 從2D到3D,沉浸式的實時視頻通信是如何實現的?
從2D到3D,沉浸式的實時視頻通信是如何實現的?
過去幾年,我們探索工作的初衷是什么?就是如何在未來提供更好的沉浸式的通訊體驗。
我們所從事的是通信技術。最早,我們提供電信網絡,語音通話是我們唯一的業務。語音通話的體驗很重要,但始終無法提供面對面、身臨其境的體驗。如何提升呢?第一步,就是加入視頻,有了視頻就拉近了彼此距離,雙方獲得了更好的交流體驗。但這還不夠。
在我們的設想中,沉浸式的通訊體驗應該像圖中所示,人們在通話時就像在同一個屋子中相視而坐。這是我們希望最終達到的體驗效果。
在7、8年前,我們做了一個項目,它叫 Augmented Personal Telepresence Overlay System(如下圖)。那時,統一通信的概念已經比較普遍,每個人在自己的桌面上都可以發起實時通信,但體驗并不特別好。那時深度相機開始出現了,它通過對深度的獲取可以把人物分割出來,分割出來之后在桌面上進行視頻通話時可以把兩個人放到一個空間里。在這個項目里,每個人坐在自己的桌子前,通過深度相機將人從環境中分割出來之后,可以在電腦上看到兩個人坐在一張桌子上,但其實他們是在不同的屋子里。同時,支持屏幕共享,這讓沉浸感得到了提升。
圖:Augmented Personal Telepresence Overlay System
但是這個項目看起來還是在一個小屏幕上,它的沉浸感比較弱。那么我們能不能進一步提升沉浸式的體驗呢?
2012年,我們采用了更大的屏幕。這個屏幕就像一面墻,需要把人物的全身從背景中分割出來。那時深度學習沒有廣泛被大家了解,不像現在用深度學習進行圖像的分割已經非常普遍。那時的圖像分割比較困難,需要借助于一些手段對人的動態進行分割,才可以把它疊加在同一個背景下,這樣你站在這個大屏幕前,跟對方才有面對面、沉浸式的感受。
剛剛的項目雖然提供了一定的沉浸感,但是它無法提供六自由度。2013年、2014年,各類 AR、VR 設備陸續面市。而頭盔、眼鏡,彌補了這一特性,能提供更沉浸式的體驗。
我們怎樣把沉浸感的視頻通信實現出來呢?
2016年,微軟做了一個名為 Holoportation 的項目。通過這個眼鏡,我們配合采集3D的軟件進行實時建模,然后傳遞給對方,對方戴上眼鏡可以實現六自由的實時交互。在眼鏡中,另一個人是通過實時的3D 建模,在本地渲染出來的。
圖:微軟的Holoportation
這與以前 2D 時代非常不同,需要進行 3D 建模。在以前傳統的 2D 時代,我們會從一個角度,用一個攝像機,拍一個視頻,然后實時獲取到信息后,傳遞給對方,1分鐘內就可以重現它,并進行渲染。到了 3D 環境下,我們沒有辦法再利用一個攝像機,來獲取 人物的 3D 信息。如何獲取這個信息,變成了非常具有挑戰性的工作。
以前 2D 時,我們獲取的信息是像素,一個 XY 座標,座標上有 RGB 的信息,有了這個信息就可以得到完整的 2D 畫面。
但是到了 3D 時,信息變成了三維的,我們需要在三維坐標上要有色彩信息和其他屬性 信息,現在沒有一個手段能夠直接獲取它。當然,現在有很多種嘗試。我們現在的系統是試著實現多視角,要能同時從四面八方獲取信息,所以我們采用了八視角,有八組相機分布在人的周圍,進行實時的采集。
3D 的采集在很早以前就有。如果不是實時的,用幾百個攝像機,可以非常好的進行重建,但都是離線狀態下進行重建,需要很長時間。但是,我們要做到實時的采集、重建,非常困難。
我們簡單來講一下當時我們是如何來實現實時的 3D 的采集(如圖)。首先我們用了八組深度攝像機來進行采集,然后實時地生成點云信息。
在動態重建時,frame 之間的差別很大。如果 frame 與 frame 之間沒有一定約束的話,人們看到的圖像會抖動、晃動,效果會很差。如果要提升效果,就要有動態的約束。對于人物這種非剛性的物體進行實時重建,挑戰是非常大的。在這個重建過程中,我們是用八個攝像機獲取到的深度彩色圖,合成為當前 frame 的模型。而它與前一個 frame 需要進行空間的匹配,從前一個模型匹配到當前的模型。我們知道,在 2D 中,我們只需要計算運動矢量,但在 3D 中則需要進行矩陣的運算,空間搜索非常復雜。在完成匹配之后還需要進行融合,融合后形成當前 frame 的 3D 模型。然后,我們再從點云模型計算 Mesh。
紋理也很有挑戰性。我們有八個攝像機,它們從不同視角觀察同一個點的時候,由于光照不同、角度不同,它顏色、紋理都有差異。所以在這個過程中,還需要我們進行融合、優化,才能有比較平滑的視覺觀感。然后再進行傳輸。在傳輸時,我們也做了一些簡單的壓縮。比如我們將 3D 紋理轉為 2D ,再進行壓縮。在這個過程中,我們也做了很多工作,比如 frame 與 frame 之間如何匹配,才能使他們相關性更高,從而提升壓縮率。
以上就是我們所做過的一些嘗試。
其實,國際上有很多組織也在研究相關的技術標準。例如,MPEG 組織也在考慮未來的沉浸式信息,如何編碼、表示和傳輸。我們也正積極參與其中,與更多人共同探索。
目前 MPEG 正在做的就是 MPEG-I。它是針對未來沉浸式多媒體的格式、編碼、壓縮、傳輸等一系列的標準。大家可能了解的更多的就是與視頻相關的 MPEG-I Part3。實際上大家可以將它理解為 H.266,也就是 H.255 的下一代。它會更多地針對沉浸式媒體的壓縮。另一方面就是 MPEG-I Part5,即點云的壓縮。這與我們剛剛分享的項目非常相關。當你獲得了 3D 模型,怎么進行高效的壓縮、存儲、傳輸,國際上也有相應的標準化組織在共同探索如何來做。現在來講還屬于比較超前的研究,仍處于早期階段。這也是第一次在 MPEG 里嘗試做點云的標準化工作,預計在明年會有第一版的標準。
在點云壓縮標準中有兩個類別,第一種是對靜態的高質量 3D 模型進行壓縮;第二種是針對動態的 3D 模型進行壓縮;第三種則是針對邊采集邊生成點云時,如何來進行壓縮。其中第二種與我們正在做的項目更加相關。
在去年的一次 MPEG 的會議上,我們經過對比選擇了由蘋果提出一套基于視頻壓縮的方案,它是目前性能表現最好的。隨后我們各個公司也會基于這套方案來進行不同程度的改進,最終會形成一套標準。
這套壓縮方案是怎么做的呢?首先對一個動態的 3D 模型壓縮時,將它映射到 6 個 2D 平面上,然后再 patch 放在同一個 2D 的圖中,最后將 Patch 信息、紋理、色彩、空間數據等到一起,再進行編碼傳輸。
VPCC(Video Point Cloud Compression)編碼器端的基本工作流程是這樣的:首先進行映射,然后選取每個部分映射到哪一個面上,然后生成 patch 信息,用視頻的方法進行壓縮。因為在壓縮之后會有一定的誤差,所以要根據原來的 patch info 進行調整,也就是圖中的“smoothing”模塊。調整之后,再通過視頻的方法對它進行壓縮。
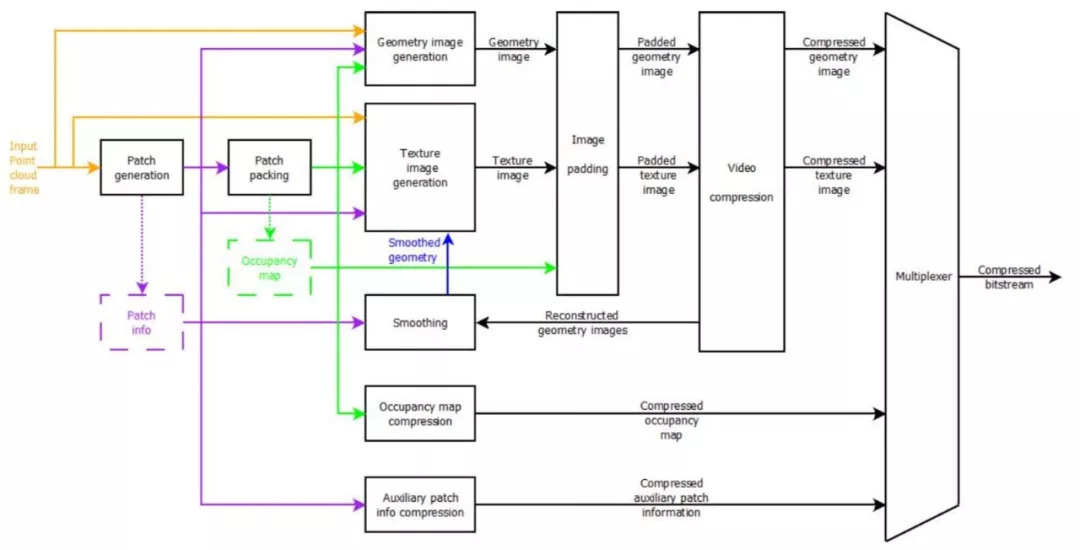
圖:編碼器架構

圖:解碼器架構
由于在 3D 上進行配準、深度計算等工作的復雜度非常高,所以現在我們在計算能力上海很難實現非常高精度的 3D 實時建模重建。但是隨著我們計算能力的不斷提升,以及深度學習的應用,可以進一步提升我們算法的性能。所以在未來會有更長足的發展。雖然動態的、高還原度的 3D 重建距離商業應用還有很長的距離。但回想我們在7、8年前做的圖像分割的技術,當時來看有很大的難度,但現在已經在手機中得到了廣泛應用。所以我們相信其中很多技術會逐步得到應用。
-
3D
+關注
關注
9文章
2911瀏覽量
108008 -
2D
+關注
關注
0文章
66瀏覽量
15244 -
視頻通信
+關注
關注
1文章
20瀏覽量
9194
原文標題:RTC 技術分享 | 從 2D 到 3D,沉浸式的實時視頻通信
文章出處:【微信號:shengwang-agora,微信公眾號:聲網Agora】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Dialog半導體推出首款2D到3D視頻轉換芯片,為智能手機
全球首款2D/3D視頻轉換實時處理芯片:DA8223
Lattice將在CES 2013上展示基于LatticeECP3的實時3D視頻轉換器
適用于顯示屏的2D多點觸摸與3D手勢模塊
如何把OpenGL中3D坐標轉換成2D坐標
阿里研發全新3D AI算法,2D圖片搜出3D模型
基于神經網絡的2D到3D的機器學習
探討一下2D和3D拓撲絕緣體
將2D/3D圖表和圖形添加到WindowsForms應用程序中
2D與3D視覺技術的比較
一文了解3D視覺和2D視覺的區別
有了2D NAND,為什么要升級到3D呢?

技術前沿:半導體先進封裝從2D到3D的關鍵





 工商網監
工商網監
評論