") NLP的介紹和如何利用機(jī)器學(xué)習(xí)進(jìn)行NLP以及三種NLP技術(shù)的詳細(xì)介紹
NLP的介紹和如何利用機(jī)器學(xué)習(xí)進(jìn)行NLP以及三種NLP技術(shù)的詳細(xì)介紹
本文用簡(jiǎn)潔易懂的語(yǔ)言,講述了自然語(yǔ)言處理(NLP)的前世今生。從什么是NLP到為什么要學(xué)習(xí)NLP,再到如何利用機(jī)器學(xué)習(xí)進(jìn)行NLP,值得一讀。這是該系列的第一部分,介紹了三種NLP技術(shù):文本嵌入、機(jī)器翻譯、Dialogue 和 Conversations。
▌什么是NLP?
自然語(yǔ)言處理(NLP)是計(jì)算機(jī)科學(xué)、人工智能和語(yǔ)言學(xué)的交叉領(lǐng)域。目的是讓計(jì)算機(jī)處理或“理解”自然語(yǔ)言,以執(zhí)行諸如語(yǔ)言翻譯和問題回答等任務(wù)。
隨著語(yǔ)音接口和聊天機(jī)器人的興起,NLP成為了信息時(shí)代最重要的技術(shù)之一,是人工智能的重要組成部分。充分理解和表達(dá)語(yǔ)言的含義是一個(gè)極其困難的目標(biāo)。為什么?因?yàn)槿祟惖恼Z(yǔ)言很特別。
人類語(yǔ)言有何特別之處?如下所示幾個(gè)方面:
人類語(yǔ)言是一種專門用來(lái)傳達(dá)說(shuō)話者(或作者)意圖的系統(tǒng)。這不僅是一個(gè)環(huán)境信號(hào),也是一種深思熟慮的交流。此外,它使用了一種編碼,小孩可以很快學(xué)會(huì)。同時(shí)它也是會(huì)改變的。
人類語(yǔ)言大多是離散的/符號(hào)的/分類的信號(hào)系統(tǒng),大概是因?yàn)檫@樣信號(hào)可靠性更高。
一種語(yǔ)言的分類符號(hào)可以以幾種方式編碼為通信信號(hào):聲音,手勢(shì),書寫,圖像等。人類語(yǔ)言可以用其中任何一種信號(hào)表示。
人類語(yǔ)言是不明確的(與編程和其他正式語(yǔ)言不同)。因此,對(duì)人類語(yǔ)言的表達(dá)、學(xué)習(xí)和使用語(yǔ)言/情境/語(yǔ)境/詞匯/視覺知識(shí)具有高度的復(fù)雜性。
▌為什么要學(xué)習(xí)NLP?
從這個(gè)研究領(lǐng)域衍生出一批快速增長(zhǎng)的有用的應(yīng)用程序。它們從簡(jiǎn)單到復(fù)雜。以下是其中幾個(gè):
拼寫檢查,關(guān)鍵字搜索,查找同義詞
從網(wǎng)站提取信息,例如:產(chǎn)品價(jià)格,日期,地點(diǎn),人員或公司名稱
分類:學(xué)校課文的閱讀水平,長(zhǎng)文檔的積極/消極情感分析
機(jī)器翻譯
口語(yǔ)對(duì)話系統(tǒng)
復(fù)雜的問答系統(tǒng)
事實(shí)上,這些應(yīng)用程序已經(jīng)在工業(yè)中得到了廣泛應(yīng)用:從搜索(書面和口頭)到在線廣告匹配; 從自動(dòng)/輔助翻譯到營(yíng)銷或財(cái)務(wù)/交易的情感分析; 從語(yǔ)音識(shí)別到聊天機(jī)器人/對(duì)話代理(自動(dòng)化客戶支持,控制設(shè)備,訂購(gòu)商品)。
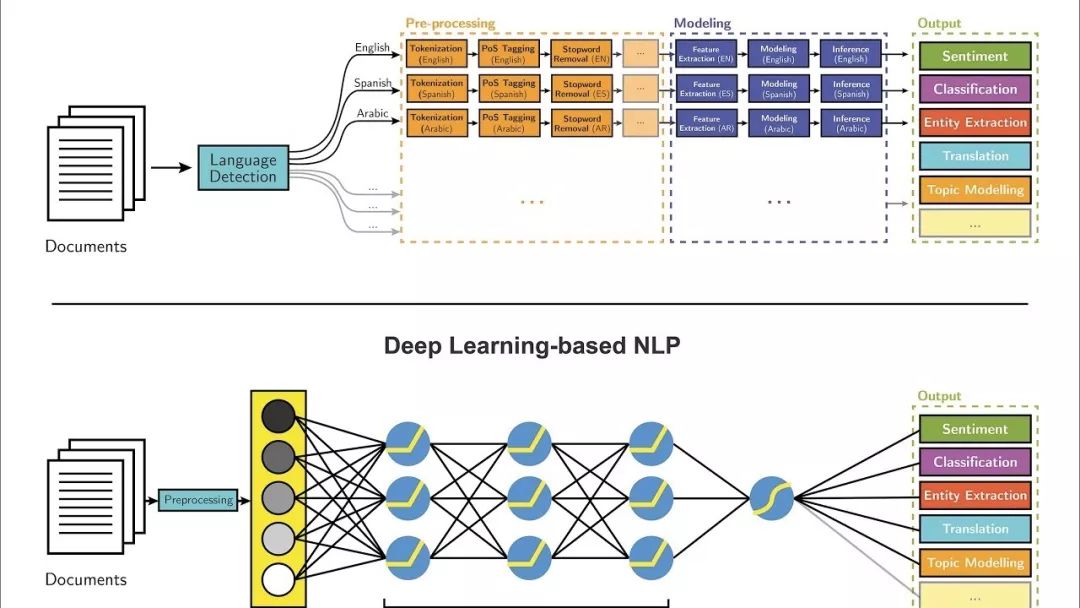
大多數(shù)NLP技術(shù)都是由深度學(xué)習(xí)(機(jī)器學(xué)習(xí)的一個(gè)子領(lǐng)域)驅(qū)動(dòng)的。在本世紀(jì)初,深度學(xué)習(xí)才開始再次獲得重視,其主要原因如下:
大量的訓(xùn)練數(shù)據(jù)。
具有先進(jìn)功能和改進(jìn)性能的新模型和算法:更靈活的中間表示學(xué)習(xí),更有效的端到端聯(lián)合系統(tǒng)學(xué)習(xí),更有效的上下文使用和任務(wù)之間的轉(zhuǎn)移學(xué)習(xí)方法,以及更好的正則化和優(yōu)化方法。
大多數(shù)機(jī)器學(xué)習(xí)方法都能很好地工作,因?yàn)槿斯ぴO(shè)計(jì)的表示和輸入特征,以及權(quán)重優(yōu)化,從而可以最好地進(jìn)行最終預(yù)測(cè)。另一方面,在深度學(xué)習(xí)中,表示學(xué)習(xí)試圖自動(dòng)學(xué)習(xí)來(lái)自原始輸入的良好特征或表示。在機(jī)器學(xué)習(xí)中,人工設(shè)計(jì)的特性常常被過度指定、不完整,并且需要很長(zhǎng)時(shí)間來(lái)設(shè)計(jì)和驗(yàn)證。相比之下,深度學(xué)習(xí)的學(xué)習(xí)特點(diǎn)是易于調(diào)整和快速學(xué)習(xí)。
深度學(xué)習(xí)提供了一個(gè)非常靈活,通用且可學(xué)習(xí)的框架,用于呈現(xiàn)視覺和語(yǔ)言信息的世界。最初,它在語(yǔ)音識(shí)別和計(jì)算機(jī)視覺等領(lǐng)域取得了突破性進(jìn)展。最近,深度學(xué)習(xí)方法在許多不同的NLP任務(wù)中獲得了很高的性能。這些模型通常可以通過一個(gè)端到端模型進(jìn)行訓(xùn)練,不需要傳統(tǒng)的、特定于任務(wù)的特性工程。
最近,我完成了斯坦福大學(xué)的CS224n自然語(yǔ)言處理與深度學(xué)習(xí)的綜合課程。本課程全面介紹應(yīng)用于NLP的深度學(xué)習(xí)的前沿研究。在模型方面,它涵蓋了詞向量表示,基于窗口的神經(jīng)網(wǎng)絡(luò),循環(huán)神經(jīng)網(wǎng)絡(luò),長(zhǎng)-短期記憶模型,遞歸神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò),以及一些涉及存儲(chǔ)器組件的最新模型。
在編程方面,我學(xué)會(huì)了實(shí)現(xiàn),訓(xùn)練,調(diào)試,可視化和創(chuàng)建我自己的神經(jīng)網(wǎng)絡(luò)模型。在這個(gè)2部分組成的系列中,我想分享我學(xué)到的7種主要的NLP技術(shù),以及使用它們的主要深度學(xué)習(xí)模型和應(yīng)用。
注意:您可以在這個(gè)GitHub Repo上訪問來(lái)自CSS 224的課程和編程作業(yè)。
https://github.com/khanhnamle1994/natural-language-processing
▌技術(shù)1:文本嵌入(Text Embeddings)
在傳統(tǒng)的NLP中, 我們把單詞看成是離散符號(hào), 然后用一個(gè)one-hot向量來(lái)表示。向量的維數(shù)是整個(gè)詞庫(kù)中單詞的數(shù)量。單詞作為離散符號(hào)的問題在于, 對(duì)于一個(gè)one-hot向量來(lái)說(shuō),沒有自然的相似性概念。因此, 另一種方法是學(xué)習(xí)在向量本身中的編碼相似性。核心思想是一個(gè)詞的意思是由經(jīng)常出現(xiàn)在其附近的詞給出的。
文本嵌入是字符串的實(shí)值向量表示形式。我們?yōu)槊總€(gè)單詞構(gòu)建一個(gè)稠密的向量, 這樣做是以便它與出現(xiàn)在相似上下文中的單詞向量相似。對(duì)于大多數(shù)深度NLP任務(wù)而言,詞嵌入被認(rèn)為是一個(gè)很好的起點(diǎn)。它們?cè)试S深度學(xué)習(xí)在較小的數(shù)據(jù)集上有效,因?yàn)樗鼈兺ǔJ巧疃葘W(xué)習(xí)體系結(jié)構(gòu)的第一批輸入,也是NLP中最流行的遷移學(xué)習(xí)方式。詞嵌入中最流行的方法是Google(Mikolov)的Word2vec和Stanford(Pennington,Socher和Manning)的GloVe。讓我們深入研究這些詞匯表達(dá):
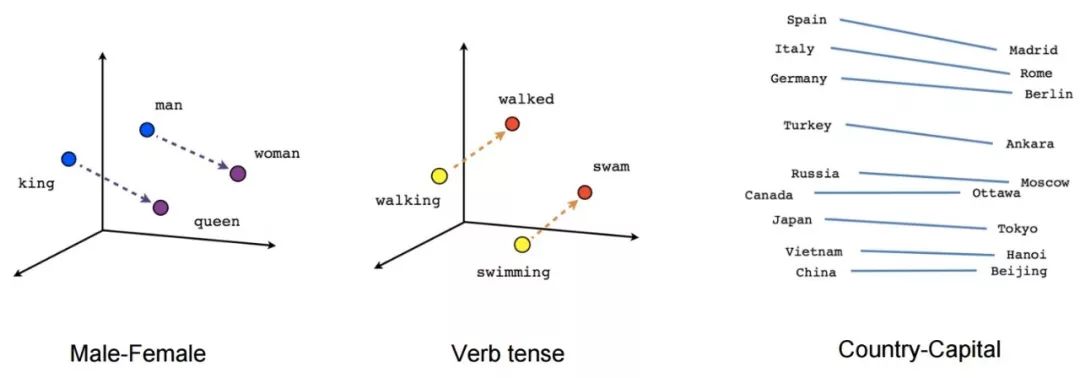
在Word2vec中,我們有一個(gè)龐大的文本語(yǔ)料庫(kù),其中固定詞匯表中的每個(gè)詞都由一個(gè)向量表示。然后我們?cè)谖谋局斜闅v每一個(gè)位置t,它有一個(gè)中心詞c和上下文詞o。接下來(lái),我們使用c和o的詞向量的相似度來(lái)計(jì)算給定c的o的概率(反之亦然)。我們不斷地調(diào)整詞向量來(lái)最大化這個(gè)概率。
為了有效地訓(xùn)練Word2vec,我們可以從數(shù)據(jù)集中去除無(wú)意義(或更高頻率)的單詞(例如a,the,of,then ...)。這有助于提升模型的準(zhǔn)確性和減少訓(xùn)練時(shí)間。 此外,我們可以對(duì)每個(gè)輸入使用negative sampling,即更新所有正確標(biāo)簽的權(quán)重,但只更新少數(shù)不正確標(biāo)簽的權(quán)重。
Word2vec有兩個(gè)值得注意的模型變體:
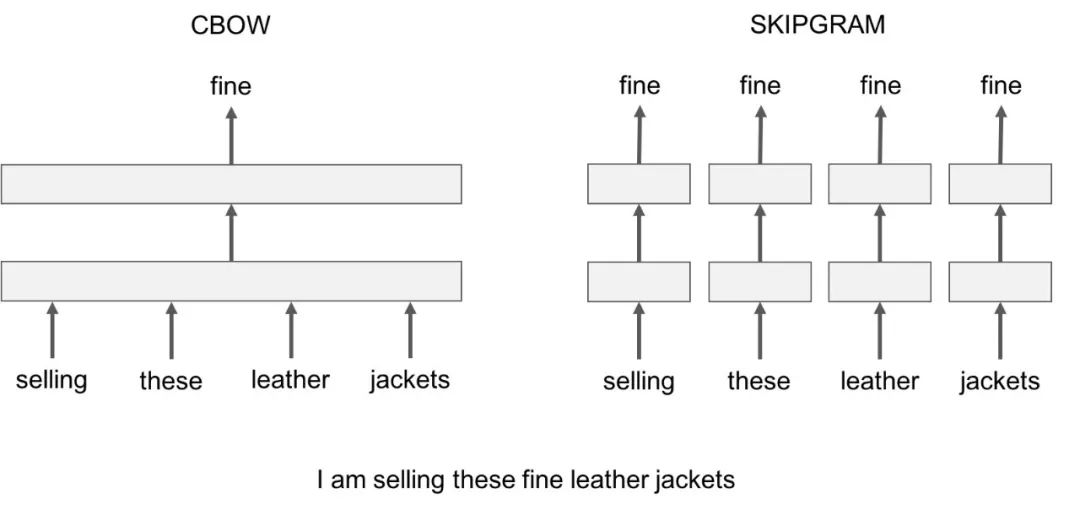
Skip-Gram:我們考慮一個(gè)包含k個(gè)連續(xù)項(xiàng)的上下文窗口。然后我們跳過其中一個(gè)詞,嘗試學(xué)習(xí)一個(gè)神經(jīng)網(wǎng)絡(luò),它獲取除跳過的項(xiàng)之外的所有項(xiàng)并預(yù)測(cè)跳過的項(xiàng)。因此,如果兩個(gè)詞在一個(gè)大語(yǔ)料庫(kù)中重復(fù)地共享相似的上下文,那么這些詞的嵌入向量就是相似的。
Continuous Bag of Words:我們?cè)谝粋€(gè)大的語(yǔ)料庫(kù)中獲取大量的句子。每當(dāng)我們看到一個(gè)單詞,我們就會(huì)聯(lián)想到周圍的單詞。然后我們將上下文單詞輸入到一個(gè)神經(jīng)網(wǎng)絡(luò)中,并在這個(gè)上下文中預(yù)測(cè)這個(gè)中心詞。當(dāng)我們有數(shù)千個(gè)這樣的上下文詞和中心詞時(shí),我們就會(huì)有一個(gè)用于神經(jīng)網(wǎng)絡(luò)的數(shù)據(jù)集的實(shí)例。我們訓(xùn)練神經(jīng)網(wǎng)絡(luò),最后編碼的隱藏層輸出表示一個(gè)特定的詞嵌入。當(dāng)我們通過大量的句子進(jìn)行訓(xùn)練時(shí),相似上下文中的單詞會(huì)得到相似的向量。
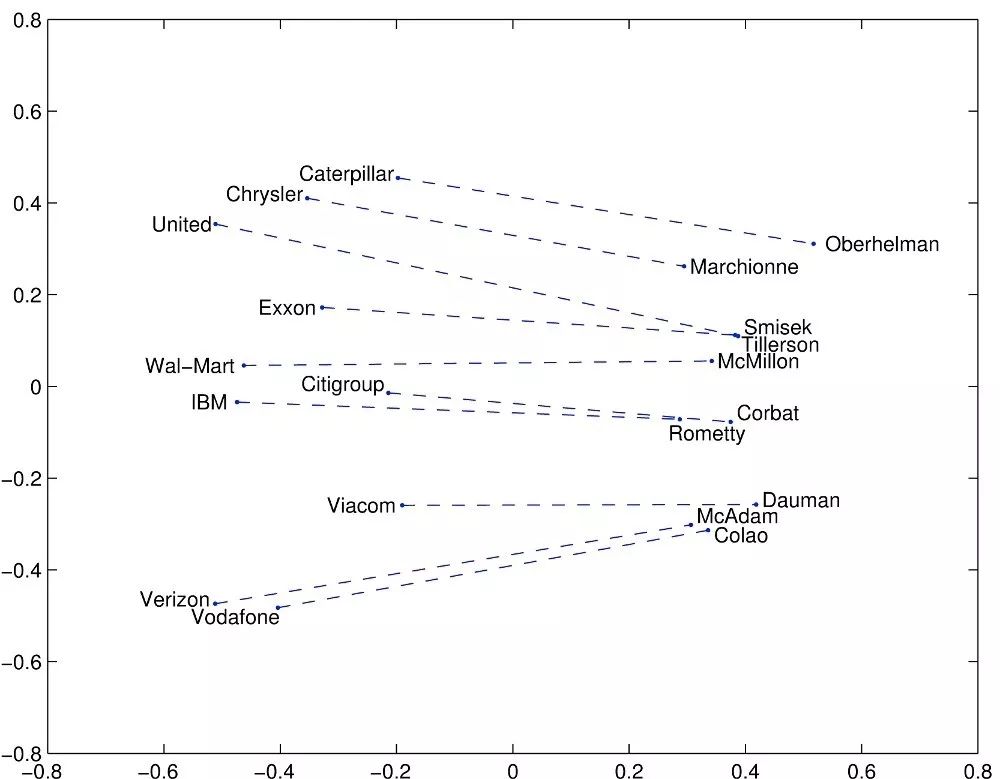
Skip-Gram和CBOW的一個(gè)不足是它們都是基于窗口的模型,這意味著語(yǔ)料庫(kù)的共現(xiàn)(co-occurrence)統(tǒng)計(jì)信息沒有得到有效利用,導(dǎo)致次優(yōu)嵌入(suboptimal embeddings)。GloVe模型試圖通過將一個(gè)詞的含義與整個(gè)觀察語(yǔ)料庫(kù)的結(jié)構(gòu)結(jié)合起來(lái),來(lái)解決這個(gè)問題。
GloVe模型試圖通過捕獲嵌入整個(gè)觀察語(yǔ)料庫(kù)結(jié)構(gòu)的一個(gè)詞的含義來(lái)解決這個(gè)問題。為了做到這一點(diǎn),模型對(duì)單詞的全局共現(xiàn)數(shù)進(jìn)行訓(xùn)練,并通過最小化最小二乘誤差來(lái)充分利用統(tǒng)計(jì)數(shù)據(jù),從而產(chǎn)生一個(gè)有意義的子結(jié)構(gòu)的詞向量空間。這樣的做法用向量距離來(lái)保留了單詞的相似性。
除了這兩種文本嵌入外,還有許多最近開發(fā)的高級(jí)模型,包括FastText,Poincare Embeddings,sense2vec,Skip-Thought,Adaptive Skip-Gram。我強(qiáng)烈建議大家去看一看。
▌技術(shù)2:機(jī)器翻譯
機(jī)器翻譯是語(yǔ)言理解的經(jīng)典測(cè)試。它由語(yǔ)言分析和語(yǔ)言生成兩部分組成。大型機(jī)器翻譯系統(tǒng)有巨大的商業(yè)用途,因?yàn)槿蛘Z(yǔ)言是一個(gè)每年400億美元的產(chǎn)業(yè)。給你一些值得注意的例子:
谷歌翻譯每天翻譯1000億字。
Facebook使用機(jī)器翻譯自動(dòng)翻譯帖子和評(píng)論中的文字,以打破語(yǔ)言障礙,讓世界各地的人們相互交流。
eBay使用機(jī)器翻譯技術(shù)來(lái)實(shí)現(xiàn)跨境貿(mào)易,并連接世界各地的買家和賣家。
微軟為Android、iOS和亞馬遜Fire的終端用戶和開發(fā)人員提供基于人工智能的翻譯,無(wú)論他們是否可以訪問互聯(lián)網(wǎng)。
早在2016年,Systran就成為首家推出30多種語(yǔ)言的神經(jīng)機(jī)器翻譯引擎的軟件提供商。
在傳統(tǒng)的機(jī)器翻譯系統(tǒng)中,我們必須使用平行語(yǔ)料庫(kù)——文本的集合,每個(gè)文本都被翻譯成一種或多種不同于原文的其他語(yǔ)言。例如,給定源語(yǔ)言f(例如法語(yǔ))和目標(biāo)語(yǔ)言e(例如英語(yǔ)),我們需要構(gòu)建多個(gè)統(tǒng)計(jì)模型,包括使用貝葉斯規(guī)則的概率公式、在平行語(yǔ)料庫(kù)上訓(xùn)練的翻譯模型p(f|e)和在僅限英語(yǔ)語(yǔ)料庫(kù)上訓(xùn)練的語(yǔ)言模型p(e)。
不用說(shuō),這種方法忽略了數(shù)百個(gè)重要的細(xì)節(jié),需要大量的人工特征工程,由許多不同的和獨(dú)立的機(jī)器學(xué)習(xí)問題組成,總體而言是一個(gè)非常復(fù)雜的系統(tǒng)。
神經(jīng)機(jī)器翻譯是通過一個(gè)稱為遞歸神經(jīng)網(wǎng)絡(luò)(RNN)的大型人工神經(jīng)網(wǎng)絡(luò)對(duì)整個(gè)過程進(jìn)行建模的方法。 RNN是一個(gè)有狀態(tài)的神經(jīng)網(wǎng)絡(luò),它和過去通過時(shí)間來(lái)連接。神經(jīng)元的信息不僅來(lái)自上一層,而且來(lái)自更前一層的信息。這意味著,我們輸入和訓(xùn)練網(wǎng)絡(luò)的順序很重要:輸入“Donald”,然后輸入“Trump”,可能會(huì)產(chǎn)生與輸入“Trump”和輸入“Donald”不同的結(jié)果。
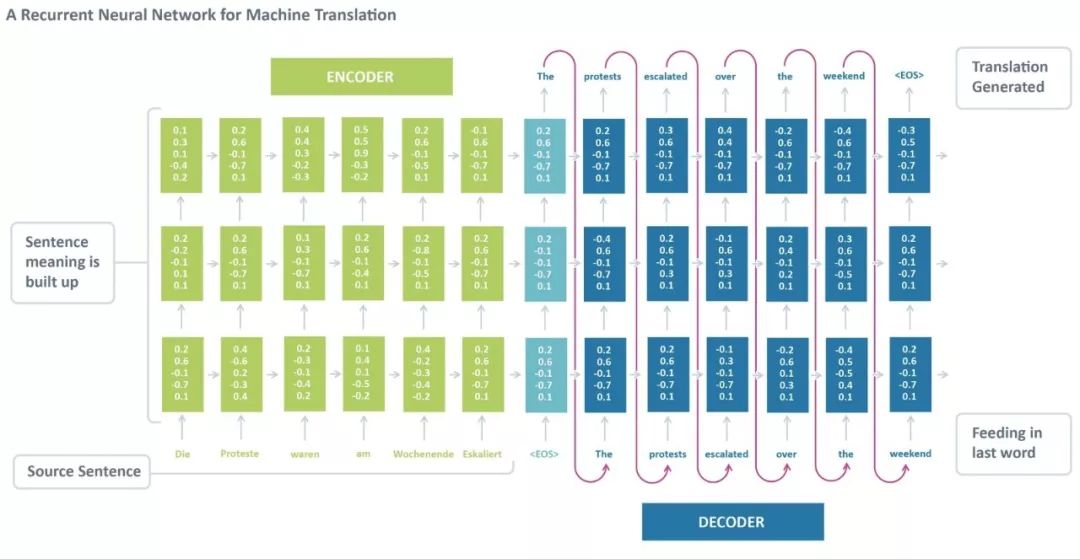
標(biāo)準(zhǔn)的神經(jīng)機(jī)器翻譯是一種端到端神經(jīng)網(wǎng)絡(luò),源語(yǔ)句由一個(gè)稱為編碼器(encoder)的RNN編碼,目標(biāo)詞使用另一個(gè)稱為解碼器(decoder)的RNN進(jìn)行預(yù)測(cè)。RNN編碼器逐個(gè)讀取一個(gè)源語(yǔ)句,然后在最后的隱藏狀態(tài)匯總整個(gè)源語(yǔ)句。RNN解碼器使用反向傳播學(xué)習(xí)這個(gè)最后的匯總并返回傳播后版本。神經(jīng)機(jī)器翻譯從2014年作為一項(xiàng)邊緣研究活動(dòng)發(fā)展到2016年成為被廣泛采用的機(jī)器翻譯的主流方式,這一過程令人驚嘆。那么,使用神經(jīng)機(jī)器翻譯的最大優(yōu)勢(shì)是什么?
端到端訓(xùn)練:NMT中的所有參數(shù)都被同時(shí)優(yōu)化,以最小化網(wǎng)絡(luò)輸出上的損失函數(shù)。
分布式表示具有優(yōu)勢(shì):NMT更好地利用單詞和短語(yǔ)的相似性。
更好地探索上下文:NMT可以使用更多的上下文——源文本和部分目標(biāo)文本——來(lái)更準(zhǔn)確地翻譯。
更流暢的文本生成:深度學(xué)習(xí)的文本生成比平行語(yǔ)料庫(kù)的生成質(zhì)量高得多。
RNNs的一個(gè)大問題是梯度消失(或爆炸)問題,其中取決于所使用的激活函數(shù),隨著時(shí)間的推移信息會(huì)迅速丟失。直觀地說(shuō),這不會(huì)是一個(gè)很大的問題。因?yàn)檫@些只是權(quán)重而不是神經(jīng)元狀態(tài),但是時(shí)間的權(quán)重實(shí)際上是存儲(chǔ)過去信息的地方;如果權(quán)重達(dá)到了0或1,000,000,那么前面的狀態(tài)將不會(huì)提供很多信息。因此,RNNs在記憶之前的單詞非常困難,并且只能根據(jù)最近的單詞做出預(yù)測(cè)。
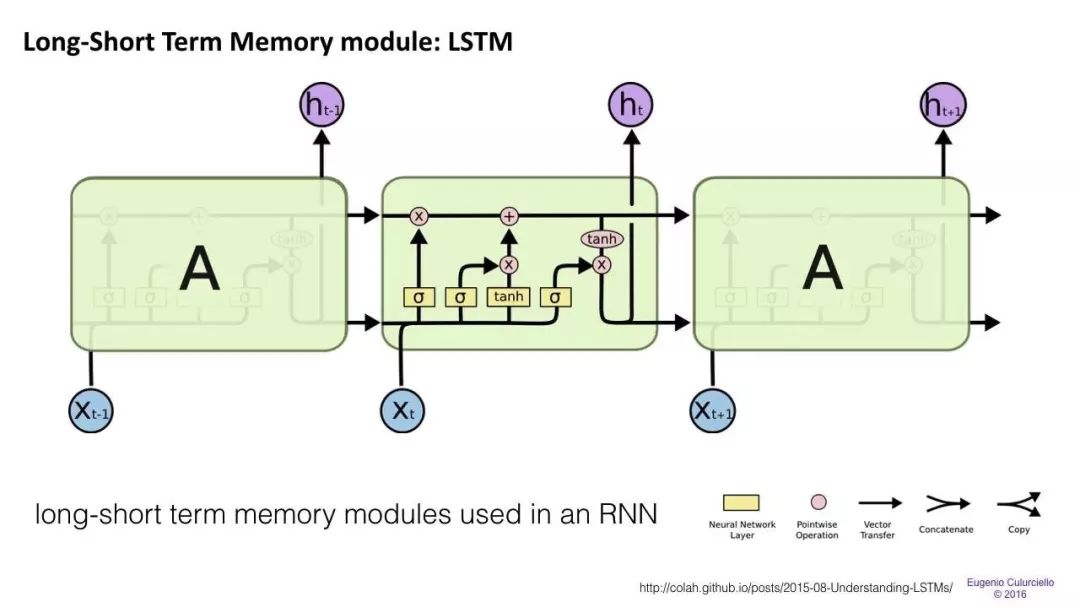
長(zhǎng)/短期記憶(LSTM)網(wǎng)絡(luò)試圖通過引入門(gate)和明確定義的記憶單元(memory cell)來(lái)解決梯度消失/爆炸問題。每個(gè)神經(jīng)元都有一個(gè)memory cell和三個(gè)gate:input,output和forget。這些門的功能是通過停止或允許信息流來(lái)保護(hù)信息。
input gate確定來(lái)自前一層的信息有多少存儲(chǔ)在單元中。
輸出層接受另一端的任務(wù),并確定下一層有多少人知道這個(gè)單元的狀態(tài)。
forget gate的作用起初看起來(lái)有點(diǎn)奇怪,但有時(shí)最好還是忘掉:如果是學(xué)習(xí)一本書,翻開新的一章,那么網(wǎng)絡(luò)可能有必要忘掉前一章中的一些人物。
LSTMs已經(jīng)被證明能夠?qū)W習(xí)復(fù)雜的序列,比如像莎士比亞一樣進(jìn)行寫作或創(chuàng)作原始的音樂。請(qǐng)注意,這些門中的每一個(gè)都對(duì)前一個(gè)神經(jīng)元中的一個(gè)單元具有權(quán)重,因此它們通常需要更多資源才能運(yùn)行。LSTM目前非常流行,并且在機(jī)器翻譯中被廣泛使用。除此之外,它是大多數(shù)序列標(biāo)簽任務(wù)的默認(rèn)模型,其中有大量的數(shù)據(jù)。
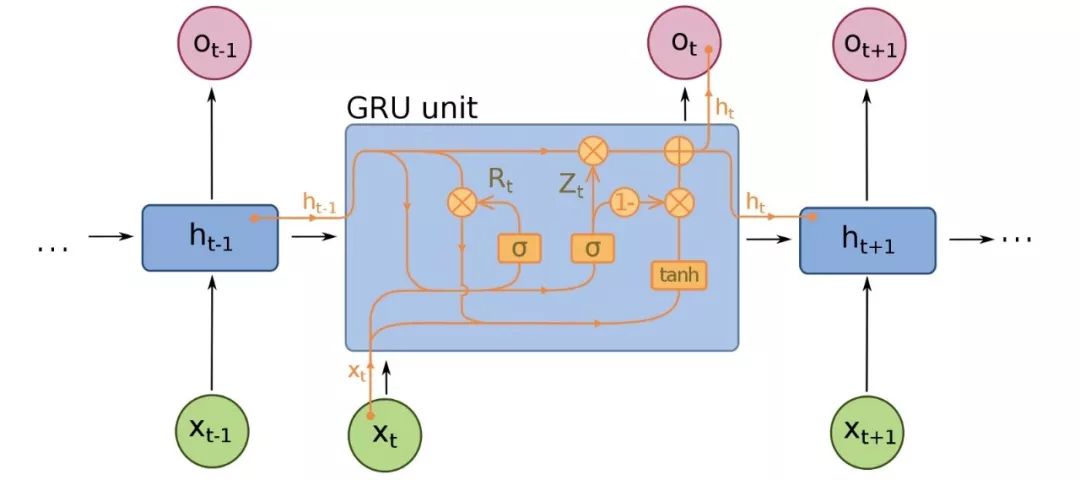
Gated recurrent units(GRU)是LSTMs的一個(gè)微小變型,也是神經(jīng)機(jī)器翻譯的擴(kuò)展。它們少了一個(gè)gate,連線方式略有不同:它們沒有一個(gè)input、output和一個(gè)forget gate,而是一個(gè)update gate。這個(gè)update gate決定從上一個(gè)狀態(tài)保存多少信息,以及從上一個(gè)層輸入多少信息。
reset gate的功能與LSTM的forget gate非常相似,但位置稍有不同。它們總是發(fā)送它們的全部狀態(tài)——它們沒有輸出門。在大多數(shù)情況下,它們的功能與LSTMs非常相似,最大的區(qū)別是GRUs稍微快一些,更容易運(yùn)行(但也更不容易表達(dá))。在實(shí)踐中,這些往往會(huì)互相抵消,因?yàn)槟阈枰粋€(gè)更大的網(wǎng)絡(luò)來(lái)重新獲得一些表示能力,這反過來(lái)又抵消了性能優(yōu)勢(shì)。在一些不需要額外表示的情況下,GRU可以勝過LSTM。
除了這三種主要體系結(jié)構(gòu)之外,近年來(lái)神經(jīng)機(jī)器翻譯系統(tǒng)也有了進(jìn)一步的改進(jìn)。以下是最顯著的發(fā)展:
Sequence to Sequence Learning with Neural Networks【1】證明了LSTM在神經(jīng)機(jī)器翻譯中的有效性。它提出了序列學(xué)習(xí)的一種通用的端到端方法,對(duì)序列結(jié)構(gòu)進(jìn)行了最少的假設(shè)。該方法使用多層Long Short Term Memory(LSTM)將輸入序列映射為固定維度的向量,然后再通過另一個(gè)深度LSTM對(duì)目標(biāo)序列進(jìn)行解碼。
Neural Machine Translation by Jointly Learning to Align and Translate【2】引入了NLP中的注意力機(jī)制(將在下一篇文章中介紹)。認(rèn)識(shí)到使用固定長(zhǎng)度的向量是提高NMT性能的瓶頸,作者建議通過允許模型自動(dòng)(軟)搜索與預(yù)測(cè)目標(biāo)相關(guān)的源句子來(lái)進(jìn)行擴(kuò)展,而不必將這些部分明確地形成為一個(gè)固定的長(zhǎng)度。
Convolutional over Recurrent Encoder for Neural Machine Translation【3】在NMT標(biāo)準(zhǔn)RNN編碼器中增加了卷積層,以便在編碼器輸出中捕獲更廣泛的上下文。
谷歌建立了自己的NMT系統(tǒng),稱為Google’s Neural Machine Translation【4】,它解決了準(zhǔn)確性和部署方便性方面的許多問題。該模型由一個(gè)深度LSTM網(wǎng)絡(luò)組成,該網(wǎng)絡(luò)包含8個(gè)編碼器和8個(gè)解碼器層,使用殘差連接以及從解碼器網(wǎng)絡(luò)到編碼器的注意力連接。
Facebook AI研究人員不使用遞歸神經(jīng)網(wǎng)絡(luò),而是使用卷積神經(jīng)網(wǎng)絡(luò)【5】序列對(duì)NMT中的學(xué)習(xí)任務(wù)進(jìn)行排序。
▌技術(shù)3:Dialogue 和 Conversations
關(guān)于會(huì)話AI的文章很多,其中大部分集中在垂直聊天機(jī)器人、messenger平臺(tái)、商業(yè)趨勢(shì)和創(chuàng)業(yè)機(jī)會(huì)(比如亞馬遜Alexa、蘋果Siri、Facebook M、谷歌助理、微軟Cortana)。人工智能理解自然語(yǔ)言的能力仍然有限。因此,創(chuàng)建完全自動(dòng)化的開放域會(huì)話助理仍然是一個(gè)開放的挑戰(zhàn)。盡管如此,以下所示的工作對(duì)于那些想要尋求對(duì)話人工智能下一個(gè)突破的人來(lái)說(shuō)是一個(gè)很好的起點(diǎn)。

來(lái)自蒙特利爾、佐治亞理工學(xué)院、微軟和Facebook的研究人員建立了一個(gè)神經(jīng)網(wǎng)絡(luò),能夠產(chǎn)生上下文敏感的對(duì)話反應(yīng)。這種新型的響應(yīng)生成系統(tǒng)可以在大量非結(jié)構(gòu)化的Twitter對(duì)話中進(jìn)行端到端訓(xùn)練。當(dāng)將上下文信息集成到經(jīng)典的統(tǒng)計(jì)模型中時(shí),使用一個(gè)遞歸的神經(jīng)網(wǎng)絡(luò)架構(gòu)來(lái)解決稀疏性問題,使系統(tǒng)能夠考慮到以前的對(duì)話。該模型顯示了對(duì)上下文敏感和非上下文敏感的機(jī)器翻譯和信息檢索baseline的一致好處。
神經(jīng)應(yīng)答機(jī)(NRM)是在香港開發(fā)的一種基于神經(jīng)網(wǎng)絡(luò)的短文本對(duì)話響應(yīng)發(fā)生器。它采用通用的編碼-解碼框架。首先,它將響應(yīng)的生成形式化為基于輸入文本潛在表示的解碼過程,而編碼和解碼都是通過遞歸神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)的。NRM通過從微博服務(wù)收集的大量一輪談話數(shù)據(jù)進(jìn)行訓(xùn)練。實(shí)證研究表明,NRM能夠?qū)Τ^75%的輸入文本產(chǎn)生語(yǔ)法正確和內(nèi)容恰當(dāng)?shù)捻憫?yīng),在相同的環(huán)境下表現(xiàn)優(yōu)于現(xiàn)有技術(shù)。
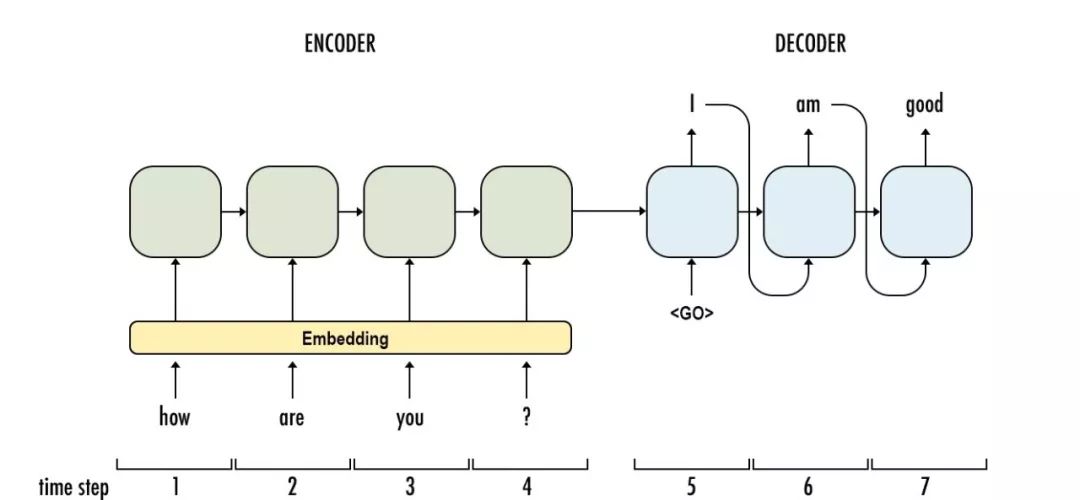
最后,谷歌的神經(jīng)會(huì)話模型(Neural Conversational Model)是會(huì)話建模的一種簡(jiǎn)單方法。它使用序列到序列(sequence-to-sequence)的框架。該模型通過預(yù)測(cè)會(huì)話中給定前一句的下一句進(jìn)行對(duì)話。該模型的優(yōu)點(diǎn)在于可以進(jìn)行端到端的訓(xùn)練,因此需要更少的手工規(guī)則。
給出一個(gè)大型的會(huì)話訓(xùn)練數(shù)據(jù)集,該模型可以生成簡(jiǎn)單的會(huì)話。它可以從特定領(lǐng)域的數(shù)據(jù)集以及電影字幕的大的、有噪聲的、通用的領(lǐng)域數(shù)據(jù)集中提取知識(shí)。在特定于域的IT help-desk數(shù)據(jù)集上,該模型可以通過對(duì)話找到技術(shù)問題的解決方案。在嘈雜的開放域電影副本數(shù)據(jù)集上,該模型可以執(zhí)行簡(jiǎn)單形式的常識(shí)推理。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8438瀏覽量
133080 -
機(jī)器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14945 -
nlp
+關(guān)注
關(guān)注
1文章
489瀏覽量
22107
原文標(biāo)題:這7種NLP黑科技讓你更好交流!來(lái)看一看是什么(Part1)
文章出處:【微信號(hào):AI_Thinker,微信公眾號(hào):人工智能頭條】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
ChatGPT爆火背后,NLP呈爆發(fā)式增長(zhǎng)!
拿高薪必備的深度學(xué)習(xí)nlp技術(shù),這篇文章講得很透徹
全面擁抱Transformer:NLP三大特征抽取器(CNNRNNTF)比較
對(duì)2017年NLP領(lǐng)域中深度學(xué)習(xí)技術(shù)應(yīng)用的總結(jié)
NLP中的深度學(xué)習(xí)技術(shù)概述

如何學(xué)習(xí)自然語(yǔ)言處理NLP詳細(xì)學(xué)習(xí)方法說(shuō)明
8個(gè)免費(fèi)學(xué)習(xí)NLP的在線資源
AI 深度學(xué)習(xí) 機(jī)器學(xué)習(xí)和NLP四種先進(jìn)技術(shù)的不同
4種常見的NLP實(shí)踐思路分析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論