 探討一些可用于解釋機器學習模型的不同技術
探討一些可用于解釋機器學習模型的不同技術
【導語】模型的可解釋性是大多數機器學習系統都需要的一種能力,即能向用戶解釋模型能做出這些預測的原因。在本篇文章中,作者將與大家探討一些可用于解釋機器學習模型的不同技術,并且重點介紹兩種提供全局和局部解釋、且與模型本身無關可解釋性技術。這些技術可以應用于任何機器學習算法,并通過分析機器學習模型的響應函數來實現可解釋性。
前言
在選擇一個合適的機器學習模型時,通常需要我們權衡模型準確性與可解釋性之間的關系:
黑盒模型 (black-box):諸如神經網絡、梯度增強模型或復雜的集成模型此類的黑盒模型 (black-box model) 通常具有很高的準確性。然而,這些模型的內部工作機制卻難以理解,也無法估計每個特征對模型預測結果的重要性,更不能理解不同特征之間的相互作用關系。
白盒模型(white-box):另一方面,像線性回歸和決策樹之類的簡單模型的預測能力通常是有限的,且無法對數據集內在的復雜性進行建模 (如特征交互)。然而,這類簡單模型通常有更好的可解釋性,內部的工作原理也更容易解釋。
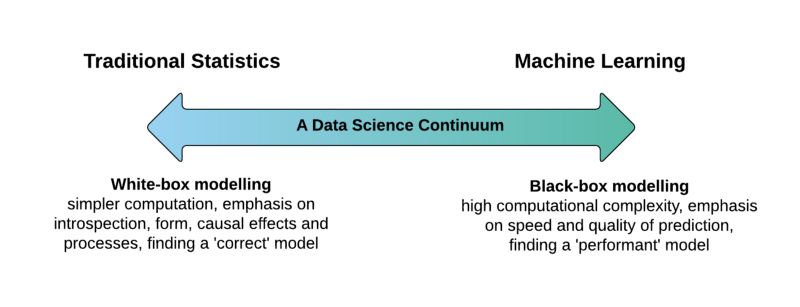
模型準確性與可解釋性關系之間的權衡取決于一個重要的假設:“可解釋性是模型的一個固有屬性”。通過正確的可解釋性技術,任何機器學習模型內部工作機理都能夠得以解釋,盡管這需要付出一些復雜性和計算成本的代價。
模型屬性
機器學習模型的可解釋程度通常與響應函數 (response function) 的兩個屬性相關。模型的響應函數 f(x) 定義模型的輸入 (特征x) 和輸出 (目標函數 f(x)) 之間的輸入-輸出對關系,而這主要取決于機器學習模型,該函數具有以下特征:
線性:在線性響應函數中,特征與目標之間呈線性關系。如果一個特征線性變化,那么期望中目標將以相似的速率線性變化。
單調性:在單調響應函數中,特征與目標對于之間的關系始終在一個方向上變化 (增大或減小)。更重要的是,這種關系適用于整個特征域,且與其他的特征變量無關。
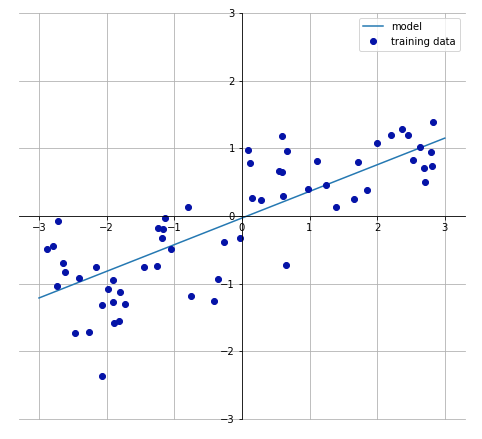
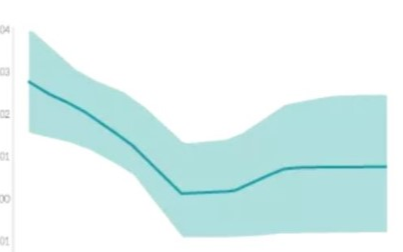
單調線性響應函數實例 (其中輸入變量為 x,響應變量為 y)
線性回歸模型的響應函數就是個線性單調函數,而隨機森林和神經網絡的響應函數則是高度非線性、非單調響應函數的例子。
下圖則闡述了在需要清晰簡單的模型可解釋性時,通常首選白盒模型 (具有線性和單調函數) 的原因。圖的上半部顯示,隨著年齡的增長,購買數量會增加,模型的響應函數在全局范圍內具有線性和單調關系,易于解釋模型。
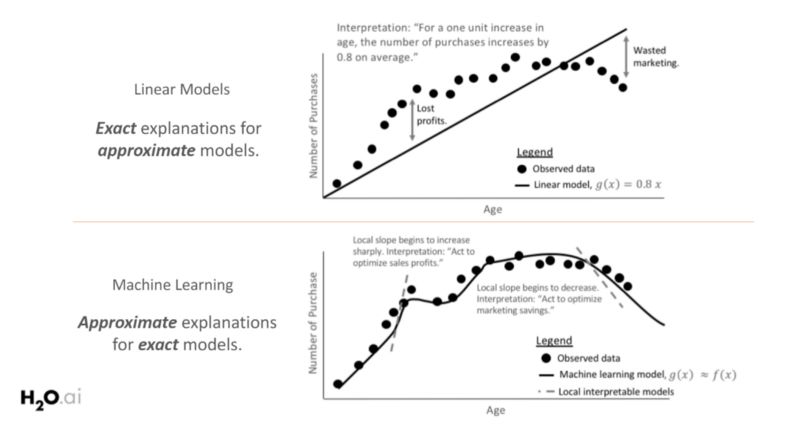
然而,由于白盒模型響應函數的線性和單調約束,通常容易忽略其變化趨勢的重要部分。通過探索更復雜的機器學習模型能夠更好地擬合觀測數據,而這些復雜模型的響應函數只是在局部呈單調線性變化。因此,為了解釋模型的行為,研究模型局部變化情況是很有必要的。
模型可解釋性的范圍,如全局或局部層面,都與模型的復雜性緊密相關。線性模型在整個特征空間中將表現出相同的行為 (如上圖所示),因此它們具有全局可解釋性。而輸入和輸出之間的關系通常受到復雜性和局部解釋的限制 (如為什么模型在某個數據點進行某種預測?),將其默認為全局性解釋。
對于那些更復雜的模型,模型的全局行為就更難定義了,而且還需要對其響應函數的小區域進行局部解釋。這些小區域可能表現出線性和單調,以便得到更準確的解釋。
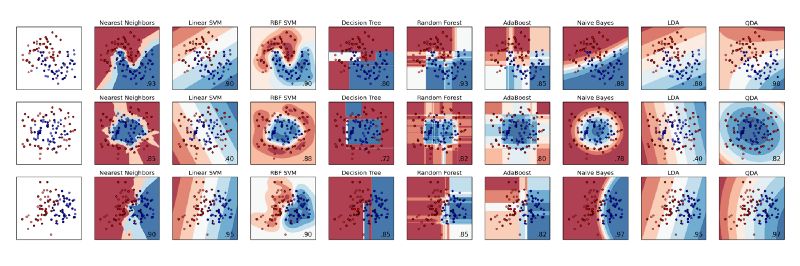
ML 庫 (例如 sklearn) 允許對不同分類器進行快速比較。當數據集的大小和維度受限時,我們還可以解釋模型的預測結果。但在大多數現實問題中,情況就不再是如此。
接下來將為大家重點介紹兩種提供全局和局部解釋、且與模型本身無關可解釋性技術。這些技術可以應用于任何機器學習算法,并通過分析機器學習模型的響應函數來實現可解釋性。
可解釋性技術
1、代理模型 (Surrogate models)
代理模型通常是一種簡單模型,用于解釋那些復雜模型。常用的代理模型有線性模型和決策樹模型,主要是由于這些模型易于解釋。構建代理模型,將其用于表示復雜模型 (響應函數) 的決策過程,并作用于輸入和模型預測,而不是在輸入和目標上訓練。
代理模型在非線性和非單調模型之上提供了一個全局可解釋層,但它們不完全相互依賴。它的作用只要是作為模型的“全局總結”,并不能完美地表示模型底層的響應函數,也不能捕獲復雜的特征關系。以下步驟說明了如何為復雜的黑盒模型構建代理模型:
訓練一個黑盒模型。
在數據集上評估黑盒模型。
選擇一個可解釋的代理模型 (通常是線性模型或決策樹模型)。
在數據集上訓練這個可解釋性模型,并預測。
確定代理模型的錯誤度量,并解釋該模型。
2、LIME
LIME 是另一種可解釋性技術,它的核心思想與代理模型相同。然而,LIME 并不是通過構建整個數據集的全局代理模型,而只是構建部分區域預測解釋的局部代理模型 (線性模型),來解釋模型的行為。有關 LIME 技術的深入解釋,可以參閱 LIME 有關的文章
文章鏈接:
https://towardsdatascience.com/understanding-model-predictions-with-lime-a582fdff3a3b
此外,LIME 方法能夠提供一種直觀的方法來解釋給定數據的模型預測結果。有關如何為復雜的黑盒模型構建 LIME 解釋模型的步驟如下:
訓練一個黑盒模型。
采樣局部感興趣區域的樣本點,這些樣本點可以從數據集中直接檢索,也可以人工生成。
通過鄰近的感興趣區域對新樣本進行加權,通過在數據集上使用變量來擬合得到一個加權的、可解釋的代理模型。
解釋這個局部代理模型。
結論
總的來說,你可以通過幾種不同的技術來提高機器學習模型的可解釋性。盡管,隨著相關領域研究的改進,這些技術也將變得越來越強大,但使用不同技術并進行比較仍然是很重要的。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101172 -
機器學習
+關注
關注
66文章
8439瀏覽量
133087 -
數據集
+關注
關注
4文章
1209瀏覽量
24834
原文標題:機器學習的可解釋性:黑盒vs白盒(內附開源學習書) | Deep Reading
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論