") 詳細梳理聊天機器人的現(xiàn)狀及技術(shù),并討論了未來可能的發(fā)展方向
詳細梳理聊天機器人的現(xiàn)狀及技術(shù),并討論了未來可能的發(fā)展方向
作者:邵浩
作為人工智能時代的入口級產(chǎn)品,近年來,聊天機器人受到了大量的關(guān)注,也得到了快速的發(fā)展。但隨著 2018 年 Facebook 關(guān)閉其虛擬助手 M,亞馬遜 Echo 也被爆出侵犯用戶隱私的問題,再加上聊天機器人實際使用效果遠低于大眾預期,整個行業(yè)也逐步走向低迷。聊天機器人的困境到底在哪兒?在如今的技術(shù)條件和市場環(huán)境下,聊天機器人廠家如何進行突圍?使用新技術(shù),開辟新賽道,是否能解決問題?本文將詳細梳理聊天機器人的現(xiàn)狀及技術(shù),指出其存在的問題,并討論了未來可能的發(fā)展方向。本文作者為狗尾草人工智能研究院院長、日本國立九州大學工學博士邵浩。
困境
一、聊天機器人太傻了
我是一個聊天機器人的從業(yè)者,辦公桌上和家里有各式各樣的聊天機器人產(chǎn)品。和大多數(shù)用戶的體驗一樣,對于一個剛剛到手的產(chǎn)品,最開始的感覺是新鮮興奮,但當體驗完功能之后,剩下的就是失望和無奈。然后,很可能就將其放在角落里再也不會打開,或者僅僅作為一個音箱,來播放音樂。
這就跟聊天機器人廠商的初衷背道而馳了。一邊是廠商希望用戶長久留存在產(chǎn)品上,一邊是用戶對產(chǎn)品的日均使用時間快速下降。那么為什么會出現(xiàn)這種情況?為什么大多數(shù)用戶對于聊天機器人的滿意度很低?
從人類的天性中,可以一窺端倪。天主教教義對人類的惡性分為七種。舉例來說,人類是懶惰的,總是希望以最少的代價獲取最大的利益。而由于技術(shù)的限制,和聊天機器人的對話經(jīng)常會使得溝通成本增加。比如,語音識別率在實際場景中不可能達到 100%,也就造成了在嘈雜環(huán)境中喚醒聊天機器人,許多時候是一個很不舒服的體驗。相比而言,人類的耳朵對于「雞尾酒會效應」卻游刃有余。又比如,想讓聊天機器人完成一項功能(訂機票、查天氣或播放一首特定風格的音樂),有時候必須通過非常明確的語言,進行多次溝通。相比而言,古代皇帝想做一件事情的時候,甚至不需要用到語言,只需一個眼神,太監(jiān)就馬上能意會到皇帝的目的。這里提到的還只是純交互部分的問題,如果再出現(xiàn)網(wǎng)絡延遲、敏感詞和敏感話題、甚至還有一些稀奇古怪的 bug,讓聊天機器人答非所問,就會讓人更加不滿。
作為從業(yè)人員,我在使用這些產(chǎn)品的時候還是很寬容的,由于知道聊天機器人的軟肋,就會盡可能的跟聊天機器人心平氣和的對話。一次不行,我再試一次,這個指令不管用,我再換一種問法。但對于普通用戶,可不會買賬。我們看下如圖 1 這個用戶,冷不丁的半夜被聊天機器人的怪笑嚇個半死。英文翻譯過來的意思就是「躺在床上正要睡著了,突然某某某音箱中的虛擬助手向我發(fā)出很大聲讓人毛骨悚然的笑聲... 今晚我要被殺了」。這個時候,如果是我的話,除了把它從樓上扔下去摔個粉碎之外,好像也沒有什么平復心情的辦法了。
圖 1. 用戶對聊天機器人的吐槽
再舉一個例子,在分析用戶使用數(shù)據(jù)的時候可以發(fā)現(xiàn),排名靠前的功能主要有閑聊、問天氣、播放音樂等。剛接觸這個行業(yè)的時候,我曾認為,既然是被高頻觸發(fā)的功能,就證明這些是用戶的「剛需」。只要對剛需功能做好優(yōu)化,用戶留存度和滿意度自然會大幅提升。后來才慢慢體會到,有些時候,并不是用戶真的最喜歡問天氣和播放音樂,而是其他的功能體驗感實在是差強人意,比較成熟的也就剩下天氣和音樂了。這就牽扯到「七宗罪」中的又一個「罪」:貪婪。用戶總是想得到更多,所以在剛拿到聊天機器人產(chǎn)品的時候,自然而然的會不斷試探其邊界,所以交互的內(nèi)容也會天馬行空,五花八門。但如果用戶得到的都是負面反饋,隨著期望的降低,問答范圍也會縮小到一些成熟和穩(wěn)定的功能上。就好像是新婚之夜,滿懷期待掀開新娘的面紗,卻發(fā)現(xiàn)等待著的是如花。
二、為什么要做聊天機器人
既然聊天機器人效果都做的不好,那為什么還有大量的公司一窩蜂涌入到這個市場?頭部廠商不惜重金做補貼,甚至能做到人民幣兩位數(shù)的售價。尤其像兒童教育聊天機器人,雖然已成為血海市場,仍然還有很多公司前赴后繼進入到這個賽道。
這還要從我們所處的時代說起。我是 80 后,很幸運經(jīng)歷了近 40 年技術(shù)爆發(fā)的 4 個時代,分別是 PC 時代、互聯(lián)網(wǎng)時代、移動互聯(lián)網(wǎng)時代和人工智能時代。而我們現(xiàn)在所處的人工智能時代,也正是 AI技術(shù)發(fā)展歷史上的第三次浪潮。
每一個時代都有其對應的入口級產(chǎn)品。在 80 到 90 年代,個人電腦是最主要的入口,其特點是「運算力改變生活」,個人電腦和 Windows 操作系統(tǒng),成就了 IBM 和微軟兩個硬件和軟件的巨頭。我至今還記得當時用一臺 486 電腦和 14 寸的球面顯示器,玩仙劍奇?zhèn)b傳的場景。而在隨后到來的互聯(lián)網(wǎng)時代,核心特點是「連接顛覆一切」,人們可以通過網(wǎng)絡隨時隨地進行信息搜索和信息交互,同時也造就了谷歌這樣一個偉大的公司。第三個時代是移動互聯(lián)網(wǎng)時代,移動技術(shù)帶來了兩大變革,一是數(shù)據(jù)利用效率的提升,導致服務發(fā)生了變化,人們可以隨時隨地享受例如叫車、點餐等即時服務,二是交互方式的改變,智能手機(主要是觸屏手機)成為了入口級設備,這個時代中最具有代表性的公司就是蘋果,iPhone 也成為了顛覆性的產(chǎn)品。
當人們跨越到人工智能時代,微軟又提出對話即平臺(Conversation As A Platform)的理念,并稱之為一種交互方式的「回歸」。之所以稱之為「回歸」,是因為從遠古時代起,語言是人類最自然的交互方式。人們通過語言來打招呼、八卦、協(xié)同狩獵,也就拉近了群體中人與人之間的距離。以色列歷史學家尤瓦爾?赫拉利的《人類簡史》甚至把「八卦」提到了非常重要的位置,是人與動物、人與其他史前人類的關(guān)鍵區(qū)別。以前由于技術(shù)的限制,人們不得不通過鍵盤和鼠標與機器進行「對話」,而現(xiàn)在我們具備了「對話即平臺」的條件,可以很好的實現(xiàn)這種最自然的交互方式,完成各種服務。因此,在人工智能時代,語音交互產(chǎn)品也自然而然成為了入口級產(chǎn)品,而聊天機器人就是一個最典型的體現(xiàn)。
因此,為了搶占這一「入口」,無論是技術(shù)巨頭還是創(chuàng)業(yè)大軍,都加入到了本就不寬的賽道中來,就如「千樹萬樹梨花開」一樣,出現(xiàn)了大量的聊天機器人產(chǎn)品。同時在 B 端和 G 端市場,為了顯得自己的高大上,很多大企業(yè)和政府機構(gòu)也都紛紛推出自己的智能問答系統(tǒng)。然而,好奇害死貓,「入口」害死人。現(xiàn)在的聊天機器人已經(jīng)變成了血海市場,哀鴻遍野。技術(shù)的低門檻,產(chǎn)品的同質(zhì)化,再加上頭部廠商的補貼策略,大公司長期虧損,中小型公司的生存更為艱難。尤其是 18 年開始的「資本寒冬」,很多的聊天機器人公司要么關(guān)門,要么轉(zhuǎn)型,這個我們暫時按下不表,后面還有更多討論。
三、聊天機器人是什么
聊天機器人從字面上來講,就是會聊天的機器人。但「會聊天」涵蓋的范圍太廣了。人們總是希望給事物打上標簽,給出定義。因此,對于聊天機器人而言,我們給出幾類角度不同的分類。
首先,從用途和使用場景上看,聊天機器人可以簡單分為功能類和娛樂類。所謂功能類,一般是為了解決某個特定的問題,比如說個人助理、音樂播放、兒童故事、網(wǎng)上購物等。而娛樂類,大多是為了陪伴用戶閑聊。微軟小娜(Cortana)和微軟小冰,分別是功能類和娛樂類的典型代表。
其次,從生態(tài)系統(tǒng)上看,聊天機器人可以分為產(chǎn)品、框架和平臺三類。我們在市場上所看到的,以及日常所使用的都稱之為「產(chǎn)品」,包括純軟件形態(tài)和軟硬件結(jié)合的品類,例如微軟小冰,亞馬遜 Echo、iPhone 上的 Siri,公子小白、小米音箱等。除此之外,為了加速實際產(chǎn)品的研發(fā),很多公司專門對外提供聊天機器人框架(Framework),以 SDK 或者 SAAS 服務的形態(tài),供需求方來構(gòu)建特定場景和領(lǐng)域的聊天機器人。典型代表包括支持 Echo 的 Amazon Alexa,微軟的 Luis with Bot 等。另外,一些純軟件形態(tài)的聊天機器人,需要承載其應用的「平臺」(Platform),比如說微信、Facebook 等。這樣就構(gòu)成了整個聊天機器人的生態(tài)體系。
最后,從交互方式上看,聊天機器人可以分為主動交互型和被動交互型兩種,其中,被動交互型又包括閑聊型、任務型和問答型三類。我們接觸到的絕大多數(shù)產(chǎn)品屬于被動交互,即由用戶發(fā)起對話,機器理解對話并作出相應的回應。主動交互可以更好的體現(xiàn)機器人和用戶之間的對等關(guān)系,即由機器人主動發(fā)起,通過共享或推薦用戶感興趣的熱點信息,和人類進行互動,但目前更多的是作為對傳統(tǒng)交互方式的一種補充,并未得到大規(guī)模廣泛應用。從被動交互的三種類型來看,閑聊型主要是進行客觀話題討論,或者用戶對聊天機器人進行一些情感表達,微軟小冰就具有很強的閑聊屬性。而任務型是為了滿足一個特定的任務或者目標,比如說利用 Siri 可以設定鬧鐘、預定餐館等。對于問答型聊天機器人,需要解決用戶對于事實型(Factoid)問答(如 what、which、who、where 和 when)問題的回復,以及非事實型問答(如 how 和 why)的回復。
用戶在和聊天機器人交互的過程中,會夾雜各式各樣的意圖。舉一個簡單的例子,以下是一段對話:
```
Q: 你知道阿楠的電話號碼么?
A: 知道
Q: 那你能告訴我他的號碼么?
A: 可以
```
我們可以看到,這其實是一段無意義的廢話。用戶的意圖是想要阿楠的電話號碼(任務型對話),而聊天機器人的回復完全屬于閑聊型對話。
四、理想和現(xiàn)實
從七十年前的原子彈,到五十年前的粒子對撞機,再到二十年前的基因編輯技術(shù),技術(shù)的在近百年來有了突飛猛進的發(fā)展。而在人工智能如此火熱的今天,為什么聊天機器人就做不好?這就需要先簡單聊一下人工智能技術(shù)的現(xiàn)狀。
文因互聯(lián)的鮑捷老師曾給出一個人工智能三次熱潮的曲線圖(圖 2),人工智能至今經(jīng)歷了三次大的熱潮。而這一輪人工智能熱潮,是伴隨著大數(shù)據(jù)和深度學習的興起。深度學習技術(shù)最早期的研究起始于上世紀六十年代的感知器,而直到最近的十年,隨著軟件和硬件的成熟,深度學習才取得了爆發(fā)式的進步,在多個領(lǐng)域例如圖像識別,語音識別等都突破了人類最好的成績。火熱的人工智能帶來了很多機會,也帶來了很多問題。資本的大量涌入,使得市場上涌現(xiàn)了一大批 AI 初創(chuàng)公司,同時媒體的大肆宣揚,也使得大眾的胃口和期望被吊得越來越高。普通的技術(shù)成果已無法吸引讀者的關(guān)注,很多媒體就開始用夸張的標題和內(nèi)容來吸引眼球,比如說「人類要被機器人取代」「重磅!機器開始威脅人類」等等。更不用說像 Sophia 這種偽 AI 的出現(xiàn),使得人們覺得 Sophia 就是人工智能應該有的樣子。而且,就好比 AlphaGo 并不能給人類端茶倒水一樣,在一個特定領(lǐng)域的優(yōu)秀表現(xiàn),并不能代表 AI 技術(shù)無所不能。又例如,谷歌在 2018 年開發(fā)者大會上演示了一個預約理發(fā)店的聊天機器人,人們在大呼驚艷的同時,自然而然的覺得人工智能技術(shù)應該可以上天入地,做到任何事情,甚至取代人類。
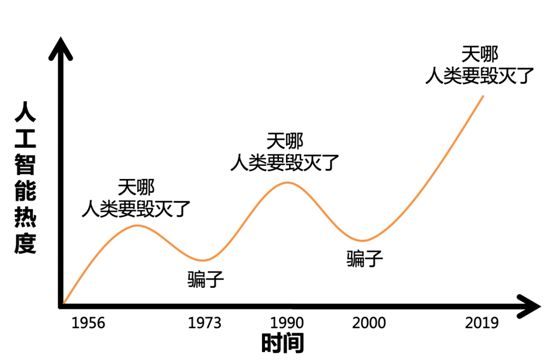
圖 2. 人工智能三次熱潮
這是技術(shù)從業(yè)者的悲劇。羅馬從來都不是一天能夠建成的,技術(shù)的突破也必然會經(jīng)歷一定時間的積累。很多時候,本來應該穩(wěn)步推進的技術(shù),卻在落地之時,面臨投資者和用戶被吊得足夠高的胃口,不得不去做一些虛假宣傳。比如說:「我的產(chǎn)品可以完美解決雞尾酒會效應」「訂咖啡、購物、訂票,我們的產(chǎn)品都可以幫你做到」等等。然后,就沒有然后了。
因此,人工智能除了經(jīng)典的三大主義(符號主義、連接主義、行為主義)之外,現(xiàn)在又多了第四個分類,叫做媒體主義。
回到深度學習技術(shù)的發(fā)展上來,AlphaGo都能打敗人類最頂尖的棋手,擁有 15 億參數(shù)的 GPT-2 模型已經(jīng)可以做到文本續(xù)寫,為什么深度學習卻沒有真正解決聊天機器人的自然交互?且不說訓練成本的問題,目前技術(shù)能夠做到比較好的基本上都是單輪交互(也就是一問一答),在多輪交互上,除了在某些特定場景可以表現(xiàn)較好(如 Google 開發(fā)者大會上的理發(fā)店預約場景),在開放式聊天中往往會慘不忍睹(這一點我們下一節(jié)會詳細討論)。而單輪交互,在技術(shù)上最簡單的解決方案,是寫一大堆的句子,并使用基本的檢索方法和規(guī)則來選取已經(jīng)寫好的答案來進行回復,甚至可以完全不用深度學習方法。所以才會出現(xiàn)僅通過堆語料就能創(chuàng)造出一個表現(xiàn)尚佳的聊天機器人。
作為從業(yè)者,從技術(shù)的角度上來講,聊天機器人的表現(xiàn)其實已經(jīng)非常不錯了。甚至在某一些特定場景下足以以假亂真了。我們經(jīng)常會被一些廣告營銷電話騷擾,以前還都是真人在和我們溝通,而現(xiàn)在出現(xiàn)了大量的聊天機器人,他們不知疲倦,可以 24 小時*7 天不間斷工作,通過電話語音,甚至很多情況下我們都無法判斷對方是不是機器人。這是因為,在特定場景下,對話可以跳轉(zhuǎn)的狀態(tài)一般都是有限的,可能產(chǎn)生的話題分支,比起圍棋的可能性要少很多,因此,即便是窮舉所有的可能性,也不是不可做到的事情。如果提前設置好對話策略,加上語音合成技術(shù),完全可以以假亂真。
我們都知道,圖靈測試由英國數(shù)學家阿蘭?圖靈于 1950 年發(fā)明,是指測試者在與被測試者(一個人和一臺機器)隔開的情況下,通過一些裝置(如鍵盤)向被測試者隨意提問。進行多次測試后,如果有超過 30% 的測試者不能確定出被測試者是人還是機器,那么這臺機器就通過了測試,并被認為具有人類智能。2014 年 6 月,一個偽裝成烏克蘭 13 歲男孩的機器人尤金?古特曼,順利的通過了圖靈測試。其實,通過這個測試也用了一些小技巧,比如說「13 歲男孩」,可以裝作自己的思考能力不夠成熟,同時,來自「烏克蘭」可以有效掩蓋其英文水平的不足。但嚴格意義上來說,通過圖靈測試并不能代表機器已經(jīng)具有自然對話的能力。曾看到過一篇關(guān)于圖靈生平的文章,提到圖靈在 1952 年被判犯有同性戀行為,并被迫接受化學閹割,兩年后圖靈自殺身亡。而圖靈測試,其實就是反映了在上世紀 50 年代的英國,每一位同性戀男性必須通過的日常測試:你是否能偽裝成一個異性戀者?根據(jù)圖靈的看法,未來的計算機就像當時的同性戀者,計算機有沒有意識并不重要,重要的是人類會怎么想。
即便是圖靈測試,也可以看做是一個特定的「閉域」,在這個閉域中,聊天的狀態(tài)是預先可以設計的,有很多的策略可以讓對話在這個特定的閉域順暢的進行下去。而很多聊天機器人廠商給自己挖的坑,是要做「開域」(也就是通用域)的聊天。在現(xiàn)有的技術(shù)條件下,這就相當于給自己的產(chǎn)品判了死刑。因為做通用域聊天,就等同于想要模擬人類真實的對話,這在目前是不可能完成的任務。具體緣由我們在下一節(jié)詳細闡述。
五、人是如何聊天的
在人類的聊天中,一句話所包含的文字,所反應的內(nèi)容僅僅是冰山一角。比如說「今天天氣不錯」,在早晨擁擠的電梯中和同事說,在秋游的過程中和驢友說,走在大街上的男女朋友之間說,在傾盆大雨中對同伴說,很可能代表完全不同的意思。在人類對話中需要考慮到的因素包括:說話者和聽者的靜態(tài)世界觀、動態(tài)情緒、兩者的關(guān)系,以及上下文和所處環(huán)境等,如圖 3。
圖 3. 人類聊天中的要素
靜態(tài)世界觀:人類在成長過程中會建立起自己的世界觀,一般跟跟經(jīng)歷和記憶有關(guān)。比如說一個素食主義者可能會非常厭惡談及紅燒肉的話題,又比如提及粉筆劃玻璃,會讓一部分人很不舒服,但對另一部分人卻沒任何影響。同時,對話的過程中也會觸發(fā)一些相關(guān)聯(lián)想,比如提到情人節(jié),會想到玫瑰花和巧克力,提到下雨天就會想到雨傘等。魯迅在《而已集?小雜感》也曾寫道「一見到短袖子,立刻想到白臂膊,立刻想到全裸體,(略),中國人的想像惟在這一層能夠如此飛躍」。
動態(tài)情緒:表現(xiàn)在交互過程中的表情、動作、語氣等。因為人類的交互過程通常需要接收多方面信息源,在不同語氣、不同表情,所表達的含義有可能完全不同。比如說「我恨你」,在戀人間輕柔的對話中很可能代表「我真的很喜歡你」。
說話者和聽者的關(guān)系:對話雙方是敵人、家人、朋友還是戀人,話語中所表達的意思就會有所區(qū)別。就比如剛剛的例子「今天天氣不錯」,在分手多年的戀人見面時說,很可能就代表「你現(xiàn)在過得好么」。
上下文:相同的詞語和句子,在不同的上下文中也會有不同的含義。「我洗頭去了」用于微信和 QQ 聊天中,很可能就代表「我不想聊了,再見」的意思。
所處環(huán)境:在不同場景下,相同話語會觸發(fā)不同的反饋。如果在廁所和人打招呼用「吃過了么」就會顯得非常尷尬了。
而且,以上這些都不是獨立因素,整合起來,才能真正反映一句話或者一個詞所蘊含的意思。這就是人類語言的奇妙之處。同時,人類在交互過程中,并不是等對方說完一句話才進行信息處理,而是隨著說出的每一個字,不斷的進行腦補,在對方說完之前就很可能了解到其所有的信息。再進一步,人類有很強的糾錯功能,在進行多輪交互的時候,能夠根據(jù)對方的反饋,修正自己的理解,達到雙方的信息同步。在回過頭看開放域的聊天機器人,寄希望于從一句話的文本理解其含義,這本身就是很不靠譜的一件事情。
目前市場上大部分的聊天機器人,還僅是單通道的交互(語音或文本),離人類多模態(tài)交互的能力還相差甚遠。哪怕僅僅是語音識別,在不同的噪音條件下也會產(chǎn)生不同的錯誤率,對于文本的理解就更加雪上加霜了。
六、技術(shù)及發(fā)展進度
在這一節(jié),我們討論下現(xiàn)有聊天機器人所涉及的技術(shù),但不會牽扯到技術(shù)細節(jié)。
機器學習和深度學習:機器學習技術(shù)屬于基礎技術(shù),比如說分類算法可以用于做用戶的意圖分類和情感分類;語言模型可以用于篩選語音識別后的句子是否通順;聚類算法可以用于做用戶的行為習慣分析等等。隨著數(shù)據(jù)量越來越多,可以發(fā)揮深度學習的優(yōu)勢,更進一步提升聊天機器人的基礎技術(shù)能力。
自然語言處理:是聊天機器人語義交互層面的核心技術(shù)。比如說檢索技術(shù)可以選取語料庫中最合適的回復,命名實體識別可以找出句子中的關(guān)鍵信息,如「播放李榮浩的李白」中,李白是指一首歌名。主體識別可以用于判斷句子的主語,例如「我給你唱歌」和「給我唱歌」的主語是不同的。此外,還有句型判斷、實體鏈接、詞性標注、依存分析等各項技術(shù),綜合運用于對用戶句子的解析。
數(shù)據(jù)庫技術(shù):通過數(shù)據(jù)庫技術(shù),我們可以在預先存儲好的大規(guī)模語料庫中,快速檢索相近的句子,也可以對海量的用戶交互數(shù)據(jù)進行存儲并進一步分析。
知識圖譜技術(shù):是聊天機器人實現(xiàn)認知交互的關(guān)鍵技術(shù)之一,可以幫助聊天機器人進行記憶、聯(lián)想和推理。關(guān)于知識圖譜,我們放到本文的下半部分專門討論。
聲學技術(shù):包括語音識別、語音合成、聲紋遷移、聲紋識別以及歌聲合成等,為聊天機器人提供了更加豐富的表現(xiàn)力。聲學技術(shù)也牽扯到和芯片、硬件(例如麥克風陣列)的配合。
計算機視覺技術(shù):通過計算機視覺技術(shù),可以進行人臉識別、情緒識別,并可以進一步配合語音、語義技術(shù)對用戶語句進行深度分析。
其他技術(shù):很多聊天機器人產(chǎn)品具備硬件形態(tài),包括虛擬形象,因此也需要芯片技術(shù)、硬件、全息技術(shù)、美術(shù)和設計的支持。
聊天機器人一定是一個技術(shù)整合的產(chǎn)物,在一個有很多串行模塊的系統(tǒng)中,有個很重要的問題是錯誤傳遞。比如說有 5 個串行模塊,每個模塊的性能都是 95%,最終的結(jié)果卻只有 77%。所以,在設計一個聊天機器人架構(gòu)的時候也需要盡可能避免模塊的串行化。同時,對于多輪交互架構(gòu),也需要有更加成熟的設計。
Gartner 給出的最新技術(shù)成熟度的圖,也反映了不同技術(shù)的發(fā)展現(xiàn)狀。網(wǎng)上流傳的一句話說到,當某個領(lǐng)域的代表性人物獲得了圖靈獎,也就代表了這個領(lǐng)域輝煌時代的結(jié)束。2019 年 3 月 27 日,ACM 宣布,深度學習的三位創(chuàng)造者 Yoshua Bengio,Yann LeCun,以及 Geoffrey Hinton 共同獲得了 2019 年的圖靈獎。在曲線中,我們也看到深度學習處于曲線的最高峰,并且即將處于下降的趨勢,也在一方面印證了隨著大數(shù)據(jù)紅利的消失,以深度學習為代表的感知智能也觸碰到了天花板。
圖 4. Gartner2018 技術(shù)成熟度曲線
破局
一、產(chǎn)業(yè)現(xiàn)狀
隨著人工智能的第三次浪潮,涌現(xiàn)了一大批聊天機器人公司,其中有平臺型公司,也有產(chǎn)品型公司。從業(yè)務角度上來看,主要分為三類:
2C 公司:主要產(chǎn)出直接面向用戶的產(chǎn)品,例如公子小白、小米音箱、天貓精靈、微軟小冰等;有一些公司還做開放性框架,例如海知智能的如意、百度的 UNIT 等。當然,還有一些公司專門針對聊天機器人推出技能包業(yè)務,比如說故事技能、冷笑話技能、訂票技能、大冒險游戲技能等。
2B 公司:主要做各種場景的落地,比如說金融領(lǐng)域的智能監(jiān)管系統(tǒng)、醫(yī)療領(lǐng)域的醫(yī)療問答助手和診斷助手、銀行柜臺的客服機器人、淘寶店家的智能客服等。有些時候,場景落地也是在跟風,例如各大銀行的智能客服,有一個感覺是別人做了,我就一定要做,這樣才顯得在 AI 上的先進性。但實際效果,大家在體驗之后也會有所判斷。
2G 公司:主要面向政府做政務類的知識庫構(gòu)建和問答業(yè)務。隨著人工智能被寫入政府工作報告,各級政府對于 AI 的落地應用都有比較高的需求。比如說政府服務大廳的引導型聊天機器人、一站式辦事機器人;政府部門的智能搜索引擎和問答系統(tǒng)等。
在 C 端市場,產(chǎn)品是需要挑剔的用戶買單的。正如本文上半部分所說,在目前的技術(shù)條件下,聊天機器人的使用感受遠未達到用戶的期望值,因此,很多 2C 公司在早期融資消耗完畢之后,產(chǎn)品也未得到用戶的認可,從而不得不考慮業(yè)務的轉(zhuǎn)型,走向 2B 和 2G 的賽道。但很清楚的一點是,轉(zhuǎn)型之后,并不一定是技術(shù)好的公司就能接到單子,能否拿到項目,其中的因素也請各位自己體會。
另外,有一個很重要的誤區(qū)在于高估了技術(shù)的作用。誠然,有一些非常優(yōu)秀的學者,或者大公司出來的技術(shù)高管,利用自己的實力和擁有的核心算法,成功的進行了融資和快速發(fā)展,比如說第四范式、三角獸、竹間智能等公司。但大多數(shù)宣稱自己擁有某一項壟斷性技術(shù)的公司,都沒有走到這一步。例如我前年曾經(jīng)關(guān)注過的某創(chuàng)業(yè)團隊,宣稱自己的 NLU 技術(shù)世界領(lǐng)先,包括分詞、詞性標注、依存、命名實體識別等,在其官網(wǎng)上也很自信的提供 NLU 平臺供用戶試用,想要打造一個開放的聊天機器人平臺。但現(xiàn)在再去看其發(fā)展,已經(jīng)開始轉(zhuǎn)向做 B 端的垂直場景業(yè)務了。另外還有一家公司,想用更深入的邏輯仿生技術(shù)打造機器人意識,然而其核心團隊人員已經(jīng)開始大量流失。
在目前的聊天機器人賽道上,很多成功的公司所使用的技術(shù)都不是自研發(fā)的,國內(nèi)很知名的一家代工廠商,通過集成開放的 API 和 SDK,也能夠打造一款低價的兒童聊天機器人,并做了很多 OEM 的業(yè)務。而且隨著 Google、Facebook 等巨頭的技術(shù)不斷開源,技術(shù)的門檻也越來越低,就算是擁有一個世界級領(lǐng)先的單點技術(shù),也很有可能不會比用規(guī)則匹配和大規(guī)模語料庫拼起來的產(chǎn)品效果更好。
當然,技術(shù)領(lǐng)先,在另一方面,也可以用于提升公司的形象,做更好的 PR,從而獲取更多的融資,吸引更優(yōu)秀的人才。達到一個正循環(huán)之后,可以用足夠多的資源將產(chǎn)品打造的更為優(yōu)秀。
大家常說人工智能的三大要素,包括數(shù)據(jù)、算法和算力。而在聊天機器人的技術(shù)體系下,最關(guān)鍵的三個因素應該是人工、數(shù)據(jù)和算法。而在現(xiàn)階段,人工是大于數(shù)據(jù),更大于算法的。工程化才是一個產(chǎn)品成功的關(guān)鍵。
二、知識圖譜能解決問題么
近兩年來,隨著 AI 熱度的降低,無論是投資者還是從業(yè)者,都開始關(guān)注另一項技術(shù)-知識圖譜。知識圖譜技術(shù)也是一個融合型技術(shù),包括數(shù)據(jù)庫、自然語言處理、知識表示、機器學習等等。其最近的火爆程度,可以從國內(nèi)知識圖譜的旗艦會議(CCKS)的參會人數(shù)一窺端倪。CCKS 全稱是全國知識圖譜與語義計算大會(China Conference on Knowledge Graph and Semantic Computing)。CCKS2016 成立之初只有 500 名參會者,這個數(shù)據(jù)到了 2017 年是 600 人,2018 年是 800 人,而 2019 年杭州的會議,預計參會者將突破 1000 人。
作為從感知智能到認知智能跨越的重要基石之一,知識圖譜被寄予了厚望。張鈸院士也提到,「沒有知識的 AI 不是真正的 AI」。拿最新的 GPT-2 算法來看,即使其文章續(xù)寫能力讓人贊嘆,也只是再次證明了足夠大的神經(jīng)網(wǎng)絡配合足夠多的訓練數(shù)據(jù),就能夠產(chǎn)生強大的記憶能力。但邏輯和推理能力,仍然是無法從記憶能力中自然而然的出現(xiàn)的。學界和企業(yè)界都寄希望于知識圖譜解決知識互連和推理的問題。那么什么是知識圖譜?簡單來說,就是把知識用圖的形式組織起來。可能這樣說還不夠明白,我們舉例子分別說下什么是知識,什么是圖譜。
所謂知識,是信息的抽象,一個很著名的 DIKW 體系,由 Rowley 在 2007 年提出,如圖 5 所示。從數(shù)據(jù)到信息到知識再到智慧,是一個不斷凝練的過程。
圖 5. DIKW 體系
舉一個簡單的例子來說,226.1 厘米,229 厘米,都是客觀存在的孤立的數(shù)據(jù)。此時,數(shù)據(jù)不具有任何的意義,僅表達一個事實存在。而「姚明臂展 226.1 厘米」,「姚明身高 229 厘米」,是事實型的陳述,屬于信息的范疇。對于知識而言,是在更高層面上的一種抽象和歸納,把姚明的身高、臂展,及姚明的其他屬性整合起來,就得到了對于姚明的一個認知,也可以進一步了解姚明的身高是比普通人更高的。最后的智慧層面,Zeleny 提到的智慧是指知道為什么(Know-why)[1],本文不對此進行深入論述。
圖譜的英文是 graph,直譯過來就是「圖」的意思。在圖論(數(shù)學的一個研究分支)中,圖(graph)表示一些事物(objects)與另一些事物之間相互連接的結(jié)構(gòu)。一張圖通常由一些結(jié)點(vertices 或 nodes)和連接這些結(jié)點的邊(edge)組成。Sylvester 在 1878 年首次提出了「圖」這一名詞 [2]。如果我們把姚明相關(guān)的「知識」用「圖譜」構(gòu)建起來,就是圖 6 所體現(xiàn)的內(nèi)容。
圖 6. 姚明的基本信息知識圖譜
在聊天機器人中使用知識圖譜,我們的期望是能夠解決很多復雜的推理問題,包括常識推理問題。比如說「雞蛋放到籃子里,是雞蛋大還是籃子大」,「蘇大強的大兒子是誰」等等。從而使得聊天機器人的對話更加具有「智慧」,不僅能記憶,還能推理、聯(lián)想和推薦,從感知層面真正跨越到認知層面。
愿望是美好的,但真正將知識圖譜落地卻鮮見成功案例。考慮到成本問題,知識圖譜問答在聊天機器人中的應用還不夠廣泛。況且,一些需求方對知識圖譜還存在不少誤區(qū)。很多企業(yè)和政府機構(gòu)在談項目需求的時候,一上來就說,「我想用知識圖譜技術(shù),你們能不能把現(xiàn)在的知識庫變成知識圖譜?實現(xiàn)大數(shù)據(jù)的鏈接?」「你們做的問答是不是基于知識圖譜的問答?」等等,其實,知識圖譜問答能不能應用,要綜合考量多方面因素,就拿知識的表示和存儲來說,選用不同的數(shù)據(jù)庫,需要用到不同的知識表示。RDF(數(shù)據(jù)的一種三元組表示形式)的數(shù)據(jù)表示可以選用 Jena 數(shù)據(jù)庫,而圖表示可以選用 Neo4j 圖數(shù)據(jù)庫。對不同來源的數(shù)據(jù)還需要進行大量的數(shù)據(jù)清洗和結(jié)構(gòu)化,甚至還牽扯到紙質(zhì)文檔(例如醫(yī)院的文本病歷)的手工錄入。結(jié)合業(yè)務來看,很多時候傳統(tǒng)關(guān)系型數(shù)據(jù)庫就能解決的問題,完全沒必要用到大規(guī)模圖數(shù)據(jù)庫,否則很容易導致整個項目的成本高、效率低的問題。
Heiko Paulheim 在其文章《How much is a Triple?Estimating the Cost of Knowledge Graph Creation》中,給出了幾個典型的知識圖譜的構(gòu)建成本。其中,上世紀 80 年代開始的也是最早的知識圖譜項目 CYC,平均構(gòu)建一條陳述句和斷言的成本是 5.71 美元,而隨著自然語言處理和機器學習技術(shù)的進步,DBpedia 構(gòu)建每一條的成本降低到了 1.85 美分。即便如此,在真正工程化落地的時候,牽扯到多源數(shù)據(jù)的清洗整合,一個知識圖譜項目的成本還是居高不下。
三、垂直領(lǐng)域的戰(zhàn)略收縮
在人工智能投資火爆的前幾年,我們經(jīng)常會看到估值十億到幾十億的聊天機器人(或智能問答系統(tǒng))公司。就像渾水沉淀后能看見底下的泥沙,隨著資本的逐漸冷靜,很多公司也進入了艱難的寒冬期。這沒什么不好,真正優(yōu)秀的公司,無論是技術(shù)和商業(yè)模式,都能夠經(jīng)得起考驗。
聊天機器人公司,在戰(zhàn)略收縮的時候,首先要做的是看清自己公司的核心競爭力。最近看了一本書叫做《失去的勝利》,里面提到了德國名將曼施坦因?qū)Χ?zhàn)初期波蘭戰(zhàn)役的回顧和評論。當?shù)聡讶姘鼑ㄌm西部的時候,波蘭軍隊仍然把主力沿著邊境部署,而不愿意放棄西部工業(yè)區(qū),并收縮到維斯托拉河流域右線重點設防。甚至還寄希望以英法聯(lián)軍的支援,反攻至柏林。結(jié)果可想而知,幻想守住一切,反倒丟掉了一切。
大部分初創(chuàng)公司,應該是集中優(yōu)勢力量突破一個點,等待資本回暖。同時精耕細作一個細分領(lǐng)域,在大公司無暇顧及的垂直行業(yè)殺出一條血路。無論是后期被收購還是能夠獨立壯大,都是比較好的結(jié)果。切忌大而全,什么都想做,做自己擅長的才是最重要的。舉例來說,一些公司利用硬件優(yōu)勢轉(zhuǎn)型打造語音交互芯片,另外還有金融知識圖譜公司從智能投顧轉(zhuǎn)為智能監(jiān)管,還有大批聊天機器人公司,從做純軟件的聊天機器人轉(zhuǎn)為為 B 端客戶提供智能客服解決方案。
而且,對于做平臺這個事情,要單獨提出來聊一聊。自然語言交互平臺,沒有大量的人員和資金支持,是無法實現(xiàn)的。由于沒有辦法進行工業(yè)級產(chǎn)出,導致了大量資本投入換來的只是 Demo 和論文,而不是實實在在的產(chǎn)品。因此,在細分領(lǐng)域做強做好,才是小公司的生存之道。
四、商業(yè)模式和產(chǎn)品的重要性
從技術(shù)到產(chǎn)品落地,還只是萬里長征的第一步,產(chǎn)品在市場上真正被用戶所接受,并能產(chǎn)生良性的流水和利潤,這才是正常的商業(yè)模式。我們看下目前幾個比較火熱的聊天機器人產(chǎn)品。首先是兒童教育機器人,教育、醫(yī)療和金融是一直都很熱的領(lǐng)域。自然而然的,很多產(chǎn)品都會冠以人工智能教育機器人的名號。但兒童教育聊天機器人真正能解決用戶需求么?很明顯不能。大多數(shù)家長還是報以嘗鮮的心態(tài),給孩子買一個玩具,并沒有寄希望于讓機器人起到「教育」的作用。但畢竟兒童市場是巨大的,中國有 1.5 億 3 到 12 歲的兒童,每年的新生嬰兒數(shù)量也達到了 2000 萬。兒童教育機器人的出貨量在近三年一直保持著 100% 的增長。因此,在這個市場上,影響用戶購買的很重要的一個因素是價格,也就造成了目前整個行業(yè)利潤的持續(xù)走低。隨著更多廠商的加入,紅海市場也逐漸變成了血海市場。另外一個典型的案例是老人陪聊機器人,這種機器人從商業(yè)模式上來看,我認為并不成立。首先,老人們對聊天機器人的接受程度不高,購買力也不強。其次,老人在對話過程中,由于對話速度、連貫性、方言等問題,使得聊天機器人的表現(xiàn)要更差。
最近網(wǎng)上討論的很多的一個典型案例是夸夸機器人。其來源是「相互表揚小組」,這些活躍在 QQ、微信、微博上的社群的目的,言簡意賅又單刀直入:溜須拍馬,相互夸獎。無論是高興的事情例如考上了大學、獲得了獎勵,還是倒霉的事情例如被老板罵,烤糊了面包,在群里都可以得到天花亂墜的夸贊。而有公司還真的將夸夸機器人產(chǎn)品化,但結(jié)果是曇花一現(xiàn),僅是蹭了一波熱度,卻沒有持續(xù)的用戶留存。其實,夸夸機器人在商業(yè)角度上是不成立的,沒有一個可行的變現(xiàn)路徑。三聯(lián)生活周刊有個評論說到:「人們?nèi)菀诪榭旃?jié)奏的生活所累,更容易在各種新鮮事物面前短暫停留。所以人們也清醒地意識到:來自陌生人的鼓舞與表揚雖然溫暖,但保質(zhì)期卻是極其有限與流于表層的」,因此付費求夸的事情也變得不切實際了。
再來看下 2B 的業(yè)務,真正成功的項目應該是給需求方帶來成本的降低或收益的提升。比如說淘寶店家的客服機器人,一套系統(tǒng)的成本,如果能夠低于將 200 位人工客服降低到 100 位所節(jié)省下來的成本,同時在獲客效果上又有所提升,那就是一個成功的項目。況且,對于開發(fā)者而言,從單一項目逐步變?yōu)?PAAS 服務或 SAAS 服務,所帶來的開發(fā)成本會顯著降低,也就可以為規(guī)模化打下良好的基礎。
剛剛聊了一些商業(yè)模式的問題,那么從產(chǎn)品形態(tài)上,有一句流行的話說的是「技術(shù)不夠,產(chǎn)品來湊;產(chǎn)品不夠,運營來湊」。既然聊天機器人受限于技術(shù)無法達到人類期望值,那么是否可以從產(chǎn)品設計的角度上,讓用戶不去關(guān)注技術(shù)表現(xiàn)本身,而是從其他維度對產(chǎn)品產(chǎn)生粘性?答案是肯定的。做產(chǎn)品的關(guān)鍵在于「高出用戶期望值」,這顯然對于 AI 產(chǎn)品是不友好的,因為用戶期望值太高了,所以要在其他層面上去想辦法。文章一開始提到,產(chǎn)品設計的一個原則應該貼合人類的七宗罪。我們曾經(jīng)獲取過一批來自不同聊天機器人脫敏后的用戶聊天數(shù)據(jù),其中包含了很多難等大雅之堂的語言。所以有一些成人用品公司開始用對話技術(shù)包裝自己的產(chǎn)品,也算是一種成功的商業(yè)實踐了。
當然,從正常的產(chǎn)品角度而言,如果一個聊天機器人產(chǎn)品的形象和使用感受,超越了聊天本身,給用戶帶來了不同的驚艷感,也可以算得上一種取長補短的方法。正如我們下一節(jié)要討論的聊天機器人的更多形態(tài),如果聊天機器人被人格化、IP 化之后,用戶也不會僅僅關(guān)注對話,而是會從更多的需求層面產(chǎn)生對產(chǎn)品的粘性。
五、多模態(tài)交互和虛擬生命
在技術(shù)不斷進步的同時,聊天機器人也逐步邁向其下一代范式-虛擬生命。其核心在于模擬生命的主要特征,以多形態(tài)和多模態(tài)進行交互 [3]。設想一下,如果你是蔡徐坤的粉絲,如果有一個聊天機器人具備蔡徐坤的形態(tài)和聲音,并且可以進行交互,那是多么令人興奮的一件事情。同時,在不同的性格和人設下,虛擬生命的交互體驗也會變得更為豐富。
再進一步,除了 IP 化和人格化,多模態(tài)交互能力會進一步增強虛擬生命對用戶的認知和表現(xiàn)力。虛擬生命能夠通過麥克風陣列、攝像頭聽得到、看得見,使其能夠綜合感知用戶意圖。同時,利用知識圖譜,虛擬生命能夠和人以及周圍環(huán)境進行「真實自然」的交流,包括規(guī)劃、推理、聯(lián)想、情感和學習能力,具有非常強的可用性和可交互性。再進一步,通過美術(shù)設計、動作捕捉、全息投影等技術(shù),虛擬生命可以在不同設備、不同場景下展示不同的形象,除了自然語言交流,還可以進行舞蹈、唱歌等更多樣的體現(xiàn)。
目前日本的 Gatebox 和國內(nèi)的狗尾草智能科技,都提出了聊天機器人的虛擬生命形態(tài)。例如,狗尾草智能科技開發(fā)了世界上第一款結(jié)合了 GAVE 引擎(Gowild AI Virtual Engine)的虛擬生命產(chǎn)品-琥珀?虛顏(如圖 7),搭載 HoloEra 硬件平臺及 360°全息投影,創(chuàng)造一個有情感、可養(yǎng)成、可進化的虛擬存在,但這種存在又可以和周邊世界進行多模態(tài)真實互動,并針對用戶行為習慣形成不同的性格體系。同時,人物還可以換成二次元角色和真實的明星,進一步提升用戶體驗和粘性。
圖 7. 虛擬生命產(chǎn)品-琥珀?虛顏
在這個新的賽道上,相信未來的聊天機器人以及虛擬生命,會以更好的形態(tài)和體驗感呈現(xiàn)給我們。
六、革命尚未成功,同志仍需努力
在這個廣闊的市場上,進步的空間還很大,挑戰(zhàn)還有很多。但有挑戰(zhàn)的事情才有意思,不是么?
-
人工智能
+關(guān)注
關(guān)注
1796文章
47666瀏覽量
240272 -
聊天機器人
+關(guān)注
關(guān)注
0文章
343瀏覽量
12368 -
ai技術(shù)
+關(guān)注
關(guān)注
1文章
1290瀏覽量
24451
原文標題:聊天機器人:困境和破局
文章出處:【微信號:jingzhenglizixun,微信公眾號:機器人博覽】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論