 BERT的官方代碼終于來了
BERT的官方代碼終于來了
谷歌AI團隊終于開源了最強NLP模型BERT的代碼和預訓練模型。從論文發布以來,BERT在NLP業內引起巨大反響,被認為開啟了NLP的新時代。
BERT的官方代碼終于來了!
昨天,谷歌在GitHub上發布了備受關注的“最強NLP模型”BERT的TensorFlow代碼和預訓練模型,不到一天時間,已經獲得3000多星!
地址:
https://github.com/google-research/bert
BERT,全稱是BidirectionalEncoderRepresentations fromTransformers,是一種預訓練語言表示的新方法。
新智元近期對BERT模型作了詳細的報道和專家解讀:
NLP歷史突破!谷歌BERT模型狂破11項紀錄,全面超越人類!
狂破11項記錄,谷歌年度最強NLP論文到底強在哪里?
解讀谷歌最強NLP模型BERT:模型、數據和訓練
BERT有多強大呢?它在機器閱讀理解頂級水平測試SQuAD1.1中表現出驚人的成績:全部兩個衡量指標上全面超越人類!并且還在11種不同NLP測試中創出最佳成績,包括將GLUE基準推至80.4%(絕對改進7.6%),MultiNLI準確度達到86.7% (絕對改進率5.6%)等。
以下是BERT模型在SQuAD v1.1問題回答任務的結果:
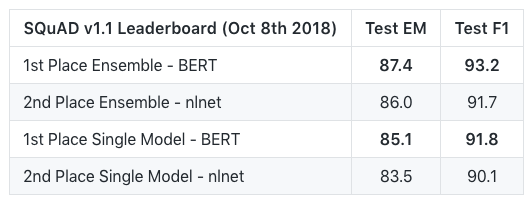
在幾個自然語言推理任務的結果:
以及更多其他任務。
而且,這些結果都是在幾乎沒有task-specific的神經網絡架構設計的情況下獲得的。
如果你已經知道BERT是什么,只想馬上開始使用,可以下載預訓練過的模型,幾分鐘就可以很好地完成調優。
預訓練模型下載:
https://github.com/google-research/bert#pre-trained-models
BERT是什么?
BERT是一種預訓練語言表示(language representations)的方法,意思是我們在一個大型文本語料庫(比如維基百科)上訓練一個通用的“語言理解”模型,然后將這個模型用于我們關心的下游NLP任務(比如問題回答)。BERT優于以前的方法,因為它是第一個用于預訓練NLP的無監督、深度雙向的系統(unsupervised,deeply bidirectionalsystem)。
無監督意味著BERT只使用純文本語料庫進行訓練,這很重要,因為網絡上有大量的公開的純文本數據,而且是多語言的。
預訓練的表示可以是上下文無關(context-free)的,也可以是上下文相關(contextual)的,并且上下文相關表示還可以是單向的或雙向的。上下文無關的模型,比如word2vec或GloVe,會為詞匯表中的每個單詞生成單個“word embedding”表示,因此bank在bank deposit(銀行存款)和river bank(河岸)中具有相同的表示。上下文模型則會根據句子中的其他單詞生成每個單詞的表示。
BERT建立在最近的預訓練contextual representations的基礎上——包括半監督序列學習、生成性預訓練、ELMo和ULMFit——但這些模型都是單向的或淺雙向的。這意味著每個單詞只能使用其左邊(或右邊)的單詞來預測上下文。例如,在I made a bank deposit這個句子中, bank的單向表示僅僅基于I made a,而不是deposit。以前的一些工作結合了來自單獨的left-context和right-context 模型的表示,但只是一種“淺層”的方式。BERT同時使用左側和右側上下文來表示“bank”—— I made a ... deposit——從深神經網絡的最底層開始,所以它是深度雙向的。
BERT使用一種簡單的方法:將輸入中15%的單詞屏蔽(mask)起來,通過一個深度雙向Transformer編碼器運行整個序列,然后僅預測被屏蔽的單詞。例如:
Input: the man went to the [MASK1] . he bought a [MASK2] of milk. Labels: [MASK1] = store; [MASK2] = gallon
為了學習句子之間的關系,我們還訓練了一個可以從任何單語語料庫生成的簡單任務:給定兩個句子A和B, 讓模型判斷B是A的下一個句子,還是語料庫中的一個隨機句子?
Sentence A: the man went to the store . Sentence B: he bought a gallon of milk . Label: IsNextSentenceSentence A: the man went to the store . Sentence B: penguins are flightless . Label: NotNextSentence
然后,我們在大型語料庫(Wikipedia + BookCorpus)上訓練了一個大型模型(12-layer 到 24-layer的Transformer),花了很長時間(100萬次更新步驟),這就是BERT。
使用BERT的兩個階段:預訓練和微調
使用BERT分為兩個階段:預訓練(Pre-training)和微調(Fine-tuning)。
預訓練(Pre-training)的成本是相當昂貴的(需要4到16個Cloud TPU訓練4天),但是對于每種語言來說都只需訓練一次(目前的模型僅限英語的,我們打算很快發布多語言模型)。大多數NLP研究人員根本不需要從頭開始訓練自己的模型。
微調(Fine-tuning)的成本不高。從完全相同的預訓練模型開始,論文中的所有結果在單個Cloud TPU上最多1小時就能復制,或者在GPU上幾小時就能復制。例如,對于SQUAD任務,在單個Cloud TPU上訓練大約30分鐘,就能獲得91.0%的Dev F1分數,這是目前單系統最先進的。
BERT的另一個重要方面是,它可以很容易地適應許多類型的NLP任務。在論文中,我們展示了句子級(例如SST-2)、句子對級別(例如MultiNLI)、單詞級別(例如NER)以及段落級別(例如SQuAD)等任務上最先進的結果,并且,幾乎沒有針對特定任務進行修改。
GitHub庫中包含哪些內容?
BERT模型架構的TensorFlow代碼(主體是一個標準Transformer架構)。
BERT-Base和BERT-Large的lowercase和cased版本的預訓練檢查點。
用于復制論文中最重要的微調實驗的TensorFlow代碼,包括SQuAD,MultiNLI和MRPC。
這個項目庫中所有代碼都可以在CPU、GPU和Cloud TPU上使用。
預訓練模型
我們發布了論文中的BERT-Base和BERT-Large模型。
Uncased表示在WordPiece tokenization之前文本已經變成小寫了,例如,John Smithbecomesjohn smith。Uncased模型也去掉了所有重音標志。
Cased表示保留了真實的大小寫和重音標記。通常,除非你已經知道大小寫信息對你的任務來說很重要(例如,命名實體識別或詞性標記),否則Uncased模型會更好。
這些模型都在與源代碼相同的許可(Apache 2.0)下發布。
請在GitHub的鏈接里下載模型:
BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parameters
BERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters (暫時未發布).
每個.zip文件包含三個項目:
一個包含預訓練權重的TensorFlow checkpoint (bert_model.ckpt),(實際上是3個文件)。
一個vocab文件(vocab.txt),用于將WordPiece映射到word id。
一個配置文件(bert_config.json),用于指定模型的超參數。
BERT的Fine-tuning
重要提示:論文里的所有結果都在單個Cloud TPU上進行了微調,Cloud TPU具有64GB的RAM。目前無法使用具有12GB-16GB RAM的GPU復現論文里BERT-Large的大多數結果,因為內存可以適用的最大 batch size太小。我們正在努力添加代碼,以允許在GPU上實現更大的有效batch size。有關更多詳細信息,請參閱out-of memory issues的部分。
使用BERT-Base的fine-tuning示例應該能夠使用給定的超參數在具有至少12GB RAM的GPU上運行。
BERT預訓練
我們發布了在任意文本語料庫上做“masked LM”和“下一句預測”的代碼。請注意,這不是論文的確切代碼(原始代碼是用C ++編寫的,并且有一些額外的復雜性),但是此代碼確實生成了論文中描述的預訓練數據。
以下是運行數據生成的方法。輸入是純文本文件,每行一個句子。(在“下一句預測”任務中,這些需要是實際的句子)。文件用空行分隔。輸出是一組序列化為TFRecord文件格式的tf.train.Examples。
你可以使用現成的NLP工具包(如spaCy)來執行句子分割。create_pretraining_data.py腳本將連接 segments,直到達到最大序列長度,以最大限度地減少填充造成的計算浪費。但是,你可能需要在輸入數據中有意添加少量噪聲(例如,隨機截斷2%的輸入segments),以使其在微調期間對非句子輸入更加魯棒。
此腳本將整個輸入文件的所有示例存儲在內存中,因此對于大型數據文件,你應該對輸入文件進行切分,并多次調用腳本。(可以將文件glob傳遞給run_pretraining.py,例如,tf_examples.tf_record *。)
max_predictions_per_seq是每個序列的masked LM預測的最大數量。你應該將其設置為max_seq_length * masked_lm_prob(腳本不會自動執行此操作,因為需要將確切的值傳遞給兩個腳本)。
python create_pretraining_data.py --input_file=./sample_text.txt --output_file=/tmp/tf_examples.tfrecord --vocab_file=$BERT_BASE_DIR/vocab.txt --do_lower_case=True --max_seq_length=128 --max_predictions_per_seq=20 --masked_lm_prob=0.15 --random_seed=12345 --dupe_factor=5
以下是如何進行預訓練。
如果你從頭開始進行預訓練,請不要包含init_checkpoint。模型配置(包括詞匯大小)在bert_config_file中指定。此演示代碼僅預訓練少量steps(20),但實際上你可能希望將num_train_steps設置為10000步或更多。傳遞給run_pretraining.py的max_seq_lengthand max_predictions_per_seq參數必須與create_pretraining_data.py相同。
python run_pretraining.py --input_file=/tmp/tf_examples.tfrecord --output_dir=/tmp/pretraining_output --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/bert_config.json --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt --train_batch_size=32 --max_seq_length=128 --max_predictions_per_seq=20 --num_train_steps=20 --num_warmup_steps=10 --learning_rate=2e-5
這將產生如下輸出:
***** Eval results ***** global_step = 20 loss = 0.0979674 masked_lm_accuracy = 0.985479 masked_lm_loss = 0.0979328 next_sentence_accuracy = 1.0 next_sentence_loss = 3.45724e-05FAQ
問:這次公開的代碼是否與Cloud TPU兼容?GPU呢?
答:是的,這個存儲庫中的所有代碼都可以與CPU,GPU和Cloud TPU兼容。但是,GPU訓練僅適用于單GPU。
問:提示內存不足,這是什么問題?
答:請參閱out-of-memory issues這部分的內容。
問:有PyTorch版本嗎?
答:目前還沒有正式的PyTorch實現。如果有人創建了一個逐行PyTorch實現,可以讓我們的預訓練checkpoints直接轉換,那么我們很樂意在這里鏈接到PyTorch版本。
問:是否會發布其他語言的模型?
答:是的,我們計劃很快發布多語言BERT模型。我們不能保證將包含哪些語言,但它很可能是一個單一的模型,其中包括大多數維基百科上預料規模較大的語言。
問:是否會發布比BERT-Large更大的模型?
答:到目前為止,我們還沒有嘗試過比BERT-Large更大的訓練。如果我們能夠獲得重大改進,可能會發布更大的模型。
問:這個庫的許可證是什么?
答:所有代碼和模型都在Apache 2.0許可下發布。
-
谷歌
+關注
關注
27文章
6194瀏覽量
106014 -
代碼
+關注
關注
30文章
4825瀏覽量
69043 -
nlp
+關注
關注
1文章
489瀏覽量
22107
原文標題:谷歌最強NLP模型BERT官方代碼來了!GitHub一天3000星
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
J-BERT N4903A高性能串行BERT手冊
回收M8040A 64 Gbaud 高性能 BERT
BERT模型的PyTorch實現
BERT再次制霸GLUE排行榜!BERT王者歸來了!

如何在BERT中引入知識圖譜中信息
圖解BERT預訓練模型!
如何優雅地使用bert處理長文本

什么是BERT?為何選擇BERT?
總結FasterTransformer Encoder(BERT)的cuda相關優化技巧





 工商網監
工商網監
評論