 遷移學習、多任務學習領域的進展
遷移學習、多任務學習領域的進展
【導讀】如今 ICML(International Conference on Machine Learning,國際機器學習大會)已經成為有巨大影響力的會議,每年都會為我們帶來很多關于機器學習趨勢與發展方向等有意義的分享。今年的 ICML 有三個討論會都重點討論了遷移學習和多任務學習。
本文的作者(Isaac Godfried)也是對這兩個領域的研究內容非常感興趣,接下來 AI科技大本營將把Isaac Godfried在這次大會上的一些見聞介紹給大家。
對于深度學習來說,若缺少大量帶標簽的高質量數據,會帶來較大的困難。許多任務都全面缺乏數據點(如:預測選舉結果、診斷罕見的疾病、翻譯稀有語種等等)。還有一些情況,數據量是足夠的,但數據噪聲很大,或標簽的質量很低(如:通過關鍵詞搜索從 Google 抓取的圖片、通過 NLP 技術制定標簽的醫療案例、只有部分注釋的文本語料庫)。但不管怎樣,找到合適的方法去學習這些低質量或有噪聲的數據都具有切實的意義。
可行的三種方法有遷移學習、多任務學習(從技術角度來講,這個方法是一種類似領域自適應的遷移學習,但在本文中我會將它們看作不同的方法來討論)以及半監督學習。還有一些其他的解決方法(主動學習、元學習、無監督學習),但本文會以 ICML 參會文章提到的三種方法為重點。由于這些方法處于領域間的邊界,我們會也會涉及一些其它的方法,在這里先做一個簡單的概述。
遷移學習
微調:假設我們同時有源分布和目標分布 S(y|x) 和 T(y2|x2),此處 x ≠ x2,y1 ≠ y2。若要進行微調,你必須具備目標域的標簽數據。通過遷移學習,我們固定網絡的淺層和中間層,只對深層特別是新類別進行微調。
多任務學習:假設我們有任務 T1、T2、T3 ... Tn;這些任務同時進行訓練,例如:訓練一個同時做情緒分類和命名實體識別的多任務網絡。這是遷移學習的形式之一,因為從本質上來看,訓練過程中你是在進行知識的遷移。
域自適應:與微調很相似,唯一不同是這里是域的改變而非標簽集。所以若給定兩種分布 S(y|x) 和 T(y|x2) x ≠ x2,但 y 是相同的。域自適應會著重于目標域中無標簽數據的無監督學習。例如:適應從模擬器(源域)的有標簽汽車圖片到街道上(目標域)的無標簽汽車圖片的模型。
元學習(終身學習):元學習的目標是學習可以高度適應新任務的“通用”屬性(超參數或權重),它的學習過程基于大量不同任務的訓練。某種程度上,元學習可以被看作一種“歷史性的”多任務學習,因為它基于多種不同的任務去尋找最合適的一組屬性。由于多任務學習始終高度依賴于模型本身,所以近期元學習的趨勢更加偏向于找到一種“與模型無關”的解決方法。
無論在什么產業或領域,遷移學習和多任務學習都是非常重要的工具。無論你從事醫學、金融、旅游或是創作,也無論你與圖像、文本、音頻還是時間序列數據打交道,這些都是機會,你可以利用已經訓練好的通用模型,然后將其引入你的特定領域進行微調。基于你的數據,你可以訓練神經網絡去同時解決多個相關任務,從而提高整體性能。
在那些專注于醫學領域的深度學習論文中,有一篇題目為 “Not to Cry Wolf: Distantly Supervised Multitask Learning Critical Care”的論文。在重癥監護室中,常常有錯誤警報問題,所以很多醫生和護士可能對此變得不再敏感。這篇文章重點介紹如何利用多任務學習和半監督學習來監測有生命危險的事件,而避免錯誤的警報。該論文的作者將輔助任務引入到多任務學習中,無需花時間去打標簽就可以提高模型的性能。特別要提的是,為了真正減少訓練所需的標簽數目,他們的模型引入了大量不相關的有監督輔助任務。另外,他們開發了一種針對不相關的多任務有監督學習的新方法,無論是面對多變量的時間序列,還是對有標簽和無標簽數據結合起來學習,該方法都能自動識別大量相關的輔助任務。
論文鏈接:
https://arxiv.org/abs/1802.05027
談論會視頻(待放)
如果我們想使用多任務學習,但只有一個任務,該怎么辦呢?一篇名為 “Pseudo-task Augmentation: From Deep Multitask Learning to Intratask Sharing?—?and Back”的論文對這一問題給出了答案。作者提出利用偽任務來幫助提升主任務的表現。這一方案是可行的,因為從本質上來看,多任務學習的工作原理基于中間層和淺層的特征共享以及特定任務的解碼器。因此,使用多種解碼器來訓練模型可以有相同的效果,即使解碼器都在為同一個任務工作,這是因為每個解碼器是通過不同方式學習該任務的;這些附加的解碼器被稱為“偽任務”。該論文的作者在 CelebrityA 數據集上得出了當前最好的結果。我很期待能看到他們能用 IMDB 的評價數據集測試一下該方法。他們基于一個基礎模型,通過自主開發的技術進行訓練,從而得到了巨大的提升。這體現了該項技術有應用于不同神經網絡結構的潛能。
論文鏈接:
https://arxiv.org/abs/1803.04062
而“GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks”這篇論文闡述了一種新的多任務神經系統正規化技術,可以幫助神經系統更快地收斂,提升整體性能。該技術也減少了調參所需的超參數數目,僅需要一個。該論文團隊使用梯度量化自動均衡算法(GradNorm)在 NYU2 數據集上得出了當前最好的結果。總體來說,該論文真正減小了訓練 MLT 算法模型的復雜度與難度。最后,該作者提出了一個有趣的想法,“GradNorm 或許也可以應用于多任務學習以外的領域。我們希望將 GradNorm 算法拓展到類別平衡與 seq2seq 模型上,以及所有由梯度沖突而引發模型性能不佳的問題。”
論文鏈接:
https://arxiv.org/abs/1711.02257
到目前為止,大多數有關遷移學習的論文都只研究了從源域到目標域的知識遷移,通過預先初始化權重并保留部分層或降低學習率的方法來實現。可以說論文“Transfer Learning via Learning to Transfer”完美地闡釋了什么是“元-遷移學習”(meta-transfer learning) 或者說"學習如何遷移學習" (即 L2T, learn to teach)。
論文中用以描述 L2T 工作流程的圖片
作者是這樣解釋的:
不像 L2T,所有現有的遷移學習算法研究的都是從零開始遷移,例如:只考慮一對興趣領域,而忽略了之前的遷移學習經驗。但不如這樣,L2T 框架能夠將所有算法的智慧集于一身,上面提到的任何一種算法都可以應用到遷移學習經驗之中。
論文鏈接:
http://proceedings.mlr.press/v80/wei18a/wei18a.pdf
那么現在問題來了,這一方法與“元學習”有何不同呢?實際上,L2T 可以被看作一種特殊的元學習:和元學習相同的是,它利用過去的歷史經驗來提升學習能力。然而,這里的歷史指的是從源域到目標域的遷移學習。
論文中引用的不同學習方法對比圖
該論文作者基于 Caltech-256 數據集對 L2T 框架進行了評估,模型在此前最好結果的基礎上有所提升。
我(本文作者)個人很高興看到 “Explicit Inductive Bias for Transfer Learning with Convolutional Networks”被選入 ICML,此前該論文被 ICLR(International Conference on Learning Representations)拒掉了。這篇論文描述了一種將正規化應用于遷移學習從而代替修改學習率的方法。研究者提出了幾種新的正規化方法,可以基于預先訓練好的模型的權重使用不同的懲罰項。他們得到了很好的實驗結果,目前我也正在嘗試把這一方法應用到我自己的幾個醫學影像模型中。
論文鏈接:
https://arxiv.org/abs/1802.01483
“Curriculum Learning by Transfer Learning: Theory and Experiments with Deep Networks”是一篇以理論為主的論文,對“課程學習” (curriculum learning) 進行了深入研究,這一說法來源于教育和心理學領域,其目的是在有一定發展前提的規則下,學習更多不同的概念。該論文還特別關注了遷移學習和課程學習之間的關系,以及課程學習和訓練所用到例子的順序之間的關系。這里要注意的一點是,這種類型的遷移與之前討論的類型有所不同。在這篇論文中,遷移學習指的是研究“知識從一個分類器到另一個分類器的遷移,如從老師分類器到學生分類器”。作者得出的結論是,課程學習使學習速率加快了,特別在處理困難的任務時,最終結果的提升尤為明顯。
論文鏈接:
https://arxiv.org/pdf/1802.03796.pdf
(無監督)域自適應的問題之一是目標域與源域的分布的一致性問題。無監督域自適應是遷移學習的類型之一。由此作者通過保證有標簽樣本和偽標簽樣本的一致性,開發了一種可以學習無標簽目標樣本語義表達的語義遷移網絡。(論文“Learning Semantic Representations for Unsupervised Domain Adaptation”)他們的方法通過基于語義損失函數來減小源域和目標域的差異的方法,使源分布和目標的分布一致。該方法在 ImageCLEF-DA 和 Office31 數據集上都取得了當前世界上最好的表現。
論文中的用圖
論文鏈接:
http://proceedings.mlr.press/v80/xie18c/xie18c.pdf
github 地址:
https://github.com/Mid-Push/Moving-Semantic-Transfer-Network
論文“Detecting and Correcting for Label Shift with Blackbox Predictors”是關于域自適應的另一篇有趣的論文。該論文的重點在于檢測訓練和測試中 y 分布的變化,這一方法在醫學上尤為有用,流行病或爆發疾病會對分布產生明顯的影響。
面對訓練集和測試集分布之間的變化,我們希望可以檢測和量化其間的變化,在沒有測試集標簽的情況下就可以對我們的分類器進行修正。
該論文的主題主要是協變量的變化。作者設計了幾個有趣的標簽轉換模擬器,然后應用于 CIFAR-10 數據集與 MINST 了。相比于未修正模型,他們的方法大大提升了準確性。
論文鏈接:
http://proceedings.mlr.press/v80/lipton18a/lipton18a.pdf
我發現論文“Rectify Heterogeneous Models with Semantic Mapping”有趣的點在于為了對齊分布,它引入了最優傳輸的方法。
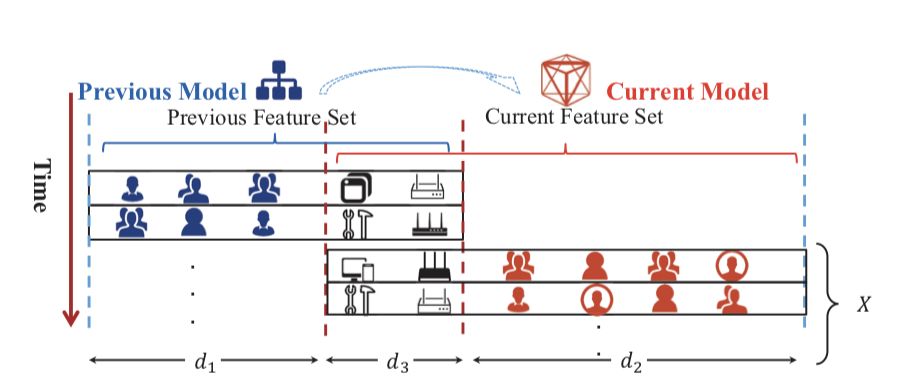
論文中描述特征空間模型的圖片
總之,該論文提出了最初的想法,并在模擬數據集和真實數據集上都取得了較好的結果,數據集包括 Amazon 用戶點擊數據集和學術論文分類數據集。
-
算法
+關注
關注
23文章
4630瀏覽量
93348 -
機器學習
+關注
關注
66文章
8438瀏覽量
133080 -
遷移學習
+關注
關注
0文章
74瀏覽量
5588
原文標題:ICML2018見聞 | 遷移學習、多任務學習領域的進展
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于稀疏編碼的遷移學習及其在行人檢測中的應用
keil下的FreeRtos多任務程序學習
一種由數據驅動的多任務學習煉鋼終點預測方法
NLP多任務學習案例分享:一種層次增長的神經網絡結構
AI實現多任務學習,究竟能做什么
機器學習方法遷移學習的發展和研究資料說明

機器學習中的Multi-Task多任務學習
關于多任務學習如何提升模型性能與原則
一個大規模多任務學習框架μ2Net
NeurIPS 2023 | 擴散模型解決多任務強化學習問題






 工商網監
工商網監
評論