 解析車牌識別技術,融合多種算法的原理和過程
解析車牌識別技術,融合多種算法的原理和過程
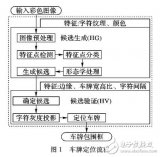
1.車牌預處理
車牌預處理過程的好壞直接影響到車牌圖像進行后期處理過程,比如車牌字符分割等。車牌預處理也是盡可能的消除噪聲,減少后期處理帶來的不必要的麻煩。
輸入的車牌是24Bit的BMP真彩色圖像,車牌照有黃底黑字,藍底白字等顏色,為了將這些車牌圖像一并處理,就要先將車牌進行灰度化處理,然后進行二值化(黑白)處理。
4-1 原始圖像
將采集的車牌圖像進行預處理,為了方便起見,這里采用的是BMP格式的圖片,我將采集的車牌圖像進行了裁剪處理,裁剪后的圖片如下:
由于中國大部分的車牌是第一個是漢字,第二個到第七個是字母或數字,這就可以將車牌圖像識別過程分成兩部分處理,第一部分是識別漢字的過程,第二部分是識別字母和數字的過程,由于漢字筆畫較多,同字母或數字的處理過程有所不同。所以我這里就先處理字母或數字的過程。
除漢字外,在第一個字母和第二個數字的中間有個一點,所以在字符分割的時候要考慮去掉中間的點。車牌圖像總體來說比較清晰,大型民用車,牌照為黃底黑字,小型民用車,牌照為藍底白字,由于字符與背景顏色對比比較明顯,所以將車牌分割開來比較容易。由于有些車牌的上面和下面也有螺絲之類的東西將車牌固定,所以在將車牌分割的時候,通過水平掃描跳躍點的方法,可以去除掉,以便最后將車牌進行分割,去除這些干擾。
在RGB模型中,如果R=G=B時,則彩色表示一種灰度顏色,其中R=G=B的值叫灰度值,因此,灰度圖像每個像素只需一個字節存放灰度值(又稱強度值、亮度值),灰度范圍為0-255。一般有四種方法對彩色圖像進行灰度化。
1. 分量法。就是將每個分量上的顏色值即RGB3種顏色提取出來。即:將彩色圖像中的三分量的亮度作為三個灰度圖像的灰度值,可根據應用需要選取一種灰度圖像。f1(i,j)=R(i,j) f2(i,j)=G(i,j) f3(i,j)=B(i,j)其中fk(i,j)(k=1,2,3)為轉換后的灰度圖像在(i,j)處的灰度值。
2.最大值法。選取彩色圖像中的三分量中(RGB)的顏色的最大值作為灰度圖的灰度值。即:f(i,j)=max(R(i,j),G(i,j),B(i,j))。
3.平均值法。 將彩色圖像中的三分量亮度求平均得到一個灰度圖f(i,j)=(R(i,j)+G(i,j)+B(i,j))/3。
4.加權平均法。根據重要性及其它指標,將三個分量以不同的權值進行加權平均。由于人眼對綠色的敏感最高,對藍色敏感最低,因此,按下式對RGB三分量進行加權平均能得到較合理的灰度圖像。f(i,j)=0.30R(i,j)+0.59G(i,j)+0.11B(i,j))。
以上四種處理過程,在車牌預處理的過程中,我選擇加權平均值法。效果如下:
圖4-2 原始圖像
圖4-3灰度圖像
如上圖,是將圖中的原始圖像進行加權平均值處理后的灰度圖像。
關鍵代碼如下:
for(i = 0;i < Height; i++)
{
for(j= 0;j < Width*3; j+=3)
{
ired =(unsigned char*)lpDibBits + LineBytes* i + j + 2;
igreen= (unsigned char*)lpDibBits + LineBytes * i + j + 1;
iblue =(unsigned char*)lpDibBits + LineBytes* i + j ;
lpdest[i*Width+ j/3]= (unsigned char)((*ired)*0.299 + (*igreen)*0.588 + (*iblue)*0.114);//加權平均值計算處理
}
}
二值化處理。二值化處理即將BMP圖像進行黑白處理,使背景與字符區分開。由于灰度化后的圖像是0-255之間的顏色值。而進行二值化處理的過程就是將此圖像的顏色分成黑色值0和白色值255兩種顏色。為了將背景與車牌字符分開,要設定一個閾值。設定閾值是關鍵。如果選取的二值化的閾值不當則就有可能不能將車牌圖像中的背景與文字進行明顯分開,所以這時二值化的閾值選取就顯得非常重要。根據試驗,我設定的閾值為125。二值化后的效果如下:
4-7 二值化后圖像
如上圖是測試藍底白字和黃底黑字的車牌圖像的二值化后的效果。通過將圖像進行二值化后,可以明顯將背景與車牌字符進行分開。
二值化處理的關鍵代碼如下:
for(i = 0; i < Height; i++)// 每行
{
for(j = 0; j < Width; j++)// 每列
{
// 指向DIB第i行,第j個象素的指針
lpSrc = (unsigned char*)lpDibBits+LineBytes *(lHeight - 1 - i) + j;
// 判斷是否小于閾值
if ((*lpSrc) < bThre)
{
*lpSrc = 0; // 直接賦值為0,即黑色
}
else
{
*lpSrc = 255; // 直接賦值為255,即白色
}
}
}
2.字符分割
由于車牌圖像做了細化處理后,可以進行水平掃描和垂直掃描將字符分開,水平掃描確定圖片的上下限,垂直掃描可以確定圖片中字符的左右坐標。根據車牌的特征,先將車牌圖像進行水平掃描跳躍點,即水平相鄰的兩個像素,如果不相同則認為有一個跳躍點,記錄次數加1,由于車牌上面有時候會有兩個白點,所以通過判斷跳躍點的個數,可以將上面的兩個白點去掉[9]。如圖,掃描處理的跳躍點統計如下:
圖4-10 原始圖像,上面有兩個白點
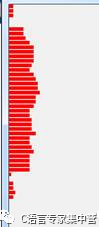
圖4-11水平掃描跳躍點的個數統計
統計結果:4 4 4 0 0 14 14 16 20 24 24 24 24 22 20 24 26 28 28 30 2626 24 20 20 22 22 22 26 20 20 22 24 20 20 20 20 2 0 4 4 6 4像素。掃描結果數量個數為的車牌高度的個數。
從上往下查找,根據實驗結果,設置當水平跳躍點超過10個的時候,作為車牌字符截取的上限。當從下往上查找,當跳躍點超過8個的時候可以作為車牌字符截取的下限。通過上面的過程,基本可以確定車牌的上部和下部。同樣,分割車牌字符左右邊界時,通過垂直掃描過程,由于數字和字母具有連通性,所以分割數字和字母比較容易。通過垂直掃描過程,統計黑色像素點的個數,由于兩個字符之間沒有黑像素,所以可以作為字符分割的界限。垂直掃描過程如下圖:

陜 A . 5 P 0 7 2
圖4-12 垂直掃描車牌字符黑像素個數統計
通過上面的統計可以很容易的把字符作用邊界進行分割開來。通過水平掃描跳躍點和垂直掃描像素點,可以分開字符。但是其中還有些問題。比如有些漢字不是聯通性,如“陜”字,左耳旁和右邊的“夾”字,有時候掃描的時候會有空隙,所以我這里在掃描第一個漢字的時候,要多加一些處理,當“陜”的左耳旁的寬度不為總寬度的1/12時候,我繼續向下掃描,直到找到為零的像素。還有就是A與5之間會有一個“.”號,這個可以通過掃描的寬度不為寬度的3/8時,我可以認為是中間的“.”號。所以通過以上的處理,基本能把大部分的車牌圖像字符進行分割。字符分割后的效果如下圖所示:
圖4-13字符分割圖像
字符分割關鍵代碼如下:
//如果距離少于寬度的1/12,則計為無效
intwid = lWidth/13;
intxx=0,pos=0;
intflag = 0;
intsuccess = 0;
for(i=0;i
{
while(VCount[i]==0)i++;
if((i-1)<0)
posi[k++]=i;
else
posi[k++]=i-1;
xx=0;
while(VCount[i]!=0&& i
if(flag==0)
{
pos= i;
while(VCount[i]==0){i++;xx++;}
if(xx < (wid/4))
{
str.Format("xx=%d wid/4=%d i=%dposi[k-1]=%d",xx,wid/4,i,posi[k-1]);
MessageBox("漢字有分割"+str);
xx=0;
while(VCount[i]!=0){i++;xx++;}
if(xx<=8)
{
xx= 0;
while(VCount[i]==0){i++;xx++;}
if(xx<(lWidth/16))
while(VCount[i]!=0 && i<(lWidth/8)) i++;
}
}
else
{
i= pos;
}
}
flag=1;
if(i>= lWidth)
{
posi[k++]=i-1;
}
else
{
posi[k++]=i+1;
}
//如果是字符第二個和第三個字符中間的點,去除。如果是1,寬度增加
if(posi[k-1]-posi[k-2]<=wid)
{
if(i<=(lWidth/8*3))
{
intx = posi[k-1]-posi[k-2]; k=k-2;
str.Format("%d%d %d %d",x,wid,i,BottomLine-TopLine);
}
else
{
posi[k-1]= posi[k-1]+wid/3;
posi[k-2]= posi[k-2]-wid/3;
}
}
if(k>=14)
{
success= 1;
break;
}
}
if(success== 0)
{
MessageBox("字符分隔出錯,程序結束識別過程!");
}
3.歸一化處理
字符分割的好壞關系到后面歸一化處理關鍵。如果字符分割不成立,歸一化處理過程也就不能成功。剛開始實驗的時候,我先進行的細化處理,然后再進行歸一化處理,但是歸一化處理后有,字符基本失去了原來的骨架結構,所以我這里先進行歸一化處理。
所謂歸一化處理,就是為了在分割字符時,字符大小不相同,所以要將字符歸一化為25×50像素大小的圖像。圖像x軸縮放比率為 ,y軸縮放比率為 ,原圖像寬度和高度為lWidth,lHeight[12]。縮放比率由公式:
在放大或縮小圖像過程中,產生的像素可能在原圖中不能找到相應的像素點。這樣就必須采用插值處理的方法。一般插值處理的方法有兩種,一種是直接賦值為與它最相鄰的像素值,另一種則通過插值算法來計算相應像素值。第一種方法計算過程較簡單效率高,但是效果不是很好,比如有時候會出現馬賽克現象;所以,這里采用第二種方法,雖然預算量有點復雜,但是最后歸一化后的字符不會失真。對后面做細化處理過程做好了鋪墊。通過實驗得出,采用雙線性插值法比最近鄰插值法效果好,所以本文中歸一化采用雙線性插值法。
圖4-14 上面為原圖像二值化后的結果,下面圖像為歸一化后的結果
歸一化關鍵代碼如下:
//針對圖像每行進行操作
for(i= 0; i < NewHeight; i++)
{
//針對圖像每列進行操作
for(j= 0; j < NewWidth; j++)
{
//指向新DIB第i行,第j個象素的指針
//注意此處寬度和高度是新DIB的寬度和高度
lpDst = (char*)lpNewDIBBits + NewLineBytes * (NewHeight - 1 - i) + j;
x= j / fXZoomRatio;
y= i / fYZoomRatio;
if(tag)
{ //tag=1,則執行以下的最近鄰插值代碼
i0= (LONG) (y + 0.5);
j0= (LONG) (x + 0.5);
//判斷是否在源圖范圍內
if((j0 >= 0) && (j0 < Width) && (i0 >= 0) && (i0< Height))
{
//指向源DIB第i0行,第j0個象素的指針
lpSrc = (char*)lpTempDIBBits + LineBytes * (Height - 1 - i0) + j0;
*lpDst= *lpSrc;
}
else
{
//對于源圖中沒有的象素,直接賦值為255
*((unsigned char*)lpDst) = 255;
}
}
else
{//否則,執行下面的雙線性插值代碼
doublem = x - LONG(x);//X方向的小數部分
doublen = y - LONG(y);//Y方向的小數部分
unsignedchar rd, ld, lu, ru;//r:右;l:左;d:下;u:上
unsignedchar pix;
ld= *((char *)lpTempDIBBits + LineBytes * (Height - 1 - LONG(y)) + LONG(x));//左下角點的像素值
rd= *((char *)lpTempDIBBits + LineBytes * (Height - 1 - LONG(y)) + LONG(x) +1);// 右下角點的像素值
lu= *((char *)lpTempDIBBits + LineBytes * (Height - 1 - LONG(y) - 1) +LONG(x));// 左上角點的像素值
ru= *((char *)lpTempDIBBits + LineBytes * (Height - 1 - LONG(y) - 1) + LONG(x) +1);// 右上角點的像素值
pix= (1 - m) * (1 - n) * ld + (1 - m) * n * lu + m * n * ru + m * (1 - n) * rd;//雙線性插值,得到變換后的像素
*((unsigned char*)lpDst) = pix;//將像素值賦給目的圖片
}
}
}
4.細化處理
對圖像的喜歡過程實際是求圖像骨架的過程。骨架是二維二值目標的重要描述,它指圖像中央的骨骼部分,是描述圖像幾何及拓撲性質的重要特征之一。細化算法有很多。按照迭代方法,分為兩類,一類是非迭代過程,一類是迭代過程。非迭代算法有基于距離變換的方法等。迭代方法是通過重復刪除像素邊緣,直到得到單獨像素寬度的圖像為止。現在用的比較多的細化算法有Hilditch、Pavlidis、Rosenfeld細化算法和索引表細化算法等[13]。下面主要介紹這四種算法。
Hilditch、Pavlidis、Rosenfeld細化算法:這類算法則是在程序中直接運算,根據運算結果來判定是否可以刪除點的算法,差別在于不同算法的判定條件不同。
其中Hilditch算法比較適用于二值圖像,是用的比較普遍的細化算法,在本文中我用了該算法后發現會有馬賽克效果,所以本文中沒有引用該算法; Pavlidis算法用位運算進行特定模式的匹配,所得的骨架是8連接的,使用于0-1二值圖像 ;Rosenfeld算法是一種并行細化方法,所得的骨架形態是8-連接的,使用于0-1二值圖像 。 后兩種算法的效果要更好一些,但是處理某些圖像時效果一般,第一種算法適用性強一些[13]。
索引表細化算法:經過預處理后得到待細化的圖像是0、1二值圖像。像素值為1的是需要細化的部分,像素值為0的是背景區域。基于索引表的算法就是依據一定的判斷依據,產生一個表,然后根據要細化的點的八個鄰域的情況進行匹配,若表中元素是1,若表中元素是1,則刪除該點(改為背景),若是0則保留。因為一個像素的8個鄰域共有256種可能情況,因此,索引表的大小一般為256種。
車牌圖像進行預處理后,細化處理是關系到后面能否正確提取字符特征值的關鍵,所以本文中在比較了幾種細化方法后,使用Rosenfeld骨架細化的方法,細化處理后可以得到圖像中字符的基本骨架,不會破壞原來的連通性。
Rosenfeld細化過程主要是保持原來圖像的連通性
通過歸一化 后,再將圖像進行細化,基本保存了字符特征的骨架特征。所以后面就是要進行的字符特征提取操作。Rosenfeld效果如下所示:
4-19大小歸一化后再細化的圖像
5.字符特征提取
字符特征提取的好壞,直接影響字符識別的結果。字符特征提取是一個字符識別過程必不可少的過程。目前,字符特征提取的方法很多,比如:基于網格像素統計方法[5],基于筆畫,輪廓,骨架特征等。我之前做了基于網格像素統計的方法,通過實驗,發現識別能力比較差,不能達到預想的結果。
針對上面的結果,我參考何兆成等人的方法,在字符細化后的基礎上,通過統計字符筆畫斜率特征,字符側面深度等特征作為字符提取的特征,得到22個特征值。具體統計方法如下:
(1)基于筆畫斜率的累計特征提取
字符最具代表性的特征是筆畫,不同的字符有不同的筆畫數量,形態,長度等,所以可將筆畫的斜率累計值作為特征進行特征值提取。筆畫斜率有正斜率,負斜率,零斜率三部分,分別統計字符零斜率,正斜率,負斜率的累加和。斜率的統計過程,例如從字符左邊掃描,當前的掃描點為 ,下一個掃描點為為 。斜率K值計算如下:
通過上面的過程,從字符左側開始計算斜率特征,可以得到3個特征。我這里從字符左右上下四個方向統計斜率特征可以得到12個特征值。
(2)拐點幅度累計特征提取
在字符中字符的拐點含有豐富的特征。所以統計拐點幅度特征累計和,可以得到4個特征值。拐點幅度特征 計算如下:
(3)字符輪廓深度特征提取
不同的字符在輪廓上有著明顯差異。比如“S”和“C”。如下圖中的“S”字符,從右側掃描深度的時候有著有很多的凹凸信息。而字符“C”從右側掃描的過程中,字符的中間凹陷比較明顯。所以通過掃描字符四個方向的輪廓深度,也能得到4個輪廓特征值。
(4)字符跳躍點統計
由于字符“1”和“B”從左側掃描過程中基本上沒有區別。所以,為了更準確些。我這里通過統計字符水平掃描跳躍點和垂直掃描字符跳躍點來區分。很明顯,字符“1”和字符“B”水平和垂直方向的跳躍點有明顯的差別。以上過程可以得到2個字符特征。
通過以上分析總共可以得到22個字符特征值。將這些特征進行訓練,即可得到所需的結果。關鍵代碼如下(計算左邊的特征值為例):
if(left[i]==-1)
{
while(left[i] == -1) i++;
}
begin=i;i=Height-1;
if(left[i] == -1)
{
while(left[i] == -1) i--;
}
end = i;
for(i=begin;i<=end;i++)
{
if(left[i] == -1)
left[i] = left[i+1];
}
//掃描深度
for(i=begin;i<=end;i++)
{
feature[4] += left[i];
}
feature[4]=feature[4]/10;
double *leftradio = new double[end-begin];
for(i=0;i
leftradio[i]=0;
int n=0;
for(i=begin;i<=(end-4);i++)
{
//如果斜率為零
if(left[i] == left[i+4])
{
feature[0]++;
leftradio[n]=0;
}
else
{
leftradio[n] =(left[i]-left[i+4])/4.0;
if(leftradio[n] <0) //如果斜率小于0
feature[1]++;
else //斜率大于0
feature[2]++;
}
n++;
}
for(i=1;i
{
feature[3] +=fabs(leftradio[i]-leftradio[i-1]);
}
5.神經網絡訓練
通過提取的特征值,識別的算法有很多,包括分類器算法,模板匹配算法,基于概率統計的Bayes分類器算法,聚類分析算法等。我這里采用的是BP神經網絡分類器算法。
將提取的特征值,輸入層為22個特征,隱含層為80個特征,輸出層為34個特征。這里去除字母“I”和“O”。字符0-9,24個字母一共34個輸出。說明:由于有34個輸出,所以這里理想情況下輸出結果為33個0和一個1.只是1在第i個輸出。i對應的數字編號如0則對應0,1對應1,9對應9,字符“A”對應10,字符“B”對應11,依次類推,字符“Z”對應33。
%創建BP網絡
net_1=newff(minmax(p),[80,34],{'tansig','purelin'},'traingdm')
%當前輸入層權值和閾值
inputWeights=net_1.IW{1,1};
inputbias=net_1.b{1};
%當前網絡層權值和閾值
layerWeights=net_1.LW{2,1};
layerbias=net_1.b{2};
%設置訓練參數
net_1.trainParam.show = 50;
net_1.trainParam.lr = 0.01; %學習率
net_1.trainParam.mc = 0.9;
net_1.trainParam.epochs = 10000;%訓練次數
net_1.trainParam.goal = 1e0; %目標誤差
%調用 TRAINGDM 算法訓練 BP 網絡
[net_1,tr]=train(net_1,p,q);
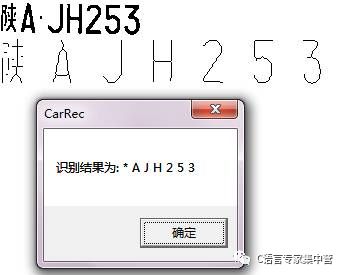
6.車牌圖像識別結果測試
因為車牌中的漢字與字母數字的結構以及骨架不同,所以漢字的識別過程需要另外再做處理,所以本文處理的是車牌除漢字外的車牌圖像識別過程。通過最終的測試實驗結果,數字的識別結果正確率比較高,字符的識別正確率比較低一點(由于訓練用的英文字符比較少)。
識別結果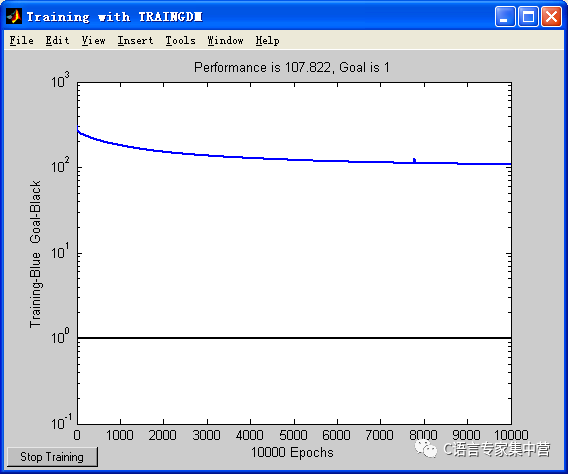
-
RGB
+關注
關注
4文章
801瀏覽量
58717 -
BMP
+關注
關注
0文章
48瀏覽量
17093
原文標題:車牌識別步驟及部分代碼
文章出處:【微信號:C_Expert,微信公眾號:C語言專家集中營】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【超值干貨】 揭秘車牌識別算法
移動端車牌識別SDK算法
車牌識別算法的關鍵技術及研究





 工商網監
工商網監
評論