 深度學習的目標檢測技術從R-CNN到R-CNN的算法和技術資料介紹
深度學習的目標檢測技術從R-CNN到R-CNN的算法和技術資料介紹
object detection我的理解,就是在給定的圖片中精確找到物體所在位置,并標注出物體的類別。object detection要解決的問題就是物體在哪里,是什么這整個流程的問題。然而,這個問題可不是那么容易解決的,物體的尺寸變化范圍很大,擺放物體的角度,姿態不定,而且可以出現在圖片的任何地方,更何況物體還可以是多個類別。
object detection技術的演進:RCNN->SppNET->Fast-RCNN->Faster-RCNN
從圖像識別的任務說起這里有一個圖像任務:既要把圖中的物體識別出來,又要用方框框出它的位置。
上面的任務用專業的說法就是:圖像識別+定位圖像識別(classification):輸入:圖片輸出:物體的類別評估方法:準確率
定位(localization):輸入:圖片輸出:方框在圖片中的位置(x,y,w,h)評估方法:檢測評價函數 intersection-over-union ( IOU )
卷積神經網絡CNN已經幫我們完成了圖像識別(判定是貓還是狗)的任務了,我們只需要添加一些額外的功能來完成定位任務即可。
定位的問題的解決思路有哪些?思路一:看做回歸問題看做回歸問題,我們需要預測出(x,y,w,h)四個參數的值,從而得出方框的位置。
步驟1:? 先解決簡單問題, 搭一個識別圖像的神經網絡? 在AlexNet VGG GoogleLenet上fine-tuning一下
步驟2:? 在上述神經網絡的尾部展開(也就說CNN前面保持不變,我們對CNN的結尾處作出改進:加了兩個頭:“分類頭”和“回歸頭”)? 成為classification + regression模式
步驟3:? Regression那個部分用歐氏距離損失? 使用SGD訓練
步驟4:? 預測階段把2個頭部拼上? 完成不同的功能
這里需要進行兩次fine-tuning第一次在ALexNet上做,第二次將頭部改成regression head,前面不變,做一次fine-tuning
Regression的部分加在哪?
有兩種處理方法:? 加在最后一個卷積層后面(如VGG)? 加在最后一個全連接層后面(如R-CNN)
regression太難做了,應想方設法轉換為classification問題。regression的訓練參數收斂的時間要長得多,所以上面的網絡采取了用classification的網絡來計算出網絡共同部分的連接權值。
思路二:取圖像窗口? 還是剛才的classification + regression思路? 咱們取不同的大小的“框”? 讓框出現在不同的位置,得出這個框的判定得分? 取得分最高的那個框
左上角的黑框:得分0.5
右上角的黑框:得分0.75
左下角的黑框:得分0.6
右下角的黑框:得分0.8
根據得分的高低,我們選擇了右下角的黑框作為目標位置的預測。注:有的時候也會選擇得分最高的兩個框,然后取兩框的交集作為最終的位置預測。
疑惑:框要取多大?取不同的框,依次從左上角掃到右下角。非常粗暴啊。
總結一下思路:對一張圖片,用各種大小的框(遍歷整張圖片)將圖片截取出來,輸入到CNN,然后CNN會輸出這個框的得分(classification)以及這個框圖片對應的x,y,h,w(regression)。
這方法實在太耗時間了,做個優化。原來網絡是這樣的:
優化成這樣:把全連接層改為卷積層,這樣可以提提速。
物體檢測(Object Detection)當圖像有很多物體怎么辦的?難度可是一下暴增啊。
那任務就變成了:多物體識別+定位多個物體那把這個任務看做分類問題?
看成分類問題有何不妥?? 你需要找很多位置, 給很多個不同大小的框? 你還需要對框內的圖像分類? 當然, 如果你的GPU很強大, 恩, 那加油做吧…
看做classification, 有沒有辦法優化下?我可不想試那么多框那么多位置啊!有人想到一個好方法:找出可能含有物體的框(也就是候選框,比如選1000個候選框),這些框之間是可以互相重疊互相包含的,這樣我們就可以避免暴力枚舉的所有框了。
大牛們發明好多選定候選框的方法,比如EdgeBoxes和Selective Search。以下是各種選定候選框的方法的性能對比。
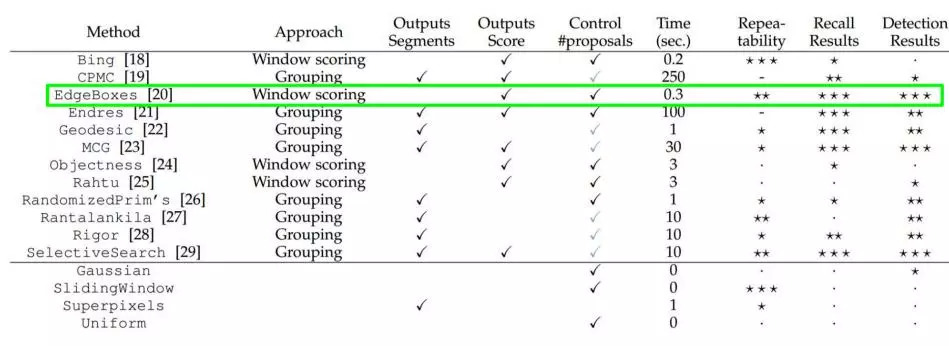
有一個很大的疑惑,提取候選框用到的算法“選擇性搜索”到底怎么選出這些候選框的呢?那個就得好好看看它的論文了,這里就不介紹了。
R-CNN橫空出世
基于以上的思路,RCNN的出現了。
步驟一:訓練(或者下載)一個分類模型(比如AlexNet)
步驟二:對該模型做fine-tuning? 將分類數從1000改為20? 去掉最后一個全連接層
步驟三:特征提取? 提取圖像的所有候選框(選擇性搜索)? 對于每一個區域:修正區域大小以適合CNN的輸入,做一次前向運算,將第五個池化層的輸出(就是對候選框提取到的特征)存到硬盤
步驟四:訓練一個SVM分類器(二分類)來判斷這個候選框里物體的類別每個類別對應一個SVM,判斷是不是屬于這個類別,是就是positive,反之nagative比如下圖,就是狗分類的SVM
步驟五:使用回歸器精細修正候選框位置:對于每一個類,訓練一個線性回歸模型去判定這個框是否框得完美。
RCNN的進化中SPP Net的思想對其貢獻很大,這里也簡單介紹一下SPP Net。
SPP NetSPP:Spatial Pyramid Pooling(空間金字塔池化)它的特點有兩個:
1.結合空間金字塔方法實現CNNs的對尺度輸入。一般CNN后接全連接層或者分類器,他們都需要固定的輸入尺寸,因此不得不對輸入數據進行crop或者warp,這些預處理會造成數據的丟失或幾何的失真。SPP Net的第一個貢獻就是將金字塔思想加入到CNN,實現了數據的多尺度輸入。
如下圖所示,在卷積層和全連接層之間加入了SPP layer。此時網絡的輸入可以是任意尺度的,在SPP layer中每一個pooling的filter會根據輸入調整大小,而SPP的輸出尺度始終是固定的。
2.只對原圖提取一次卷積特征
在R-CNN中,每個候選框先resize到統一大小,然后分別作為CNN的輸入,這樣是很低效的。所以SPP Net根據這個缺點做了優化:只對原圖進行一次卷積得到整張圖的feature map,然后找到每個候選框zaifeature map上的映射patch,將此patch作為每個候選框的卷積特征輸入到SPP layer和之后的層。節省了大量的計算時間,比R-CNN有一百倍左右的提速。
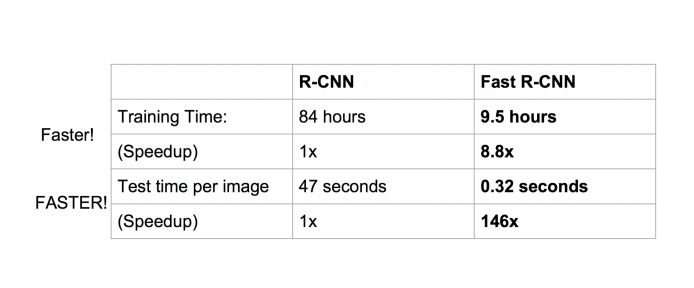
Fast R-CNNSPP Net真是個好方法,R-CNN的進階版Fast R-CNN就是在RCNN的基礎上采納了SPP Net方法,對RCNN作了改進,使得性能進一步提高。
R-CNN與Fast RCNN的區別有哪些呢?先說RCNN的缺點:即使使用了selective search等預處理步驟來提取潛在的bounding box作為輸入,但是RCNN仍會有嚴重的速度瓶頸,原因也很明顯,就是計算機對所有region進行特征提取時會有重復計算,Fast-RCNN正是為了解決這個問題誕生的。
大牛提出了一個可以看做單層sppnet的網絡層,叫做ROI Pooling,這個網絡層可以把不同大小的輸入映射到一個固定尺度的特征向量,而我們知道,conv、pooling、relu等操作都不需要固定size的輸入,因此,在原始圖片上執行這些操作后,雖然輸入圖片size不同導致得到的feature map尺寸也不同,不能直接接到一個全連接層進行分類,但是可以加入這個神奇的ROI Pooling層,對每個region都提取一個固定維度的特征表示,再通過正常的softmax進行類型識別。另外,之前RCNN的處理流程是先提proposal,然后CNN提取特征,之后用SVM分類器,最后再做bbox regression,而在Fast-RCNN中,作者巧妙的把bbox regression放進了神經網絡內部,與region分類和并成為了一個multi-task模型,實際實驗也證明,這兩個任務能夠共享卷積特征,并相互促進。Fast-RCNN很重要的一個貢獻是成功的讓人們看到了Region Proposal+CNN這一框架實時檢測的希望,原來多類檢測真的可以在保證準確率的同時提升處理速度,也為后來的Faster-RCNN做下了鋪墊。
畫一畫重點:R-CNN有一些相當大的缺點(把這些缺點都改掉了,就成了Fast R-CNN)。大缺點:由于每一個候選框都要獨自經過CNN,這使得花費的時間非常多。解決:共享卷積層,現在不是每一個候選框都當做輸入進入CNN了,而是輸入一張完整的圖片,在第五個卷積層再得到每個候選框的特征
原來的方法:許多候選框(比如兩千個)-->CNN-->得到每個候選框的特征-->分類+回歸現在的方法:一張完整圖片-->CNN-->得到每張候選框的特征-->分類+回歸
所以容易看見,Fast RCNN相對于RCNN的提速原因就在于:不過不像RCNN把每個候選區域給深度網絡提特征,而是整張圖提一次特征,再把候選框映射到conv5上,而SPP只需要計算一次特征,剩下的只需要在conv5層上操作就可以了。
在性能上提升也是相當明顯的:
Faster R-CNNFast R-CNN存在的問題:存在瓶頸:選擇性搜索,找出所有的候選框,這個也非常耗時。那我們能不能找出一個更加高效的方法來求出這些候選框呢?解決:加入一個提取邊緣的神經網絡,也就說找到候選框的工作也交給神經網絡來做了。做這樣的任務的神經網絡叫做Region Proposal Network(RPN)。
具體做法:? 將RPN放在最后一個卷積層的后面? RPN直接訓練得到候選區域
RPN簡介:? 在feature map上滑動窗口? 建一個神經網絡用于物體分類+框位置的回歸? 滑動窗口的位置提供了物體的大體位置信息? 框的回歸提供了框更精確的位置
一種網絡,四個損失函數;? RPN calssification(anchor good.bad)? RPN regression(anchor->propoasal)? Fast R-CNN classification(over classes)? Fast R-CNN regression(proposal ->box)
速度對比
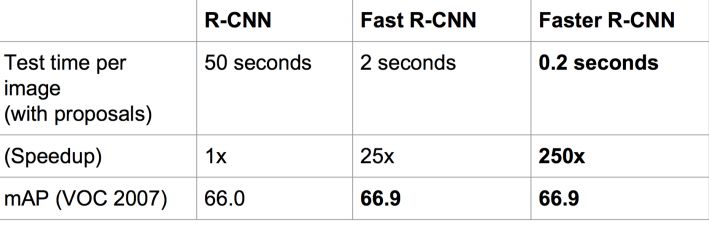
Faster R-CNN的主要貢獻是設計了提取候選區域的網絡RPN,代替了費時的選擇性搜索,使得檢測速度大幅提高。
最后總結一下各大算法的步驟:RCNN1. 在圖像中確定約1000-2000個候選框 (使用選擇性搜索)2. 每個候選框內圖像塊縮放至相同大小,并輸入到CNN內進行特征提取3. 對候選框中提取出的特征,使用分類器判別是否屬于一個特定類4. 對于屬于某一特征的候選框,用回歸器進一步調整其位置
Fast RCNN1. 在圖像中確定約1000-2000個候選框 (使用選擇性搜索)2. 對整張圖片輸進CNN,得到feature map3. 找到每個候選框在feature map上的映射patch,將此patch作為每個候選框的卷積特征輸入到SPP layer和之后的層4. 對候選框中提取出的特征,使用分類器判別是否屬于一個特定類5. 對于屬于某一特征的候選框,用回歸器進一步調整其位置
Faster RCNN1. 對整張圖片輸進CNN,得到feature map2. 卷積特征輸入到RPN,得到候選框的特征信息3. 對候選框中提取出的特征,使用分類器判別是否屬于一個特定類4. 對于屬于某一特征的候選框,用回歸器進一步調整其位置
總的來說,從R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN一路走來,基于深度學習目標檢測的流程變得越來越精簡,精度越來越高,速度也越來越快。可以說基于region proposal的R-CNN系列目標檢測方法是當前目標檢測技術領域最主要的一個分支。
-
目標檢測
+關注
關注
0文章
211瀏覽量
15664 -
深度學習
+關注
關注
73文章
5516瀏覽量
121556 -
cnn
+關注
關注
3文章
353瀏覽量
22338
原文標題:深度學習的目標檢測技術演進:R-CNN、Fast R-CNN、Faster R-CNN
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于深度學習的目標檢測算法解析
深度卷積神經網絡在目標檢測中的進展
介紹目標檢測工具Faster R-CNN,包括它的構造及實現原理

什么是Mask R-CNN?Mask R-CNN的工作原理
手把手教你操作Faster R-CNN和Mask R-CNN

基于改進Faster R-CNN的目標檢測方法
用于實例分割的Mask R-CNN框架
深入了解目標檢測深度學習算法的技術細節
PyTorch教程14.8之基于區域的CNN(R-CNN)

PyTorch教程-14.8。基于區域的 CNN (R-CNN)






 工商網監
工商網監
評論