 一種通過引入硬注意力機制來引導學習視覺回答任務的研究
一種通過引入硬注意力機制來引導學習視覺回答任務的研究
【導讀】軟注意力機制已在計算機視覺領域取得了廣泛的應用和成功。但是我們發現硬注意力機制在計算機視覺任務中的研究還相對空白。而硬注意力機制能夠從輸入信息中選擇重要的特征,因此它被視為是一種比軟注意力機制更高效的方法。本次,將為大家介紹一種通過引入硬注意力機制來引導學習視覺回答任務的研究。此外結合L2 正則化篩選特征向量,可以高效地促進篩選的過程并取得更好的整體表現,而無需專門的學習過程。
摘要
生物感知中的注意機制主要是用于為復雜處理過程選擇感知信息子集,以對所有感官輸入執行禁止操作。軟注意力機制 (soft attention mechanism) 通過選擇性地忽略部分信息來對其余信息進行重加權聚合計算,已在計算機視覺領域取得了廣泛的應用和成功。然而,我們對于硬注意力機制 (hard attention mechanism) 的探索卻相對較少,在這里,我們引入一種新的硬注意力方法,它能夠在最近發布的一些視覺問答數據庫中取得有競爭力的表現,甚至在一些數據集中的性能超過了軟注意力機制。雖然硬注意力機制通常被認為是一種不可微分的方法,我們發現特征量級與語義相關性是相關的,并能為我們提供有用的信號來篩選注意力機制選擇標準。由于硬注意力機制能夠從輸入信息中選擇重要的特征,因此它被視為是一種比軟注意力機制更高效的方法,特別地對于最近研究中使用非局部逐對操作 (non-local pairwise) 而言,其計算和內存成本的消耗是巨大的。
簡介
視覺注意力有助于促進人類在復雜視覺推理多方面的能力。例如,對于需要在人群中識別出狗的任務,視覺系統能夠自適應地分配更多的計算處理資源,對狗及其潛在的目標或場景進行視覺信息處理。當觀察者正觀察場景中的其他目標,而未發覺到一些引人注目的實體時,這種感知效果將變得非常顯著。盡管注意力機制并不是計算機視覺領域中的一項變革性的技術,但由于許多計算機視覺任務,如檢測,分割和分類,并沒有涉及復雜的視覺推理過程,因此這種注意力機制對計算機視覺任務而言還是有幫助的。
視覺問答任務是一項需要復雜推理過程的視覺任務,在近些年得到廣泛的關注并取得了長足的進步。成功的視覺問答框架必須要能夠處理多個對象及其之間復雜的關系,同時還要能夠集成豐富的目標背景知識。我們意識到計算機視覺中的軟注意力機制主要是通過加權聚合部分重要信息來提高視覺處理的準確性,但對于計算機視覺中的硬注意力機制的研究相對空白。
在這里,我們探索一種簡單的硬注意力機制,來引導卷積神經網絡的特征表征:特征學習通常需要為硬注意力的選擇提供一種簡單的訪問信號。特別地,用 L2 正則化篩選這些特征向量已被驗證是一種有助于硬注意力機制的方法,它能夠高效地促進篩選的過程并取得更好的整體表現,而無需專門的學習過程。下圖1展示了這種方法的結果。注意力信號直接源自于標準的監督任務損失函數,而無需任何明確的監督信號來激活正則化,也無需其他潛在的措施。
圖1 基于給定的自然圖像和文本問題輸入,我們的視覺問答架構得到的輸出結果圖。這里,我們使用了一種硬注意機制,只對那些重要的視覺特征進行選擇并處理。基于我們模型結構,正則化后視覺特征的相關性以及那些具有高度相關性并包含重要語義內容的特征向量的前提,生成我們的注意力圖像。
此外,通過對特征向量的 L2 正則化處理來選擇重要性特征,我們的視覺問答框架進一步采用硬注意力機制進行增強。我們將最初的版本成為硬注意力網絡 HAN (Hard Attention Network),用于通過頂層正則化項來選擇固定數量的特征向量。第二個版本我們稱之為自適應的硬注意力網絡 AdaHAN (Hard Hard Attention Network),這是基于輸入來決定特征向量的可變數量的一種網絡結構。我們在大量的數據集上評估我們的方法,實驗結果表明我們的算法能夠在多個視覺問答數據及上實現與軟注意力機制相當的性能。此外,我們的方法還能產生可解釋的硬注意力掩模,其中所選的圖像特征區域通常包含一些相應的重要語義信息,如一些連貫的對象。相比于非局部成對模型,我們的方法也能取得相當出色的表現。
方法
下圖2展示了我們提出的用于學習從圖像和問題映射到答案的模型結構。我們用卷積神經網絡 (CNN) 對圖像進行編碼(在這里采用的是預訓練的 ResNet-101 模型,或是從頭開始訓練小型的 CNN 模型),并用 LSTM 將問題編碼為一個固定長度的矢量表征。通過將答案復制到 CNN 模型中每個空間位置并將其與視覺特征相連接,我們計算得到組合表征。經過幾層組合處理后,我們在空間位置上引入注意力機制,這與先前研究中引入軟注意力機制的過程是一致的。最后,我們將特征聚合,并使用池化和 (sum-pooling) 或關系模塊 (relational modules),通過計算答案類別的標準邏輯回歸損失來端到端地訓練整個網絡。
圖2 我們在模型中引入硬注意力機制來代替軟注意力機制,并遵循標準視覺問答框架的其他結構。圖像和問題都被編碼成各自的矢量表征。隨后,空間視覺特征的編碼被進一步表示,而問題嵌入相應地通過傳播和連接 (或添加) 以形成多模式輸入表征。我們的注意力機制能夠有選擇性地選擇用于下一次聚合和處理多模式向量的應答模塊。
▌1.硬注意力機制
我們引入了一種新的硬注意力機制,它在空間位置上產生二進制掩碼,并確定用于下一步處理的特征選擇。我們將我們的方法稱為硬注意力網絡 (HAN),其核心在于對每個空間位置使用 L2 正則化激活以生成該位置相關性。L2 范數和相關性之間的關系是 CNN 訓練特征的一種新屬性,這不需要額外的約束或目標。我們的結構也只是對這種現象進行引導而沒有明確地訓練該網絡。
因此,與軟注意力機制相比,我們的方法不需要額外的參數學習。HAN 只需要一個額外的、可解釋的超參數:即輸入單元所使用的稀疏,也是用于權衡訓練速度和準確性的參數。
▌2.特征聚合
池化和在引入注意力機制后,減少特征矢量的一種簡單方法是將其進行池化和操作以生成長度固定的矢量。在注意力權重向量為 w 的軟注意力條件下,我們很容易計算得到向量的池化和。在硬注意力條件下,基于選擇的特征,我們也可以由此類比地計算。
非局部逐對操作 為進一步改善池化和的性能,我們探索一種與通過非局部成對計算來演繹推理相類似的方法。其數學描述如下:
在這里,softmax 函數作用于所有的 i, j 位置。我們的方法能夠成對地計算非局部嵌入之間的關系,獨立于空間或時間的近似度。硬注意力機制能夠幫助我們減少所要考慮的設置,因此我們的目標在于測試通過硬注意力選擇的特征是否能與此操作相兼容。
實驗
為了展示硬注意力機制對視覺問答任務的重要性,我們首先在 VQA-CP v2 數據集上,將 HAN 與現有的軟注意力網絡 SAN 進行比較分析,并通過卷積映射直接控制空間單元出現的數量來探索不同程度的硬注意力的影響。隨后,我們評估 AdaHAN 模型并研究網絡深度和預訓練策略的影響,這是一種能夠自適應地選擇單元出現數量的一種模型。最后,我們展示了定性的實驗結果,并提供了在 CLEVR 數據集上的結果,以表明我們方法的通用性。
▌1.實驗細節
我們的模型都使用相同的 LSTM 模型用于問題嵌入,其大小為512,并采用在ImageNet 數據集上預訓練的 ResNet-101 模型的最后一個卷積層 (能夠產生10×10空間表征,每個具有2048個維度),用于圖像嵌入。此外,我們還使用3層大小分別為1024、2048、1000的 MLP 結構,作為一個分類模型。我們使用 ADAM 進行優化,采用分布式設置,以128每批次大小來計算梯度值,并根據經驗在Visual QA數據集上選擇默認的超參數。
▌2.數據集
VQA-CP v2 數據集的結果:VQA-CP v2 數據集包含 121K (98K) 張圖像數據,438K (220K) 條問題數據以及 4.4M (2.2M) 答案數據。該數據集提供了標準的訓練測試過程,并將問題分解為不同的類型:如答案為肯定/否定類型,答案是數字類型,以及其他類型等,這有助于我們用每種問題類型準確性來評估網絡架構的性能。
CLEVR:CLEVR 是一個合成數據庫,由 100K 張 3D 渲染圖像組成,如球體、圓柱體等。雖然視覺任務相對簡單,但解決這個數據集也需要推理目標間的復雜關系。
▌3.結果分析
硬注意力機制的影響
我們考慮最基礎的硬注意力結構:采用硬注意力機制,并對每個出現單元進行池化和操作,最后連接一個小型的 MLP 結構。下表1展示了我們的實驗結果。可以看到,引入硬注意力機制不僅不會丟失特征的重要信息,還能在較少出現單元的情況下,取得相當的性能結果,這表明了這種機制是圖像的重要部分。此外,在表1下面我們還與軟注意力機制進行了對比,可以發現軟注意力機制的表現并不優于我們的方法。
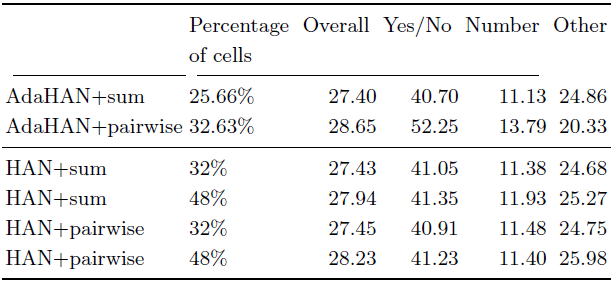
表1 不同出現單元數量和聚合操作的性能比較。我們考慮簡單的和操作和非局部成對計算作為特征聚合的工具。
自適應硬注意力機制的結果
下表2展示了自適應硬注意力機制的實驗結果。我們可以看到,自適應機制使用非常少的單元:進行池化和計算時,只使用100個單元中的25.66個,而進行非局部成對聚合時,則只有32.63個單元被使用。這表明即便非常簡單的自適應方法,也能給圖像和問題的解決可以帶來計算和性能方面的提升,這也說明更復雜的方法將是未來工作的重要方向。
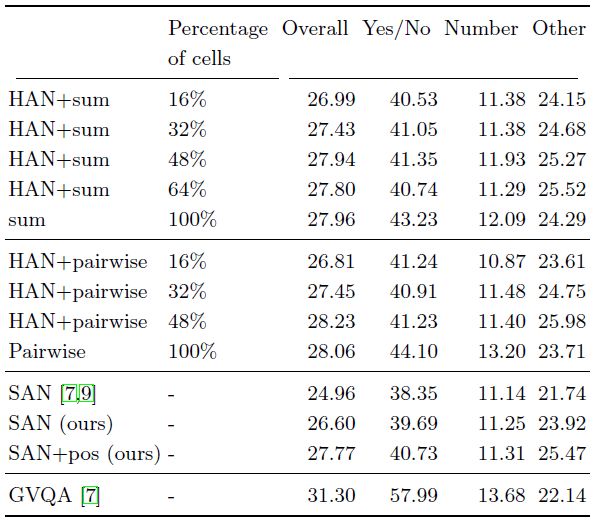
表2 不同自適應硬注意力技術、單元出現的平均數量和聚合操作的性能對比。我們考慮一種簡單的和操作和非局部成對聚合操作。
此外,下表3展示了移除兩層結構后自適應硬注意力機制的性能表現。可以看到,移除這些層后,模型的表現下降了約1%,這表明了決定單元出現與否需要不同的信息,這不同于 ResNet 模型的分類微調設計,同時也說明了深度對于自適應機制的影響。
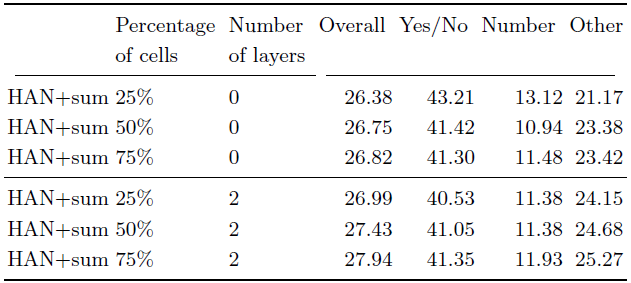
表3 在 VQA-CP v2 數據集上不同單元出現數量的性能比較。其中第二列表示輸入單元出現的百分比,而第三列代表 MLP 結構的層數。
定性結果及 CLEVR 數據集結果
下圖3、圖4展示了我們方法的定性實驗結果。圖3展示了采用不同硬注意力機制(HAN、AdaHAN)、不同聚合操作 (和操作、逐對操作) 的實驗結果。而圖4展示了采用最佳的模型設置:自適應硬注意力機制加上非局部逐對聚合操作 (AdaHAN+pairwise),在 VQA-CP 數據集上的實驗結果。
圖3 不同硬注意力機制和不同聚合方法變體的定性結果
圖4 AdaHAN+pairwise 的定性結果
此外,我們還進一步在 CLEVR 數據集上驗證我們方法的通用性,其他的設置與 VQA-CP 數據集上相類似。下圖5展示了兩種方法的實驗結果。
圖5 在 CLEVR 數據集上相同超參數設置,不同方法的驗證精度結果。(a) HAN+RN (0.25的輸入單元) 和 標準的 RN 結構 (全輸入單元),訓練12個小時來測量方法的有效性。(b) 我們的硬注意力方法。
結論
我們已經引入了一種新的硬注意力方法用于計算機視覺任務,它能夠選擇用于下一步處理的特征向量子集。我們探索了兩種模型:一個選擇具有預定義向量數量的 HAN 模型,另一個自適應地選擇子集大小作為輸入的 AdaHAN。通過特征向量數量與相關信息的相關性,我們的注意力機制能夠解決文獻中現有方法存在的梯度問題。經過大量的實驗評估,結果表明了在具有挑戰性的 Visual QA 數據集上,我們的 HAN 和 AdaHAN 模型能夠取得有競爭力的性能表現,并在某些時候取得相當甚至超過軟注意力機制的表現,同時還能提供額外的計算效率優勢。最后,我們還提供了可解釋性表示,即對所選特征的空間位置中相應貢獻最大、最顯著的部分進行了可視化。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101166 -
圖像
+關注
關注
2文章
1089瀏覽量
40572 -
數據庫
+關注
關注
7文章
3846瀏覽量
64685
原文標題:如何通過引入硬注意力機制來學習視覺問答任務?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
DeepMind為視覺問題回答提出了一種新的硬注意力機制
注意力機制或將是未來機器學習的核心要素
基于注意力機制的深度學習模型AT-DPCNN

一種注意力增強的自然語言推理模型aESIM

基于層次注意力機制的多模態圍堵情感識別模型

基于多層CNN和注意力機制的文本摘要模型

基于層次注意力機制的多任務疾病進展模型
結合注意力機制的跨域服裝檢索方法
一種新的深度注意力算法

基于YOLOv5s基礎上實現五種視覺注意力模塊的改進
一種基于因果路徑的層次圖卷積注意力網絡






 工商網監
工商網監
評論