 如何解決數據稀疏而對深度學習的影響問題?詳細方法概述
如何解決數據稀疏而對深度學習的影響問題?詳細方法概述
深度學習,有太多令人驚嘆的能力!從12年的圖像識別開始,深度學習的一個個突破,讓人們一次又一次的刷新對它的認知。然而,應用深度學習,一直有一個巨大的前提:大量標注數據。但是難道數據少,就享受不到深度學習帶來的紅利了么?近日來自卡內基梅隆大學、亞馬遜研究院、加州理工學院的研究員,在人工智能頂級會議 UAI 上闡述了多種方法,嘗試緩解甚至解決數據稀疏對深度學習的影響。
主要方法
為了解決深度學習數據少,和數據稀疏, 目前業界的主流方法有一下5種:
數據增廣
半監督學習
遷移學習
領域自適應
主動學習
下面,我們對這5種方式進行一個簡單的介紹,詳細的介紹.
數據增廣
數據增廣,主要是想,對現有的數據,添加噪聲等各種其他變換,從而產生一些有意義的數據,是的數據集增加,從而解決數據稀疏的問題,提升模型性能。 特別的,如圖所示,Zachary Lipton 介紹了近期他的一個工作:利用 GAN來做圖像數據增廣。
半監督學習
半監督學習的情形是指:我們擁有少量的標注樣本(圖中橘色部分)以及大量的未標注樣本(圖中藍色部分)。
半監督學習,一般的思路是:在全部數據上去學習數據表示,在有標簽的樣本上去學習模型,用所有數據去加正則。
遷移學習
遷移學習,主要是想,在一個擁有大量樣本的數據(圖中藍色部分)上去學習模型,在改動較少的情況下,將學習到的模型遷移到類似的目標數據(圖中橘色部分)和任務上。
領域自適應
領域自適應,主要是想,在已有的標注數據p(x,y)上學習模型, 然后嘗試在另一個分布上q(x,y)上去做應用。
主動學習
主動學習,維護了兩個部分:學習引擎和選擇引擎。學習引擎維護一個基準分類器,并使用監督學習算法對系統提供的已標注樣例進行學習從而使該分類器的性能提高,而選擇引擎負責運行樣例選擇算法選擇一個未標注的樣例并將其交由人類專家進行標注,再將標注后的樣例加入到已標注樣例集中。學習引擎和選擇引擎交替工作,經過多次循環,基準分類器的性能逐漸提高,當滿足預設條件時,過程終止。
-
圖像識別
+關注
關注
9文章
521瀏覽量
38386 -
GaN
+關注
關注
19文章
1965瀏覽量
74223 -
深度學習
+關注
關注
73文章
5513瀏覽量
121544
原文標題:數據少,就享受不到深度學習的紅利了么?總是有辦法的!
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于稀疏編碼的遷移學習及其在行人檢測中的應用
基于深度學習的異常檢測的研究方法
基于深度學習的異常檢測的研究方法
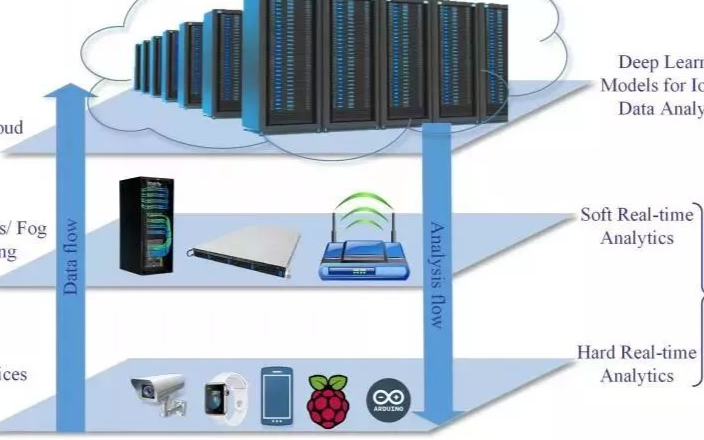
如何使用極端學習機進行人臉特征深度稀疏自編碼的詳細方法概述
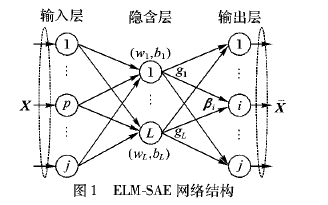
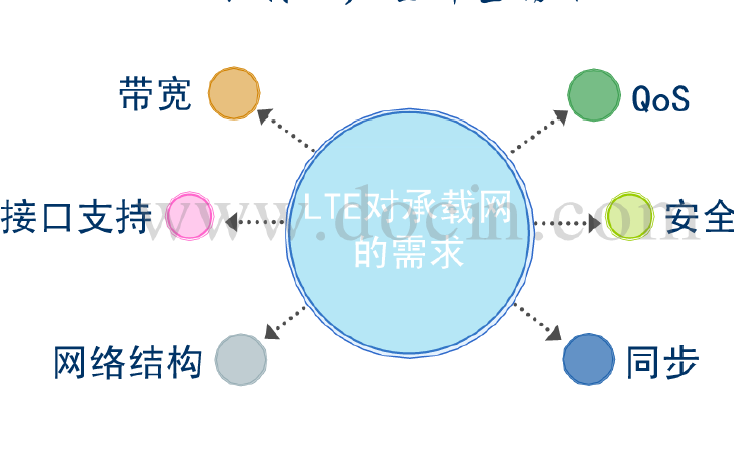
LTE的結構是怎樣的LTE承載網如何解決詳細方案概述
深度學習優化器方法及學習率衰減方式的詳細資料概述
針對線性回歸模型和深度學習模型,介紹了確定訓練數據集規模的方法
什么?不用GPU也能加速你的YOLOv3深度學習模型








 工商網監
工商網監
評論