 谷歌、DeepMind重磅推出PlaNet 強化學習新突破
谷歌、DeepMind重磅推出PlaNet 強化學習新突破
Google AI 與 DeepMind 合作推出深度規劃網絡 (PlaNet),這是一個純粹基于模型的智能體,能從圖像輸入中學習世界模型,完成多項規劃任務,數據效率平均提升50倍,強化學習又一突破。
通過強化學習 (RL),對 AI 智能體如何隨著時間的推移提高決策能力的研究進展迅速。
對于強化學習,智能體在選擇動作 (例如,運動命令) 時會觀察一系列感官輸入(例如,相機圖像),并且有時會因為達成指定目標而獲得獎勵。
RL 的無模型方法 (Model-free) 旨在通過感官觀察直接預測良好的行為,這種方法使 DeepMind 的 DQN 能夠玩雅達利游戲,使其他智能體能夠控制機器人。
然而,這是一種黑盒方法,通常需要經過數周的模擬交互才能通過反復試驗來學習,這限制了它在實踐中的有效性。
相反,基于模型的 RL 方法 (Model-basedRL) 試圖讓智能體了解整個世界的行為。這種方法不是直接將觀察結果映射到行動,而是允許 agent 明確地提前計劃,通過 “想象” 其長期結果來更仔細地選擇行動。
Model-based 的方法已經取得了巨大的成功,包括 AlphaGo,它設想在已知游戲規則的虛擬棋盤上進行一系列的移動。然而,要在未知環境中利用規劃(例如僅將像素作為輸入來控制機器人),智能體必須從經驗中學習規則或動態。
由于這種動態模型原則上允許更高的效率和自然的多任務學習,因此創建足夠精確的模型以成功地進行規劃是 RL 的長期目標。
為了推動這項研究挑戰的進展,Google AI 與 DeepMind 合作,提出了深度規劃網絡 (Deep Planning Network, PlaNet),該智能體僅從圖像輸入中學習世界模型 (world model),并成功地利用它進行規劃。
PlaNet 解決了各種基于圖像的控制任務,在最終性能上可與先進的 model-free agent 競爭,同時平均數據效率提高了 5000%。研究團隊將發布源代碼供研究社區使用。
在 2000 次的嘗試中,PlaNet 智能體學習解決了各種連續控制任務。以前的沒有學習環境模型的智能體通常需要多 50 倍的嘗試次數才能達到類似的性能。
PlaNet 的工作原理
簡而言之,PlaNet 學習了給定圖像輸入的動態模型 (dynamics model),并有效地利用該模型進行規劃,以收集新的經驗。
與以前的圖像規劃方法不同,我們依賴于隱藏狀態或潛在狀態的緊湊序列。這被稱為latent dynamics model:我們不是直接從一個圖像到下一個圖像地預測,而是預測未來的潛在狀態。然后從相應的潛在狀態生成每一步的圖像和獎勵。
通過這種方式壓縮圖像,agent 可以自動學習更抽象的表示,例如對象的位置和速度,這樣就可以更容易地向前預測,而不需要沿途生成圖像。
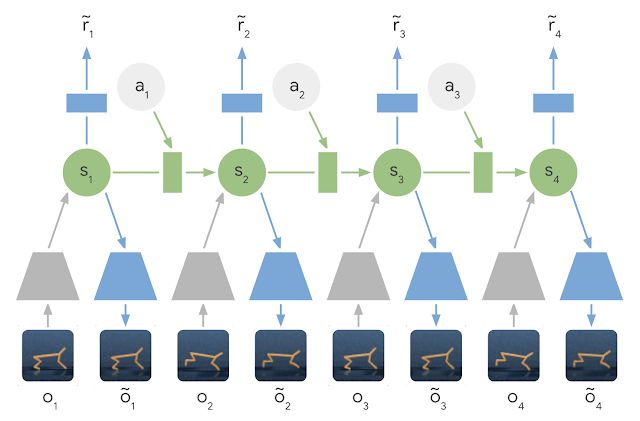
Learned Latent Dynamics Model:在 latent dynamics 模型中,利用編碼器網絡(灰色梯形) 將輸入圖像的信息集成到隱藏狀態(綠色) 中。然后將隱藏狀態向前投影,以預測未來的圖像(藍色梯形) 和獎勵(藍色矩形)。
為了學習一個精確的 latent dynamics 模型,我們提出了:
循環狀態空間模型 (Recurrent State Space Model):一種具有確定性和隨機性成分的 latent dynamics 模型,允許根據魯棒規劃的需要預測各種可能的未來,同時記住多個時間步長的信息。我們的實驗表明這兩個組件對于提高規劃性能是至關重要的。
潛在超調目標 (Latent Overshooting Objective):我們通過在潛在空間中強制 one-step 和 multi-step 預測之間的一致性,將 latent dynamics 模型的標準訓練目標推廣到訓練多步預測。這產生了一個快速和有效的目標,可以改善長期預測,并與任何潛在序列模型兼容。
雖然預測未來的圖像允許我們教授模型,但編碼和解碼圖像 (上圖中的梯形) 需要大量的計算,這會減慢智能體的 planning 過程。然而,在緊湊的潛在狀態空間中進行 planning 是很快的,因為我們只需要預測未來的 rewards 來評估一個動作序列,而不是預測圖像。
例如,智能體可以想象球的位置和它到目標的距離在特定的動作中將如何變化,而不需要可視化場景。這允許我們在每次智能體選擇一個動作時,將 10000 個想象的動作序列與一個大的 batch size 進行比較。然后執行找到的最佳序列的第一個動作,并在下一步重新規劃。
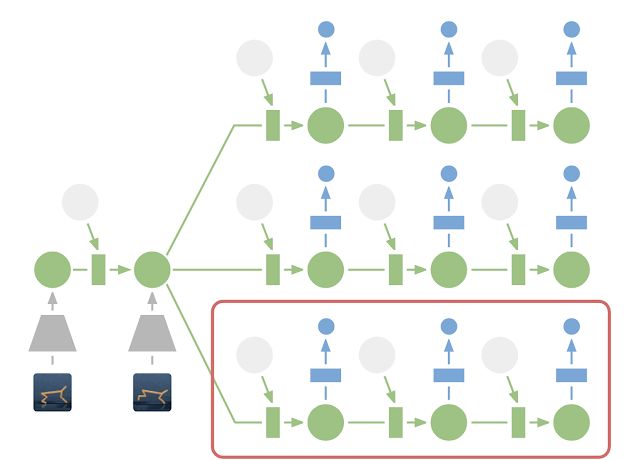
在潛在空間中進行規劃:為了進行規劃,我們將過去的圖像 (灰色梯形) 編碼為當前的隱藏狀態 (綠色)。這樣,我們可以有效地預測多個動作序列的未來獎勵。請注意,上圖中昂貴的圖像解碼器 (藍色梯形) 已經消失了。然后,執行找到的最佳序列的第一個操作 (紅色框)。
與我們之前關于世界模型的工作 (https://worldmodels.github.io/) 相比,PlaNet 在沒有策略網絡的情況下工作 —— 它純粹通過 planning 來選擇行動,因此它可以從模型當下的改進中獲益。有關技術細節,請參閱我們的研究論文。
PlaNet vs. Model-Free 方法
我們在連續控制任務上評估了 PlaNet。智能體只被輸入圖像觀察和獎勵。我們考慮了具有各種不同挑戰的任務:
側手翻任務:帶有一個固定的攝像頭,這樣推車可以移動到視線之外。因此,智能體必須吸收并記住多個幀的信息。
手指旋轉任務:需要預測兩個單獨的對象,以及它們之間的交互。
獵豹跑步任務:包括難以準確預測的地面接觸,要求模型預測多個可能的未來。
杯子接球任務:它只在球被接住時提供一個稀疏的獎勵信號。這要求準確預測很遠的未來,并規劃一個精確的動作序列。
走路任務:模擬機器人一開始是躺在地上,然后它必須先學會站立,再學習行走。
PlaNet 智能體接受了各種基于圖像的控制任務的訓練。動圖顯示了當智能體解決任務時輸入的圖像。這些任務提出了不同的挑戰:部分可觀察性、與地面的接觸、接球的稀疏獎勵,以及控制一個具有挑戰性的雙足機器人。
這一研究是第一個使用學習模型進行規劃,并在基于圖像的任務上優于 model-free 方法的案例。
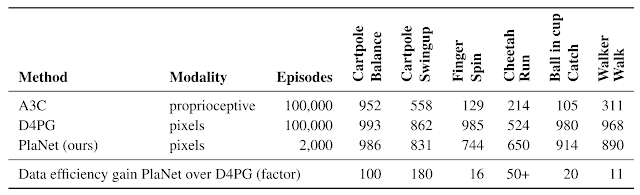
下表將PlaNet與著名的A3C 智能體和 D4PG 智能體進行了比較,后者結合了 model-free RL 的最新進展。這些基線數據來自 DeepMind 控制套件。PlaNet 在所有任務上都明顯優于 A3C,最終性能接近 D4PG,同時與環境的交互平均減少了 5000%。
所有任務只需要一個智能體
此外,我們只訓練了一個單一的 PlaNet 智能體來解決所有六個任務。
在不知道任務的情況下,智能體被隨機放置在不同的環境中,因此它需要通過觀察圖像來推斷任務。
在不改變超參數的情況下,多任務智能體實現了與單個智能體相同的平均性能。雖然在側手翻任務中學習速度較慢,但在需要探索的具有挑戰性的步行任務中,它的學習速度要快得多,最終表現也更好。
在多個任務上訓練的 PlaNet 智能體。智能體觀察前 5 個幀作為上下文以推斷任務和狀態,并在給定動作序列的情況下提前準確地預測 50 個步驟。
結論
我們的結果展示了構建自主 RL 智能體的學習動態模型的前景。我們鼓勵進一步的研究,集中在學習更困難的任務的精確動態模型,如三維環境和真實的機器人任務。擴大規模的一個可能因素是 TPU 的處理能力。我們對 model-based 強化學習帶來的可能性感到興奮,包括多任務學習、分層規劃和使用不確定性估計的主動探索。
-
谷歌
+關注
關注
27文章
6194瀏覽量
106016 -
強化學習
+關注
關注
4文章
268瀏覽量
11301 -
DeepMind
+關注
關注
0文章
131瀏覽量
10939
原文標題:一個智能體打天下:谷歌、DeepMind重磅推出PlaNet,數據效率提升50倍
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
谷歌加速AI部門整合:AI Studio團隊并入DeepMind
OpenAI從谷歌DeepMind挖角三名高級工程師
螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
如何使用 PyTorch 進行強化學習
AI實火!諾貝爾又把化學獎頒給AI大模型
谷歌AlphaChip強化學習工具發布,聯發科天璣芯片率先采用
谷歌DeepMind被曝抄襲開源成果,論文還中了頂流會議

通過強化學習策略進行特征選擇

谷歌提出大規模ICL方法
谷歌DeepMind發布人工智能模型AlphaFold最新版本
谷歌DeepMind推出新一代藥物研發AI模型AlphaFold 3
谷歌DeepMind推出SIMI通用AI智能體
谷歌模型軟件有哪些功能






 工商網監
工商網監
評論