") 如何基于Keras和Tensorflow用LSTM進(jìn)行時間序列預(yù)測
如何基于Keras和Tensorflow用LSTM進(jìn)行時間序列預(yù)測
編者按:本文將介紹如何基于Keras和Tensorflow,用LSTM進(jìn)行時間序列預(yù)測。文章數(shù)據(jù)來自股票市場數(shù)據(jù)集,目標(biāo)是提供股票價格的動量指標(biāo)。
GitHub:github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction
什么是LSTM?
自提出后,傳統(tǒng)神經(jīng)網(wǎng)絡(luò)架構(gòu)一直沒法解決一些基礎(chǔ)問題,比如解釋依賴于信息和上下文的輸入序列。這些信息可以是句子中的某些單詞,我們能用它們預(yù)測下一個單詞是什么;也可以是序列的時間信息,我們能基于時間元素分析句子的上下文。
簡而言之,傳統(tǒng)神經(jīng)網(wǎng)絡(luò)每次只會采用獨(dú)立的數(shù)據(jù)向量,它沒有一個類似“記憶”的概念,用來處理和“記憶”有關(guān)各種任務(wù)。
為了解決這個問題,早期提出的一種方法是在網(wǎng)絡(luò)中添加循環(huán),得到輸出值后,它的輸入信息會通過循環(huán)被“繼承”到輸出中,這是它最后看到的輸入上下文。這些網(wǎng)絡(luò)被稱為遞歸神經(jīng)網(wǎng)絡(luò)(RNN)。雖然RNN在一定程度上解決了上述問題,但它們還是存在相當(dāng)大的缺陷,比如在處理長期依賴性問題時容易出現(xiàn)梯度消失。
這里我們不深入探討RNN的缺陷,我們只需知道,既然RNN這么容易梯度消失,那么它就不適合大多數(shù)現(xiàn)實(shí)問題。在這個基礎(chǔ)上,Hochreiter&Schmidhuber于1997年提出了長期短期記憶網(wǎng)絡(luò)(LSTM),這是一種特殊的RNN,它能使神經(jīng)元在其管道中保持上下文記憶,同時又解決了梯度消失問題。具體工作原理可讀《一文詳解LSTM網(wǎng)絡(luò)》。
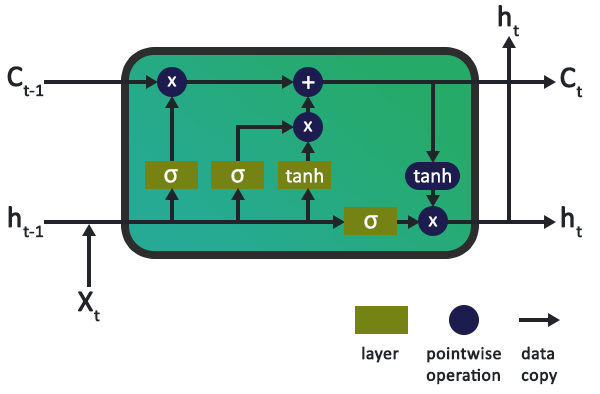
上圖是LSTM的一個典型內(nèi)部示意圖,它由若干節(jié)點(diǎn)和若干操作組成。其中,操作充當(dāng)輸入門、輸出門和遺忘門,為節(jié)點(diǎn)狀態(tài)提供信息。而節(jié)點(diǎn)狀態(tài)負(fù)責(zé)在網(wǎng)絡(luò)中記錄長期記憶和上下文。
一個簡單的正弦曲線示例
為了演示LSTM在預(yù)測時間序列中的作用,我們先從最基礎(chǔ)的開始:一個時間序列——標(biāo)準(zhǔn)正弦曲線。
代碼數(shù)據(jù)文件夾中提供的數(shù)據(jù)包含我們創(chuàng)建的sinewave.csv文件,該文件包含5001個正弦曲線時間段,幅度和頻率為1(角頻率為6.28),時間差為0.01。它的圖像如下所示:
正弦曲線數(shù)據(jù)集
有了數(shù)據(jù),接下來就是實(shí)現(xiàn)目標(biāo)。在這個任務(wù)中,我們希望LSTM能根據(jù)提供的數(shù)據(jù)學(xué)習(xí)正弦曲線,并預(yù)測此后的N步,持續(xù)輸出曲線。
為了做到這一點(diǎn),我們需要先對CSV文件中的數(shù)據(jù)進(jìn)行轉(zhuǎn)換,把處理后的數(shù)據(jù)加載到pandas的數(shù)據(jù)框架中。之后,它會輸出numpy數(shù)組,饋送進(jìn)LSTM。Keras的LSTM一般輸入(N, W, F)三維numpy數(shù)組,其中N表示訓(xùn)練數(shù)據(jù)中的序列數(shù),W表示序列長度,F(xiàn)表示每個序列的特征數(shù)。
在這個例子中,我們使用的序列長度是50(讀取窗口大小),這意味著網(wǎng)絡(luò)能在每個序列中都觀察到完整的正弦曲線形狀,便于學(xué)習(xí)。
序列本身是滑動窗口,因此如果我們每次只移動1,所得圖像其實(shí)和先前的圖像是完全一樣的。下面是我們在示例中截取的窗口圖像:
為了加載這些數(shù)據(jù),我們在代碼中創(chuàng)建了一個DataLoader類。你可能會注意到,在初始化DataLoader對象時,會傳入文件名、傳入確定用于訓(xùn)練與測試的數(shù)據(jù)百分比的拆分變量,以及允許選擇一列或多列數(shù)據(jù)的列變量用于單維或多維分析。
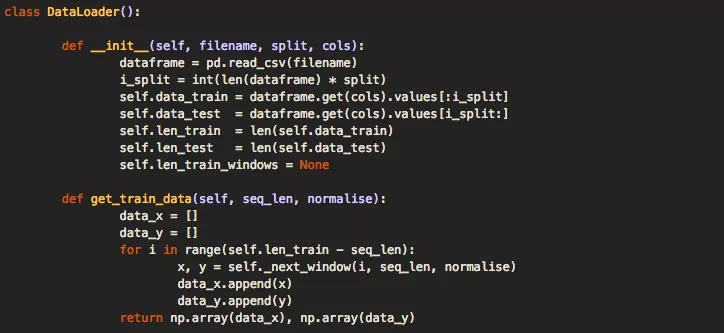
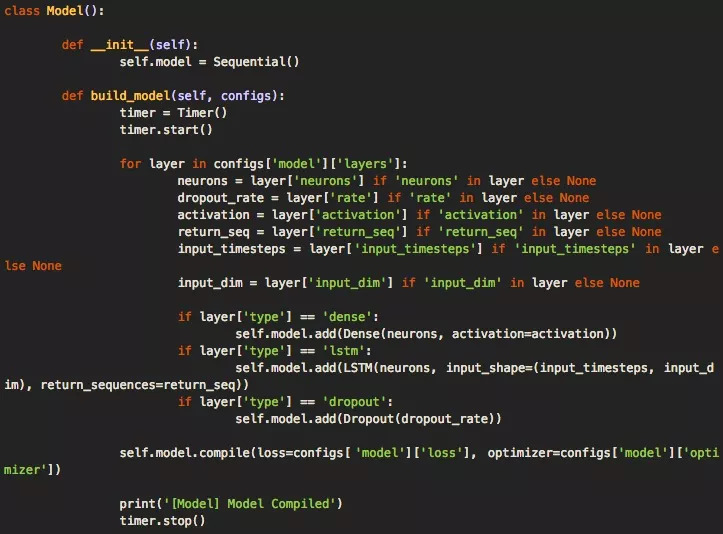
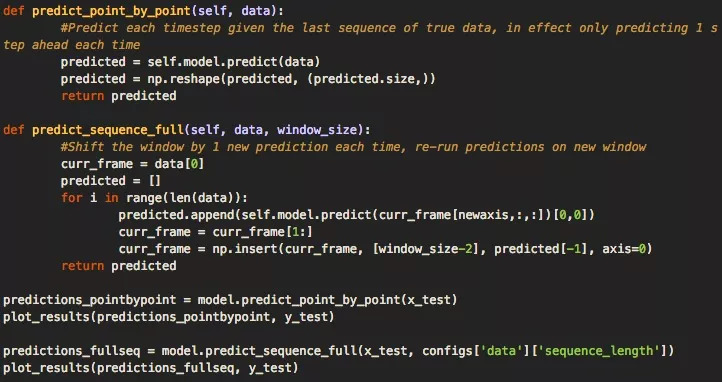
當(dāng)我們有一個允許加載數(shù)據(jù)的數(shù)據(jù)對象之后,就是時候準(zhǔn)備構(gòu)建深層神經(jīng)網(wǎng)絡(luò)模型了。我們的代碼框架利用模型類型和config.json文件,再加上存儲在配置文件中的架構(gòu)和超參數(shù),可以輕松構(gòu)建出模型。其中執(zhí)行構(gòu)建命令的主要函數(shù)是build_model(),它負(fù)責(zé)接收解析的配置文件。
這個函數(shù)的代碼如下所示,它可以輕松擴(kuò)展,以便用于更復(fù)雜的架構(gòu)。
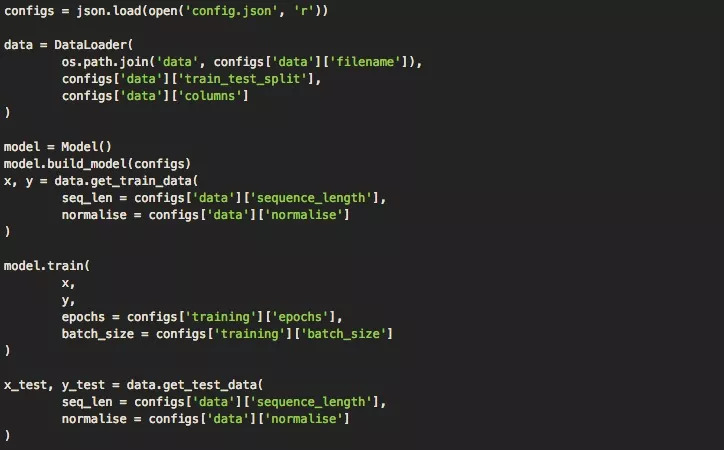
加載數(shù)據(jù)并建立模型后,現(xiàn)在我們可以用訓(xùn)練數(shù)據(jù)訓(xùn)練模型。如下代碼所示,我們創(chuàng)建了一個單獨(dú)的運(yùn)行模塊,它會利用我們的模型和DataLoader一起訓(xùn)練,輸出預(yù)測結(jié)果和可視化。
對于輸出,我們會進(jìn)行兩種類型的預(yù)測:一是逐點(diǎn)預(yù)測,即先讓模型預(yù)測單個點(diǎn)的值,在圖中繪出位置,然后移動滑動窗口,用完整的測試數(shù)據(jù)預(yù)測下個點(diǎn)的值。二是預(yù)測一個完整序列,即只用訓(xùn)練數(shù)據(jù)的第一部分初始化一次訓(xùn)練窗口,然后就像逐點(diǎn)預(yù)測一樣,不斷移動滑動窗口并預(yù)測下一個點(diǎn)。
和第一種做法不同的是,第二種做法是在用預(yù)測所得的數(shù)據(jù)進(jìn)行預(yù)測,即在第二次預(yù)測時,模型所用數(shù)據(jù)中有一個數(shù)據(jù)點(diǎn)(最后一個點(diǎn))來自之前的預(yù)測;第三次預(yù)測時,數(shù)據(jù)中就有兩個點(diǎn)來自之前的預(yù)測……以此類推,到第50次預(yù)測時,測試集里的數(shù)據(jù)已經(jīng)完全是預(yù)測的數(shù)據(jù)。這意味著模型可預(yù)測的時間序列被大大延長。
逐點(diǎn)預(yù)測結(jié)果
完整序列預(yù)測結(jié)果
作為參考,你可以在下面的配置文件中看到用于正弦曲線示例的網(wǎng)絡(luò)架構(gòu)和超參數(shù)。
我們可以從上面兩幅圖中發(fā)現(xiàn),如果用第二種方法進(jìn)行預(yù)測,隨著測試集中被不斷加入新的預(yù)測數(shù)據(jù)點(diǎn),模型的性能會漸漸下降,預(yù)測結(jié)果和真實(shí)結(jié)果的誤差越來越大。但正弦函數(shù)是一個非常簡單的零噪聲震蕩函數(shù),總體來看,我們的模型在沒有過擬合的同時還是能很好的模型曲線大致情況的。
接下來,就讓我們在股票數(shù)據(jù)上試試LSTM。
沒那么簡單的股票市場
很多股民都做過這樣一個夢:如果我能準(zhǔn)確預(yù)測大盤走向,那一夜暴富豈不是手到擒來?但一覺醒來,現(xiàn)實(shí)是殘酷的,預(yù)測這件事并不像數(shù)字模擬那么簡單。
和正弦曲線不同,股票市場的時間序列并不是某個特定靜態(tài)函數(shù)的映射,它最明顯的屬性是隨機(jī)性。真正的隨機(jī)是不可預(yù)測的,也沒有預(yù)測的價值,但是,很多人相信股票市場不是一個純粹的隨機(jī)市場,它的時間序列可能存在某種隱藏模式。而根據(jù)上文的介紹,LSTM無疑是捕捉這種長期依賴關(guān)系的一個好方法。
下文使用的數(shù)據(jù)是Github數(shù)據(jù)文件夾中的sp500.csv文件。此文件包含2000年1月至2018年9月的標(biāo)準(zhǔn)普爾500股票指數(shù)的開盤價、最高價、最低價、收盤價以及每日交易量。
在第一個例子中,正弦曲線的取值范圍是-1到1,這和股票市場不同,收盤價是個不斷變化的絕對價格,這意味著如果我們不做歸一化處理就直接訓(xùn)練模型,它永遠(yuǎn)不會收斂。
為了解決這個問題,我們設(shè)訓(xùn)練/測試的滑動窗口大小為n,對每個窗口進(jìn)行歸一化,以反映從該窗口開始的百分比變化。
n = 價格變化的歸一化列表[滑動窗口]
p = 調(diào)整后每日利潤的原始列表[滑動窗口]
歸一化:ni= pi/p0- 1
反歸一化:pi= p0( ni+ 1)
處理完數(shù)據(jù)后,我們就可以和之前一樣運(yùn)行模型。但是,我們做了一個重要的修改:不使用model.train() ,而是用model.traingenerator()。這樣做是為了在處理大型數(shù)據(jù)集時節(jié)約內(nèi)存,前者會把完整數(shù)據(jù)集全部加載到內(nèi)存中,然后一個窗口一個窗口歸一化,容易內(nèi)存溢出。此外,我們還調(diào)用了Keras的fitgenerator()函數(shù),用python生成器動態(tài)訓(xùn)練數(shù)據(jù)集來繪制數(shù)據(jù),進(jìn)一步降低內(nèi)存負(fù)擔(dān)。
在之前的例子中,逐點(diǎn)預(yù)測的結(jié)果比完整序列預(yù)測更精確,但這有點(diǎn)欺騙性。在這種情況下,除了預(yù)測點(diǎn)和最后一次預(yù)測的數(shù)據(jù)點(diǎn)之間的距離,神經(jīng)網(wǎng)絡(luò)其實(shí)不需要了解時間序列本身,因?yàn)榧幢闼@次預(yù)測錯誤了,在進(jìn)行下一次預(yù)測時,它也只會考慮真實(shí)結(jié)果,完全無視自己的錯誤,然后繼續(xù)產(chǎn)生錯誤預(yù)測。
雖然這聽起來不太妙,但其實(shí)這種方法還是有用的,它至少能反映下一個點(diǎn)的范圍,可用于波動率預(yù)測等應(yīng)用。
逐點(diǎn)預(yù)測結(jié)果
接著是完整序列預(yù)測,在正弦曲線那個例子中,這種方法的偏差雖然越來越大,但它還是保留了整體波動形狀。如下圖所示,在復(fù)雜的股票價格預(yù)測中,它連這個優(yōu)勢都沒了,除了剛開始橙線略有波動,它預(yù)測的整體趨勢是一條水平線。
完整序列預(yù)測結(jié)果
最后,我們對該模型進(jìn)行了第三種預(yù)測,我將其稱為多序列預(yù)測。這是完整序列預(yù)測的混合產(chǎn)物,因?yàn)樗匀皇褂脺y試數(shù)據(jù)初始化測試窗口,預(yù)測下一個點(diǎn),然后用下一個點(diǎn)創(chuàng)建一個新窗口。但是,一旦輸入窗口完全由過去預(yù)測點(diǎn)組成,它就會停止,向前移動一個完整的窗口長度,用真實(shí)的測試數(shù)據(jù)重置窗口,然后再次啟動該過程。
實(shí)質(zhì)上,這為測試數(shù)據(jù)提供了多個趨勢線預(yù)測,以便我們評估模型對未知數(shù)據(jù)的預(yù)測性能。
多序列預(yù)測結(jié)果
如上圖所示,神經(jīng)網(wǎng)絡(luò)似乎正確地預(yù)測了絕大多數(shù)時間序列的趨勢(和趨勢幅度),雖然不完美,但它確實(shí)表明LSTM在時間序列問題中確實(shí)有用武之地。
結(jié)論
雖然本文給出了LSTM應(yīng)用的一個示例,但它只觸及時間序列預(yù)測問題的表面。現(xiàn)如今,LSTM已成功應(yīng)用于眾多現(xiàn)實(shí)問題,從文本自動糾正、異常檢測、欺詐檢測到自動駕駛汽車技術(shù)開發(fā)。
它還存在一些局限性,特別是在金融時間序列任務(wù)上,通常這類任務(wù)很難建模。此外,一些基于注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)也開始在其他任務(wù)上表現(xiàn)出超越LSTM的性能。
但截至目前,LSTM相比傳統(tǒng)神經(jīng)網(wǎng)絡(luò)還是進(jìn)步明顯,它能夠非線性地建模關(guān)系并以非線性方式處理具有多個維度的數(shù)據(jù),這是幾十年前的人們夢寐以求的。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101169 -
keras
+關(guān)注
關(guān)注
2文章
20瀏覽量
6096 -
rnn
+關(guān)注
關(guān)注
0文章
89瀏覽量
6914
原文標(biāo)題:基于LSTM深層神經(jīng)網(wǎng)絡(luò)的時間序列預(yù)測
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
TensorFlow常用Python擴(kuò)展包
介紹有關(guān)時間序列預(yù)測和時間序列分類
怎樣去搭建一套用于多步時間序列預(yù)測的LSTM架構(gòu)?
自回歸滯后模型進(jìn)行多變量時間序列預(yù)測案例分享
基于SARIMA、XGBoost和CNN-LSTM的時間序列預(yù)測對比
小波回聲狀態(tài)網(wǎng)絡(luò)的時間序列預(yù)測
Keras和TensorFlow究竟哪個會更好?
TensorFlow和Keras哪個更好用?
如何用Python進(jìn)行時間序列分解和預(yù)測?

融合EMD與LSTM網(wǎng)絡(luò)的頻譜占用度預(yù)測模型
基于TensorFlow和Keras的圖像識別






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論