") 兩篇關(guān)于Google語(yǔ)義表示相關(guān)研究最新進(jìn)展的論文
兩篇關(guān)于Google語(yǔ)義表示相關(guān)研究最新進(jìn)展的論文
近年來(lái),“基于神經(jīng)網(wǎng)絡(luò)的自然語(yǔ)言識(shí)別”相關(guān)的研究取得了飛速進(jìn)展,特別是在學(xué)習(xí)語(yǔ)義的文本表示方面,這些進(jìn)展有助于催生一系列真正新奇的產(chǎn)品,例如智能撰寫(Gmail 的輔助郵件創(chuàng)作)和Talk to Books(訪問(wèn)文末的鏈接,試著與書(shū)籍對(duì)話)。還有助于提高訓(xùn)練數(shù)據(jù)量有限的各種自然語(yǔ)言任務(wù)的性能,例如,通過(guò)僅僅 100 個(gè)標(biāo)記示例構(gòu)建強(qiáng)大的文本分類器。
下面我們將討論兩篇關(guān)于 Google 語(yǔ)義表示相關(guān)研究最新進(jìn)展的論文,以及可在 TensorFlow Hub 上下載的兩個(gè)新模型,我們希望開(kāi)發(fā)者使用這些模型來(lái)構(gòu)建令人興奮的新應(yīng)用。
TensorFlow Hub是一個(gè)管理、分發(fā)和檢索用于 TensorFlow 的可重用代碼(模型)的管理工具。
語(yǔ)義文本相似度
在“Learning Semantic Textual Similarity from Conversations”中,我們引入了一種新的方法來(lái)學(xué)習(xí)語(yǔ)義文本相似度的語(yǔ)句形式。可以直觀理解為,如果句子的答復(fù)具有相似的分布,那么它們?cè)谡Z(yǔ)義上是相似的。例如,“你多大了?” (How old are you?) 和“你幾歲了?” (What is your age?) 都是關(guān)于年齡的問(wèn)題,可以通過(guò)類似的答復(fù)來(lái)回答,例如“我 20 歲” (I am 20 years old)。相比之下,雖然“你好嗎?” (How are you?) 和“你多大?” (How old are you?) 包含的英文單詞幾乎相同,但它們的含義卻大相徑庭,因而答復(fù)也不同。
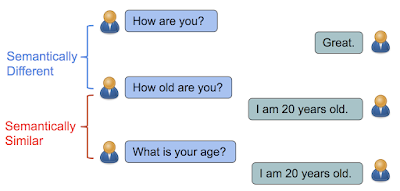
如果句子可以通過(guò)相同的答復(fù)來(lái)回答,那么它們?cè)谡Z(yǔ)義上是相似的。否則,它們?cè)谡Z(yǔ)義上是不同的。
在這項(xiàng)研究中,我們的目標(biāo)是通過(guò)答復(fù)分類任務(wù)學(xué)習(xí)語(yǔ)義相似度:給定一個(gè)對(duì)話輸入,我們希望從一批隨機(jī)選擇的答復(fù)中選出正確的答復(fù)。但是,最終目標(biāo)是學(xué)習(xí)一個(gè)可以返回表示各種自然語(yǔ)言關(guān)系(包括相似度和相關(guān)性)編碼的模型。通過(guò)添加另一個(gè)預(yù)測(cè)任務(wù)(在本例中為SNLI 蘊(yùn)含數(shù)據(jù)集),并通過(guò)共享編碼層強(qiáng)制執(zhí)行,我們?cè)谙嗨贫榷攘糠矫娅@得了更好的性能,例如STSBenchmark(句子相似度基準(zhǔn))和CQA 任務(wù) B(問(wèn)題/問(wèn)題相似度任務(wù))。這是因?yàn)檫壿嬏N(yùn)含與簡(jiǎn)單的等價(jià)有很大不同,并且更有助于學(xué)習(xí)復(fù)雜的語(yǔ)義表示。

對(duì)于給定的輸入,可將分類視為潛在候選項(xiàng)排名問(wèn)題。
Universal Sentence Encoder
“Universal Sentence Encoder”一文中引入了一個(gè)模型,此模型通過(guò)增加更多的任務(wù)對(duì)上述多任務(wù)訓(xùn)練進(jìn)行了擴(kuò)展,我們使用類似于skip-thought的模型 (論文鏈接在文末)(可以在給定的文本范圍內(nèi)預(yù)測(cè)句子)來(lái)訓(xùn)練它們。但是,盡管原始 skip-thought 模型中采用的是編碼器-解碼器架構(gòu),我們并未照搬使用,而是通過(guò)共享編碼器的方式使用了只有編碼器的架構(gòu)來(lái)驅(qū)動(dòng)預(yù)測(cè)任務(wù)。通過(guò)這種方式可以大大縮短訓(xùn)練時(shí)間,同時(shí)保持各種傳輸任務(wù)的性能,包括情感和語(yǔ)義相似度分類。目的是提供一種單一編碼器來(lái)支持盡可能廣泛的應(yīng)用,包括釋義檢測(cè)、相關(guān)性、聚類和自定義文本分類。
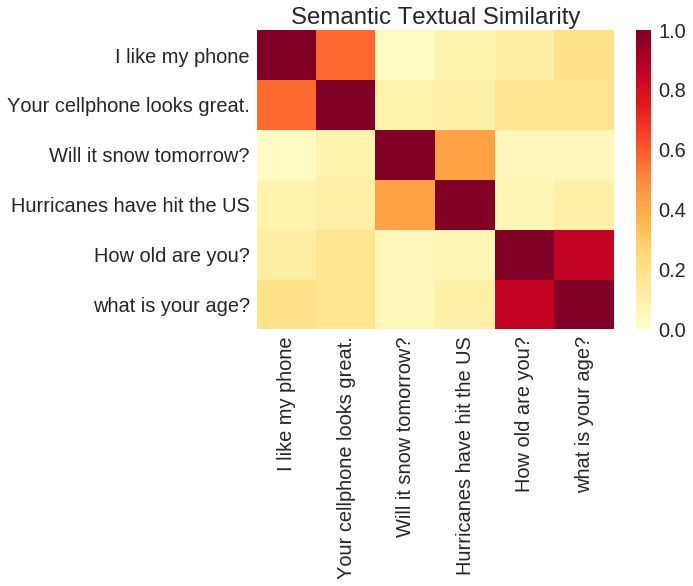
基于 TensorFlow Hub Universal Sentence Encoder 的輸出進(jìn)行的語(yǔ)義相似度成對(duì)比較。
正如我們的論文所述,Universal Sentence Encoder 模型的一個(gè)版本使用了深度平均網(wǎng)絡(luò)(DAN) 編碼器,而另一個(gè)版本則使用了更復(fù)雜的自助網(wǎng)絡(luò)架構(gòu)- Transformer。
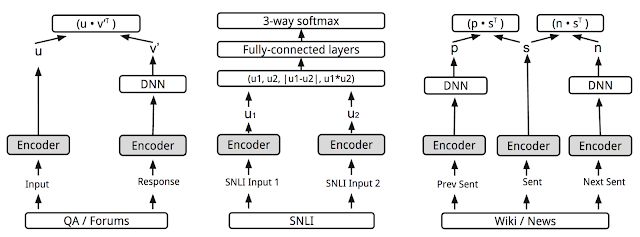
"Universal Sentence Encoder"中所述的多任務(wù)訓(xùn)練。各種任務(wù)和任務(wù)結(jié)構(gòu)通過(guò)共享編碼器層/參數(shù)(灰色框)連接。
對(duì)于更復(fù)雜的架構(gòu)而言,與相對(duì)簡(jiǎn)單的 DAN 模型相比,此模型在各種情感和相似度分類任務(wù)上的表現(xiàn)更加出色,而短句子方面的速度只是稍微慢一些。然而,隨著句子長(zhǎng)度的增加,使用 Transformer 的模型的計(jì)算時(shí)間顯著增加,而同等條件下,DAN 模型的計(jì)算時(shí)間幾乎保持不變。
新模型
除了上述 Universal Sentence Encoder 模型外,我們還將在 TensorFlow Hub 上分享兩個(gè)新模型:Universal Sentence Encoder - Large和Universal Sentence Encoder - Lite。這些都是預(yù)訓(xùn)練的 Tensorflow 模型,可返回可變長(zhǎng)度文本輸入的語(yǔ)義編碼。這些編碼可用于語(yǔ)義相似度度量、相關(guān)性、分類或自然語(yǔ)言文本的聚類。
Large 模型使用 Transformer 編碼器進(jìn)行訓(xùn)練,我們的第二篇論文進(jìn)行了介紹。此模型適用于需要高精度語(yǔ)義表示以及要求以速度和大小為代價(jià)獲得最佳模型性能的場(chǎng)景。
Lite 模型基于 Sentence Piece 詞匯而非單詞進(jìn)行訓(xùn)練,以顯著減少詞匯量,而詞匯量則顯著影響模型大小。此模型適用于內(nèi)存和 CPU 等資源有限的場(chǎng)景,例如基于設(shè)備端或基于瀏覽器的實(shí)現(xiàn)。
我們很高興與社區(qū)分享本研究成果和這些模型。我們相信這里所展示的成果只是一個(gè)開(kāi)始,并且還有許多重要的研究問(wèn)題亟待解決。例如,將技術(shù)擴(kuò)展到更多語(yǔ)言(上述模型目前僅支持英語(yǔ))。我們也希望進(jìn)一步開(kāi)發(fā)這項(xiàng)技術(shù),以便能夠理解段落甚至文檔級(jí)別的文本。如果能夠完成這些任務(wù),或許我們能制作出一款真正意義上的“通用”編碼器。
-
編碼器
+關(guān)注
關(guān)注
45文章
3667瀏覽量
135243 -
Google
+關(guān)注
關(guān)注
5文章
1772瀏覽量
57801 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101169
原文標(biāo)題:語(yǔ)義文本相似度研究進(jìn)展
文章出處:【微信號(hào):tensorflowers,微信公眾號(hào):Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論