使一個(gè)值匹配另一個(gè)值需要更改的字母數(shù)量(距離)。 ? 已知這些類別應(yīng)僅有四個(gè)值:「toronto」、「vancouver」、「montreal」和「calgary」。計(jì)算所有值與單詞「toronto」(和「vancouver」)之間的距離,我們可以看到疑似拼寫錯(cuò)誤的值與正確值之間的距離較小,因?yàn)樗鼈冎挥袔讉€(gè)字母不同。 ?
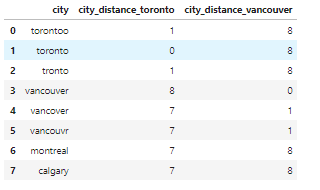
from nltk.metrics import edit_distance
df_city_ex = pd.DataFrame(data={'city': ['torontoo', 'toronto', 'tronto', 'vancouver', 'vancover', 'vancouvr', 'montreal', 'calgary']})
df_city_ex['city_distance_toronto'] = df_city_ex['city'].map(lambda x: edit_distance(x, 'toronto'))
df_city_ex['city_distance_vancouver'] = df_city_ex['city'].map(lambda x: edit_distance(x, 'vancouver'))
df_city_ex
?
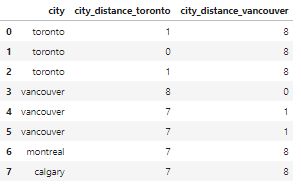
msk = df_city_ex['city_distance_toronto'] <= 2 df_city_ex.loc[msk, 'city'] = 'toronto' msk = df_city_ex['city_distance_vancouver'] <= 2 df_city_ex.loc[msk, 'city'] = 'vancouver' df_city_ex?
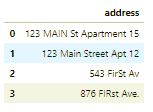
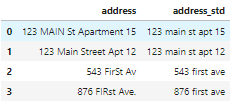
# no address column in the housing dataset. So create one to show the code. df_add_ex = pd.DataFrame(['123 MAIN St Apartment 15', '123 Main Street Apt 12 ', '543 FirSt Av', ' 876 FIRst Ave.'], columns=['address']) df_add_ex? 我們可以看到,地址特征非常混亂。 ?
 ? 如何處理地址不一致的數(shù)據(jù)? ? 運(yùn)行以下代碼將所有字母轉(zhuǎn)為小寫,刪除空格,刪除句號(hào),并將措辭標(biāo)準(zhǔn)化。 ?
? 如何處理地址不一致的數(shù)據(jù)? ? 運(yùn)行以下代碼將所有字母轉(zhuǎn)為小寫,刪除空格,刪除句號(hào),并將措辭標(biāo)準(zhǔn)化。 ?
df_add_ex['address_std'] = df_add_ex['address'].str.lower() df_add_ex['address_std'] = df_add_ex['address_std'].str.strip() # remove leading and trailing whitespace. df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\.', '') # remove period. df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\bstreet\b', 'st') # replace street with st. df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\bapartment\b', 'apt') # replace apartment with apt. df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\bav\b', 'ave') # replace apartment with apt. df_add_ex? 現(xiàn)在看起來好多了: ?
編輯:黃飛
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論