 西安交通大學人工智能與機器人研究所公開全球首個五維駕駛場景理解數據集
西安交通大學人工智能與機器人研究所公開全球首個五維駕駛場景理解數據集
在自主駕駛領域,已經建立了大量的數據集來輔助完成三維或二維目標檢測、立體視覺、語義或實例分割等任務。然而,更有意義的自主車輛周圍對象的動態演化卻很少被利用,并且缺乏大規模的數據集平臺。為了解決這個問題,西安交通大學構建并公開了BLVD數據集,與以往靜態檢測、語義或者實例分割任務的數據集不同,BLVD旨在為動態4D跟蹤(3D+時間)、5D交互事件識別(4D+交互行為)和意圖預測等任務提供一個統一的驗證平臺。
BLVD數據集與之前的數據集相比將體現出對交通場景的更深層次理解。BLVD一共標注654個包含12萬幀的序列。并進行了全序列5D語義注釋。包含249129條3D目標框,4902個有效可跟蹤的獨立個體,包含總長度約214900個跟蹤點,6004個用于5D交互事件識別的有效片段以及4900個可以進行5D意圖預測的目標。根據標注場景中交通參與者的密集程度(低和高)和光照條件(白天和晚上),BLVD包含四種場景。
論文發表于ICRA2019,BLVD數據集已經公開,并可在github項目站點:
https://github.com/VCCIV/BLVD/下載。
論文網址參見:https://arxiv.org/abs/1903.06405
在BLVD數據集中,定義了三種參與者,包括車輛、行人和騎行者,其中騎行者包括騎自行車的人和摩托車的人。數據構建由西安交通大學夸父號無人車采集,采集車上裝載多種傳感器用于周圍感知,包括一個Velodyne HDL-64E三維激光雷達、一個全球定位系統(GPS)及慣性導航系統、兩個高分辨率多視點相機。值得注意的是,所裝載的所有的傳感器都是自動進行了時鐘同步和對齊。與以往的駕駛場景中的三維目標跟蹤、行為理解與分析數據集相比,BLVD具有更豐富的場景多樣性。包含不同駕駛場景(城市和高速公路)、多種光照條件(白天和晚上)、多種個體密度。圖1給出了一個典型的簡介,它表示從數據集測試的靜態3D注釋到5D意圖預測的任務流程。
圖1 BLVD上5D語義注釋的任務流示意。(a)表示包含多個靜態三維目標的數據幀,(b)展示4D(3D+時間)維度的三維目標跟蹤,(c)表示5D交互行為類型,每一個個體都進行了類型標注。(d)展示5D意圖預測示意,包含位置預測、3D框的幾何結構、朝向和行為交互狀態預測。
值得注意的是,BLVD的不同數據任務具有一致的數據劃分標準,可以提供從三維目標跟蹤、五維度行為交互狀態識別、五維度意圖預測任務的串行多任務驗證。其中對于五維度行為交互狀態識別,對于不同的交通參與者,如車輛、行為何騎行者,分別設定了13種、8種及7種行為狀態,如圖2所示。
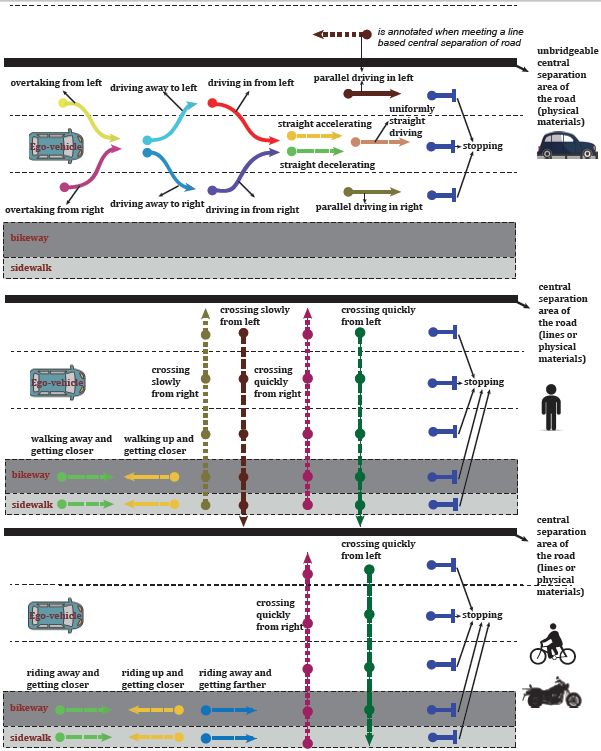
圖2基于車輛坐標系的交互行為類型的說明。從上到下依次展示活動車輛、行人和騎手的活動類型。注意,有一個額外的參與者交互行為類型(指“其它”)用于表示其他的交互行為類型。
【結論】
西安交通大學人工智能與機器人研究所研究人員為自主駕駛構建的大規模5D語義數據集,采集于多種駕駛場景,并能夠高效、準確地進行校準、同步和校正。不同于以往的靜態檢測/分割任務,他們更注重對交通場景的深入理解。具體來說,本次數據標注了4D跟蹤、5D交互狀態識別、5D意向預測等任務。在不斷的優化完善下,相信這個數據集將在機器人和計算機視覺領域非常有用。
-
傳感器
+關注
關注
2553文章
51407瀏覽量
756634 -
激光雷達
+關注
關注
968文章
4028瀏覽量
190424 -
數據集
+關注
關注
4文章
1209瀏覽量
24835
原文標題:西安交通大學人工智能與機器人研究所公開全球首個五維駕駛場景理解數據集
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
【「具身智能機器人系統」閱讀體驗】1.初步理解具身智能
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
【「具身智能機器人系統」閱讀體驗】+數據在具身人工智能中的價值
【「具身智能機器人系統」閱讀體驗】+初品的體驗
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊
優艾智合與西安交大成立具身智能機器人研究院

名單公布!【書籍評測活動NO.51】具身智能機器人系統 | 了解AI的下一個浪潮!
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
開啟全新AI時代 智能嵌入式系統快速發展——“第六屆國產嵌入式操作系統技術與產業發展論壇”圓滿結束
FPGA在人工智能中的應用有哪些?
阿爾泰科技與西安交通大學陜西省某技術重點實驗室共謀未來!

人工智能與機器人的區別
直線電機生產廠家談高校建成投用人形機器人研究院






 工商網監
工商網監
評論