") 基于深度學(xué)習(xí)的目標(biāo)檢測(cè)來實(shí)現(xiàn)監(jiān)控系統(tǒng)的快速教程
基于深度學(xué)習(xí)的目標(biāo)檢測(cè)來實(shí)現(xiàn)監(jiān)控系統(tǒng)的快速教程
【導(dǎo)讀】這是一篇關(guān)于使用基于深度學(xué)習(xí)的目標(biāo)檢測(cè)來實(shí)現(xiàn)監(jiān)控系統(tǒng)的快速教程。在教程中通過使用 GPU 多處理器來比較不同目標(biāo)檢測(cè)模型在行人檢測(cè)上的性能。
監(jiān)控是安保和巡邏的一個(gè)組成部分,大多數(shù)情況下,這項(xiàng)工作都是在長(zhǎng)時(shí)間去觀察發(fā)現(xiàn)那些我們不愿意發(fā)生的事情。然而突發(fā)事件發(fā)生的低概率性無法掩蓋監(jiān)控這一平凡工作的重要性,這個(gè)工作甚至是至關(guān)重要的。
如果有能夠代替我們?nèi)プ觥暗却捅O(jiān)視”突發(fā)事件的工具那就再好不過了。幸運(yùn)的是,這些年隨著技術(shù)的進(jìn)步,我們已經(jīng)可以編寫一些腳本來自動(dòng)執(zhí)行監(jiān)控這一項(xiàng)任務(wù)。在深入探究之前,需要我們先考慮兩個(gè)問題。
機(jī)器是否已經(jīng)達(dá)到人類的水平?
任何熟悉深度學(xué)習(xí)的人都知道圖像分類器的準(zhǔn)確度已經(jīng)趕超人類。圖1顯示了近幾年來對(duì)于人類、傳統(tǒng)計(jì)算機(jī)視覺 (CV) 和深度學(xué)習(xí)在 ImageNet 數(shù)據(jù)集上的分類錯(cuò)誤率。
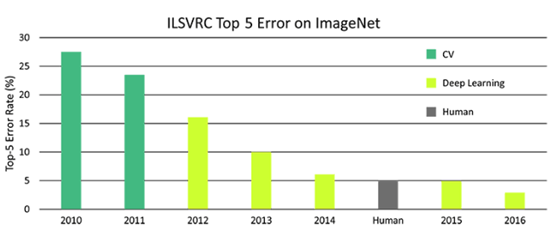
圖 1 人類、深度學(xué)習(xí)和 CV 在 ImageNet 上分類錯(cuò)誤率
與人類相比,機(jī)器可以更好地監(jiān)視目標(biāo),使用機(jī)器進(jìn)行監(jiān)視效率更高,其優(yōu)點(diǎn)可總結(jié)如下:
重復(fù)的任務(wù)會(huì)導(dǎo)致人類注意力的下降,而使用機(jī)器進(jìn)行監(jiān)視時(shí)并無這一煩惱,我們可以把更多的精力放在處理出現(xiàn)的突發(fā)事件上面。
當(dāng)要監(jiān)視的范圍較大時(shí),需要大量的人員,固定相機(jī)的視野也很有限。但是通過移動(dòng)監(jiān)控機(jī)器人 (如微型無人機(jī)) 就能解決這一問題。
此外,同樣的技術(shù)可用于各種不受限于安全性的應(yīng)用程序,如嬰兒監(jiān)視器或自動(dòng)化產(chǎn)品交付。
那我們?cè)撊绾螌?shí)現(xiàn)自動(dòng)化?
在我們討論復(fù)雜的理論之前,先讓我們看一下監(jiān)控的正常運(yùn)作方式。我們?cè)谟^看即時(shí)影像時(shí),如果發(fā)現(xiàn)異常就采會(huì)取行動(dòng)。因此我們的技術(shù)也應(yīng)該通過仔細(xì)閱讀視頻的每一幀來發(fā)現(xiàn)異常的事物,并判斷這一過程是否需要報(bào)警。
大家可能已經(jīng)知道了,這個(gè)過程實(shí)現(xiàn)的本質(zhì)是通過目標(biāo)檢測(cè)定位,它與分類不同,我們需要知道目標(biāo)的確切位置,而且在單個(gè)圖像中可能有多個(gè)目標(biāo)。為了更好的區(qū)分我們舉了一個(gè)簡(jiǎn)單形象的例子如圖2所示。
圖2 分類、定位、檢測(cè)和分割的示例圖
為了找到確切的位置,我們的算法應(yīng)該檢查圖像的每個(gè)部分,以找到某類的存在。自2014年以來,深度學(xué)習(xí)的持續(xù)迭代研究引入了精心設(shè)計(jì)的神經(jīng)網(wǎng)絡(luò),它能夠?qū)崟r(shí)檢測(cè)目標(biāo)。圖3顯示了近兩年R-CNN、Fast R-CNN 和 Faster R-CNN 三種模型的檢測(cè)性能。
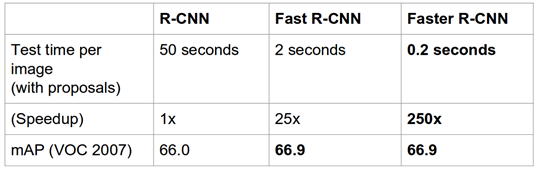
圖3 R-CNN、Fast R-CNN 和 Faster R-CNN 性能
這里有幾種在內(nèi)部使用的不同方法來執(zhí)行相同任務(wù)的深度學(xué)習(xí)框架。其中最流行的是 Faster-RCNN、YOLO 和 SSD。圖4展示了 Faster R-CNN、R-FCN 和 SSD 的檢測(cè)性能。
圖4 Faster R-CNN、R-FCN 和 SSD 的檢測(cè)性能,速度與準(zhǔn)確性的權(quán)衡,更高的 mpA 和更低的 GPU 時(shí)間是最佳的。
每個(gè)模型都依賴于基礎(chǔ)分類器,這極大影響了最終的準(zhǔn)確性和模型大小。此外,目標(biāo)檢測(cè)器的選擇會(huì)嚴(yán)重影響計(jì)算復(fù)雜性和最終精度。在選擇目標(biāo)檢測(cè)算法時(shí),速度、精度和模型大小的權(quán)衡關(guān)系始終存在著。
在有了上面的學(xué)習(xí)了解后,接下來我們將學(xué)習(xí)如何使用目標(biāo)檢測(cè)構(gòu)建一個(gè)簡(jiǎn)單而有效的監(jiān)控系統(tǒng)。
我們先從由監(jiān)視任務(wù)的性質(zhì)而引起的限制約束開始討論起。
深度學(xué)習(xí)在監(jiān)控中的限制
在實(shí)現(xiàn)自動(dòng)化監(jiān)控之前,我們需要考慮以下幾個(gè)因素:
1.即時(shí)影像
為了在大范圍內(nèi)進(jìn)行觀察,我們可能需要多個(gè)攝像頭。而且,這些攝像頭需要有可用來存儲(chǔ)數(shù)據(jù)的地方 (本地或遠(yuǎn)程位置)。圖5為典型的監(jiān)控?cái)z像頭。
圖5 典型的監(jiān)控?cái)z像頭
高質(zhì)量的視頻比低質(zhì)量的視頻要占更多的內(nèi)存。此外,RGB 輸入流比 BW 輸入流大3倍。由于我們只能存儲(chǔ)有限數(shù)量的輸入流,故通常情況下我們會(huì)選擇降低質(zhì)量來保證最大化存儲(chǔ)。
因此,可推廣的監(jiān)控系統(tǒng)應(yīng)該能夠解析低質(zhì)量的圖像。同時(shí)我們的深度學(xué)習(xí)算法也必須在低質(zhì)量的圖像上進(jìn)行訓(xùn)練。
2.處理能力
在哪里處理從相機(jī)源獲得的數(shù)據(jù)是另一個(gè)大問題。通常有兩種方法可以解決這一問題。
集中式服務(wù)器處理
來自攝像機(jī)的視頻流在遠(yuǎn)程服務(wù)器或集群上逐幀處理。這種方法很強(qiáng)大,使我們能夠從高精度的復(fù)雜模型中獲益。但這種方法的缺點(diǎn)是有延遲。此外,如果不用商業(yè) API,則服務(wù)器的設(shè)置和維護(hù)成本會(huì)很高。圖6顯示了三種模型隨著推理時(shí)間的增長(zhǎng)內(nèi)存的消耗情況。
圖6 內(nèi)存消耗與推理時(shí)間(毫秒),大多數(shù)高性能模型都會(huì)占用大量?jī)?nèi)存
分散式邊緣處理
通過附加一個(gè)微控制器來對(duì)相機(jī)本身進(jìn)行實(shí)時(shí)處理。優(yōu)點(diǎn)在于沒有傳輸延遲,發(fā)現(xiàn)異常時(shí)還能更快地進(jìn)行反饋,不會(huì)受到 WiFi 或藍(lán)牙的限制 (如 microdrones)。缺點(diǎn)是微控制器沒有 GPU 那么強(qiáng)大,因此只能使用精度較低的模型。使用板載 GPU 可以避免這一問題,但是太過于昂貴。圖 7 展示了目標(biāo)檢測(cè)器 FPS 的性能。
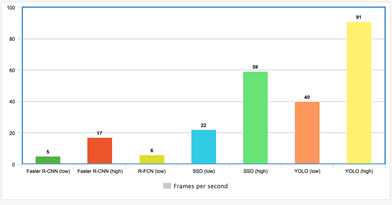
圖 7 各類目標(biāo)檢測(cè)器 FPS 的性能
訓(xùn)練監(jiān)控系統(tǒng)
在接下來的內(nèi)容里我們將會(huì)嘗試如何使用目標(biāo)檢測(cè)進(jìn)行行人識(shí)別。使用 TensorFlow 目標(biāo)檢測(cè) API 來創(chuàng)建目標(biāo)檢測(cè)模塊,我們還會(huì)簡(jiǎn)要的闡述如何設(shè)置 API 并訓(xùn)練它來執(zhí)行監(jiān)控任務(wù)。整個(gè)過程可歸納為三個(gè)階段 (流程圖如圖8所示):
數(shù)據(jù)準(zhǔn)備
訓(xùn)練模型
推論
圖8 目標(biāo)檢測(cè)模型的訓(xùn)練工作流程
▌第1階段:數(shù)據(jù)準(zhǔn)備
第一步:獲取數(shù)據(jù)集
監(jiān)控錄像是獲取最準(zhǔn)確數(shù)據(jù)集的來源。但是,在大多數(shù)情況下,想要獲取這樣的監(jiān)控錄像并不容易。因此,我們需要訓(xùn)練我們的目標(biāo)檢測(cè)器使其能從普通圖像中識(shí)別出目標(biāo)。
圖9 從數(shù)據(jù)集中提取出帶標(biāo)注的圖像
正如前面所說,我們的圖像質(zhì)量可能較差,所以所訓(xùn)練的模型必須適應(yīng)在這樣的圖像質(zhì)量下進(jìn)行工作。我們對(duì)數(shù)據(jù)集中的圖像 (如圖9所示) 添加一些噪聲或者嘗試模糊和腐蝕的手段,來降低數(shù)據(jù)集中的圖片質(zhì)量。
在目標(biāo)檢測(cè)任務(wù)中,我們使用了 TownCentre 數(shù)據(jù)集。使用視頻的前3600幀進(jìn)行訓(xùn)練,剩下的900幀用于測(cè)試。
第二步:圖像標(biāo)注
使用像 LabelImg 這樣的工具進(jìn)行標(biāo)注,這項(xiàng)工作雖然乏味但也同樣很重要。我們將標(biāo)注完的圖像保存為 XML 文件。
第三步:克隆存儲(chǔ)庫(kù)
運(yùn)行以下命令以安裝需求文件,編譯一些 Protobuf 庫(kù)并設(shè)置路徑變量
pipinstall-rrequirements.txtsudoapt-getinstallprotobuf-compilerprotocobject_detection/protos/*.proto--python_out=.exportPYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
第四步:準(zhǔn)備所需的輸入
首先,我們需要給每個(gè)目標(biāo)一個(gè)標(biāo)簽,并將文件中每個(gè)標(biāo)簽表示為如下所示的label_map.pbtxt
item{id:1name:‘target’}
接下來,創(chuàng)建一個(gè)包含 XML 和圖像文件名稱的文本文件。例如,如果數(shù)據(jù)集中有 img1.jpg, img2.jpg, 和 img1.xml, img2.xml ,則 trainval.txt 文件的表示應(yīng)如下所示:
img1img2
將數(shù)據(jù)集分為兩個(gè)文件夾 (圖像與標(biāo)注)。將 label_map.pbtx 和 trainval.txt放在標(biāo)注文件夾中,然后在標(biāo)注文件夾中創(chuàng)建一個(gè)名為 xmls 的子文件夾,并將所有 XML 文件放入該子文件夾中。目錄層次結(jié)構(gòu)應(yīng)如下所示:
-base_directory|-images|-annotations||-xmls||-label_map.pbtxt||-trainval.txt
第五步:創(chuàng)建 TF 記錄
API 接受 TPRecords 文件格式的輸入。使用 creat_tf_record.py 文件將數(shù)據(jù)集轉(zhuǎn)換為 TFRecords。我們應(yīng)該在 base directory 中執(zhí)行以下命令:
pythoncreate_tf_record.py--data_dir=`pwd`--output_dir=`pwd`
在該程序執(zhí)行完后,我們可以獲取 train.record 和 val.record 文件。
▌第2階段:訓(xùn)練模型
第1步:模型選擇
如前所述,速度與準(zhǔn)確度兩者不可得兼,從頭開始創(chuàng)建和訓(xùn)練目標(biāo)檢測(cè)器是非常耗時(shí)的。因此, TensorFlow 目標(biāo)檢測(cè) API 提供了一系列預(yù)先訓(xùn)練好的模型,我們可以根據(jù)自己的使用情況進(jìn)行微調(diào),該過程稱為遷移學(xué)習(xí),它可以大大提高我們的訓(xùn)練速度。
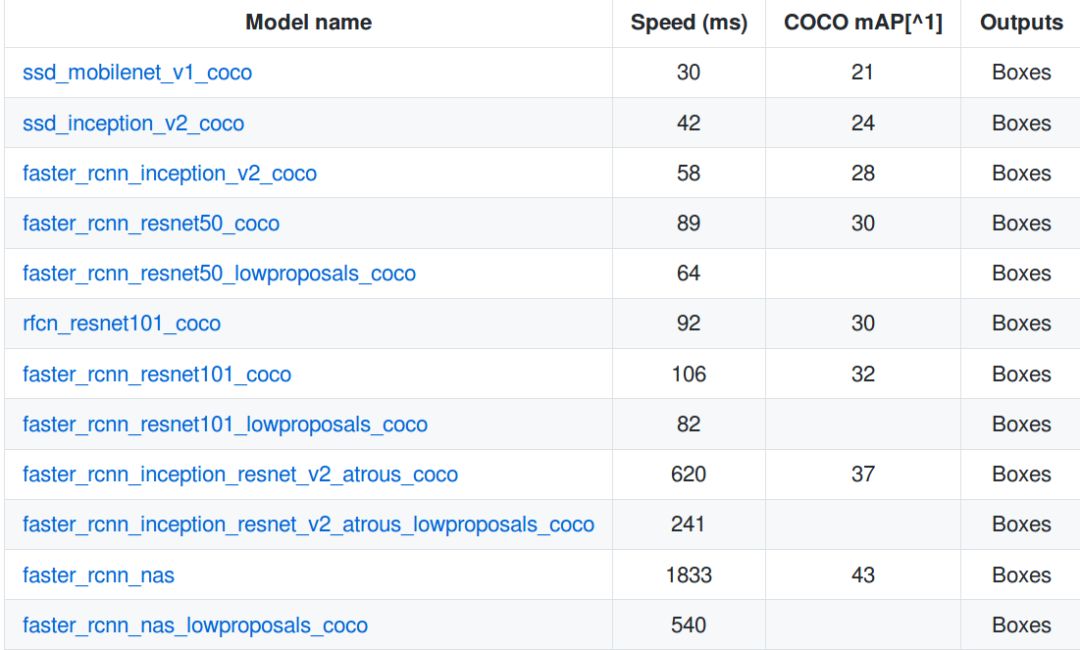
圖10 MS COCO 數(shù)據(jù)集中一組預(yù)訓(xùn)練過的模型
從圖 10 中下載一個(gè)模型,并將內(nèi)容解壓縮到 base directory 中。可獲取模型檢查點(diǎn),固定推理圖和 pipeline.config 文件。
第2步:定義訓(xùn)練工作
我們必須在 pipleline.config 文件中定義“訓(xùn)練工作”,并將該文件放到 base directory 中。該文件中最重要的是后幾行——我們只需將突出顯示的值放到各自的位置。
gradient_clipping_by_norm:10.0fine_tune_checkpoint:"model.ckpt"from_detection_checkpoint:truenum_steps:200000}train_input_reader{label_map_path:"annotations/label_map.pbtxt"tf_record_input_reader{input_path:"train.record"}}eval_config{num_examples:8000max_evals:10use_moving_averages:false}eval_input_reader{label_map_path:"annotations/label_map.pbtxt"shuffle:falsenum_epochs:1num_readers:1tf_record_input_reader{input_path:"val.record"}}
第3步:開始訓(xùn)練
執(zhí)行以下命令以啟動(dòng)訓(xùn)練工作,建議使用具有足夠大的 GPU 計(jì)算機(jī),以便加快訓(xùn)練過程。
pythonobject_detection/train.py--logtostderr--pipeline_config_path=pipeline.config--train_dir=train
▌第3階段:推論
第1步:導(dǎo)出訓(xùn)練模型
在模型使用之前,需要將訓(xùn)練好的檢查點(diǎn)文件導(dǎo)出到固定推理圖上,實(shí)現(xiàn)這個(gè)過程并不困難,只需要執(zhí)行以下代碼 (用檢查點(diǎn)替換“xxxxx”)
pythonobject_detection/export_inference_graph.py--input_type=image_tensor--pipeline_config_path=pipeline.config--trained_checkpoint_prefix=train/model.ckpt-xxxxx--output_directory=output
該程序執(zhí)行完后,我們可得到 frozen_inference_graph.pb 以及一堆檢查點(diǎn)文件。
第2步:在視頻流上使用
我們需要從視頻源中提出每一幀,這可以使用 OpenCV 的 VideoCapture 方法完成,代碼如下所示:
cap=cv2.VideoCapture()flag=Truewhile(flag):flag,frame=cap.read()##--ObjectDetectionCode--
第一階段使用的數(shù)據(jù)提取代碼會(huì)使我們的測(cè)試集圖像自動(dòng)創(chuàng)建“test_images”文件夾。我們的模型可以通過執(zhí)行以下命令在測(cè)試集上進(jìn)行工作:
pythonobject_detection/inference.py--input_dir={PATH}--output_dir={PATH}--label_map={PATH}--frozen_graph={PATH}--num_output_classes=1--n_jobs=1--delay=0
實(shí)驗(yàn)
正如前面所講到的,在選擇目標(biāo)檢測(cè)模型時(shí),速度與準(zhǔn)確度不可得兼。對(duì)此我們進(jìn)行了一些實(shí)驗(yàn),測(cè)量使用三種不同的模型檢測(cè)到人的 FPS 和數(shù)量精確度。此外,我們的實(shí)驗(yàn)是在不同的資源約束 (GPU并行約束) 條件下操作的。
▌設(shè)置
我們的實(shí)驗(yàn)選擇了以下的模型,這些模型可以在 TensorFlow 目標(biāo)檢測(cè)API 的Zoo 模塊中找到。
Faster RCNN with ResNet 50
SSD with MobileNet v1
SSD with InceptionNet v2
所有的模型都在 Google Colab 上進(jìn)行了 10k 步訓(xùn)練,通過比較模型檢測(cè)到的人數(shù)與實(shí)際人數(shù)之間的接近程度來衡量計(jì)數(shù)準(zhǔn)確度。在一下約束條件下測(cè)試 FPS 的推理速度。
Single GPU
Two GPUs in parallel
Four GPUs in parallel
Eight GPUs in parallel
結(jié)果
下面的 GIF是我們?cè)跍y(cè)試集上使用 FasterRCNN 輸出的片段。
▌?dòng)?xùn)練時(shí)間
圖11展示了以10 k步 (單位:小時(shí)) 訓(xùn)練每個(gè)模型所需的時(shí)間 (不包括參數(shù)搜索所需要的時(shí)間)
圖11 各模型訓(xùn)練所需時(shí)間
▌速度 (每秒幀數(shù))
在之前的實(shí)驗(yàn)中,我們測(cè)量了3種模型在5種不同資源約束下的 FPS 性能,其測(cè)量結(jié)果如圖12所示:
圖12 使用不同 GPU 數(shù)量下的 FPS 性能
當(dāng)我們使用單個(gè) GPU 時(shí),SSD速度非常快,輕松超越 FasterRCNN 的速度。但是當(dāng) GPU 個(gè)數(shù)增加時(shí),F(xiàn)asterRCNN 很快就會(huì)追上 SSD 。
為了證明我們的結(jié)論:視頻處理系統(tǒng)的速度不能高于圖像輸入系統(tǒng)的速度,我們優(yōu)先讀取圖像。圖13展示了添加延遲后帶有 NobileNet +SSD 的 FPS 改進(jìn)狀況,從圖13中可看出當(dāng)我們加入延遲后,F(xiàn)PS 迅速增加。
圖13 增加不同延遲后模型的 FPS 改進(jìn)狀況
▌?dòng)?jì)數(shù)準(zhǔn)確性
我們將計(jì)數(shù)準(zhǔn)確度定義為目標(biāo)檢測(cè)系統(tǒng)正確識(shí)別出人臉的百分比。圖14是我們每個(gè)模型精確度的表現(xiàn),從圖14中可看出 FasterRCNN 是準(zhǔn)確度最高的模型,MobileNet 的性能優(yōu)于 InceptionNet。
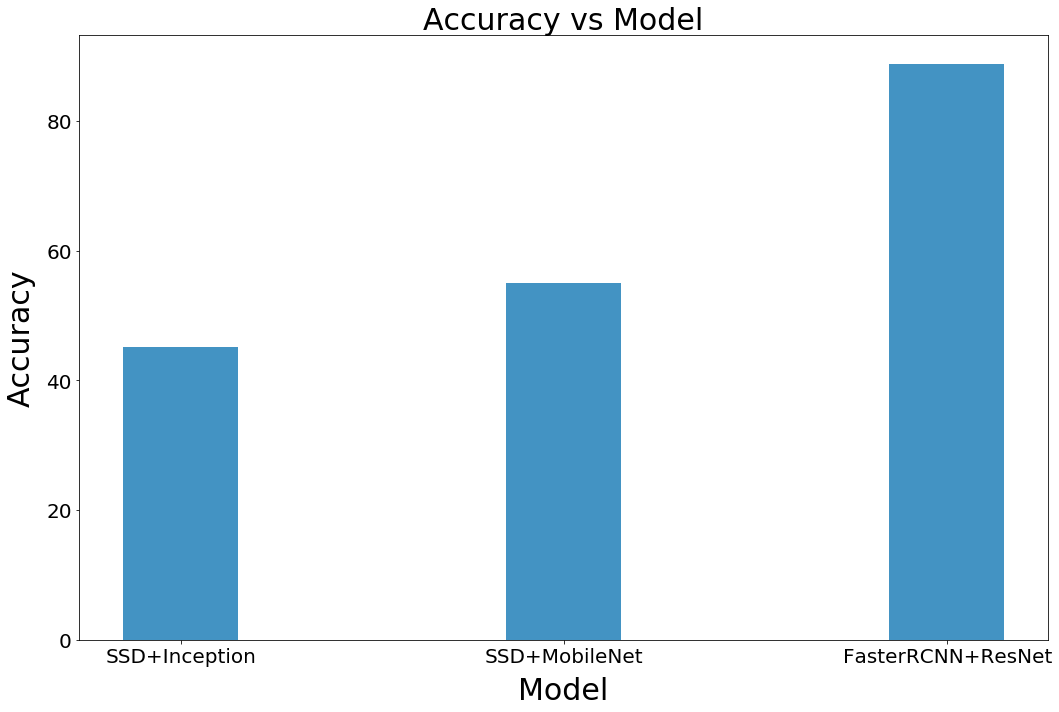
圖 14 各模型計(jì)數(shù)精確度
Nanonets
看到這里相信大家都有一個(gè)共同的感受——步驟太多了吧!是的,如果是這樣的一個(gè)模型在實(shí)際工作即繁重又昂貴。
為此,更好的解決方案就是使用已部署在服務(wù)器上的 API 服務(wù)。Nanonets 就提供了這樣的一個(gè) API,他們將 API 部署在帶有 GPU 的高質(zhì)量硬件上,以便開發(fā)者不用為性能而困擾。
Nanonets可以減少工作的流程的方法在于:我將現(xiàn)有的 XML 注釋轉(zhuǎn)換成 JSON 格式并提供給NanonetsAPI。所以當(dāng)不想進(jìn)行手動(dòng)注釋數(shù)據(jù)集時(shí),可以直接請(qǐng)求NanonetsAPI來為數(shù)據(jù)添加注釋。
上圖表示為減少后的工作流程
Nanonets 的訓(xùn)練時(shí)間大約花了 2 個(gè)小時(shí),就訓(xùn)練時(shí)間而言,Nanonets是明顯的贏家,并且在準(zhǔn)確性方面Nanonets也擊敗了 FasterRCNN。
FasterRCNNCountAccuracy=88.77%NanonetsCountAccuracy=89.66%
下面展現(xiàn)了我們的測(cè)試數(shù)據(jù)集中四個(gè)模型的性能。顯然,兩種 SSD 模型都有點(diǎn)不穩(wěn)定并且精度較低。盡管 FasterRCNN 和 Nanonets 都有較高的精準(zhǔn)度,但Nanonets具有更穩(wěn)定的邊界框。
自動(dòng)監(jiān)控的可信度有多高?
深度學(xué)習(xí)是一種令人驚嘆的工具。但是我們?cè)诙啻蟪潭壬峡梢孕湃挝覀兊谋O(jiān)控系統(tǒng)并自動(dòng)采取行動(dòng)?在以下幾個(gè)情況下,自動(dòng)化過程時(shí)需要引起注意。
▌可疑的結(jié)論
我們不知道深度學(xué)習(xí)算法是如何得出結(jié)論的。即使數(shù)據(jù)的饋送過程很完美,也可能存在大量虛假的成功例子。雖然引導(dǎo)反向傳播在一定程度上可以解釋決策,但是關(guān)于這方面的研究還有待我們進(jìn)一步的研究。
▌對(duì)抗性攻擊
深度學(xué)習(xí)系統(tǒng)很脆弱,對(duì)抗性攻擊類似于圖像的視錯(cuò)覺。計(jì)算出的不明顯干擾會(huì)迫使深度學(xué)習(xí)模型分類失誤。使用相同的原理,研究人員已經(jīng)能夠通過使用 adversarial glasses 來規(guī)避基于深度學(xué)習(xí)的監(jiān)控系統(tǒng)。
▌?wù)`報(bào)
另一個(gè)問題是,如果出現(xiàn)誤報(bào)我們?cè)撛趺醋觥T搯栴}的嚴(yán)重程度取決于應(yīng)用程序本身。例如邊境巡邏系統(tǒng)的誤報(bào)可能比花園監(jiān)控系統(tǒng)更重要。
▌相似的面孔
外觀并不像指紋一樣獨(dú)一無二,同卵雙胞胎是最好的一個(gè)例子。這會(huì)帶來恨大的干擾。
▌數(shù)據(jù)集缺乏多樣性
深度學(xué)習(xí)算法的好壞和數(shù)據(jù)集有很大關(guān)聯(lián),Google 曾將一個(gè)黑人錯(cuò)誤歸類為大猩猩。
注:鑒于 GDPR 和以上原因,關(guān)于監(jiān)控自動(dòng)化的合法性和道德性問題是不可忽視的。此教程也是出于并僅用于學(xué)習(xí)分享目的。在教程中使用的公開數(shù)據(jù)集,所以在使用過程中有責(zé)任確保它的合法性。
-
監(jiān)控系統(tǒng)
+關(guān)注
關(guān)注
21文章
3941瀏覽量
176857 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1700瀏覽量
46127 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5515瀏覽量
121551
原文標(biāo)題:如何通過深度學(xué)習(xí)輕松實(shí)現(xiàn)自動(dòng)化監(jiān)控?
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Nanopi深度學(xué)習(xí)之路(1)深度學(xué)習(xí)框架分析
深度學(xué)習(xí)實(shí)現(xiàn)目標(biāo)檢測(cè)俄羅斯總統(tǒng)***對(duì)沙特王儲(chǔ)攤的“友好攤手”瞬間
CV:基于深度學(xué)習(xí)實(shí)現(xiàn)目標(biāo)檢測(cè)之GUI界面產(chǎn)品設(shè)計(jì)并實(shí)現(xiàn)圖片識(shí)別、視頻識(shí)別、攝像頭識(shí)別
全網(wǎng)唯一一套labview深度學(xué)習(xí)教程:tensorflow+目標(biāo)檢測(cè):龍哥教你學(xué)視覺—LabVIEW深度學(xué)習(xí)教程
【HarmonyOS HiSpark AI Camera】基于深度學(xué)習(xí)的目標(biāo)檢測(cè)系統(tǒng)設(shè)計(jì)
基于深度學(xué)習(xí)模型的點(diǎn)云目標(biāo)檢測(cè)及ROS實(shí)現(xiàn)
如何使用深度學(xué)習(xí)進(jìn)行視頻行人目標(biāo)檢測(cè)
探究深度學(xué)習(xí)在目標(biāo)視覺檢測(cè)中的應(yīng)用與展望
OpenCV使用深度學(xué)習(xí)做邊緣檢測(cè)的流程

基于深度學(xué)習(xí)的目標(biāo)檢測(cè)研究綜述

深度學(xué)習(xí)在目標(biāo)檢測(cè)中的應(yīng)用
簡(jiǎn)述深度學(xué)習(xí)的基準(zhǔn)目標(biāo)檢測(cè)及其衍生算法
如何學(xué)習(xí)基于Tansformer的目標(biāo)檢測(cè)算法
深度學(xué)習(xí)檢測(cè)小目標(biāo)常用方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論