 一種通過編程方式生成訓練數據的“弱監督”范式
一種通過編程方式生成訓練數據的“弱監督”范式
手工標記大量數據始終是開發機器學習的一大瓶頸。斯坦福AI Lab的研究人員探討了一種通過編程方式生成訓練數據的“弱監督”范式,并介紹了他們的開源Snorkel框架。
近年來,機器學習(ML)對現實世界的影響越來越大。這在很大程度上是由于深度學習模型的出現,使得從業者可以在基準數據集上獲得state-of-the-art的分數,而無需任何手工特征設計。考慮到諸如TensorFlow和PyTorch等多種開源ML框架的可用性,以及大量可用的最先進的模型,可以說,高質量的ML模型現在幾乎成為一種商品化資源了。然而,有一個隱藏的問題:這些模型依賴于大量手工標記的訓練數據。
這些手工標記的訓練集創建起來既昂貴又耗時——通常需要幾個月甚至幾年的時間、花費大量人力來收集、清理和調試——尤其是在需要領域專業知識的情況下。除此之外,任務經常會在現實世界中發生變化和演變。例如,標記指南、粒度或下游用例都經常發生變化,需要重新標記(例如,不要只將評論分類為正面或負面,還要引入一個中性類別)。
由于這些原因,從業者越來越多地轉向一種較弱的監管形式,例如利用外部知識庫、模式/規則或其他分類器啟發式地生成訓練數據。從本質上來講,這些都是以編程方式生成訓練數據的方法,或者更簡潔地說,編程訓練數據(programming training data)。
在本文中,我們首先回顧了ML中由標記訓練數據驅動的一些領域,然后描述了我們對建模和整合各種監督源的研究。我們還討論了為大規模多任務機制構建數據管理系統的設想,這種系統使用數十或數百個弱監督的動態任務,以復雜、多樣的方式交互。
回顧:如何獲得更多有標簽的訓練數據?
ML中的許多傳統研究方法也同樣受到對標記訓練數據的需求的推動。我們首先將這些方法與弱監督方法(weak supervision)區分開來:弱監督是利用來自主題領域專家(subject matter experts,簡稱SME)的更高級別和/或更嘈雜的輸入。
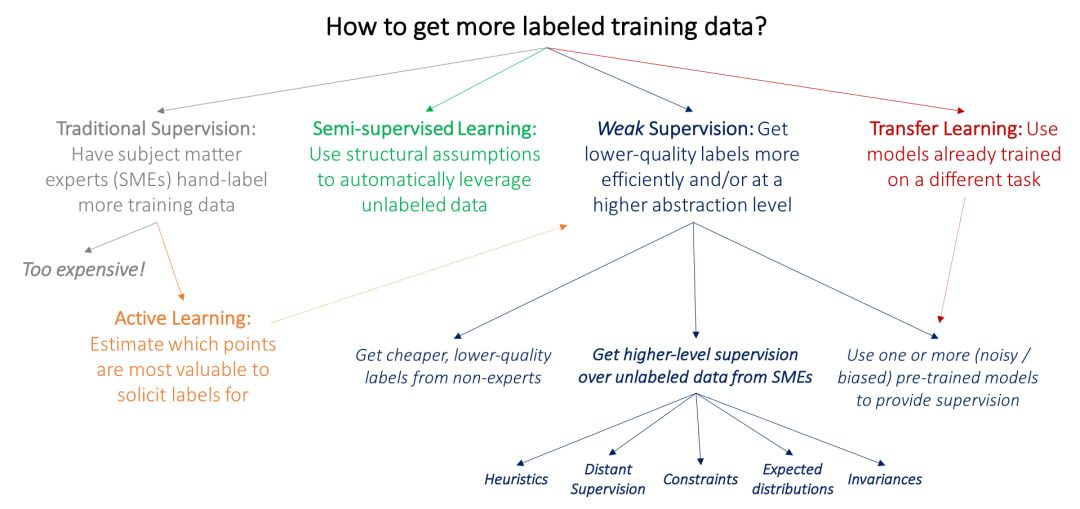
目前主流方法的一個關鍵問題是,由領域專家直接給大量數據加標簽是很昂貴的:例如,為醫學成像研究構建大型數據集更加困難,因為跟研究生不同,放射科醫生可不會接受一點小恩小惠就愿意為你標記數據。因此,在ML中,許多經過深入研究的工作線都是由于獲取標記訓練數據的瓶頸所致:
在主動學習(active learning)中,目標是讓領域專家為估計對模型最有價值的數據點貼標簽,從而更有效地利用領域專家。在標準的監督學習設置中,這意味著選擇要標記的新數據點。例如,我們可以選擇靠近當前模型決策邊界的乳房X線照片,并要求放射科醫生僅給這些照片進行標記。但是,我們也可以只要求對這些數據點進行較弱的監督,在這種情況下,主動學習與弱監督是完美互補的;這方面的例子可以參考(Druck, settle, and McCallum 2009)。
在半監督學習(semi-supervised learning )設置中,我們的目標是用一個小的標記訓練集和一個更大的未標記數據集。然后使用關于平滑度、低維結構或距離度量的假設來利用未標記數據(作為生成模型的一部分,或作為一個判別模型的正則項,或學習一個緊湊的數據表示);參考閱讀見(Chapelle, Scholkopf, and Zien 2009)。從廣義上講,半監督學習的理念不是從SME那里尋求更多輸入,而是利用領域和任務不可知的假設來利用未經標記的數據,而這些數據通常可以以低成本大量獲得。最近的方法使用生成對抗網絡(Salimans et al. 2016)、啟發式轉換模型(Laine and Aila 2016)和其他生成方法來有效地幫助規范化決策邊界。
在典型的遷移學習(transfer learning )設置中,目標是將一個或多個已經在不同數據集上訓練過的模型應用于我們的數據集和任務;相關的綜述見(Pan和Yang 2010)。例如,我們可能已經有身體其他部位腫瘤的大型訓練集,并在此基礎上訓練了分類器,然后希望將其應用到我們的乳房X光檢查任務中。在當今的深度學習社區中,一種常見的遷移學習方法是在一個大數據集上對模型進行“預訓練”,然后在感興趣的任務上對其進行“微調”。另一個相關的領域是多任務學習(multi-task learning),其中幾個任務是共同學習的(Caruna 1993; Augenstein, Vlachos, and Maynard 2015)。
上述范例可能讓我們得以不用向領域專家合作者尋求額外的訓練標簽。然而,對某些數據進行標記是不可避免的。如果我們要求他們提供各種類型的更高級、或不那么精確的監督形式,這些形式可以更快、更簡便地獲取,會怎么樣呢?例如,如果我們的放射科醫生可以花一個下午的時間來標記一組啟發式的資源或其他資源,如果處理得當,這些資源可以有效地替代成千上萬的訓練標簽,那會怎么樣呢?
將領域知識注入AI
從歷史的角度來看,試圖“編程”人工智能(即注入領域知識)并不是什么新鮮想法,但現在提出這個問題的主要新穎之處在于,AI從未像現在這樣強大,同時在可解釋性和可控制性方面,它還是一個“黑盒”。
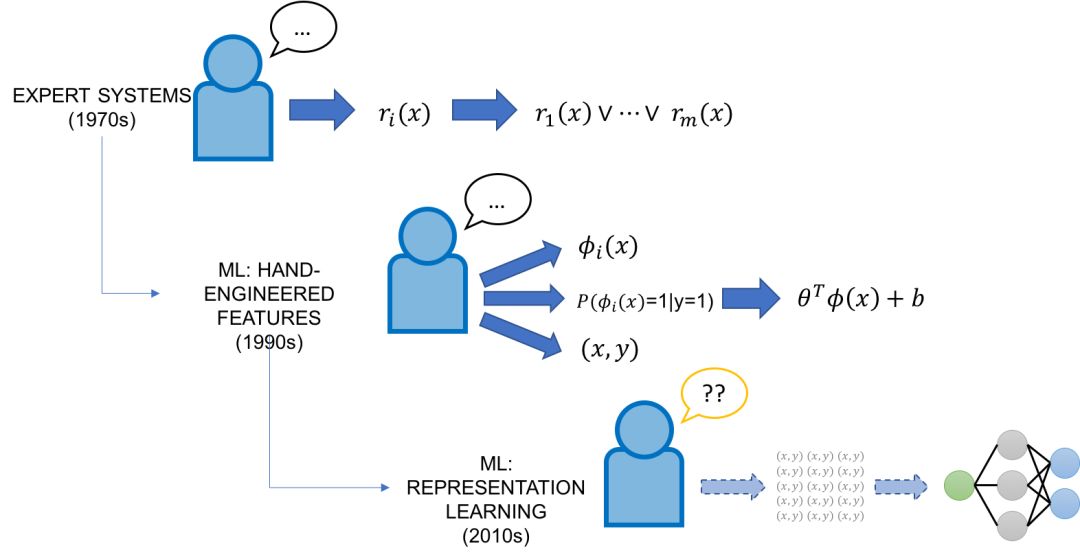
在20世紀70年代和80年代,AI的重點是專家系統,它將來自領域專家的手工策劃的事實和規則的知識庫結合起來,并使用推理引擎來應用它們。20世紀90年代,ML開始作為將知識集成到AI系統的工具獲得成功,并承諾以強大而靈活的方式從標記的訓練數據自動實現這一點。
經典的(非表示學習)ML方法通常有兩個領域專家輸入端口。首先,這些模型通常比現代模型的復雜度要低得多,這意味著可以使用更少的手工標記數據。其次,這些模型依賴于手工設計的特性,這些特性為編碼、修改和與模型的數據基本表示形式交互提供了一種直接的方法。然而,特性工程不管在過去還是現在通常都被認為是ML專家的任務,他們通常會花費整個博士生涯來為特定的任務設計特性。
進入深度學習模型:由于它們具有跨許多領域和任務自動學習表示的強大能力,它們在很大程度上避免了特性工程的任務。然而,它們大部分是完整的黑盒子,除了標記大量的訓練集和調整網絡架構外,普通開發人員對它們幾乎沒有控制權。在許多意義上,它們代表了舊的專家系統脆弱但易于控制的規則的對立面——它們靈活但難以控制。
這使我們從一個略微不同的角度回到了最初的問題:我們如何利用我們的領域知識或任務專業知識來編寫現代深度學習模型?有沒有辦法將舊的基于規則的專家系統的直接性與這些現代ML方法的靈活性和強大功能結合起來?
代碼作為監督:通過編程訓練ML
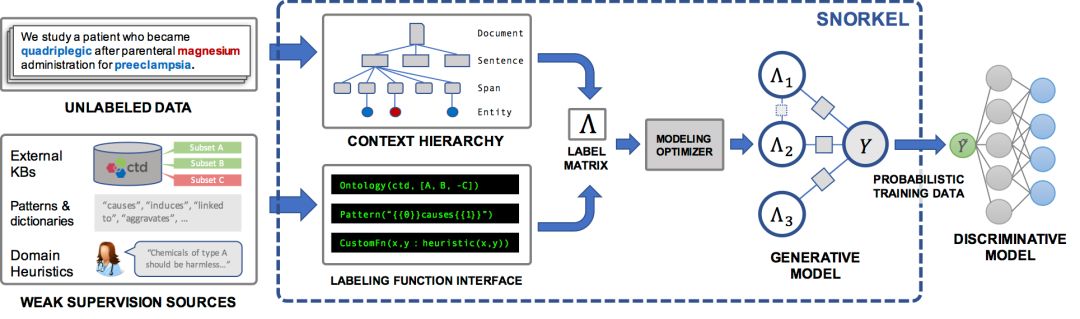
Snorkel是我們為支持和探索這種與ML的新型交互而構建的一個系統。在Snorkel中,我們不使用手工標記的訓練數據,而是要求用戶編寫標記函數(labeling functions, LF),即用于標記未標記數據子集的黑盒代碼片段。
然后,我們可以使用一組這樣的LF來為ML模型標記訓練數據。因為標記函數只是任意的代碼片段,所以它們可以對任意信號進行編碼:模式、啟發式、外部數據資源、來自群眾工作者的嘈雜標簽、弱分類器等等。而且,作為代碼,我們可以獲得所有其他相關的好處,比如模塊化、可重用性和可調試性。例如,如果我們的建模目標發生了變化,我們可以調整標記函數來快速適應!
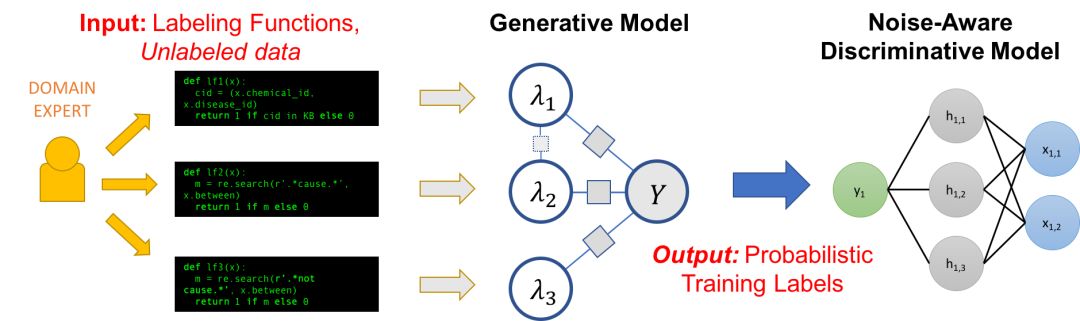
一個問題是,標記函數會產生有噪聲的輸出,這些輸出可能會重疊和沖突,從而產生不太理想的訓練標簽。在Snorkel中,我們使用數據編程方法對這些標簽進行去噪,該方法包括三個步驟:
1.我們將標記函數應用于未標記的數據。
2.我們使用一個生成模型來在沒有任何標記數據的條件下學習標記函數的準確性,并相應地對它們的輸出進行加權。我們甚至可以自動學習它們的關聯結構。
3.生成模型輸出一組概率訓練標簽,我們可以使用這些標簽來訓練一個強大、靈活的判別模型(如深度神經網絡),它將泛化到標記函數表示的信號之外。
可以認為,這整個pipeline為“編程”ML模型提供了一種簡單、穩健且與模型無關的方法!
標記函數(Labeling Functions)
從生物醫學文獻中提取結構化信息是最能激勵我們的應用之一:大量有用的信息被有效地鎖在數百萬篇科學論文的密集非結構化文本中。我們希望用機器學習來提取這些信息,進而使用這些信息來診斷遺傳性疾病。
考慮這樣一個任務:從科學文獻中提取某種化學-疾病的關系。我們可能沒有足夠大的標記訓練數據集來完成這項任務。然而,在生物醫學領域,存在著豐富的知識本體、詞典等資源,其中包括各種化學與疾病名稱數據、各種類型的已知化學-疾病關系數據庫等,我們可以利用這些資源來為我們的任務提供弱監督。此外,我們還可以與生物學領域的合作者一起提出一系列特定于任務的啟發式、正則表達式模式、經驗法則和負標簽生成策略。

作為一種表示載體的生成模型
在我們的方法中,我們認為標記函數隱含地描述了一個生成模型。讓我們來快速復習一下:給定數據點x,以及我們想要預測的未知標簽y,在判別方法中,我們直接對P(y|x)建模,而在生成方法中,我們對P(x,y) = P(x|y)P(y)建模。在我們的例子中,我們建模一個訓練集標記的過程P(L,y),其中L是由對象x的標記函數生成的標簽,y是對應的(未知的)真實標簽。通過學習生成模型,并直接估計P(L|y),我們本質上是在根據它們如何重疊和沖突來學習標記函數的相對準確性(注意,我們不需要知道y!)
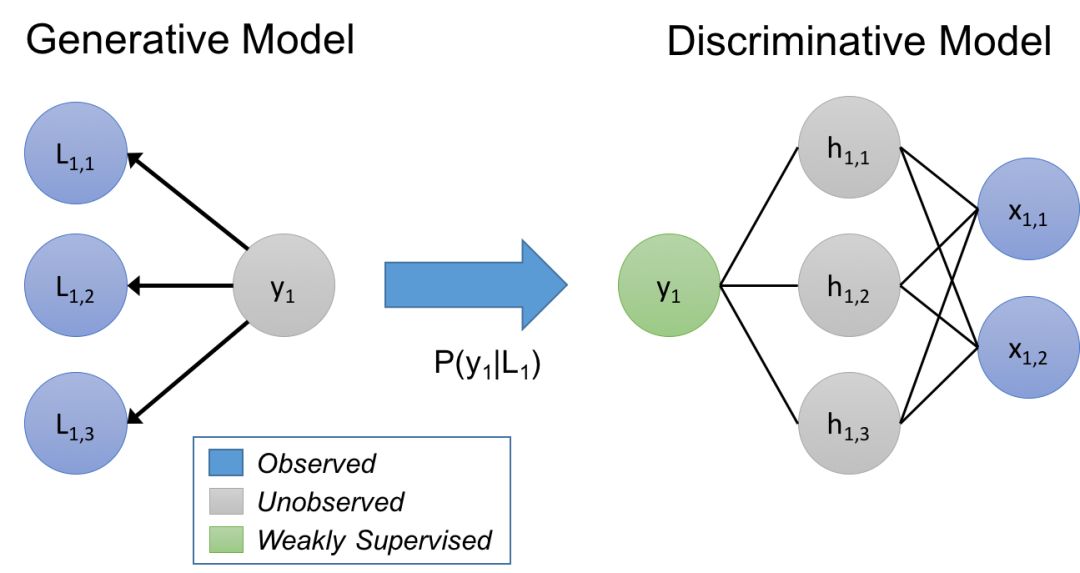
我們使用這個估計的生成模型在標簽函數上訓練一個噪聲感知版本的最終判別模型。為了做到這一點,生成模型推斷出訓練數據的未知標簽的概率,然后我們最小化關于這些概率的判別模型的預期損失。
估計這些生成模型的參數可能非常棘手,特別是當使用的標記函數之間存在統計依賴性時。在Data Programming: Creating Large Training Sets, Quickly(https://arxiv.org/abs/1605.07723)這篇論文中,我們證明了給定足夠的標記函數的條件下,可以得到與監督方法相同的asymptotic scaling。我們還研究了如何在不使用標記數據的情況下學習標記函數之間的相關性,以及如何顯著提高性能。
Snorkel:一個開源的框架
在我們最近發表的關于Snorkel的論文(https://arxiv.org/abs/1711.10160)中,我們發現在各種實際應用中,這種與現代ML模型交互的新方法非常有效!包括:
1.在一個關于Snorkel的研討會上,我們進行了一項用戶研究,比較了教SMEs使用Snorkel的效率,以及花同樣的時間進行純手工標記數據的效率。我們發現,使用Snorkel構建模型不僅快了2.8倍,而且平均預測性能也提高了45.5%。
2.在與斯坦福大學、美國退伍軍人事務部和美國食品和藥物管理局的研究人員合作的兩個真實的文本關系提取任務,以及其他四個基準文本和圖像任務中,我們發現,與baseline技術相比,Snorkel平均提高了132%。
3.我們探索了如何對用戶提供的標記函數建模的新的權衡空間,從而得到了一個基于規則的優化器,用于加速迭代開發周期。
下一步:大規模多任務弱監管
我們實驗室正在進行各種努力,將Snorkel設想的弱監督交互模型擴展到其他模式,如格式豐富的數據和圖像、使用自然語言的監督任務和自動生成標簽函數!
在技術方面,我們感興趣的是擴展Snorkel的核心數據編程模型,使其更容易指定具有更高級別接口(如自然語言)的標記函數,以及結合其他類型的弱監督(如數據增強)。
多任務學習(MTL)場景的普及也引發了這樣一個問題:當嘈雜的、可能相關的標簽源現在要標記多個相關任務時會發生什么?我們是否可以通過對這些任務進行聯合建模來獲益?我們在一個新的多任務感知版本的Snorkel,即Snorkel MeTaL中解決了這些問題,它可以支持多任務弱監管源,為一個或多個相關任務提供噪聲標簽。
我們考慮的一個例子是設置具有不同粒度的標簽源。例如,假設我們打算訓練一個細粒度的命名實體識別(NER)模型來標記特定類型的人和位置,并且我們有一些細粒度的嘈雜標簽,例如標記“律師”與“醫生”,或“銀行”與“醫院”;以及有些是粗粒度的,例如標記“人”與“地點”。通過將這些資源表示為標記不同層次相關的任務,我們可以聯合建模它們的準確性,并重新加權和組合它們的多任務標簽,從而創建更清晰、智能聚合的多任務訓練數據,從而提高最終MTL模型的性能。
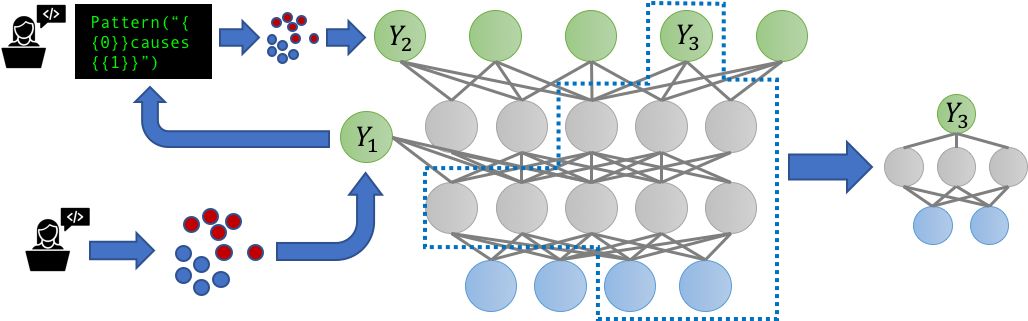
我們相信,為MTL構建數據管理系統最激動人心的方面將圍繞大規模多任務機制(massivelymulti-task regime),在這種機制中,數十到數百個弱監督(因而高度動態)的任務以復雜、多樣的方式交互。
雖然迄今為止大多數MTL工作都考慮最多處理由靜態手工標記訓練集定義的少數幾項任務,但世界正在迅速發展成組織(無論是大公司、學術實驗室還是在線社區)都要維護數以百計的弱監督、快速變化且相互依賴的建模任務。此外,由于這些任務是弱監督的,開發人員可以在數小時或數天內(而不是數月或數年)添加、刪除或更改任務(即訓練集),這可能需要重新訓練整個模型。
在最近的一篇論文The Role of Massively Multi-Task and Weak Supervision in Software 2.0 (http://cidrdb.org/cidr2019/papers/p58-ratner-cidr19.pdf)中,我們概述了針對上述問題的一些初步想法,設想了一個大規模的多任務設置,其中MTL模型有效地用作一個訓練由不同開發人員弱標記的數據的中央存儲庫,然后組合在一個中央“mother”多任務模型中。
不管確切的形式因素是什么,很明顯,MTL技術在未來有許多令人興奮的進展——不僅是新的模型架構,而且還與遷移學習方法、新的弱監督方法、新的軟件開發和系統范例日益統一。
-
AI
+關注
關注
87文章
31523瀏覽量
270339 -
機器學習
+關注
關注
66文章
8439瀏覽量
133087 -
數據集
+關注
關注
4文章
1209瀏覽量
24834
原文標題:放棄手工標記數據,斯坦福大學開發弱監督編程范式Snorkel
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是編程范式?常見的編程范式有哪些?各大編程范式詳解
LabVIEW圖形化編程語言的編程范式
請問怎么設計一種弱信號處理模塊測試系統?
一種同步通訊板的網絡電路碼表的生成
一種基于監督機制的工業物聯網安全數據融合方法
一種新的DEA公共權重生成方法
實現強監督和弱監督學習網絡的協同增強學習

一種十億級數據規模的半監督圖像分類模型
深度學習:基于語境的文本分類弱監督學習
無監督的多跳問答的可能性研究


一種基于改進的DCGAN生成SAR圖像的方法






 工商網監
工商網監
評論