 一種基于MapReduce模型的并行化k-medoids聚類算法
一種基于MapReduce模型的并行化k-medoids聚類算法
摘要:
隨著電力通信技術的發展,產生了大量分布式電力通信子系統以及海量電力通信數據,在海量數據中挖掘重要信息變得十分重要。聚類分析作為數據并行化處理和信息挖掘的一個有效手段,在電力通信中得到了廣泛的應用。然而,傳統聚類算法在處理海量電力數據時已不能滿足時間性能的要求。針對這一問題,提出了一種基于MapReduce模型的并行化k-medoids聚類算法,首先采用基于密度的聚類思想對k-medoids算法初始點的選取策略進行優化,并利用Hadoop平臺下的MapReduce編程框架實現了算法的并行化處理。實驗結果表明,改進的并行化聚類算法與其他算法相比,減少了聚類時間,提高了聚類精度,有利于對電力數據的有效分析和利用
0 引言
隨著電力通信網絡以功能為中心持續性發展,產生了大量分專業、分功能和分管理域的運維管理系統,進而導致大量電力數據孤島的產生。如何利用分布式系統更好地處理這些數據量巨大且類型復雜的電力通信運維數據已成為研究的熱點問題。聚類分析作為數據處理的一個有效手段,支持對大量無序分散數據進行整合分類從而進行更深層次的關聯性分析或者數據挖掘,在電力通信網絡中得到越來越廣泛的應用。同時,分布式系統中并行化處理機制因其優秀的靈活性和高效性逐漸成為數據挖掘的一個重要研究方向。
國內外學者也越來越對這方面加大關注,文獻[1]提出了一種基于DBSACN算法的并行優化的聚類算法。文獻[2]中通過計算距離選擇最中心的k個數據點作為初始聚類中心,然后用k-medoids算法進行迭代聚類,提高了聚類效果,但不適合處理大規模數據;文獻[3]提出了一種蟻群 k-medoids 融合聚類算法,該算法不需要人為確定類簇數目和初始聚類中心,提高了聚類效果,但也僅只適用于小型數據集;文獻[4]采用基于粒計算的聚類算法,該算法在初始聚類中心的選取過程中的計算量較大,且在處理大規模數據時存在時延問題;文獻[5]提出了將局部搜索過程嵌入到迭代局部搜索過程中的方法,顯著減少了計算時間。文獻[6]在Hadoop平臺上實現了傳統k-medoids聚類算法的并行化處理,減少了聚類時間,但在初始聚類中心的選取機制上沒有進行改進,沒有提高聚類效果;文獻[7]采用基于核的自適應聚類算法,克服了k-medoids 的初值敏感問題,但是沒有降低算法的時間復雜度。
綜上所述,k-medoids聚類算法存在初始值敏感、運行速度慢、時間復雜度較高等問題,需要對k-medoids算法中初始點選取以及并行化方式進行算法優化設計。
1 k-medoids聚類初始點選取改進機制
k-medoids算法是一種基于劃分的聚類算法,具有簡單、收斂速度快以及對噪聲點不敏感等優點,因此在模式識別、數據挖掘等領域都得到了廣泛的應用。k-medoids算法初始中心點的選取十分重要,如果初始中心點選擇的是離群點時,就會導致由離群點算出的質心會偏離整個簇,造成數據分析不正確;如果選擇的初始中心點離得太近,就會顯著增加計算的時間消耗。因此本文算法首先對初始中心點的選取進行優化。基于密度的聚類可以很好地分離簇和環境噪聲,所以本文采用基于密度的聚類思想,盡量減少噪聲數據對選取初始點的影響。
定義1:點密度是對于數據集U中的數據集的樣本點x,以x為球心,某一正數r為半徑的球形域中所包含樣本點的個數,記作Dens(x)。其中:

本文算法中,首先對每個數據點并行計算點密度,并將點密度作為該數據點的一個屬性。選取初始聚類中心的具體步驟如下:
(1)計算數據集中m個數據點之間的距離。
(2)計算每個樣本點的點密度Dens(xi)以及均值點密度AvgDens,將點密度大于AvgDens的點即核心點存入集合T中,并記錄其簇中所包含的數據點。
(3)合并所有具有公共核心點的簇。
(4)計算各個簇的類簇密度CDens(ci),選擇其中k個較大密度的簇,計算其中心點,即為初始聚類中心。
類簇中心點的計算方法如下:假設有一個類簇ci包含m個數據點{x1,x2,…,xm},則其中心點ni按如式(5)計算:

經過上述步驟,可以優化初始聚類中心點的選取,使之后的聚類迭代運算更加有效,降低搜索范圍,大大減少搜索指派的時間。
2 k-medoids聚類算法并行化設計策略
本文針對k-medoids算法具有初始點選取復雜、聚類迭代時間久、中心點選取消耗資源過多等缺點,使用Hadoop平臺下的MapReduce編程框架對算法進行初始點的點密度計算選取并行化、非中心點分配并行化和中心點更新并行化等方面的改進。MapReduce分為Map(映射)和Reduce(化簡)兩部分操作,使用MapReduce實現算法并行化關鍵在于Map函數和Reduce函數的設計。其中Map函數將可并行執行的多個任務映射到多個計算節點,多個計算節點對各自被分派的任務并行進行處理,Reduce函數則是在各計算節點處理結束后,將計算結果返回給主進程進行匯總。
2.1 點密度計算并行化策略
在點密度的計算中,由于一個數據點的點密度對其他數據點的點密度沒有影響,所以該計算過程是可以并行化的。使用MultithreadedMapper在一個JVM進程里以多線程的方式同時運行多個Mapper,每個線程實例化一個Mapper對象,各個線程并發執行。主進程把數據點分派給若干個不同的計算節點進行處理,計算節點將數據平均分成k份,且有k個線程,每個線程中的數據點都與數據集中所有點進行距離計算,進而計算出點密度,最后通過Reduce函數將計算結果匯總并輸出。并行處理使得點密度計算所用時間大大減少,提高了算法的執行效率。
2.2 非中心點分配及中心點更新并行化策略
非中心點分配階段的主要工作是計算各數據點到每個中心點的距離,由于每個數據點跟各個中心點距離的計算互不影響,所以該計算過程也是可并行化的。此階段的MapReduce化過程中,Map函數主要負責將數據集里除中心點外的每一個樣本點分配給與其距離最近的聚類中心,Reduce函數則負責通過計算更新每一個簇的中心點,按照這個原則迭代下去一直到達到設定閾值。主進程利用Map函數把非中心點分配的任務分派給若干個計算節點,每個計算節點采用基于Round-Robin的并行化分配策略。首先把每一個數據點看作一個請求,輪詢地分配給不同的線程,對非中心點和每一個中心點的距離進行計算,找出最小的距離,然后把該非中心點指派給最小距離所對應的中心點。
因為輪詢調度算法是假設所有服務器中的處理性能都是相同,并不關心每臺服務器當前的計算速度和響應速度。因此當用戶發出請求時,如果服務間隔的時間變化較大的時候,那么Round-Robin調度算法是非常容易導致服務器之間的負載發生不平衡表現。而本文中所運用的每個數據點都是平等的,所以不會造成服務器分配任務不均的問題。因此基于Round-Robin的策略是可行的。
本文算法在實現聚類的過程中經歷了兩次并行化劃分,分別是非中心點分配和中心點更新過程。這兩次并行化過程是周而復始的,直到滿足程序退出的條件才會終止循環。
3 仿真實驗與結果分析
仿真實驗分別使用本文算法、DBSCAN并行化算法[1]和k-medoids并行化算法[8]進行對比試驗,證明各個算法的優劣性。為了證明本文算法的有效性,實驗將分析不同算法的聚類時間、聚類準確度以及增加線程數之后的時間消耗。實驗將在兩種類型的數據集上進行測試:
(1)電力數據集。電力通信數據的屬性有設備狀態、設備資產、網絡拓撲等,其數據量約為1 GB。
(2)公有數據集。分別為200數量級的Northix、1 000數量級的DSA、5 000數量級的SSC和10 000數量級的GPSS。
3.1 電力數據集實驗結果分析
實驗首先設置6個線程對數據集進行處理,三種算法對電力數據進行聚類的結果見表1。其中k-medoids并行化算法[8]采用標簽共現原則對初始點選取進行改進,但沒有考慮線程的分配方式,因此其執行效率最差;DBSCAN算法考慮到了初始點的選取,并采用動態分配策略實現并行化,但在計算動態分配過程中增加了一定消耗,因此聚類準確度和執行效率都略有提升;本文所提出的算法,既考慮了初始點的合理選取,同時采用簡單有效的并行化分配策略,以減少計算和過多資源占用,因此相對于k-medoids并行化算法和DBSCAN并行化算法執行效率大幅提升,準確度也有所提高。
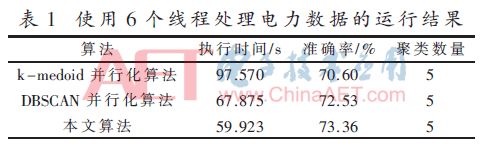
然后增加線程處理器的數量至8個,得到下表的聚類結果,見表2。
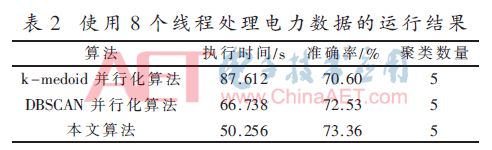
由表2可得,使用8個線程時,本文算法比k-medoids并行化算法執行時間快了42.64%,比DBSCAN并行化算法快了24.70%。
各類算法增加線程后所用時間相比原算法減少的百分比如圖1。
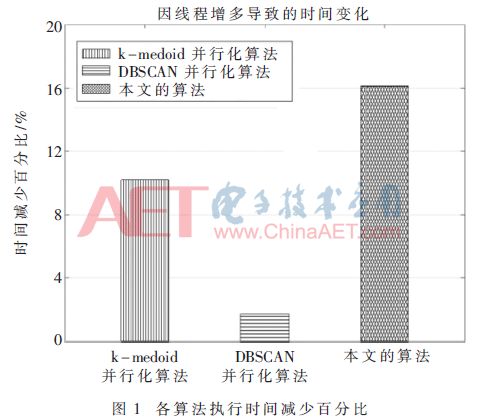
由圖1可知,k-medoids并行化算法減少了10.20%,DBSCAN并行化算法減少了1.68%,本文算法減少了16.13%,說明本文算法在線程數增加時,可以更有效地減少運算時間,提高執行效率。
3.2 公有數據集實驗結果分析
基于Northix、DSA、SSC和GPSS數據集使用5個線程實現算法的聚類準確度比較見表3。
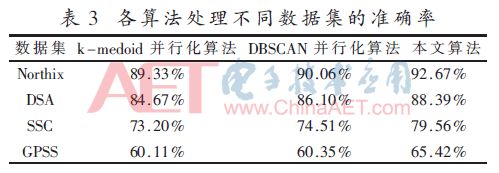
本文算法的聚類準確度均高于k-medoids并行化算法和DBSCAN并行化算法,并且在處理較大數量級的數據集時,本文算法準確度更占優勢。不同數據集上各算法的執行時間如圖2。
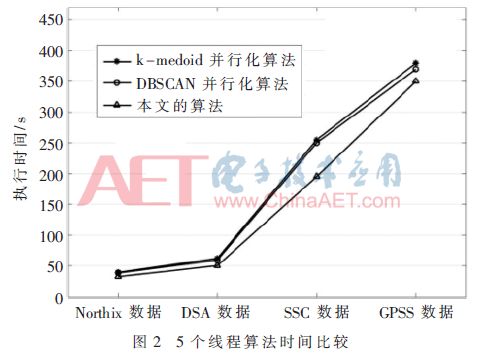
根據圖2,隨著數據量的增大,三種算法執行效率差異逐漸增大,本文算法性能明顯優于k-medoids并行性算法和DBSCAN并行算法。接著對三個算法使用7個線程時的執行時間進行比較,如圖3所示。
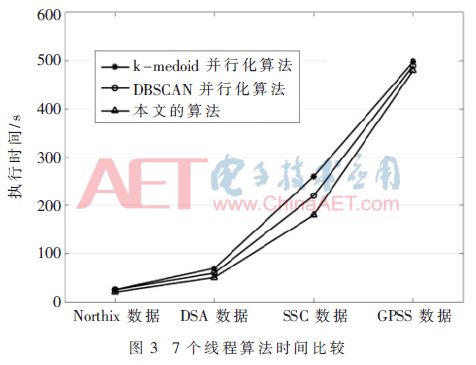
從圖3中可以看出,使用7個線程在1 000、5 000、10 000數據級時,本文算法執行時間明顯優于其他兩個算法。
3.3 實驗小結
仿真實驗可知,在同一線程數時,本文算法比對比算法聚類準確率高,執行時間短;在線程數增加時,本文算法執行時間顯著降低;隨著數據量的增長,本文算法在保證更高準確度的基礎上,執行時間優勢逐漸凸顯。
4 結論
本文針對電力通信數據的聚類處理問題,提出基于密度的聚類思想對k-medoids算法初始點的選取策略進行優化,并利用MapReduce編程框架實現了算法的并行化處理。通過仿真實驗表明本文提出的優化算法可行有效,并具有較好的執行效率。在接下來的研究中可以考慮線程數小于聚類數時的優化分配策略,進一步提高算法性能。
-
聚類算法
+關注
關注
2文章
118瀏覽量
12158 -
MapReduce
+關注
關注
0文章
45瀏覽量
6312
原文標題:【學術論文】電力通信大數據并行化聚類算法研究
文章出處:【微信號:ChinaAET,微信公眾號:電子技術應用ChinaAET】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種新的人工魚群混合聚類算法

一種基于MapReduce的圖結構聚類算法






 工商網監
工商網監
評論