 為大家介紹三個NLP領域的熱門詞匯
為大家介紹三個NLP領域的熱門詞匯
編者按:在過去的一段時間,自然語言處理領域取得了許多重要的進展,Transformer、BERT、無監督機器翻譯,這些詞匯仿佛在一夜之間就進入了人們的視野。你知道它們具體都是什么意思嗎?今天,我們就將為大家介紹三個NLP領域的熱門詞匯。
Transformer
Transformer在2017年由Google在題為《Attention Is All You Need》的論文中提出。Transformer是一個完全基于注意力機制的編解碼器模型,它拋棄了之前其它模型引入注意力機制后仍然保留的循環與卷積結構,而采用了自注意力(Self-attention)機制,在任務表現、并行能力和易于訓練性方面都有大幅的提高。
在 Transformer 出現之前,基于神經網絡的機器翻譯模型多數都采用了 RNN的模型架構,它們依靠循環功能進行有序的序列操作。雖然 RNN 架構有較強的序列建模能力,但是存在訓練速度慢,訓練質量低等問題。
與基于 RNN 的方法不同,Transformer 模型中沒有循環結構,而是把序列中的所有單詞或者符號并行處理,同時借助自注意力機制對句子中所有單詞之間的關系直接進行建模,而無需考慮各自的位置。具體而言,如果要計算給定單詞的下一個表征,Transformer 會將該單詞與句子中的其它單詞一一對比,并得出這些單詞的注意力分數。注意力分數決定其它單詞對給定詞匯的語義影響。之后,注意力分數用作所有單詞表征的平均權重,這些表征輸入全連接網絡,生成新表征。
由于 Transformer 并行處理所有的詞,以及每個單詞都可以在多個處理步驟內與其它單詞之間產生聯系,它的訓練速度比 RNN 模型更快,在翻譯任務中的表現也比 RNN 模型更好。除了計算性能和更高的準確度,Transformer 另一個亮點是可以對網絡關注的句子部分進行可視化,尤其是在處理或翻譯一個給定詞時,因此可以深入了解信息是如何通過網絡傳播的。
之后,Google的研究人員們又對標準的 Transformer 模型進行了拓展,采用了一種新型的、注重效率的時間并行循環結構,讓它具有通用計算能力,并在更多任務中取得了更好的結果。
改進的模型(Universal Transformer)在保留Transformer 模型原有并行結構的基礎上,把 Transformer 一組幾個各異的固定的變換函數替換成了一組由單個的、時間并行的循環變換函數構成的結構。相比于 RNN一個符號接著一個符號從左至右依次處理序列,Universal Transformer 和 Transformer 能夠一次同時處理所有的符號,但 Universal Transformer 接下來會根據自注意力機制對每個符號的解釋做數次并行的循環處理修飾。Universal Transformer 中時間并行的循環機制不僅比 RNN 中使用的串行循環速度更快,也讓 Universal Transformer 比標準的前饋 Transformer 更加強大。
預訓練Pre-train
目前神經網絡在進行訓練的時候基本都是基于后向傳播(Back Propagation,BP)算法,通過對網絡模型參數進行隨機初始化,然后利用優化算法優化模型參數。但是在標注數據很少的情況下,通過神經網絡訓練出的模型往往精度有限,“預訓練”則能夠很好地解決這個問題,并且對一詞多義進行建模。
預訓練是通過大量無標注的語言文本進行語言模型的訓練,得到一套模型參數,利用這套參數對模型進行初始化,再根據具體任務在現有語言模型的基礎上進行精調。預訓練的方法在自然語言處理的分類和標記任務中,都被證明擁有更好的效果。目前,熱門的預訓練方法主要有三個:ELMo,OpenAI GPT和BERT。
在2018年初,艾倫人工智能研究所和華盛頓大學的研究人員在題為《Deep contextualized word representations》一文中提出了ELMo。相較于傳統的使用詞嵌入(Word embedding)對詞語進行表示,得到每個詞唯一固定的詞向量,ELMo 利用預訓練好的雙向語言模型,根據具體輸入從該語言模型中可以得到在文本中該詞語的表示。在進行有監督的 NLP 任務時,可以將 ELMo 直接當做特征拼接到具體任務模型的詞向量輸入或者是模型的最高層表示上。
在ELMo的基礎之上,OpenAI的研究人員在《Improving Language Understanding by Generative Pre-Training》提出了OpenAI GPT。與ELMo為每一個詞語提供一個顯式的詞向量不同,OpenAI GPT能夠學習一個通用的表示,使其能夠在大量任務上進行應用。在處理具體任務時,OpenAI GPT 不需要再重新對任務構建新的模型結構,而是直接在 Transformer 這個語言模型上的最后一層接上 softmax 作為任務輸出層,再對這整個模型進行微調。
ELMo和OpenAI GPT這兩種預訓練語言表示方法都是使用單向的語言模型來學習語言表示,而Google在提出的BERT則實現了雙向學習,并得到了更好的訓練效果。具體而言,BERT使用Transformer的編碼器作為語言模型,并在語言模型訓練時提出了兩個新的目標:MLM(Masked Language Model)和句子預測。MLM是指在輸入的詞序列中,隨機的擋上 15% 的詞,并遮擋部分的詞語進行雙向預測。為了讓模型能夠學習到句子間關系,研究人員提出了讓模型對即將出現的句子進行預測:對連續句子的正誤進行二元分類,再對其取和求似然。
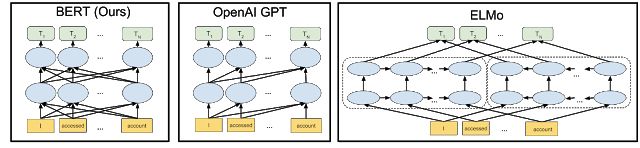
圖片來源:Google AI Blog
無監督機器翻譯
Unsupervised Machine Translation
現有的機器翻譯需要大量的翻譯文本做訓練樣本,這使得機器翻譯只在一小部分樣本數量充足的語言上表現良好,但如何在沒有源翻譯的情況下訓練機器翻譯模型,即無監督訓練,成為了目前熱門的研究話題。Facebook在EMNLP 2018上的論文《Phrase-Based & Neural Unsupervised Machine Translation》利用跨字嵌入(Cross Word Embedding),提升了高達11 BLEU,那么Facebook是如何實現的呢?
第一步是讓系統學習雙語詞典。系統首先為每種語言中的每個單詞訓練詞嵌入,訓練詞嵌入通過上下文來預測給定單詞周圍的單詞。不同語言的詞嵌入具有相似的鄰域結構,因此可以通過對抗訓練等方法讓系統學習旋轉變換一種語言的詞嵌入,以匹配另一種語言的詞嵌入。基于這些信息,就可以得到一個相對準確的雙語詞典,并基本可以實現逐字翻譯。在得到語言模型和初始的逐字翻譯模型之后,就可以構建翻譯系統的早期版本。
然后將系統翻譯出的語句作為標注過的真實數據進行處理,訓練反向機器翻譯系統,得到一個更加流暢和語法正確的語言模型,并將反向翻譯中人工生成的平行句子與該語言模型提供的校正相結合,以此來訓練這個翻譯系統。
通過對系統的訓練,形成了反向翻譯的數據集,從而改進原有的機器翻譯系統。隨著一個系統得到改進,可以使用它以迭代方式在相反方向上為系統生成訓練數據,并根據需要進行多次迭代。
逐字嵌入初始化、語言建模和反向翻譯是無監督機器翻譯的三個重要原則。將基于這些原理得到的翻譯系統應用于無監督的神經模型和基于計數的統計模型,從訓練好的神經模型開始,使用基于短語模型的其它反向翻譯句子對其進行訓練,最終得到了一個既流暢,準確率又高的模型。
對于無監督機器翻譯,微軟亞洲研究院自然語言計算組也進行了探索。研究人員利用后驗正則(Posterior Regularization)的方式將SMT(統計機器翻譯)引入到無監督NMT的訓練過程中,并通過EM過程交替優化SMT和NMT模型,使得無監督NMT迭代過程中的噪音能夠被有效去除,同時NMT模型也彌補了SMT模型在句子流暢性方面的不足。相關論文《Unsupervised Neural Machine Translation with SMT as Posterior Regularization》已被AAAI 2019接收。
感謝微軟亞洲研究院自然語言計算組研究員葛濤對本文提供的幫助。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101167 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14945 -
nlp
+關注
關注
1文章
489瀏覽量
22107
原文標題:請收下這份NLP熱門詞匯解讀
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MOS管的三個二級效應
探索并行領域—并行設計行業的三個實例介紹
NLP的介紹和如何利用機器學習進行NLP以及三種NLP技術的詳細介紹

最先進的NLP模型很脆弱!最先進的NLP模型是虛假的!
Richard Socher:NLP領域的發展要過三座大山
隨著人工智能的發展 即將出現這三個熱門職業
介紹三個NLP領域的熱門詞匯
華為三個全新商標對應不同領域
NLP 2019 Highlights 給NLP從業者的一個參考
詞匯知識融合可能是NLP任務的永恒話題





 工商網監
工商網監
評論