") 語音識別技術(shù)的發(fā)展歷程,語音識別是如何工作的?語音識別資料概述
語音識別技術(shù)的發(fā)展歷程,語音識別是如何工作的?語音識別資料概述
你一定不會懷疑自己電腦的麥克風(fēng)正背著你偷偷摸摸做些什么,因?yàn)槟阋呀?jīng)很久沒有用過它了。
但事實(shí)真的是這樣嗎?
難道谷歌真的在“監(jiān)聽”用戶嗎?
挨君想告訴你,這基本沒 可 能。
谷歌瀏覽器的用戶已經(jīng)超過20億了,要是監(jiān)聽每個用戶每天說的話,這個數(shù)據(jù)量太過驚人。投入高昂的成本就為了實(shí)現(xiàn)廣告精準(zhǔn)投放,還冒著巨大的法律風(fēng)險,這種事正常人是不會去做的。
對于視頻中展現(xiàn)的“事實(shí)”,可能的操作是谷歌使用了一個語音關(guān)鍵詞識別系統(tǒng)。
有商業(yè)價值的關(guān)鍵詞總共就幾百萬個,為了簡單,可以只做頭部那些最賺錢的幾十萬個。這幾十萬個關(guān)鍵詞也不需要先跑語音識別再跑文本匹配,拿原始的語音文件來搞一個中等深度的神經(jīng)網(wǎng)絡(luò)甚至線性特征模型就可以,速度也非常快。
所以大家不用擔(dān)心語音識別正在侵犯你的隱私。相反,作為人類與機(jī)器最自然的交互形式(絕對不是打字),在未來,當(dāng)你不想用手或者像殘障人士難以用手的時候,語音識別將會是操作一切最方便的鑰匙。
語音識別發(fā)展史
說到語音識別,大家熟悉的可能是最近十年里才出現(xiàn)的微信語音轉(zhuǎn)文字,或者語音實(shí)時記錄和翻譯。但其實(shí)語音識別的歷史比互聯(lián)網(wǎng)還早,現(xiàn)代計算機(jī)誕生的那一刻,就已經(jīng)埋下了語音識別的種子。
1946年,現(xiàn)代計算機(jī)誕生。它的誕生讓人們意識到,原來計算機(jī)能完成這么多工作,而且做得比人還好;
(馮諾依曼和第一臺現(xiàn)代計算機(jī))
1950年,圖靈在《思想》雜志發(fā)表了一篇題為《計算機(jī)器和智能》的論文,來探討計算機(jī)是否可以具備智能;
在圖靈思想的啟發(fā)下,人們想著既然計算機(jī)這么能干,干嘛不把它設(shè)計得和人類一樣能看能說能聽呢,這不就能幫人類做更多事了嘛!(果然,懶才是科學(xué)發(fā)展的源動力啊)
于是,第一代語音識別系統(tǒng)誕生,被稱為機(jī)器的聽覺系統(tǒng)。
1952年,貝爾研究所研制了世界上第一個能識別10個英文數(shù)字發(fā)音的實(shí)驗(yàn)系統(tǒng)。也就是你說“yi”,計算機(jī)就知道這是“1”,能力跟嬰兒差不多。
1960年,英國的Denes等人研制了第一個計算機(jī)語音識別系統(tǒng)。
但是因?yàn)樽R別量小,這些系統(tǒng)根本達(dá)不到實(shí)際應(yīng)用的要求,包括后續(xù)的20年間,都是在走彎路,沒有什么研究成果。
直到1970年,統(tǒng)計語言學(xué)的出現(xiàn)才使得語音識別重獲新生。
統(tǒng)計語言學(xué)帶來的重生
推動這個技術(shù)路線轉(zhuǎn)變的關(guān)鍵人物是德里克·賈里尼克(Frederick Jelinek)和他領(lǐng)導(dǎo)的IBM華生實(shí)驗(yàn)室(T.J.Watson)。
統(tǒng)計語言學(xué)帶來的結(jié)果是,讓IBM當(dāng)時的語音識別率從70%提升到90%,同時語音識別的規(guī)模從幾百單詞上升到幾萬單詞,這樣語音識別就有了從實(shí)驗(yàn)室走向?qū)嶋H應(yīng)用的可能。
人類的語言是非常復(fù)雜的。不同于音頻識別,語音識別的難點(diǎn)在于把一段音頻不僅轉(zhuǎn)換成對應(yīng)的字,還要是一段邏輯清晰、語音明確的語句。
舉個例子,我們對計算機(jī)念一句話,“周五一起吃飯吧”。計算機(jī)根據(jù)音頻做出的識別可能結(jié)果是這樣的:州午衣起癡范爸。
如果僅看讀音和文字的一一對應(yīng),這個準(zhǔn)確度可以說是很高了,因?yàn)槿绻畹目邶X稍有不清更糟糕的結(jié)果可能是“鄒五意起次換吧”。
但是無論哪種結(jié)果,在實(shí)際應(yīng)用上都是不可行的,完全沒法交流嘛。
那么統(tǒng)計語言學(xué)帶來的變革是什么呢?
我們知道,雖然人類的語言很復(fù)雜,但仍有一定規(guī)律可循,無論是“州午衣起癡范爸”,還是“鄒五意起次換吧”都不是一個正常人會說的話。統(tǒng)計語言學(xué)的作用就是找出人類說話的規(guī)律,這樣就可以大大減少了語言識別產(chǎn)生的誤差。這其中一個非常關(guān)鍵的概念就是語素。
語素是語言中最小的音義結(jié)合體,一個語言單位必須同時滿足三個條件——“最小、有音、有義”才能被稱作語素。語素又可以分成三類:
單音節(jié)語素:構(gòu)詞由一個字才有意思的詞組成
雙音節(jié)語素:構(gòu)詞由兩個字才有意思的詞組成
多音節(jié)語素:構(gòu)詞由兩個字以上才有意思的詞組成
啥意思呢?舉個例子。
你、我、他,這三個字都是單音節(jié)語素,因?yàn)槊總€字都能自成一個含義。
你可能要說了,那不是廢話嗎,還有什么字是沒有含義的嗎?
當(dāng)然有!比如挨君最喜歡吃的“餛飩”。
餛飩就是一個雙音節(jié)語素。單獨(dú)的餛或者飩都不具備任何含義,只有組合在一起的時候才有真正的意義。類似的還有“琵琶”、“霹靂”等等。另外比如“沙發(fā)”這類詞,一旦拆分開其含義就完全脫離原來語素的,也被稱為雙音節(jié)語素。
最后一種情況就是多音節(jié)語素,主要是專有名詞還有擬聲詞,比如喜馬拉雅,動次打次。
我們再看回剛才的例子,當(dāng)機(jī)器知道語素之后,即便同音它也不會把“周五”識別成“州午”,因?yàn)楹笳邲]有任何意義,也不會把“吃飯”識別成“癡范”。
又有人要說了,現(xiàn)在很多網(wǎng)絡(luò)用語把吃飯說成次飯,我也能看懂啊。
如果說“次飯”你能理解那當(dāng)然普大喜奔啦,要是“鄒五意起次換吧”你都能理解的話,那對于語音識別團(tuán)隊(duì)來說可真是天大的喜訊了。然而真實(shí)情況是,視人視場景不同,識別準(zhǔn)確率永遠(yuǎn)是語音識別第一位的追求。
以上,根據(jù)語素等人類語言規(guī)律挑選同音字的工作,在語音識別中我們稱為語言模型。
語言模型的好基友
語音識別中還有一個模型,就是聲學(xué)模型。
聲學(xué)模型和語言模型是語音識別里的一對好基友。聲學(xué)模型負(fù)責(zé)挑選出與音頻匹配的所有字,語言模型負(fù)責(zé)從所有同音字里挑出符合原句意思的字。
聲學(xué)模型的原理說起來跟做牛肉火鍋有點(diǎn)像。
我們拿到一段語音,首先要把它切成若干小段,這個過程叫做分幀。
跟片好的牛肉會被分成匙仁、吊龍、匙柄一樣,片好的幀會根據(jù)聲學(xué)特征被計算機(jī)算法識別為一個個【狀態(tài)】,多個狀態(tài)又可以組合成音素。
音素是語音中的最小的單位,比如哦(o),只有一個音素;我(wo)則有兩個音素,w、o;吼(hou),則有三個音素,h、o、u。
有了音素就可以對應(yīng)找到匹配的字。
所以你可以這么理解,【狀態(tài)】就像生牛肉,還不是人類可以“食用”的模樣,需要用計算機(jī)算法來“涮一涮”成為音素才能成為一個【字】。
PS:如果你對【狀態(tài)】這個概念還不太理解,那也沒關(guān)系,因?yàn)榻鼛啄瓿霈F(xiàn)了一個叫CTC的新技術(shù),建模單元放大到了音節(jié)或音素的單位,直接跳過了【狀態(tài)】這個概念,所以這個知識點(diǎn)以后都不會考了。
剛才提到語言模型為語音識別帶來的重生,并不是說在此之前聲學(xué)模型就已經(jīng)非常成熟了,相反,語音識別重生不久(到20世紀(jì)90年代)再次轉(zhuǎn)涼就是因?yàn)槁晫W(xué)模型太弱,缺少足夠的數(shù)據(jù)和算法。這一狀況直到互聯(lián)網(wǎng)的出現(xiàn)并且?guī)砹藰O其豐富的大數(shù)據(jù)后,才稍微得以改善。
可以這么說,語音識別的童年,是灰暗坎坷的。
語音識別是如何工作的
說完語音識別的兩個模型,現(xiàn)在我們可以大致梳理下語音識別的基本步驟,如下圖:
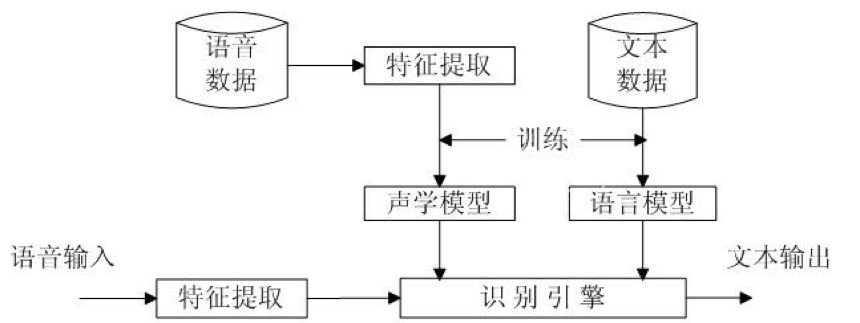
你通過微信發(fā)送了一段語音,對方因?yàn)樵陂_會無法聽,于是使用了語音轉(zhuǎn)文字的功能。語音識別系統(tǒng)先把這段語音分幀,然后提取每一幀的特征形成【狀態(tài)】,幾個狀態(tài)(通常為3個)又會組合成一個音素,音素又構(gòu)成了諸多同音字,接著語言模型從諸多同音字中挑選出可以使語義完整的字,最后一個個呈現(xiàn)在你面前。
雖然過程看著挺簡單的,但事實(shí)上,受各種語音語調(diào)、方言、說話環(huán)境、說話方式等等的影響,語音識別要提高準(zhǔn)確率非常非常非常…非 常 難。得虧現(xiàn)在有了大數(shù)據(jù)和深度學(xué)習(xí),這兩個模型才得到了好好的訓(xùn)練,包括現(xiàn)在很多語音識別廠商都表示已經(jīng)可以實(shí)現(xiàn)97%的識別準(zhǔn)確率。
這里插播一段廣告,
網(wǎng)易人工智能對語音識別技術(shù)的研究開始于2014年,目前通過網(wǎng)易AI平臺已服務(wù)于網(wǎng)易游戲、有道詞典等產(chǎn)品。網(wǎng)易AI平臺語音識別技術(shù)的優(yōu)勢有:領(lǐng)先的中英文語音識別轉(zhuǎn)寫技術(shù),中文轉(zhuǎn)寫準(zhǔn)確率可達(dá)97%以上;提供基于垂直行業(yè)語音模型進(jìn)行深度優(yōu)化訓(xùn)練,在游戲行業(yè)的語音識別準(zhǔn)確性保持業(yè)界頂尖水平;提供標(biāo)準(zhǔn)規(guī)范的SDK和API接口,接入迅速,使用便捷。
說了這么多,語音識別算是人工智能領(lǐng)域比較成熟的技術(shù),但對于人類的遠(yuǎn)大愿景而言,這才只是起步,就像小嬰兒現(xiàn)在只能聽,接下來還要會說、會做、會想。不過有了深度學(xué)習(xí)之后,這一切現(xiàn)在看來似乎有了觸達(dá)的可能。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101169 -
語音識別
+關(guān)注
關(guān)注
38文章
1742瀏覽量
112925 -
人工智能
+關(guān)注
關(guān)注
1796文章
47666瀏覽量
240286
原文標(biāo)題:科普 | 一文讀懂AI大勢技術(shù)-語音識別
文章出處:【微信號:gh_70d0cce81c74,微信公眾號:網(wǎng)易人工智能】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
語音識別技術(shù)的應(yīng)用及發(fā)展
基于labview的語音識別
【語音識別】你知道什么是離線語音識別和在線語音識別嗎?
離線語音識別和控制的工作原理及應(yīng)用
離線語音識別及控制是怎樣的技術(shù)?
國內(nèi)語音識別技術(shù)上市公司匯總_語音識別技術(shù)現(xiàn)狀_語音識別原理及應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論