 電子發燒友App
電子發燒友App


中繼器是Axure中的一個重難點,掌握中繼器的用法,在Axure原型設計中,會有很大的幫助。本文為大家詳細解說axure中繼器實現數據查詢、修改、判斷功能方法。
中繼器函數
目前中繼器中提供可以查詢內部數據的函數只有「Repeater」,當我們使用此函數時只能獲得以數組形式排列的整個中繼器內的數據。例如:
對中繼器使用函數 Repeater.text 時,得到以下數據

由此我們得知:中繼器內的數據是以「數組」形式儲存的,當輸出時,每個數組之間通過換行符 ‘n’ 連接。
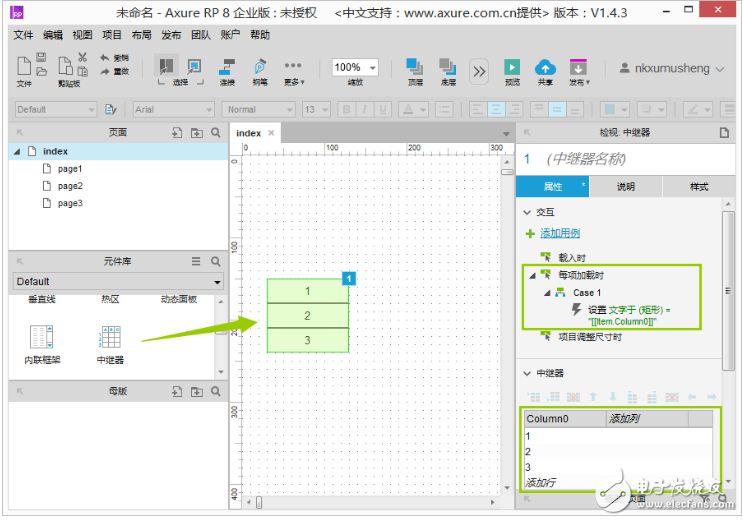
這時候有人會問,為什么不像數據庫一樣,直接按照 Repeater [ 0 ] [ 0 ] 類似的形式直接輸出某個字段呢?很抱歉,通過測試發現,目前 Axure 中的函數是不能識別數組的,而「Item. 列名」這個函數也只能直接對中繼器的動作中(例如篩選、更新等)使用,并不能在其他函數賦值中直接使用。如下圖:
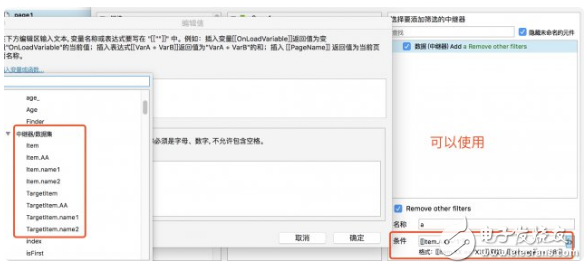
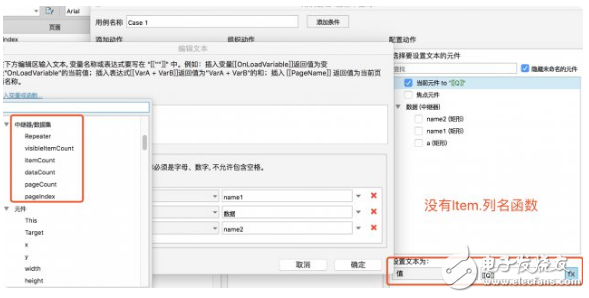
字符串處理
現在我們已經知道,通過直接調用中繼器某個具體字段的方式已經破滅了。
回到開始,目前我們外部組件能獲取中繼器數據只有「Repeater」一個函數可以用了,但是它里面的數據是整個中繼器的所有數據,而且還是每個數據換行展示的,離我們想要的某個字段差距太遠了,怎么辦呢?
1. 篩選中繼器,獲取指定行內容
首先我們做的的是篩選,通過中繼器的篩選功能,將中繼器數據指定到我們想要的那一行數據中,例如當我們想獲得 ID 是 1 的人的姓名時,我們直接對 ID 進行篩選。
此時我們看到,其他沒用行的數據已經消失了,貌似離我們想要的結果進了很多。
2. 格式化數據
如果想要獲得姓名這個字段,我們需要將得到的數據進行格式化,調整為一行字符串顯示,并且每個字段之間通過「,」隔開。這時候需要用到「split ( ‘separator‘,limit ) 」函數(返回字符串),第一個參數是分割字符,此時我們用換行符 ’n‘ 進行分割,第二個字符是分割最長的字符串個數,這里可以省略。

是不是已經有點感覺了呢?Axure 提供了那么多的字符串處理函數,如果想獲得 ‘li’ 這個字符串,是不是很簡單呢?
3. 截取字符串
字符串都是以「0」開始排列的,‘li’ 的位置應該是從 2 到 3. 那么我們使用「substring ( from,to ) 」函數(返回字符串),就可以得到這個姓名了。
這時候有人會問,如果姓名字符長度不確定呢?沒問題,我們已經知道了每個字符組是通過「,」隔開的,那么我們直接截取第一個 ‘,’ 到第二個 ‘,’ 之間的內容就可以了。
怎么找到 ‘,’ 的位置呢?使用「indexOf(‘searchValue’,start)」(返回數字)函數就可以了,前面的字段是查找內容 ‘,’,后面的字段是字符串開始查找的位置,例如通過
LVAR.substring ( LVAR.indexOf ( ‘,‘ ) ,LVAR.indexOf ( ‘,’, ( LVAR.indexOf ( ‘,‘ ) +1 ) ) )
OH,NO!你已經亂了?突然來了一個這么長的,到底是什么東西?那好,我給你分析下:
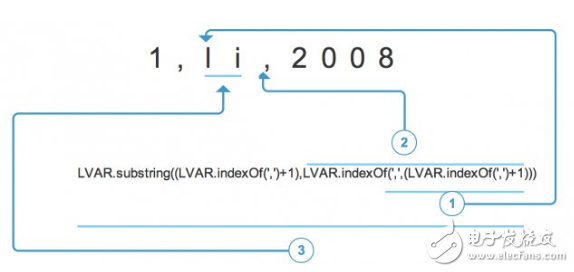
查找字符串 LVAR 中第一個 ‘,’ 出現的位置,返回數字。為什么要 +1 呢?因為它的輸出作為前面 LVAR.indexOf(2)的起始查找位置,就是說查找 2 字符串時候,是從它第一個 ‘,’ 后面的一個字符開始查找的。
從字符串 LVAR 第一個 ‘,’ 的后一位開始查找 ‘,’,說白了就是得到字符串 LVAR 第二個 ‘,’ 的位置。
截取字符串 LVAR 從第一個 ‘,’ 出現的位置開始到第二個 ‘,’ 出現的位置。
這下明白了嗎?還要記住一點,就是substring函數截取的時候,是保留前面的第一個字符,不保留最后面的字符。所以當讀取到第一個 ‘,’ 的時候,要從它后面開始截取,一直到第二個 ‘,’ 出現為止。
挑戰升級
不知道還有幾個人能看到這里,因為大部分人可能還是抱著一個失望的態度,『看了半天你就告訴我怎么截取字符串嗎?老子 800 年前就會了,這跟數據庫查的太遠了吧,我怎么能隨便查詢任意參數呢?』
別急,上面都是基礎,干貨來了。
需要函數:
Repeater.text 確保中繼器返回的是字符串
split ( “ ) 按照特定分隔符分割字符串
substring ( from,to ) 按照指定位置分割字符串
indexOf ( ) 查找某個字符串在字符串出現位置
concat ( ) 連接字符串
length 獲取字符串長度
場景設計
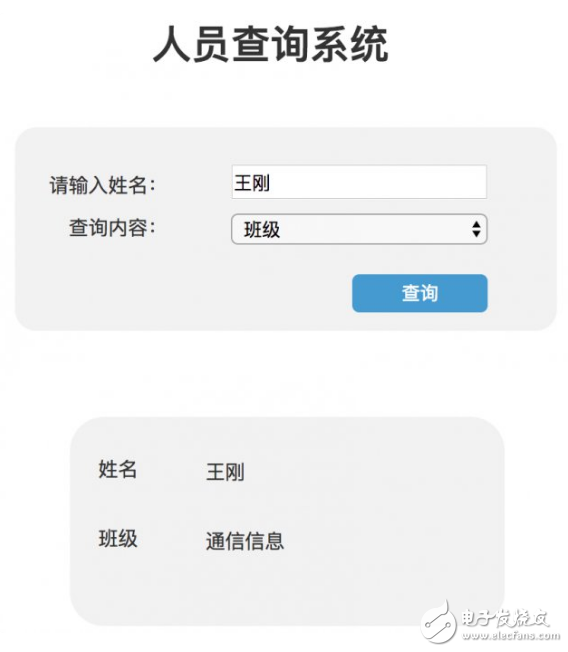
學校有一個【人員管理系統】,系統里包含所有學生的姓名、學院、電話、年齡等各種信息。使用者可以通過姓名查詢學生的任意其他特定信息,也可以修改任意信息。
例如:查詢王剛的班級,查詢鄧爽的電話號碼等。
構架分析
由需求得知我們需要查詢指定姓名人員的某項信息,即數據庫中特定行中的某項。由上文得知,我們可以通過篩選中繼器方式得到指定行數據,即指定姓名的所有信息。然后通過切割字符串的方式查找到指定項目的信息。
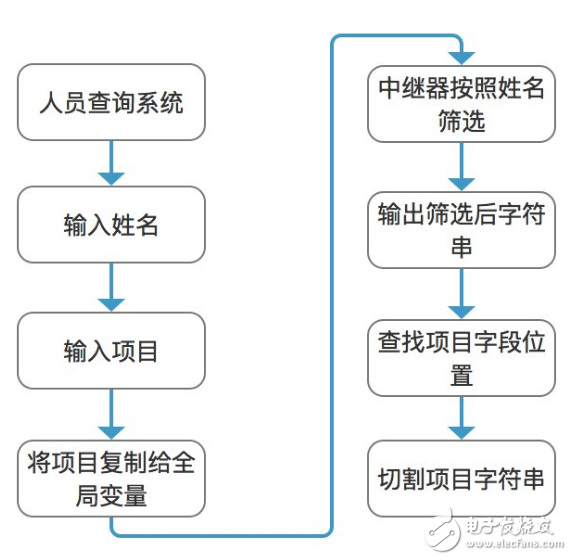
在整個環節中,只有「查找項目字段位置」是個難點,因為項目是不確定的,在輸出后的字符串中,只有按照「,」分割的數據內容,并不能知道每個數據代表著什么,所以如何查找指定項目的位置呢?
這里我們引入了一個類似「列名」的輔助字段,即將所有的數據內容前面加上一個列名標識,例如:
姓名中的數據變為 王剛—— name_ 王剛
班級中的數據變為 通信信息—— class_ 通信信息
手機中的數據變為 23456 —— phone_23456
年齡中的數據變為 22 —— age_22
這樣我們獲得某一行的字符串數據就變化成了:
王剛,通信信息,23456,22 —— name_ 王剛,class_ 通信信息,phone_23456,age_22
看到了嗎?我們得到了一個有標識的字符串,相信有些人已經想明白了,我們在字符串中通過數據前面的標識就可以判斷每個數據是什么意思了。如果想得到班級,識別 ‘class_’, 如果想得到年齡,識別 ‘age_’ 就可以了,無論數據有多少項,無論它位置在哪,只要我們指定想要數據的標識就可以了。
系統搭建
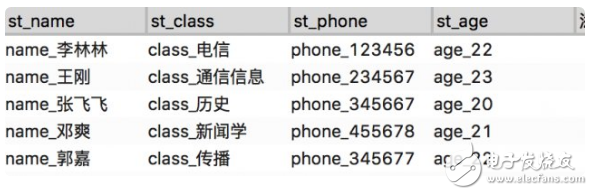
優化數據表
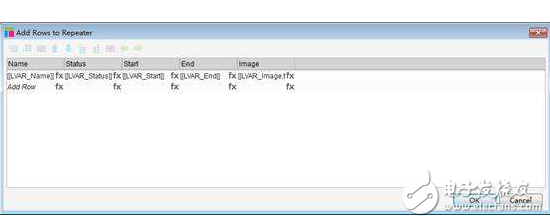
將原有數據按照指定數據格式優化(關于在 excel 中為同一列中每項數據增加字符的方法有很多),優化后添加到中繼器數據中。
設置全局變量
首先設置一個表示查詢項目的變量「Finder」,通過查詢的項目內容為「Finder」賦值。 之后設置每個查詢項目對應的特定前綴,name_、class_ 等。
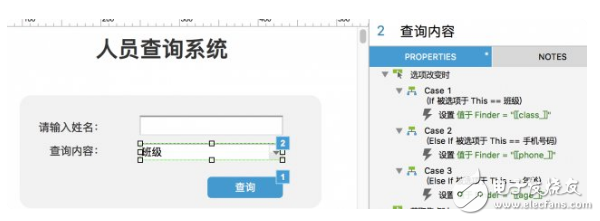
設置查詢面板
查詢面板包括姓名文本框,查詢項目列表框,查詢按鈕。
當切換查詢項目時,系統將查詢項目賦值給項目變量「Finder」,項目變量默認值與查詢項目列表默認值相同。
當點擊查詢按鈕時,將「姓名」賦值給全局變量「Name」,然后按照「姓名」文本框篩選中繼器數據,之后按照項目變量「Finder」將具體項目數值顯示到查詢結果中。
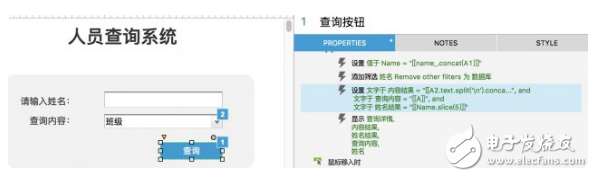
設置查詢結果面板
查詢結果包括姓名及查詢內容結果,對應文本框顯示相應信息即可,在此不再贅述。
函數分析
以下是查詢結果顯示的函數:
[ [ A2.text.split ( ‘n‘ ) .concat ( ‘,’ ) .substring ( ( A2.text.split ( ‘n‘ ) .indexOf ( Finder ) +Finder.length ) ,A2.text.split ( ‘n’ ) .concat ( ‘,‘ ) .indexOf ( ‘,’, ( A2.text.split ( ‘n‘ ) .indexOf ( Finder ) ) ) ) ] ]
如果上文看懂的人會發現這里有幾個特殊的地方:
A2.text.split ( ‘n’ ) .concat ( ‘,‘ ) :在重新排列字符串最后加一個 ’,‘,為了防止查找不到最后一個 ’,‘ 而出現 bug。
A2.text.split ( ‘n’ ) .indexOf ( Finder ) +Finder.length:因為 Finder 字符串長度的不確定性,切割的起始位置是從「Finder」字符串后開始切割的。
系統優化
由于時間原因功能做的比較簡單,但是通過這個方法我們可以查找或修改任意項目的內容,比如查找某個學生的全部信息,按照班級查找某個姓名的學生等。
















 工商網監
工商網監
評論