 基于深度學習技術,從頭開始搭建圖像語義搜索引擎
基于深度學習技術,從頭開始搭建圖像語義搜索引擎
編者按:和Insight Data Science AI負責人Emmanuel Ameisen一起,基于深度學習技術,從頭開始搭建圖像語義搜索引擎。
教會電腦看照片
為何使用相似性搜索?
一圖勝千言,更勝萬行代碼。
許多產品的基礎在于展示圖片。當我們瀏覽服飾網站上的套裝時,當我們在Airbnb上尋找度假租屋時,當我們選擇領養的寵物時,它看起來怎么樣常常是我們決策的一個重要因素。我們感知事物的方式是預測我們將喜歡什么樣的事物的強力預測者,因此它是值得測量的有價值的性質。
然而,讓計算機以人類的方式理解圖像在很長時間以來都是一項計算機科學挑戰。2012年以來,在圖像分類或目標檢測之類的感知任務中,深度學習慢慢開始取代方向梯度直方圖這樣的經典方法。這一轉變的重要原因之一是,在足夠大的數據集上訓練之后,深度學習能夠自動提取有意義的表示。
這正是許多團隊——比如Pinterest、StitchFix、Flickr——開始使用深度學習來學習他們的圖像表示的原因,并基于用戶覺得賞心悅目的內容提供推薦。類似地,Insight也使用深度學習創建用于幫助人們認養貓咪、推薦太陽鏡、搜索藝術風格等應用的模型。
許多推薦系統基于協同過濾:利用用戶的相關性做出推薦(“喜歡你喜歡的某物的用戶也喜歡……”)。然而,這些模型需要大量數據才能足夠精確,同時難以處理沒有用戶見過的新物品。而所謂基于內容的推薦系統,則可以使用物品表示,并不存在上面提到的問題。
此外,這些表示可以讓消費者高效地搜索照片庫,查找和剛看過的自拍照相似的圖像(以圖查詢),或者查找包含特定物體(比如汽車)的照片(以文本查詢)。常見的例子包括Google反向圖像搜索(Google Reverse Image Search),以及Google圖像搜索。
基于我們為許多語義理解項目提供技術咨詢的經驗,我們想要撰寫一篇教程,關于如何為圖像和文本數據創建你自己的表示,以及高效進行相似性搜索。讀完本文之后,不管你的數據集有多大,你都應該能夠從頭搭建一個快速的語義搜索模型。
這篇教程有配套的使用streamlit制作的注釋代碼notebook,以及相應的GitHub代碼倉庫hundredblocks/semantic-search,供閱讀時參考。
我們的計劃是什么?
先談談優化
和軟件工程一樣,機器學習中,有很多處理問題的方法,各有各的折衷。如果你正在做一項研究或者一個本地原型,你可以使用非常低效的解決方案。但是如果我們創建的是可維護、可伸縮的相似圖像搜索引擎,那么我們需要考慮我們如何適應數據演變,以及我們的模型可以運行得多快。
讓我們想象一些方法:
我們創建了一個在我們所有圖像上訓練的端到端模型,接受一張圖像作為輸入,然后輸出所有圖像的相似度評分。預測很快(一次前向傳播),但每次新增一張圖像,我們就需要訓練一個新模型。我們也會很快達到這樣一個狀態,分類是如此之多,以致于正確地優化它極為困難。這個方法很快速,但無法擴展至大數據集。此外,我們需要手工標注數據集的圖像相似性,極耗時間。
另一個方法是創建一個接受兩種圖像作為輸入的模型,并輸出這對圖像0到1之間的相似度評分(比如,使用孿生網絡)。這些模型在大數據集上能夠產生精確的結果,但導致了另一種伸縮性問題。我們通常想要查看大量圖像找到相似圖像,所以我們需要為數據集中的每對圖像運行相似性模型。如果我們的模型是CNN,并且我們的圖像數量超過兩位數,那模型就太慢了,慢到我們不會考慮。此外,這個方法只能支持相似圖像搜索,無法支持基于文本搜索圖像。
有更簡單的方法,一個類似詞嵌入的方法。如果我們找到圖像的一種富有表達力的向量表示,或者說嵌入,我們可以通過檢查它們的向量的接近程度計算圖像的相似度。這類搜索方法是一個充分研究過的常見問題,許多庫實現了高速的解決方案(我們這里將使用Annoy)。此外,如果我們事先計算數據集中所有圖像的向量,這個方法既快速(一次前向傳播,和一次高效的相似度搜索),又可伸縮。最后,如果我們成功找到圖像和文本的共同嵌入,我們可以使用它們基于文本搜索圖像!
由于方法3的簡單性和高效性,本文將使用方法3.
我們如何操作?
那么,我們到底如何使用深度學習表示來創建一個搜索引擎?
我們的最終目標是得到一個可以接受圖像作為輸入,輸出相似圖像或標簽,或者接受文本作為輸入,輸出相似文本或圖像的搜索引擎。為此,我們需要經過如下步驟:
根據輸入圖像搜索類似圖像(圖像 -> 圖像)
根據文本搜索類似文本(文本 -> 文本)
生成圖像標簽,基于文本搜索圖像(圖像 <-> 文本)
為了做到這些,我們將使用嵌入,圖像和文本的向量表示。一旦我們有了嵌入,搜索就變成尋找輸入向量的相近向量簡單過程。
我們通過計算圖像嵌入的余弦相似度找到相近向量。相似圖像會有相似的嵌入,也就是說,嵌入之間會有高余弦相似度。
讓我們從數據集開始。
數據集
圖像
我們的圖像數據集總共有1000張圖像,分為20類,每類50張。這個數據集是由Cyrus Rashtchian、Peter Young、Micah Hodosh、Julia Hockenmaier制作的。之前提到過的本文的代碼倉庫中,有自動下載所有圖像文件的腳本。
除了類別之外,數據集中還包括每張圖像的說明。為了增加難度,也為了表明我們的方法的通用性,我們將只使用類別,丟棄所有說明。如前所述,數據集總共包括20個分類:
aeroplanebicyclebirdboatbottlebuscarcatchaircowdining_tabledoghorsemotorbikepersonpotted_plantsheepsofatraintv_monitor
上面是數據集中的一些樣本。我們看到,標簽的噪聲不小:許多照片包含多個類別,而標簽并不總是主要的類別。例如,右下角的圖像的標簽是chair(椅子)而不是person(人),盡管圖像中間有3個人,而椅子毫不引人注意。
文本
我們將加載在維基百科數據上預訓練的詞嵌入(本文將使用Glove模型)。我們將使用這些向量在我們的語義搜索中納入文本。如果你不熟悉詞向量,可以參考我的NLP教程的第七步。
圖像 -> 圖像
從簡單的開始
我們將使用在大型數據集(Imagenet)上預訓練的模型。這里我們使用的是VGG16,不過你也可以使用任何其他最近的CNN架構。我們使用VGG16生成圖像的嵌入。
VGG16(圖片來源:Data Wow博客)
我們說的生成嵌入是什么意思?我們將使用預訓練模型,直到倒數第二層,然后儲存激活的值。下圖中,嵌入層加上了綠色高亮,這一層在最后的分類層之前。
一旦我們使用模型生成圖像特征后,我們就可以把它們儲存在磁盤上,然后可以重復利用,無需再次推理!這正是嵌入在實際應用中如此流行的原因之一,因為它們帶來了巨大的效率提升。將其儲存在磁盤上之后,我們將使用Annoy為嵌入創建一個高速索引,這讓我們可以為任意給定嵌入快速尋找最近的嵌入。
在我們的嵌入中,每張圖像表示為一個4096維的稀疏向量。之所以向量是稀疏的,是因為我們取的是激活函數之后的值,而激活函數將負值轉為零。
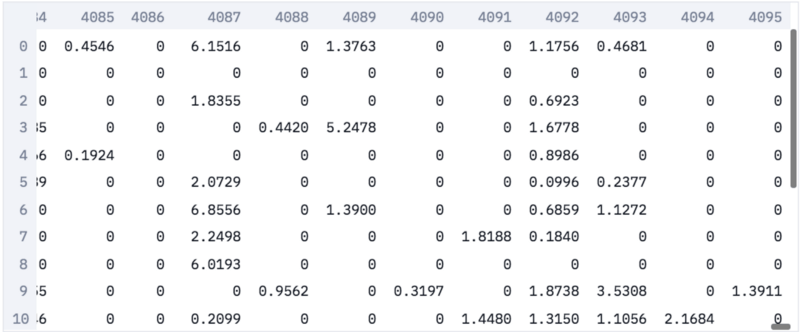
圖像嵌入
基于嵌入通過圖像搜索
現在我們可以直接接受一張圖像作為輸入,得到它的嵌入,然后查詢我們的高速索引找到相似嵌入,也就是相似圖像。
這一點特別有用,因為圖像標簽常常包含噪聲,通過圖像搜索通常優于通過標簽搜索。
例如,在我們的數據集中,我們有cat類(貓),也有bottle類(瓶)。
你覺得下面這張圖像的標簽是什么?
圖像縮放至224x224,這是神經網絡看到的分辨率
很不幸,這張圖像被打上了瓶標簽。這是真實數據集中常常碰到的問題。給圖像打上唯一的標簽限制性很大,因此我們希望使用更細致的表示。好在這正是深度學習擅長的!
讓我們看看基于嵌入的圖像搜索表現如何?
搜索dataset/bottle/2008_000112.jpg的相似圖像……
太棒了——基本上搜到的都是關于貓的圖像,這看起來很合理!我們的預訓練網絡在多種多樣的圖像上訓練過,包括貓圖,所以能夠精確地找到相似圖像,即使它從未在這一特定數據集上訓練過。
然而,下排中間的圖像顯示的是架子上的瓶子。總的來說,這一方法在尋找相似圖像上表現不錯,不過有時我們只對圖像的局部感興趣。
例如,在上面的搜索中,我們可能只想搜索相似的貓咪,而不是相似的瓶子。
半監督搜索
解決這一問題的一個常用方法是首先使用目標檢測模型檢測出貓,然后對原圖進行裁切,通過裁切出的貓圖進行搜索。
不過這會大大增加計算負擔,所以有可能的話,我們想避免使用這種方法。
有一個更簡單的“取巧”方法,重新加權激活。我們加載原本拋棄掉的最后一層的權重,然后使用和我們搜尋的分類相連的權重,重新加權嵌入。這個很酷的技巧最初是由我在Insight的同事Daweon Ryu告訴我的。例如,我們將使用Siamese cat(暹邏貓)分類的權重重新加權數據集的激活(下圖中加上了綠色高亮)。你可以查看前面提到的配套notebook,了解實現細節。
顯示的分類層僅供參考,并不在嵌入中使用
讓我們看看使用Imagenet的分類284(即Siamese cat)加權激活后效果如何?
基于加權特征搜索dataset/bottle/2008_000112.jpg的相似圖像……
我們可以看到,搜索加上了偏置,尋找類似暹邏貓的東西。結果中不再有瓶子圖像了,這很好。不過你可能注意到我們的最后一張圖像是一只羊!有意思,給我們的模型加上偏置導致了不同種類的錯誤。就我們目前的應用范圍來說,這種錯誤比之前的錯誤更加合理。
我們已經見到了相似圖像搜索更寬泛的方式,通過以模型的特定分類為條件進行搜索。
這是一項很棒的進展,但由于我們使用的是在Imagenet上預訓練的模型,我們因此受到1000個Imagenet分類的限制。這些分類遠遠說不上包羅萬象(例如,它們缺乏關于人的類型),所以,我們想要找到更靈活的理想方案。此外,如果我們只是想在不提供輸入圖像的前提下搜索貓圖呢?
為了達成這一點,我們將使用簡單技巧之外的方法,利用可以理解單詞語義的模型。
文本 -> 文本
說到底,沒什么不同
用于文本的嵌入
繞行至自然語言處理(NLP)的世界,我們可以類似的方法索引和搜索單詞。
我們將載入Glove預訓練的向量,這些向量是通過爬取所有維基百科文章,然后學習數據集中單詞之間的語言聯系得到的。
和之前一樣,我們創建一份索引,這次索引包括的是所有的Glove向量。接著,我們可以搜索我們的嵌入以查找相近單詞。
例如,搜索said將返回如下的[單詞, 距離]列表:
['said', 0.0]
['told', 0.688713550567627]
['spokesman', 0.7859575152397156]
['asked', 0.872875452041626]
['noting', 0.9151610732078552]
['warned', 0.915908694267273]
['referring', 0.9276227951049805]
['reporters', 0.9325974583625793]
['stressed', 0.9445104002952576]
['tuesday', 0.9446316957473755]
這看起來非常合理,絕大多數單詞的含義都很相似,或者表示相宜的概念。最后一項結果(tuesday,周二)則表明,這模型遠不完美。不過這個模型將給我們一個好的開始。現在,讓我們嘗試將單詞和圖像同時納入我們的模型。
維度問題
使用嵌入的距離作為搜索方法相當通用,但我們的單詞表示和圖像表示看起來不兼容。圖像嵌入的維度是4096,而單詞嵌入的維度是300——我們怎么能用一種嵌入搜索另一種呢?此外,即使兩種嵌入維度相等,它們也是通過完全不同的方法訓練的,因此圖像和相關單詞碰巧具有相同嵌入的概率極低。我們需要訓練聯合模型。
圖像 <-> 文本
世界的碰撞
現在,讓我們創建一個混合模型,可以從單詞到圖像,也可以從圖像到單詞。
在這篇教程中,這是我們第一次實際訓練自己的模型,該模型的靈感來自一篇杰出的論文DeViSE。我們不會精確地重新實現論文中的算法,不過我們的模型基本遵循論文的主要思路。(你也可以參考fast.ai第11課,其中包含了論文算法的一個略微不同的實現)。
主要思路是通過重新訓練圖像模型,改變標簽的類別來組合兩種表示。
我們通常訓練圖像分類器從許多類別(Imagenet有1000個類別)中選中一個。也就是說——以Imagenet為例——最后一層是一個表示每個分類概率的1000維向量。這意味著我們的模型沒有分類相似性的語義理解,將“貓”圖分類為“狗”,在模型看來,和將其分類為“飛機”錯得一樣離譜。
在我們的混合模型中,我們將模型的最后一層替換為類別的詞向量。這讓我們的模型得以學習圖像語義和單詞語義間的映射,同時,相似分類將彼此接近(因為,相比“飛機”,“貓”的詞向量和“狗”的詞向量更接近)。我們不預測1000維的稀疏向量(除了一個分量為1外,所有分量均為0),我們將預測300維的語義豐富的詞向量。
我們通過添加兩個密集層達成這一點:
大小為2000的中間層
大小為300的輸出層(大小等于Glove的詞向量)
下面是在Imagenet上訓練的模型的架構:
這是改動之后的架構:
訓練模型
我們接著從數據集中分出訓練集,再訓練我們的模型,以學習預測與圖像相關的詞向量。例如,對類別為貓的圖像而言,我們嘗試預測300維的“貓”詞向量。
再訓練需要一些時間,但仍然比在Imagenet上訓練要快得多。作為參考,在我不帶GPU的筆記本上,再訓練耗時6到7小時。
值得注意的是這一方法的雄心壯志。相比通常的數據集(Imagenet有一百萬張圖像),我們這里使用的訓練集(數據集的80%,也就是800張圖像)根本不算什么(3個數量級的差異)。如果我們使用傳統的基于類別訓練的技術,我們不會指望我們的模型在測試集上表現良好,更別說在全新的樣本上了。
一旦模型訓練完成,我們將創建相應的Glove詞向量索引和圖像的高速索引(運行模型于數據集上的所有圖像),并儲存到磁盤上。
標記
現在,提取任意圖像的標簽非常簡單。我們只需將圖像傳入訓練好的網絡,保存網絡輸出的300維向量,并在Glove英文單詞索引中找到最接近的單詞。讓我們用一張圖像來試一下——這張圖像在數據集中被打上了bottle(瓶)標簽,不過它包含多種物品。
下面是生成的標簽:(注釋為譯者所加)
[6676, 'bottle', 0.3879561722278595] # 瓶
[7494, 'bottles', 0.7513495683670044] # 瓶(復數)
[12780, 'cans', 0.9817070364952087] # 罐頭
[16883, 'vodka', 0.9828150272369385] # 伏特加
[16720, 'jar', 1.0084964036941528] # 廣口瓶
[12714, 'soda', 1.0182772874832153] # 蘇打水
[23279, 'jars', 1.0454961061477661] # 廣口瓶(復數)
[3754, 'plastic', 1.0530102252960205] # 塑料
[19045, 'whiskey', 1.061428427696228] # 威士忌
[4769, 'bag', 1.0815287828445435] # 袋
這個結果相當驚人,大多數標簽高度相關。這一方法仍然有提升的空間,但它對圖像中的大多數物品的理解相當好。模型學習提取許多相關的標簽,甚至包括沒有訓練過的類別!
通過文本搜索圖像
最重要的是,我們可以基于聯合嵌入,通過任何單詞搜索我們的圖像數據庫。我們只需從Glove獲取預訓練的詞嵌入,然后找到具有相似嵌入的圖像。
讓我們首先從訓練數據集中的一個單詞dog(狗)開始:
好,相當好的結果——但是任何基于標簽訓練的分類器也能給出這樣的結果!讓我們增加難度,搜索關鍵詞ocean(海洋),這是我們的數據集中沒有包含的類別。
太棒了——我們的模型理解ocean(海洋)和water(水)相似,并且返回了很多boat(船)分類的圖像。
試試street(街道)?
這里,返回的圖像來自多個分類(汽車、狗、自行車、巴士、人),不過大部分都包含街道或者靠近街道,盡管我們在訓練模型的時候從未使用過這一概念。由于我們通過預訓練的詞向量,利用外部知識學習圖像到向量的一種映射,該映射比簡單的類別具有更豐富的語義,所以我們的模型能夠很好地概括外部概念。
單詞之外
英語詞匯增加得很快,但還沒有快到為所有東西發明一個單詞。例如,在發布這篇文章的時候,還沒有一個英語單詞表示“躺在沙發上的貓”,這是一個再合理不過的可以在搜索引擎中輸入的查詢。如果我們希望同時搜索多個單詞,我們可以使用一個非常簡單的方法,利用詞向量的算術性質。實際上,把兩個詞向量加起來一般來說效果非常好。所以如果我們直接使用“貓”、“沙發”的平均詞向量進行搜索,我們可以希望得到和貓相似,同時和沙發相似的圖像,或者說,貓在沙發上的圖像。
讓我們試著使用這一混合嵌入搜索!
結果非常棒,大多數圖像都包含某種毛茸茸的動物和沙發(我特別喜歡第二排最左的圖像,看起來像放在沙發邊上的一袋皮毛)!我們基于單個單詞訓練的模型,可以處理兩個單詞的組合。我們現在并沒有造出Google圖像搜索,但就這一相對簡單的架構而言,這毫無疑問是令人印象深刻的結果。
實際上,這一方法可以很自然地擴展到多個領域(比如這個聯合嵌入代碼和英語文本的例子),所以我們希望能了解你最后將這一方法應用到了哪里。
結語
我希望你覺得這篇文章有干貨,并且驅散了基于內容的推薦和語義搜索的一些迷霧。如果你有任何問題或評論,或者想要分享你用這篇教程的方法創造的東西,可以在Twitter上聯系我(EmmanuelAmeisen)!
-
圖像
+關注
關注
2文章
1089瀏覽量
40572 -
數據集
+關注
關注
4文章
1209瀏覽量
24830 -
深度學習
+關注
關注
73文章
5513瀏覽量
121544
原文標題:深度學習表示不可思議的威力:從頭搭建圖像語義搜索引擎
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
[分享]最強山寨版搜索引擎震驚世界-熊熊搜索
參加搜索引擎營銷SEM培訓的好處?
搜索引擎查詢日志的聚類
教育網BBS搜索引擎設計與實現
基于元數據的語義搜索技術研究
主題搜索引擎的研究
網絡搜索引擎,網絡搜索引擎的工作原理

垂直搜索引擎是什么_垂直搜索引擎有哪些
介紹五個具有高級功能的搜索引擎
蘋果自研的搜索引擎干的過谷歌嗎?
NAS下搭建linux命令搜索引擎教程
使用Rust語言重寫的代碼搜索引擎黑鳥系統Blackbird正式啟用





 工商網監
工商網監
評論