") 為何說Bert是近年來NLP重大進展的集大成者?
為何說Bert是近年來NLP重大進展的集大成者?
作者簡介:張俊林,中國中文信息學(xué)會理事,目前在新浪微博 AI Lab 擔(dān)任資深算法專家。在此之前,張俊林曾經(jīng)在阿里巴巴任資深技術(shù)專家,以及在百度和用友擔(dān)任技術(shù)經(jīng)理及技術(shù)總監(jiān)等職務(wù)。同時他是技術(shù)書籍《這就是搜索引擎:核心技術(shù)詳解》(該書榮獲全國第十二屆輸出版優(yōu)秀圖書獎)、《大數(shù)據(jù)日知錄:架構(gòu)與算法》的作者。
Bert 最近很火,應(yīng)該是最近最火爆的 AI 進展,網(wǎng)上的評價很高,那么 Bert 值得這么高的評價嗎?我個人判斷是值得。那為什么會有這么高的評價呢?是因為它有重大的理論或者模型創(chuàng)新嗎?其實并沒有,從模型創(chuàng)新角度看一般,創(chuàng)新不算大。但是架不住效果太好了,基本刷新了很多 NLP 的任務(wù)的最好性能,有些任務(wù)還被刷爆了,這個才是關(guān)鍵。另外一點是 Bert 具備廣泛的通用性,就是說絕大部分 NLP 任務(wù)都可以采用類似的兩階段模式直接去提升效果,這個第二關(guān)鍵。客觀的說,把 Bert 當(dāng)做最近兩年 NLP 重大進展的集大成者更符合事實。
本文的主題是自然語言處理中的預(yù)訓(xùn)練過程,會大致說下 NLP 中的預(yù)訓(xùn)練技術(shù)是一步一步如何發(fā)展到 Bert 模型的,從中可以很自然地看到 Bert 的思路是如何逐漸形成的,Bert 的歷史沿革是什么,繼承了什么,創(chuàng)新了什么,為什么效果那么好,主要原因是什么,以及為何說模型創(chuàng)新不算太大,為何說 Bert 是近年來 NLP 重大進展的集大成者。
我們一步一步來講,而串起來這個故事的脈絡(luò)就是自然語言的預(yù)訓(xùn)練過程,但是落腳點還是在 Bert 身上。要講自然語言的預(yù)訓(xùn)練,得先從圖像領(lǐng)域的預(yù)訓(xùn)練說起。
▌圖像領(lǐng)域的預(yù)訓(xùn)練
自從深度學(xué)習(xí)火起來后,預(yù)訓(xùn)練過程就是做圖像或者視頻領(lǐng)域的一種比較常規(guī)的做法,有比較長的歷史了,而且這種做法很有效,能明顯促進應(yīng)用的效果。
那么圖像領(lǐng)域怎么做預(yù)訓(xùn)練呢,上圖展示了這個過程,我們設(shè)計好網(wǎng)絡(luò)結(jié)構(gòu)以后,對于圖像來說一般是 CNN 的多層疊加網(wǎng)絡(luò)結(jié)構(gòu),可以先用某個訓(xùn)練集合比如訓(xùn)練集合 A 或者訓(xùn)練集合 B 對這個網(wǎng)絡(luò)進行預(yù)先訓(xùn)練,在 A 任務(wù)上或者B任務(wù)上學(xué)會網(wǎng)絡(luò)參數(shù),然后存起來以備后用。
假設(shè)我們面臨第三個任務(wù) C,網(wǎng)絡(luò)結(jié)構(gòu)采取相同的網(wǎng)絡(luò)結(jié)構(gòu),在比較淺的幾層 CNN 結(jié)構(gòu),網(wǎng)絡(luò)參數(shù)初始化的時候可以加載 A 任務(wù)或者 B 任務(wù)學(xué)習(xí)好的參數(shù),其它 CNN 高層參數(shù)仍然隨機初始化。之后我們用 C 任務(wù)的訓(xùn)練數(shù)據(jù)來訓(xùn)練網(wǎng)絡(luò),此時有兩種做法,一種是淺層加載的參數(shù)在訓(xùn)練 C 任務(wù)過程中不動,這種方法被稱為“Frozen”;另外一種是底層網(wǎng)絡(luò)參數(shù)盡管被初始化了,在 C 任務(wù)訓(xùn)練過程中仍然隨著訓(xùn)練的進程不斷改變,這種一般叫“Fine-Tuning”,顧名思義,就是更好地把參數(shù)進行調(diào)整使得更適應(yīng)當(dāng)前的 C 任務(wù)。一般圖像或者視頻領(lǐng)域要做預(yù)訓(xùn)練一般都這么做。
這么做有幾個好處,首先,如果手頭任務(wù) C 的訓(xùn)練集合數(shù)據(jù)量較少的話,現(xiàn)階段的好用的 CNN 比如 Resnet/Densenet/Inception 等網(wǎng)絡(luò)結(jié)構(gòu)層數(shù)很深,幾百萬上千萬參數(shù)量算起步價,上億參數(shù)的也很常見,訓(xùn)練數(shù)據(jù)少很難很好地訓(xùn)練這么復(fù)雜的網(wǎng)絡(luò),但是如果其中大量參數(shù)通過大的訓(xùn)練集合比如 ImageNet 預(yù)先訓(xùn)練好直接拿來初始化大部分網(wǎng)絡(luò)結(jié)構(gòu)參數(shù),然后再用 C 任務(wù)手頭比較可憐的數(shù)據(jù)量上 Fine-tuning 過程去調(diào)整參數(shù)讓它們更適合解決 C 任務(wù),那事情就好辦多了。
這樣原先訓(xùn)練不了的任務(wù)就能解決了,即使手頭任務(wù)訓(xùn)練數(shù)據(jù)也不少,加個預(yù)訓(xùn)練過程也能極大加快任務(wù)訓(xùn)練的收斂速度,所以這種預(yù)訓(xùn)練方式是老少皆宜的解決方案,另外療效又好,所以在做圖像處理領(lǐng)域很快就流行開來。
那么新的問題來了,為什么這種預(yù)訓(xùn)練的思路是可行的?
目前我們已經(jīng)知道,對于層級的 CNN 結(jié)構(gòu)來說,不同層級的神經(jīng)元學(xué)習(xí)到了不同類型的圖像特征,由底向上特征形成層級結(jié)構(gòu),如上圖所示,如果我們手頭是個人臉識別任務(wù),訓(xùn)練好網(wǎng)絡(luò)后,把每層神經(jīng)元學(xué)習(xí)到的特征可視化肉眼看一看每層學(xué)到了啥特征,你會看到最底層的神經(jīng)元學(xué)到的是線段等特征,圖示的第二個隱層學(xué)到的是人臉五官的輪廓,第三層學(xué)到的是人臉的輪廓,通過三步形成了特征的層級結(jié)構(gòu),越是底層的特征越是所有不論什么領(lǐng)域的圖像都會具備的比如邊角線弧線等底層基礎(chǔ)特征,越往上抽取出的特征越與手頭任務(wù)相關(guān)。
正因為此,所以預(yù)訓(xùn)練好的網(wǎng)絡(luò)參數(shù),尤其是底層的網(wǎng)絡(luò)參數(shù)抽取出特征跟具體任務(wù)越無關(guān),越具備任務(wù)的通用性,所以這是為何一般用底層預(yù)訓(xùn)練好的參數(shù)初始化新任務(wù)網(wǎng)絡(luò)參數(shù)的原因。而高層特征跟任務(wù)關(guān)聯(lián)較大,實際可以不用使用,或者采用 Fine-tuning 用新數(shù)據(jù)集合清洗掉高層無關(guān)的特征抽取器。
一般我們喜歡用 ImageNet 來做網(wǎng)絡(luò)的預(yù)訓(xùn)練,主要有兩點,一方面 ImageNet 是圖像領(lǐng)域里有超多事先標(biāo)注好訓(xùn)練數(shù)據(jù)的數(shù)據(jù)集合,分量足是個很大的優(yōu)勢,量越大訓(xùn)練出的參數(shù)越靠譜;另外一方面因為 ImageNet 有 1000 類,類別多,算是通用的圖像數(shù)據(jù),跟領(lǐng)域沒太大關(guān)系,所以通用性好,預(yù)訓(xùn)練完后哪哪都能用,是個萬金油。分量足的萬金油當(dāng)然老少通吃,人人喜愛。
聽完上述話,如果你是具備研究素質(zhì)的人,也就是說具備好奇心,你一定會問下面這個問題:“既然圖像領(lǐng)域預(yù)訓(xùn)練這么好用,那干嘛自然語言處理不做這個事情呢?是不是搞 NLP 的人比搞 CV 的傻啊?就算你傻,你看見人家這么做,有樣學(xué)樣不就行了嗎?這不就是創(chuàng)新嗎,也許能成,萬一成了,你看,你的成功來得就是這么突然!”
嗯,好問題,其實搞 NLP 的人一點都不比你傻,早就有人嘗試過了,不過總體而言不太成功而已。聽說過 word embedding 嗎?2003 年出品,陳年技術(shù),馥郁芳香。word embedding 其實就是 NLP 里的早期預(yù)訓(xùn)練技術(shù)。當(dāng)然也不能說 word embedding 不成功,一般加到下游任務(wù)里,都能有 1 到 2 個點的性能提升,只是沒有那么耀眼的成功而已。
沒聽過?那下面就把這段陳年老賬講給你聽聽。
▌Word Embedding 考古史
這塊大致講講 Word Embedding 的故事,很粗略,因為網(wǎng)上關(guān)于這個技術(shù)講的文章太多了,汗牛沖動,我不屬牛,此刻更沒有流汗,所以其實絲毫沒有想講 Word Embedding 的沖動和激情,但是要說預(yù)訓(xùn)練又得從這開始,那就粗略地講講,主要是引出后面更精彩的部分。在說 Word Embedding 之前,先更粗略地說下語言模型,因為一般 NLP 里面做預(yù)訓(xùn)練一般的選擇是用語言模型任務(wù)來做。
什么是語言模型?其實看上面這張 PPT 上扣下來的圖就明白了,為了能夠量化地衡量哪個句子更像一句人話,可以設(shè)計如上圖所示函數(shù),核心函數(shù) P 的思想是根據(jù)句子里面前面的一系列前導(dǎo)單詞預(yù)測后面跟哪個單詞的概率大小(理論上除了上文之外,也可以引入單詞的下文聯(lián)合起來預(yù)測單詞出現(xiàn)概率)。句子里面每個單詞都有個根據(jù)上文預(yù)測自己的過程,把所有這些單詞的產(chǎn)生概率乘起來,數(shù)值越大代表這越像一句人話。語言模型壓下暫且不表,我隱約預(yù)感到我這么講你可能還是不太會明白,但是大概這個意思,不懂的可以去網(wǎng)上找,資料多得一樣地汗牛沖動。
假設(shè)現(xiàn)在讓你設(shè)計一個神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),去做這個語言模型的任務(wù),就是說給你很多語料做這個事情,訓(xùn)練好一個神經(jīng)網(wǎng)絡(luò),訓(xùn)練好之后,以后輸入一句話的前面幾個單詞,要求這個網(wǎng)絡(luò)輸出后面緊跟的單詞應(yīng)該是哪個,你會怎么做?
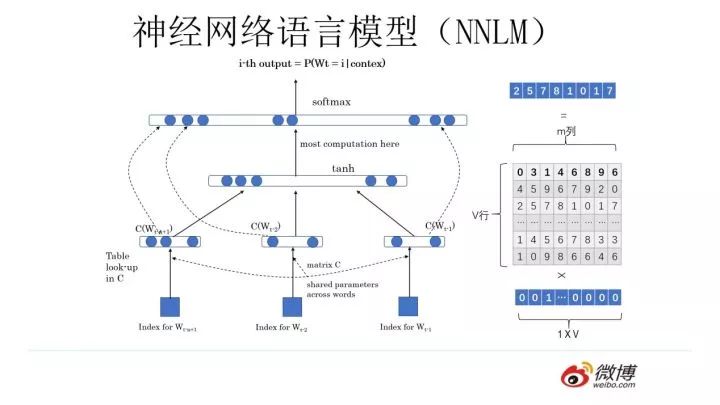
你可以像上圖這么設(shè)計這個網(wǎng)絡(luò)結(jié)構(gòu),這其實就是大名鼎鼎的中文人稱“神經(jīng)網(wǎng)絡(luò)語言模型”,英文小名 NNLM 的網(wǎng)絡(luò)結(jié)構(gòu),用來做語言模型。這個工作有年頭了,是個陳年老工作,是 Bengio 在 2003 年發(fā)表在 JMLR 上的論文。它生于 2003,火于 2013,以后是否會不朽暫且不知,但是不幸的是出生后應(yīng)該沒有引起太大反響,沉寂十年終于時來運轉(zhuǎn)沉冤得雪,在 2013 年又被 NLP 考古工作者從海底濕淋淋地?fù)瞥鰜砹思廊肷竦睢?/p>
為什么會發(fā)生這種技術(shù)奇遇記?你要想想 2013 年是什么年頭,是深度學(xué)習(xí)開始滲透 NLP 領(lǐng)域的光輝時刻,萬里長征第一步,而 NNLM 可以算是南昌起義第一槍。在深度學(xué)習(xí)火起來之前,極少有人用神經(jīng)網(wǎng)絡(luò)做 NLP 問題,如果你 10 年前堅持用神經(jīng)網(wǎng)絡(luò)做 NLP,估計別人會認(rèn)為你這人神經(jīng)有問題。所謂紅塵滾滾,誰也擋不住歷史發(fā)展趨勢的車輪,這就是個很好的例子。
上面是閑話,閑言碎語不要講,我們回來講一講 NNLM 的思路。先說訓(xùn)練過程,現(xiàn)在看其實很簡單,見過 RNN、LSTM、CNN后的你們回頭再看這個網(wǎng)絡(luò)甚至顯得有些簡陋。學(xué)習(xí)任務(wù)是輸入某個句中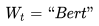 單詞前面句子的 t-1 個單詞,要求網(wǎng)絡(luò)正確預(yù)測單詞 Bert,即最大化:
單詞前面句子的 t-1 個單詞,要求網(wǎng)絡(luò)正確預(yù)測單詞 Bert,即最大化:
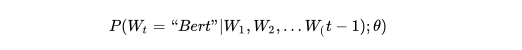
前面任意單詞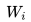 用Onehot編碼(比如:0001000)作為原始單詞輸入,之后乘以矩陣 Q 后獲得向量
用Onehot編碼(比如:0001000)作為原始單詞輸入,之后乘以矩陣 Q 后獲得向量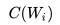 ,每個單詞的
,每個單詞的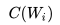 拼接,上接隱層,然后接 softmax 去預(yù)測后面應(yīng)該后續(xù)接哪個單詞。這個
拼接,上接隱層,然后接 softmax 去預(yù)測后面應(yīng)該后續(xù)接哪個單詞。這個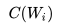 是什么?這其實就是單詞對應(yīng)的 Word Embedding 值,那個矩陣 Q 包含 V 行,V 代表詞典大小,每一行內(nèi)容代表對應(yīng)單詞的 Word embedding 值。只不過 Q 的內(nèi)容也是網(wǎng)絡(luò)參數(shù),需要學(xué)習(xí)獲得,訓(xùn)練剛開始用隨機值初始化矩陣 Q,當(dāng)這個網(wǎng)絡(luò)訓(xùn)練好之后,矩陣 Q 的內(nèi)容被正確賦值,每一行代表一個單詞對應(yīng)的 Word embedding 值。
是什么?這其實就是單詞對應(yīng)的 Word Embedding 值,那個矩陣 Q 包含 V 行,V 代表詞典大小,每一行內(nèi)容代表對應(yīng)單詞的 Word embedding 值。只不過 Q 的內(nèi)容也是網(wǎng)絡(luò)參數(shù),需要學(xué)習(xí)獲得,訓(xùn)練剛開始用隨機值初始化矩陣 Q,當(dāng)這個網(wǎng)絡(luò)訓(xùn)練好之后,矩陣 Q 的內(nèi)容被正確賦值,每一行代表一個單詞對應(yīng)的 Word embedding 值。
所以你看,通過這個網(wǎng)絡(luò)學(xué)習(xí)語言模型任務(wù),這個網(wǎng)絡(luò)不僅自己能夠根據(jù)上文預(yù)測后接單詞是什么,同時獲得一個副產(chǎn)品,就是那個矩陣 Q,這就是單詞的 Word Embedding 是被如何學(xué)會的。
2013 年最火的用語言模型做 Word Embedding 的工具是 Word2Vec,后來又出了 Glove,Word2Vec 是怎么工作的呢?看下圖。
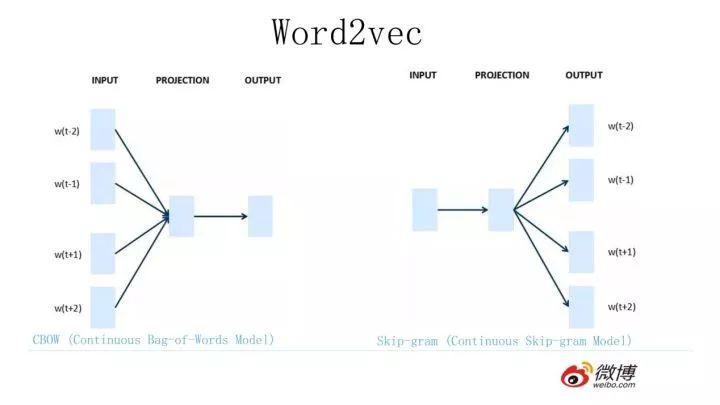
Word2Vec 的網(wǎng)絡(luò)結(jié)構(gòu)其實和 NNLM 是基本類似的,只是這個圖長得清晰度差了點,看上去不像,其實它們是親兄弟。不過這里需要指出:盡管網(wǎng)絡(luò)結(jié)構(gòu)相近,而且也是做語言模型任務(wù),但是其訓(xùn)練方法不太一樣。Word2Vec 有兩種訓(xùn)練方法,一種叫 CBOW,核心思想是從一個句子里面把一個詞摳掉,用這個詞的上文和下文去預(yù)測被摳掉的這個詞;第二種叫做 Skip-gram,和 CBOW 正好反過來,輸入某個單詞,要求網(wǎng)絡(luò)預(yù)測它的上下文單詞。
而你回頭看看,NNLM 是怎么訓(xùn)練的?是輸入一個單詞的上文,去預(yù)測這個單詞。這是有顯著差異的。為什么 Word2Vec 這么處理?原因很簡單,因為 Word2Vec 和 NNLM 不一樣,NNLM 的主要任務(wù)是要學(xué)習(xí)一個解決語言模型任務(wù)的網(wǎng)絡(luò)結(jié)構(gòu),語言模型就是要看到上文預(yù)測下文,而 word embedding 只是無心插柳的一個副產(chǎn)品。但是 Word2Vec 目標(biāo)不一樣,它單純就是要 word embedding 的,這是主產(chǎn)品,所以它完全可以隨性地這么去訓(xùn)練網(wǎng)絡(luò)。
為什么要講 Word2Vec 呢?這里主要是要引出 CBOW 的訓(xùn)練方法,BERT 其實跟它有關(guān)系,后面會講它們之間是如何的關(guān)系,當(dāng)然它們的關(guān)系 BERT 作者沒說,是我猜的,至于我猜的對不對,后面你看后自己判斷。

使用 Word2Vec 或者 Glove,通過做語言模型任務(wù),就可以獲得每個單詞的 Word Embedding,那么這種方法的效果如何呢?上圖給了網(wǎng)上找的幾個例子,可以看出有些例子效果還是很不錯的,一個單詞表達(dá)成 Word Embedding 后,很容易找出語義相近的其它詞匯。
我們的主題是預(yù)訓(xùn)練,那么問題是 Word Embedding 這種做法能算是預(yù)訓(xùn)練嗎?這其實就是標(biāo)準(zhǔn)的預(yù)訓(xùn)練過程。要理解這一點要看看學(xué)會 Word Embedding 后下游任務(wù)是怎么用它的。
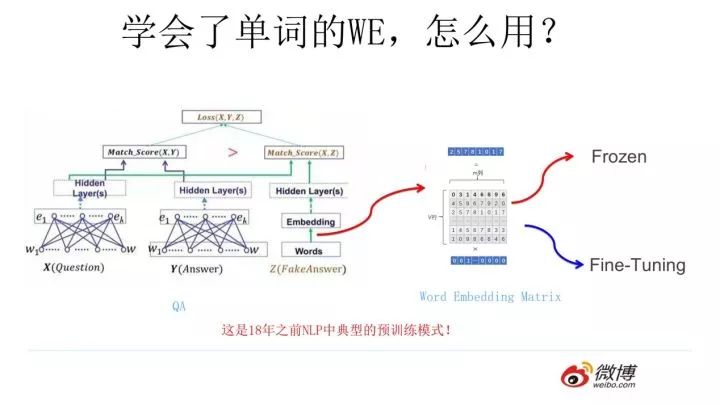
假設(shè)如上圖所示,我們有個 NLP 的下游任務(wù),比如 QA,就是問答問題,所謂問答問題,指的是給定一個問題 X,給定另外一個句子 Y, 要判斷句子 Y 是否是問題 X 的正確答案。問答問題假設(shè)設(shè)計的網(wǎng)絡(luò)結(jié)構(gòu)如上圖所示,這里不展開講了,懂得自然懂,不懂的也沒關(guān)系,因為這點對于本文主旨來說不關(guān)鍵,關(guān)鍵是網(wǎng)絡(luò)如何使用訓(xùn)練好的 Word Embedding 的。
它的使用方法其實和前面講的 NNLM 是一樣的,句子中每個單詞以 Onehot 形式作為輸入,然后乘以學(xué)好的 Word Embedding 矩陣 Q,就直接取出單詞對應(yīng)的 Word Embedding 了。這乍看上去好像是個查表操作,不像是預(yù)訓(xùn)練的做法是吧?其實不然,那個 Word Embedding 矩陣 Q 其實就是網(wǎng)絡(luò) Onehot 層到 embedding 層映射的網(wǎng)絡(luò)參數(shù)矩陣。
所以你看到了,使用 Word Embedding 等價于什么?等價于把 Onehot 層到 embedding 層的網(wǎng)絡(luò)用預(yù)訓(xùn)練好的參數(shù)矩陣 Q 初始化了。這跟前面講的圖像領(lǐng)域的低層預(yù)訓(xùn)練過程其實是一樣的,區(qū)別無非 Word Embedding 只能初始化第一層網(wǎng)絡(luò)參數(shù),再高層的參數(shù)就無能為力了。下游 NLP 任務(wù)在使用 Word Embedding 的時候也類似圖像有兩種做法:
一種是 Frozen,就是 Word Embedding 那層網(wǎng)絡(luò)參數(shù)固定不動;
另外一種是 Fine-Tuning,就是 Word Embedding 這層參數(shù)使用新的訓(xùn)練集合訓(xùn)練也需要跟著訓(xùn)練過程更新掉。
上面這種做法就是 18 年之前 NLP 領(lǐng)域里面采用預(yù)訓(xùn)練的典型做法,之前說過,Word Embedding 其實對于很多下游 NLP 任務(wù)是有幫助的,只是幫助沒有大到閃瞎忘記戴墨鏡的圍觀群眾的雙眼而已。那么新問題來了,為什么這樣訓(xùn)練及使用 Word Embedding 的效果沒有期待中那么好呢?答案很簡單,因為 Word Embedding 有問題唄。這貌似是個比較弱智的答案,關(guān)鍵是 Word Embedding 存在什么問題?這其實是個好問題。

這片在 Word Embedding 頭上籠罩了好幾年的烏云是什么?是多義詞問題。我們知道,多義詞是自然語言中經(jīng)常出現(xiàn)的現(xiàn)象,也是語言靈活性和高效性的一種體現(xiàn)。多義詞對 Word Embedding 來說有什么負(fù)面影響?
如上圖所示,比如多義詞 Bank,有兩個常用含義,但是 Word Embedding 在對 bank 這個單詞進行編碼的時候,是區(qū)分不開這兩個含義的,因為它們盡管上下文環(huán)境中出現(xiàn)的單詞不同,但是在用語言模型訓(xùn)練的時候,不論什么上下文的句子經(jīng)過 word2vec,都是預(yù)測相同的單詞 bank,而同一個單詞占的是同一行的參數(shù)空間,這導(dǎo)致兩種不同的上下文信息都會編碼到相同的 word embedding 空間里去。所以 word embedding 無法區(qū)分多義詞的不同語義,這就是它的一個比較嚴(yán)重的問題。
你可能覺得自己很聰明,說這可以解決啊,確實也有很多研究人員提出很多方法試圖解決這個問題,但是從今天往回看,這些方法看上去都成本太高或者太繁瑣了,有沒有簡單優(yōu)美的解決方案呢?
ELMO 提供了一種簡潔優(yōu)雅的解決方案。
▌從 Word Embedding 到 ELMO
ELMO 是“Embedding from Language Models”的簡稱,其實這個名字并沒有反應(yīng)它的本質(zhì)思想,提出ELMO的論文題目:“Deep contextualized word representation”更能體現(xiàn)其精髓,而精髓在哪里?在 deep contextualized 這個短語,一個是 deep,一個是 context,其中 context 更關(guān)鍵。在此之前的 Word Embedding 本質(zhì)上是個靜態(tài)的方式,所謂靜態(tài)指的是訓(xùn)練好之后每個單詞的表達(dá)就固定住了,以后使用的時候,不論新句子上下文單詞是什么,這個單詞的 Word Embedding 不會跟著上下文場景的變化而改變,所以對于比如 Bank 這個詞,它事先學(xué)好的 Word Embedding 中混合了幾種語義,在應(yīng)用中來了個新句子,即使從上下文中(比如句子包含 money 等詞)明顯可以看出它代表的是「銀行」的含義,但是對應(yīng)的 Word Embedding 內(nèi)容也不會變,它還是混合了多種語義。這是為何說它是靜態(tài)的,這也是問題所在。
ELMO 的本質(zhì)思想是:我事先用語言模型學(xué)好一個單詞的 Word Embedding,此時多義詞無法區(qū)分,不過這沒關(guān)系。在我實際使用 Word Embedding 的時候,單詞已經(jīng)具備了特定的上下文了,這個時候我可以根據(jù)上下文單詞的語義去調(diào)整單詞的 Word Embedding 表示,這樣經(jīng)過調(diào)整后的 Word Embedding 更能表達(dá)在這個上下文中的具體含義,自然也就解決了多義詞的問題了。所以 ELMO 本身是個根據(jù)當(dāng)前上下文對 Word Embedding 動態(tài)調(diào)整的思路。
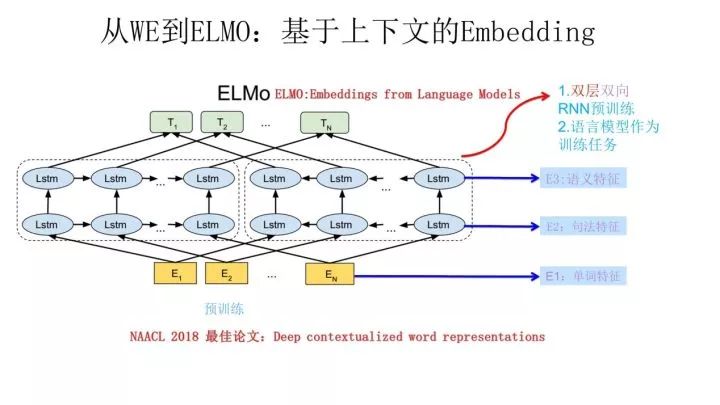
ELMO 采用了典型的兩階段過程,第一個階段是利用語言模型進行預(yù)訓(xùn)練;第二個階段是在做下游任務(wù)時,從預(yù)訓(xùn)練網(wǎng)絡(luò)中提取對應(yīng)單詞的網(wǎng)絡(luò)各層的 Word Embedding 作為新特征補充到下游任務(wù)中。
上圖展示的是其預(yù)訓(xùn)練過程,它的網(wǎng)絡(luò)結(jié)構(gòu)采用了雙層雙向 LSTM,目前語言模型訓(xùn)練的任務(wù)目標(biāo)是根據(jù)單詞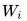 的上下文去正確預(yù)測單詞
的上下文去正確預(yù)測單詞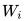 ,
,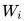 之前的單詞序列 Context-before 稱為上文,之后的單詞序列 Context-after 稱為下文。圖中左端的前向雙層LSTM代表正方向編碼器,輸入的是從左到右順序的除了預(yù)測單詞外
之前的單詞序列 Context-before 稱為上文,之后的單詞序列 Context-after 稱為下文。圖中左端的前向雙層LSTM代表正方向編碼器,輸入的是從左到右順序的除了預(yù)測單詞外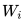 的上文 Context-before;右端的逆向雙層 LSTM 代表反方向編碼器,輸入的是從右到左的逆序的句子下文 Context-after;每個編碼器的深度都是兩層 LSTM 疊加。這個網(wǎng)絡(luò)結(jié)構(gòu)其實在 NLP 中是很常用的。
的上文 Context-before;右端的逆向雙層 LSTM 代表反方向編碼器,輸入的是從右到左的逆序的句子下文 Context-after;每個編碼器的深度都是兩層 LSTM 疊加。這個網(wǎng)絡(luò)結(jié)構(gòu)其實在 NLP 中是很常用的。
使用這個網(wǎng)絡(luò)結(jié)構(gòu)利用大量語料做語言模型任務(wù)就能預(yù)先訓(xùn)練好這個網(wǎng)絡(luò),如果訓(xùn)練好這個網(wǎng)絡(luò)后,輸入一個新句子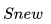 ,句子中每個單詞都能得到對應(yīng)的三個Embedding:最底層是單詞的 Word Embedding,往上走是第一層雙向 LSTM中對應(yīng)單詞位置的 Embedding,這層編碼單詞的句法信息更多一些;再往上走是第二層 LSTM 中對應(yīng)單詞位置的 Embedding,這層編碼單詞的語義信息更多一些。也就是說,ELMO 的預(yù)訓(xùn)練過程不僅僅學(xué)會單詞的 Word Embedding,還學(xué)會了一個雙層雙向的 LSTM 網(wǎng)絡(luò)結(jié)構(gòu),而這兩者后面都有用。?
,句子中每個單詞都能得到對應(yīng)的三個Embedding:最底層是單詞的 Word Embedding,往上走是第一層雙向 LSTM中對應(yīng)單詞位置的 Embedding,這層編碼單詞的句法信息更多一些;再往上走是第二層 LSTM 中對應(yīng)單詞位置的 Embedding,這層編碼單詞的語義信息更多一些。也就是說,ELMO 的預(yù)訓(xùn)練過程不僅僅學(xué)會單詞的 Word Embedding,還學(xué)會了一個雙層雙向的 LSTM 網(wǎng)絡(luò)結(jié)構(gòu),而這兩者后面都有用。?
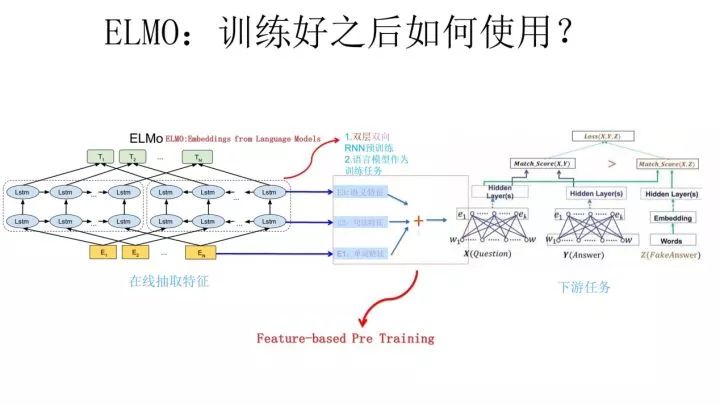
上面介紹的是 ELMO 的第一階段:預(yù)訓(xùn)練階段。那么預(yù)訓(xùn)練好網(wǎng)絡(luò)結(jié)構(gòu)后,如何給下游任務(wù)使用呢?上圖展示了下游任務(wù)的使用過程,比如我們的下游任務(wù)仍然是 QA 問題,此時對于問句 X,我們可以先將句子 X 作為預(yù)訓(xùn)練好的 ELMO 網(wǎng)絡(luò)的輸入,這樣句子 X 中每個單詞在 ELMO 網(wǎng)絡(luò)中都能獲得對應(yīng)的三個 Embedding,之后給予這三個 Embedding 中的每一個 Embedding 一個權(quán)重 a,這個權(quán)重可以學(xué)習(xí)得來,根據(jù)各自權(quán)重累加求和,將三個 Embedding 整合成一個。
然后將整合后的這個 Embedding 作為 X 句在自己任務(wù)的那個網(wǎng)絡(luò)結(jié)構(gòu)中對應(yīng)單詞的輸入,以此作為補充的新特征給下游任務(wù)使用。對于上圖所示下游任務(wù) QA 中的回答句子 Y 來說也是如此處理。
因為 ELMO給下游提供的是每個單詞的特征形式,所以這一類預(yù)訓(xùn)練的方法被稱為“Feature-based Pre-Training”。至于為何這么做能夠達(dá)到區(qū)分多義詞的效果,你可以想一想,其實比較容易想明白原因。
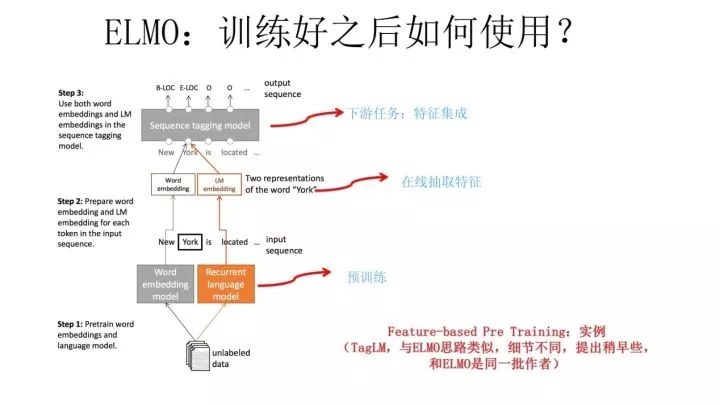
上面這個圖是 TagLM 采用類似 ELMO 的思路做命名實體識別任務(wù)的過程,其步驟基本如上述 ELMO 的思路,所以此處不展開說了。TagLM 的論文發(fā)表在 2017 年的 ACL 會議上,作者就是 AllenAI 里做 ELMO 的那些人,所以可以將 TagLM 看做 ELMO 的一個前導(dǎo)工作。前幾天這個 PPT 發(fā)出去后有人質(zhì)疑說 FastAI 的在 18 年 4 月提出的 ULMFiT 才是拋棄傳統(tǒng) Word Embedding 引入新模式的開山之作,我深不以為然。
首先 TagLM 出現(xiàn)的更早而且模式基本就是 ELMO 的思路;另外 ULMFiT 使用的是三階段模式,在通用語言模型訓(xùn)練之后,加入了一個領(lǐng)域語言模型預(yù)訓(xùn)練過程,而且論文重點工作在這塊,方法還相對比較繁雜,這并不是一個特別好的主意,因為領(lǐng)域語言模型的限制是它的規(guī)模往往不可能特別大,精力放在這里不太合適,放在通用語言模型上感覺更合理;再者,盡管 ULFMiT 實驗做了 6 個任務(wù),但是都集中在分類問題相對比較窄,不如 ELMO 驗證的問題領(lǐng)域廣,我覺得這就是因為第二步那個領(lǐng)域語言模型帶來的限制。所以綜合看,盡管 ULFMiT 也是個不錯的工作,但是重要性跟 ELMO 比至少還是要差一檔,當(dāng)然這是我個人看法。
每個人的學(xué)術(shù)審美口味不同,我個人一直比較贊賞要么簡潔有效體現(xiàn)問題本質(zhì)要么思想特別游離現(xiàn)有框架腦洞開得異常大的工作,所以 ULFMiT 我看論文的時候就感覺看著有點難受,覺得這工作沒抓住重點而且特別麻煩,但是看 ELMO 論文感覺就賞心悅目,覺得思路特別清晰順暢,看完暗暗點贊,心里說這樣的文章獲得 NAACL2018 最佳論文當(dāng)之無愧,比 ACL 很多最佳論文也好得不是一點半點,這就是好工作帶給一個有經(jīng)驗人士的一種在讀論文時候就能產(chǎn)生的本能的感覺,也就是所謂的這道菜對上了食客的審美口味。

前面我們提到靜態(tài) Word Embedding 無法解決多義詞的問題,那么 ELMO 引入上下文動態(tài)調(diào)整單詞的 embedding 后多義詞問題解決了嗎?解決了,而且比我們期待的解決得還要好。
上圖給了個例子,對于 Glove 訓(xùn)練出的 Word Embedding 來說,多義詞比如 play,根據(jù)它的 embedding 找出的最接近的其它單詞大多數(shù)集中在體育領(lǐng)域,這很明顯是因為訓(xùn)練數(shù)據(jù)中包含 play 的句子中體育領(lǐng)域的數(shù)量明顯占優(yōu)導(dǎo)致;而使用 ELMO,根據(jù)上下文動態(tài)調(diào)整后的 embedding 不僅能夠找出對應(yīng)的「演出」的相同語義的句子,而且還可以保證找出的句子中的 play 對應(yīng)的詞性也是相同的,這是超出期待之處。之所以會這樣,是因為我們上面提到過,第一層 LSTM 編碼了很多句法信息,這在這里起到了重要作用。
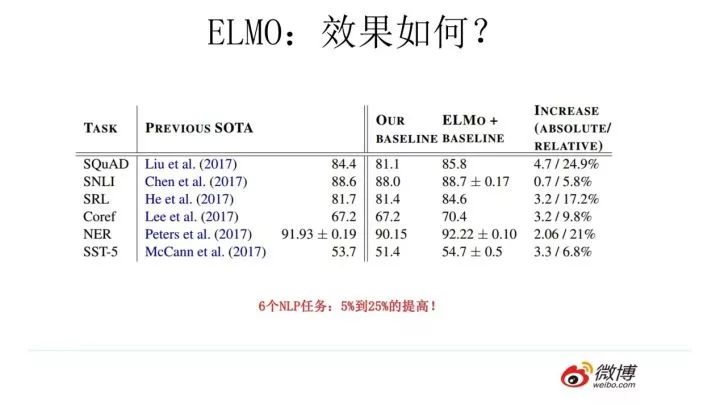
ELMO 經(jīng)過這般操作,效果如何呢?實驗效果見上圖,6 個 NLP 任務(wù)中性能都有幅度不同的提升,最高的提升達(dá)到 25% 左右,而且這 6 個任務(wù)的覆蓋范圍比較廣,包含句子語義關(guān)系判斷,分類任務(wù),閱讀理解等多個領(lǐng)域,這說明其適用范圍是非常廣的,普適性強,這是一個非常好的優(yōu)點。

那么站在現(xiàn)在這個時間節(jié)點看,ELMO 有什么值得改進的缺點呢?首先,一個非常明顯的缺點在特征抽取器選擇方面,ELMO 使用了 LSTM 而不是新貴 Transformer,Transformer 是谷歌在 17 年做機器翻譯任務(wù)的“Attention is all you need”的論文中提出的,引起了相當(dāng)大的反響,很多研究已經(jīng)證明了 Transformer 提取特征的能力是要遠(yuǎn)強于 LSTM 的。如果 ELMO 采取 Transformer 作為特征提取器,那么估計 Bert 的反響遠(yuǎn)不如現(xiàn)在的這種火爆場面。另外一點,ELMO 采取雙向拼接這種融合特征的能力可能比 Bert 一體化的融合特征方式弱,但是,這只是一種從道理推斷產(chǎn)生的懷疑,目前并沒有具體實驗說明這一點。
我們?nèi)绻?ELMO 這種預(yù)訓(xùn)練方法和圖像領(lǐng)域的預(yù)訓(xùn)練方法對比,發(fā)現(xiàn)兩者模式看上去還是有很大差異的。除了以 ELMO 為代表的這種基于特征融合的預(yù)訓(xùn)練方法外,NLP 里還有一種典型做法,這種做法和圖像領(lǐng)域的方式就是看上去一致的了,一般將這種方法稱為“基于 Fine-tuning 的模式”,而 GPT 就是這一模式的典型開創(chuàng)者。
▌從 Word Embedding 到 GPT
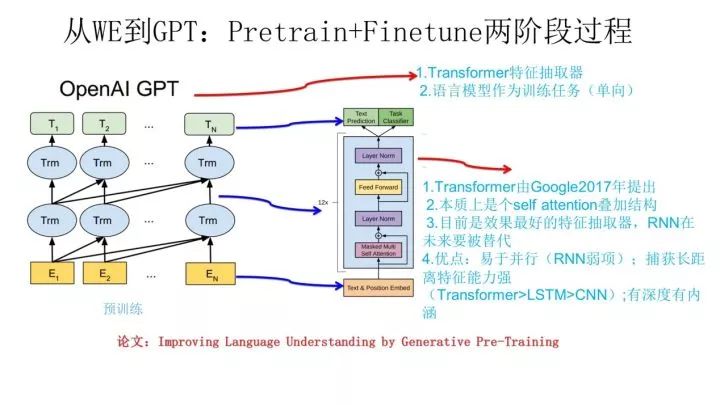
GPT 是“Generative Pre-Training”的簡稱,從名字看其含義是指的生成式的預(yù)訓(xùn)練。GPT 也采用兩階段過程,第一個階段是利用語言模型進行預(yù)訓(xùn)練,第二階段通過 Fine-tuning 的模式解決下游任務(wù)。上圖展示了 GPT 的預(yù)訓(xùn)練過程,其實和 ELMO 是類似的,主要不同在于兩點:
首先,特征抽取器不是用的 RNN,而是用的 Transformer,上面提到過它的特征抽取能力要強于 RNN,這個選擇很明顯是很明智的;
其次,GPT 的預(yù)訓(xùn)練雖然仍然是以語言模型作為目標(biāo)任務(wù),但是采用的是單向的語言模型,所謂“單向”的含義是指:語言模型訓(xùn)練的任務(wù)目標(biāo)是根據(jù)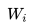 單詞的上下文去正確預(yù)測單詞
單詞的上下文去正確預(yù)測單詞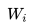 ,
,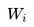 之前的單詞序列 Context-before 稱為上文,之后的單詞序列 Context-after 稱為下文。ELMO 在做語言模型預(yù)訓(xùn)練的時候,預(yù)測單詞
之前的單詞序列 Context-before 稱為上文,之后的單詞序列 Context-after 稱為下文。ELMO 在做語言模型預(yù)訓(xùn)練的時候,預(yù)測單詞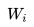 同時使用了上文和下文,而 GPT 則只采用 Context-before 這個單詞的上文來進行預(yù)測,而拋開了下文。
同時使用了上文和下文,而 GPT 則只采用 Context-before 這個單詞的上文來進行預(yù)測,而拋開了下文。
這個選擇現(xiàn)在看不是個太好的選擇,原因很簡單,它沒有把單詞的下文融合進來,這限制了其在更多應(yīng)用場景的效果,比如閱讀理解這種任務(wù),在做任務(wù)的時候是可以允許同時看到上文和下文一起做決策的。如果預(yù)訓(xùn)練時候不把單詞的下文嵌入到 Word Embedding 中,是很吃虧的,白白丟掉了很多信息。
這里強行插入一段簡單提下 Transformer,盡管上面提到了,但是說的還不完整,補充兩句。首先,Transformer 是個疊加的“自注意力機制(Self Attention)”構(gòu)成的深度網(wǎng)絡(luò),是目前 NLP 里最強的特征提取器,注意力這個機制在此被發(fā)揚光大,從任務(wù)的配角不斷搶戲,直到 Transformer 一躍成為踢開 RNN 和 CNN 傳統(tǒng)特征提取器,榮升頭牌,大紅大紫。你問了:什么是注意力機制?這里再插個廣告,對注意力不了解的可以參考鄙人 16 年出品 17 年修正的下文:“深度學(xué)習(xí)中的注意力模型”,補充下相關(guān)基礎(chǔ)知識,如果不了解注意力機制你肯定會落后時代的發(fā)展。而介紹 Transformer 比較好的文章可以參考哈佛大學(xué) NLP 研究組寫的“The Annotated Transformer.”,代碼原理雙管齊下,講得非常清楚,這里不展開介紹。
其次,我的判斷是 Transformer 在未來會逐漸替代掉 RNN 成為主流的 NLP 工具,RNN 一直受困于其并行計算能力,這是因為它本身結(jié)構(gòu)的序列性依賴導(dǎo)致的,盡管很多人在試圖通過修正 RNN 結(jié)構(gòu)來修正這一點,但是我不看好這種模式,因為給馬車換輪胎不如把它升級到汽車,這個道理很好懂,更何況目前汽車的雛形已經(jīng)出現(xiàn)了,干嘛還要執(zhí)著在換輪胎這個事情呢?是吧?再說 CNN,CNN 在 NLP 里一直沒有形成主流,CNN 的最大優(yōu)點是易于做并行計算,所以速度快,但是在捕獲 NLP 的序列關(guān)系尤其是長距離特征方面天然有缺陷,不是做不到而是做不好,目前也有很多改進模型,但是特別成功的不多。綜合各方面情況,很明顯 Transformer 同時具備并行性好,又適合捕獲長距離特征,沒有理由不在賽跑比賽中跑不過 RNN 和 CNN。
好了,題外話結(jié)束,我們再回到主題,接著說 GPT。上面講的是 GPT 如何進行第一階段的預(yù)訓(xùn)練,那么假設(shè)預(yù)訓(xùn)練好了網(wǎng)絡(luò)模型,后面下游任務(wù)怎么用?它有自己的個性,和 ELMO 的方式大有不同。
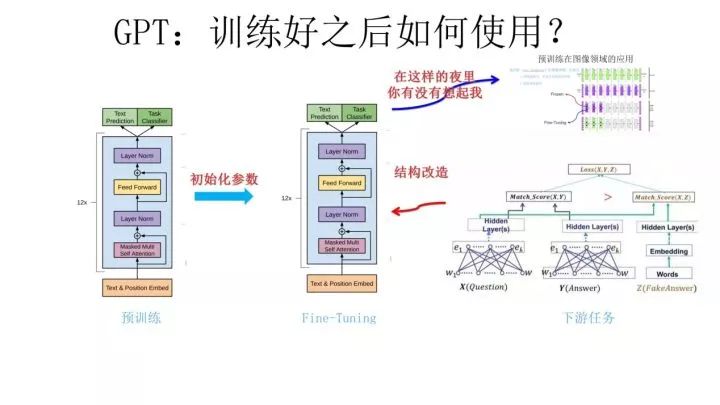
上圖展示了 GPT 在第二階段如何使用。首先,對于不同的下游任務(wù)來說,本來你可以任意設(shè)計自己的網(wǎng)絡(luò)結(jié)構(gòu),現(xiàn)在不行了,你要向 GPT 的網(wǎng)絡(luò)結(jié)構(gòu)看齊,把任務(wù)的網(wǎng)絡(luò)結(jié)構(gòu)改造成和 GPT 的網(wǎng)絡(luò)結(jié)構(gòu)是一樣的。然后,在做下游任務(wù)的時候,利用第一步預(yù)訓(xùn)練好的參數(shù)初始化 GPT 的網(wǎng)絡(luò)結(jié)構(gòu),這樣通過預(yù)訓(xùn)練學(xué)到的語言學(xué)知識就被引入到你手頭的任務(wù)里來了,這是個非常好的事情。再次,你可以用手頭的任務(wù)去訓(xùn)練這個網(wǎng)絡(luò),對網(wǎng)絡(luò)參數(shù)進行 Fine-tuning,使得這個網(wǎng)絡(luò)更適合解決手頭的問題。就是這樣。看到了么?這有沒有讓你想起最開始提到的圖像領(lǐng)域如何做預(yù)訓(xùn)練的過程(請參考上圖那句非常容易暴露年齡的歌詞)?對,這跟那個模式是一模一樣的。
這里引入了一個新問題:對于 NLP 各種花樣的不同任務(wù),怎么改造才能靠近 GPT 的網(wǎng)絡(luò)結(jié)構(gòu)呢?
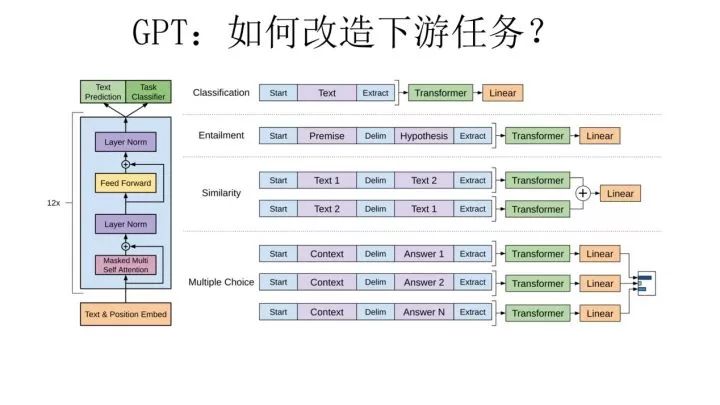
GPT 論文給了一個改造施工圖如上,其實也很簡單:對于分類問題,不用怎么動,加上一個起始和終結(jié)符號即可;對于句子關(guān)系判斷問題,比如 Entailment,兩個句子中間再加個分隔符即可;對文本相似性判斷問題,把兩個句子順序顛倒下做出兩個輸入即可,這是為了告訴模型句子順序不重要;對于多項選擇問題,則多路輸入,每一路把文章和答案選項拼接作為輸入即可。從上圖可看出,這種改造還是很方便的,不同任務(wù)只需要在輸入部分施工即可。
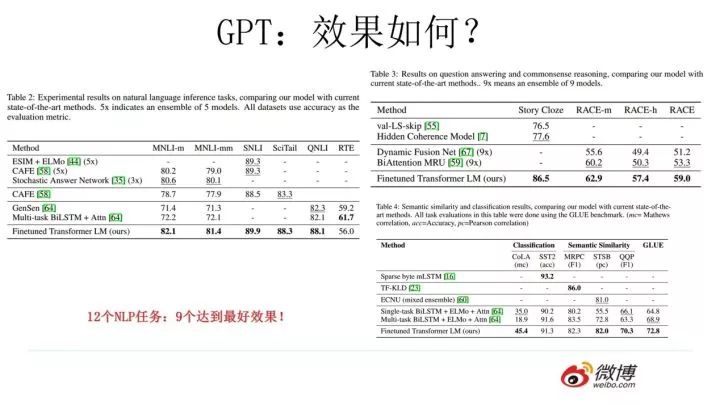
GPT 的效果是非常令人驚艷的,在 12 個任務(wù)里,9 個達(dá)到了最好的效果,有些任務(wù)性能提升非常明顯。

那么站在現(xiàn)在的時間節(jié)點看,GPT 有什么值得改進的地方呢?其實最主要的就是那個單向語言模型,如果改造成雙向的語言模型任務(wù)估計也沒有 Bert 太多事了。當(dāng)然,即使如此 GPT 也是非常非常好的一個工作,跟 Bert 比,其作者炒作能力亟待提升。
▌Bert 的誕生
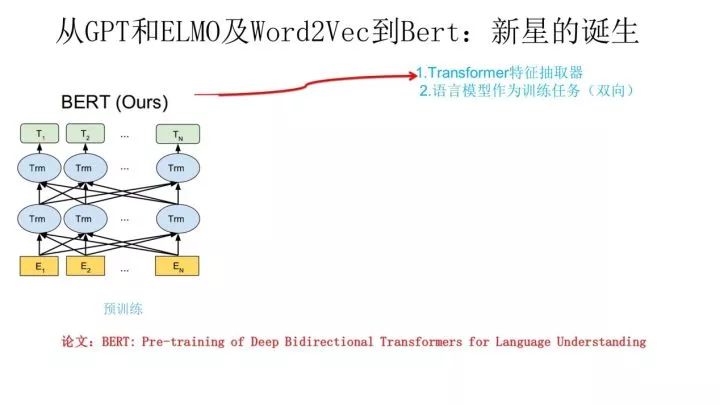
我們經(jīng)過跋山涉水,終于到了目的地 Bert 模型了。
Bert 采用和 GPT 完全相同的兩階段模型,首先是語言模型預(yù)訓(xùn)練;其次是使用 Fine-Tuning 模式解決下游任務(wù)。和 GPT 的最主要不同在于在預(yù)訓(xùn)練階段采用了類似 ELMO 的雙向語言模型,當(dāng)然另外一點是語言模型的數(shù)據(jù)規(guī)模要比 GPT 大。所以這里 Bert 的預(yù)訓(xùn)練過程不必多講了。
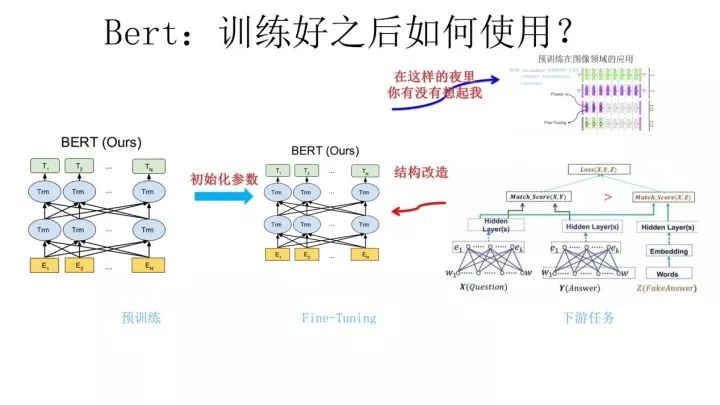
第二階段,F(xiàn)ine-Tuning 階段,這個階段的做法和 GPT 是一樣的。當(dāng)然,它也面臨著下游任務(wù)網(wǎng)絡(luò)結(jié)構(gòu)改造的問題,在改造任務(wù)方面 Bert 和 GPT 有些不同,下面簡單介紹一下。

在介紹 Bert 如何改造下游任務(wù)之前,先大致說下 NLP 的幾類問題,說這個是為了強調(diào) Bert 的普適性有多強。通常而言,絕大部分 NLP 問題可以歸入上圖所示的四類任務(wù)中:
一類是序列標(biāo)注,這是最典型的 NLP 任務(wù),比如中文分詞,詞性標(biāo)注,命名實體識別,語義角色標(biāo)注等都可以歸入這一類問題,它的特點是句子中每個單詞要求模型根據(jù)上下文都要給出一個分類類別。
第二類是分類任務(wù),比如我們常見的文本分類,情感計算等都可以歸入這一類。它的特點是不管文章有多長,總體給出一個分類類別即可。
第三類任務(wù)是句子關(guān)系判斷,比如 Entailment,QA,語義改寫,自然語言推理等任務(wù)都是這個模式,它的特點是給定兩個句子,模型判斷出兩個句子是否具備某種語義關(guān)系。
第四類是生成式任務(wù),比如機器翻譯,文本摘要,寫詩造句,看圖說話等都屬于這一類。它的特點是輸入文本內(nèi)容后,需要自主生成另外一段文字。
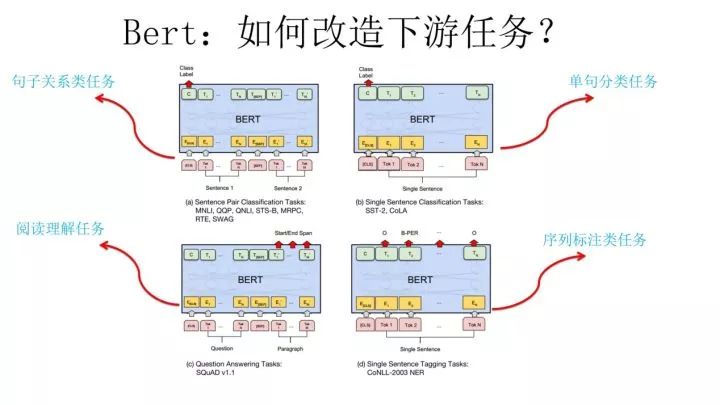
對于種類如此繁多而且各具特點的下游 NLP 任務(wù),Bert 如何改造輸入輸出部分使得大部分 NLP 任務(wù)都可以使用 Bert 預(yù)訓(xùn)練好的模型參數(shù)呢?
上圖給出示例,對于句子關(guān)系類任務(wù),很簡單,和 GPT 類似,加上一個起始和終結(jié)符號,句子之間加個分隔符即可。對于輸出來說,把第一個起始符號對應(yīng)的 Transformer 最后一層位置上面串接一個 softmax 分類層即可。對于分類問題,與 GPT 一樣,只需要增加起始和終結(jié)符號,輸出部分和句子關(guān)系判斷任務(wù)類似改造;對于序列標(biāo)注問題,輸入部分和單句分類是一樣的,只需要輸出部分 Transformer 最后一層每個單詞對應(yīng)位置都進行分類即可。從這里可以看出,上面列出的 NLP 四大任務(wù)里面,除了生成類任務(wù)外,Bert 其它都覆蓋到了,而且改造起來很簡單直觀。
盡管 Bert 論文沒有提,但是稍微動動腦子就可以想到,其實對于機器翻譯或者文本摘要,聊天機器人這種生成式任務(wù),同樣可以稍作改造即可引入 Bert 的預(yù)訓(xùn)練成果。只需要附著在 S2S 結(jié)構(gòu)上,encoder 部分是個深度 Transformer 結(jié)構(gòu),decoder 部分也是個深度 Transformer 結(jié)構(gòu)。根據(jù)任務(wù)選擇不同的預(yù)訓(xùn)練數(shù)據(jù)初始化 encoder 和 decoder 即可。這是相當(dāng)直觀的一種改造方法。當(dāng)然,也可以更簡單一點,比如直接在單個 Transformer 結(jié)構(gòu)上加裝隱層產(chǎn)生輸出也是可以的。
不論如何,從這里可以看出,NLP 四大類任務(wù)都可以比較方便地改造成 Bert 能夠接受的方式。這其實是 Bert 的非常大的優(yōu)點,這意味著它幾乎可以做任何 NLP 的下游任務(wù),具備普適性,這是很強的。
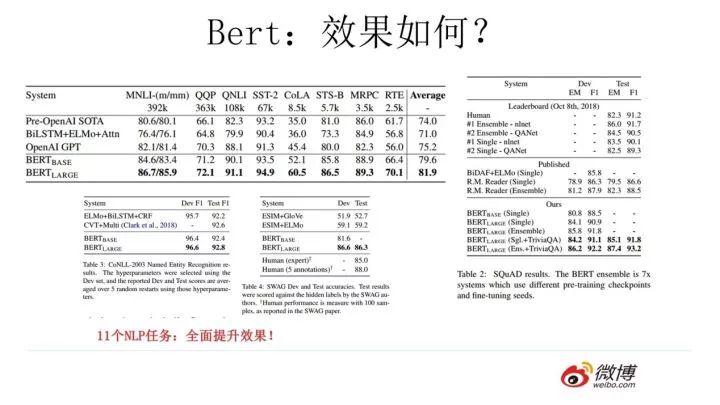
Bert 采用這種兩階段方式解決各種 NLP 任務(wù)效果如何?在 11 個各種類型的 NLP 任務(wù)中達(dá)到目前最好的效果,某些任務(wù)性能有極大的提升。一個新模型好不好,效果才是王道。
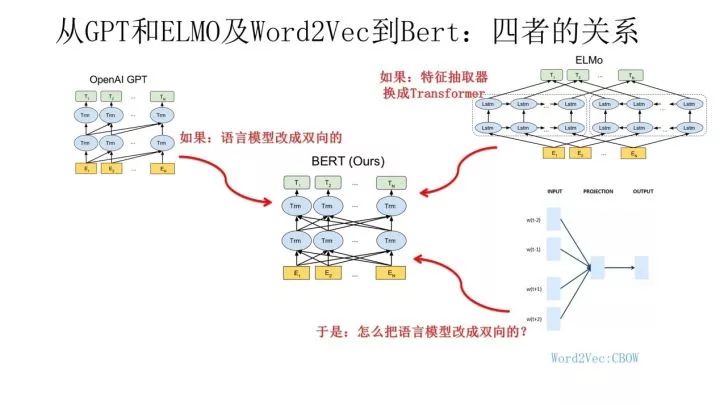
到這里我們可以再梳理下幾個模型之間的演進關(guān)系。從上圖可見,Bert 其實和 ELMO 及 GPT 存在千絲萬縷的關(guān)系,比如如果我們把 GPT 預(yù)訓(xùn)練階段換成雙向語言模型,那么就得到了 Bert;而如果我們把 ELMO 的特征抽取器換成 Transformer,那么我們也會得到 Bert。所以你可以看出:Bert 最關(guān)鍵兩點,一點是特征抽取器采用 Transformer;第二點是預(yù)訓(xùn)練的時候采用雙向語言模型。
那么新問題來了:對于 Transformer 來說,怎么才能在這個結(jié)構(gòu)上做雙向語言模型任務(wù)呢?
乍一看上去好像不太好搞。我覺得吧,其實有一種很直觀的思路,怎么辦?看看 ELMO 的網(wǎng)絡(luò)結(jié)構(gòu)圖,只需要把兩個 LSTM 替換成兩個 Transformer,一個負(fù)責(zé)正向,一個負(fù)責(zé)反向特征提取,其實應(yīng)該就可以。當(dāng)然這是我自己的改造,Bert 沒這么做。那么 Bert 是怎么做的呢?我們前面不是提過 Word2Vec 嗎?我前面肯定不是漫無目的地提到它,提它是為了在這里引出那個 CBOW 訓(xùn)練方法,所謂寫作時候埋伏筆的「草蛇灰線,伏脈千里」,大概就是這個意思吧?
前面提到了 CBOW 方法,它的核心思想是:在做語言模型任務(wù)的時候,我把要預(yù)測的單詞摳掉,然后根據(jù)它的上文 Context-Before 和下文 Context-after 去預(yù)測單詞。其實 Bert 怎么做的?Bert 就是這么做的。從這里可以看到方法間的繼承關(guān)系。當(dāng)然 Bert 作者沒提 Word2Vec 及 CBOW 方法,這是我的判斷,Bert 作者說是受到完形填空任務(wù)的啟發(fā),這也很可能,但是我覺得他們要是沒想到過 CBOW 估計是不太可能的。
從這里可以看出,在文章開始我說過 Bert 在模型方面其實沒有太大創(chuàng)新,更像一個最近幾年 NLP 重要技術(shù)的集大成者,原因在于此,當(dāng)然我不確定你怎么看,是否認(rèn)同這種看法,而且我也不關(guān)心你怎么看。其實 Bert 本身的效果好和普適性強才是最大的亮點。
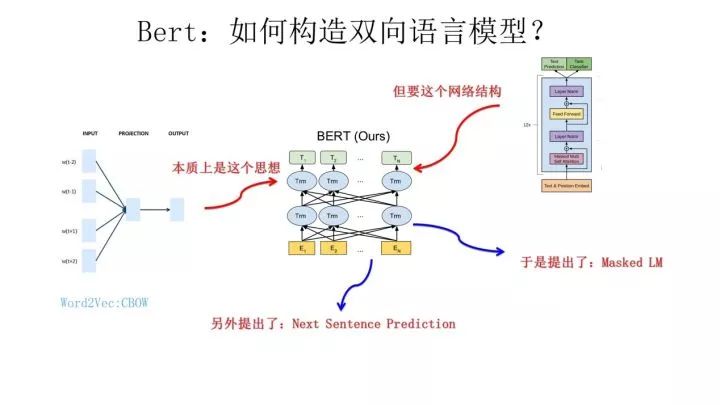
那么 Bert 本身在模型和方法角度有什么創(chuàng)新呢?就是論文中指出的 Masked 語言模型和 Next Sentence Prediction。而 Masked 語言模型上面講了,本質(zhì)思想其實是 CBOW,但是細(xì)節(jié)方面有改進。

Masked 雙向語言模型向上圖展示這么做:隨機選擇語料中 15% 的單詞,把它摳掉,也就是用 [Mask] 掩碼代替原始單詞,然后要求模型去正確預(yù)測被摳掉的單詞。但是這里有個問題:訓(xùn)練過程大量看到 [mask] 標(biāo)記,但是真正后面用的時候是不會有這個標(biāo)記的,這會引導(dǎo)模型認(rèn)為輸出是針對 [mask] 這個標(biāo)記的,但是實際使用又見不到這個標(biāo)記,這自然會有問題。
為了避免這個問題,Bert 改造了一下,15% 的被上天選中要執(zhí)行 [mask] 替身這項光榮任務(wù)的單詞中,只有 80% 真正被替換成 [mask] 標(biāo)記,10% 被貍貓換太子隨機替換成另外一個單詞,10% 情況這個單詞還待在原地不做改動。這就是 Masked 雙向語音模型的具體做法。

至于說“Next Sentence Prediction”,指的是做語言模型預(yù)訓(xùn)練的時候,分兩種情況選擇兩個句子,一種是選擇語料中真正順序相連的兩個句子;另外一種是第二個句子從語料庫中拋色子,隨機選擇一個拼到第一個句子后面。我們要求模型除了做上述的 Masked 語言模型任務(wù)外,附帶再做個句子關(guān)系預(yù)測,判斷第二個句子是不是真的是第一個句子的后續(xù)句子。
之所以這么做,是考慮到很多 NLP 任務(wù)是句子關(guān)系判斷任務(wù),單詞預(yù)測粒度的訓(xùn)練到不了句子關(guān)系這個層級,增加這個任務(wù)有助于下游句子關(guān)系判斷任務(wù)。所以可以看到,它的預(yù)訓(xùn)練是個多任務(wù)過程。這也是 Bert 的一個創(chuàng)新。
上面這個圖給出了一個我們此前利用微博數(shù)據(jù)和開源的 Bert 做預(yù)訓(xùn)練時隨機抽出的一個中文訓(xùn)練實例,從中可以體會下上面講的 masked 語言模型和下句預(yù)測任務(wù)。訓(xùn)練數(shù)據(jù)就長這種樣子。
順帶講解下 Bert 的輸入部分,也算是有些特色。它的輸入部分是個線性序列,兩個句子通過分隔符分割,最前面和最后增加兩個標(biāo)識符號。每個單詞有三個 embedding:
位置信息 embedding,這是因為 NLP 中單詞順序是很重要的特征,需要在這里對位置信息進行編碼;
單詞 embedding, 這個就是我們之前一直提到的單詞 embedding;
句子 embedding,因為前面提到訓(xùn)練數(shù)據(jù)都是由兩個句子構(gòu)成的,那么每個句子有個句子整體的 embedding 項對應(yīng)給每個單詞。把單詞對應(yīng)的三個 embedding 疊加,就形成了 Bert 的輸入。
至于 Bert 在預(yù)訓(xùn)練的輸出部分如何組織,可以參考上圖的注釋。

我們說過 Bert 效果特別好,那么到底是什么因素起作用呢?如上圖所示,對比試驗可以證明,跟 GPT 相比,雙向語言模型起到了最主要的作用,對于那些需要看到下文的任務(wù)來說尤其如此。而預(yù)測下個句子來說對整體性能來說影響不算太大,跟具體任務(wù)關(guān)聯(lián)度比較高。

最后,我講講我對 Bert 的評價和看法,我覺得 Bert 是 NLP 里里程碑式的工作,對于后面 NLP 的研究和工業(yè)應(yīng)用會產(chǎn)生長久的影響,這點毫無疑問。但是從上文介紹也可以看出,從模型或者方法角度看,Bert 借鑒了 ELMO,GPT 及 CBOW,主要提出了 Masked 語言模型及 Next Sentence Prediction,但是這里 Next Sentence Prediction 基本不影響大局,而 Masked LM 明顯借鑒了 CBOW 的思想。所以說 Bert 的模型沒什么大的創(chuàng)新,更像最近幾年 NLP 重要進展的集大成者,這點如果你看懂了上文估計也沒有太大異議,如果你有大的異議,杠精這個大帽子我隨時準(zhǔn)備戴給你。如果歸納一下這些進展就是:
首先是兩階段模型,第一階段雙向語言模型預(yù)訓(xùn)練,這里注意要用雙向而不是單向,第二階段采用具體任務(wù) Fine-tuning 或者做特征集成;
第二是特征抽取要用 Transformer 作為特征提取器而不是 RNN 或者 CNN;
第三,雙向語言模型可以采取 CBOW 的方法去做(當(dāng)然我覺得這個是個細(xì)節(jié)問題,不算太關(guān)鍵,前兩個因素比較關(guān)鍵)。
Bert 最大的亮點在于效果好及普適性強,幾乎所有 NLP 任務(wù)都可以套用 Bert 這種兩階段解決思路,而且效果應(yīng)該會有明顯提升。可以預(yù)見的是,未來一段時間在 NLP 應(yīng)用領(lǐng)域,Transformer 將占據(jù)主導(dǎo)地位,而且這種兩階段預(yù)訓(xùn)練方法也會主導(dǎo)各種應(yīng)用。
另外,我們應(yīng)該弄清楚預(yù)訓(xùn)練這個過程本質(zhì)上是在做什么事情,本質(zhì)上預(yù)訓(xùn)練是通過設(shè)計好一個網(wǎng)絡(luò)結(jié)構(gòu)來做語言模型任務(wù),然后把大量甚至是無窮盡的無標(biāo)注的自然語言文本利用起來,預(yù)訓(xùn)練任務(wù)把大量語言學(xué)知識抽取出來編碼到網(wǎng)絡(luò)結(jié)構(gòu)中,當(dāng)手頭任務(wù)帶有標(biāo)注信息的數(shù)據(jù)有限時,這些先驗的語言學(xué)特征當(dāng)然會對手頭任務(wù)有極大的特征補充作用,因為當(dāng)數(shù)據(jù)有限的時候,很多語言學(xué)現(xiàn)象是覆蓋不到的,泛化能力就弱,集成盡量通用的語言學(xué)知識自然會加強模型的泛化能力。
如何引入先驗的語言學(xué)知識其實一直是 NLP 尤其是深度學(xué)習(xí)場景下的 NLP 的主要目標(biāo)之一,不過一直沒有太好的解決辦法,而 ELMO/GPT/Bert 的這種兩階段模式看起來無疑是解決這個問題自然又簡潔的方法,這也是這些方法的主要價值所在。
對于當(dāng)前 NLP 的發(fā)展方向,我個人覺得有兩點非常重要,一個是需要更強的特征抽取器,目前看 Transformer 會逐漸擔(dān)當(dāng)大任,但是肯定還是不夠強的,需要發(fā)展更強的特征抽取器;第二個就是如何優(yōu)雅地引入大量無監(jiān)督數(shù)據(jù)中包含的語言學(xué)知識,注意我這里強調(diào)地是優(yōu)雅,而不是引入,此前相當(dāng)多的工作試圖做各種語言學(xué)知識的嫁接或者引入,但是很多方法看著讓人牙疼,就是我說的不優(yōu)雅。目前看預(yù)訓(xùn)練這種兩階段方法還是很有效的,也非常簡潔,當(dāng)然后面肯定還會有更好的模型出現(xiàn)。
完了,這就是自然語言模型預(yù)訓(xùn)練的發(fā)展史。
-
圖像
+關(guān)注
關(guān)注
2文章
1089瀏覽量
40574 -
神經(jīng)元
+關(guān)注
關(guān)注
1文章
363瀏覽量
18511 -
nlp
+關(guān)注
關(guān)注
1文章
489瀏覽量
22110
原文標(biāo)題:從Word Embedding到Bert模型——自然語言處理預(yù)訓(xùn)練技術(shù)發(fā)展史
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
國內(nèi)儀器儀表的重大成果有哪些
近年來移動電源的發(fā)展歷程
高端技術(shù)集成!征服所有玩四軸的人!!
近年來下游市場,不管是電子產(chǎn)品、汽車電子還是工業(yè)領(lǐng)域及USB Type-C的各種設(shè)備
北京君正案例:數(shù)傳網(wǎng)關(guān)的集大成者—積木式邊緣網(wǎng)關(guān)
近年來市場電池修復(fù)方法的比較
為什么說新一代Leaf電池模組是自然冷卻方式集大成者
榮耀Note 10官宣:搭載最新的GPU Turbo技術(shù),年度旗艦集大成者
比特幣ETF為何始終都未能取得重大進展
為什么說比特幣是多種技術(shù)的集大成者
谷歌在自研芯片方面取得重大進展
NLP入門之Bert的前世今生

北京君正案例:數(shù)傳網(wǎng)關(guān)的集大成者—積木式邊緣網(wǎng)關(guān)
劉德華代言華為非凡大師,首推Mate 60RS版及黃金智能腕表
愛普生M-G370和M-G365——小型高精度定位裝置的集大成者






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論