 機器學習新手最適合學習的10個算法
機器學習新手最適合學習的10個算法
在機器學習領域里,不存在一種萬能的算法可以完美解決所有問題,尤其是像預測建模的監督學習里。
比方說,神經網絡不見得比決策樹好,同樣反過來也不成立。最后的結果是有很多因素在起作用的,比方說數據集的大小以及組成。所以,針對你要解決的問題,最好是嘗試多種不同的算法。并借一個測試集來評估不同算法之間的表現,最后選出一個結果最好的。
當然,你要選適合解決你問題的算法來嘗試。比方說,要打掃房子,你會用真空吸塵器,掃把,拖把;你絕對不會翻出一把鏟子來開始挖坑,對吧。不過呢,對于所有預測建模的監督學習算法來說,還是有一些通用的底層原則的。
機器學習算法,指的是要學習一個目標函數,能夠盡可能地還原輸入和輸出之間的關系。
然后根據新的輸入值X,來預測出輸出值Y。精準地預測結果是機器學習建模的任務。
所以我們來了解一下,Top10機器學習算法1線性回歸
統計學與機器學習領域里研究最多的算法。做預測建模,最重要的是準確性(盡可能減小預測值和實際值的誤差)。哪怕犧牲可解釋性,也要盡可能提高準確性。為了達到這個目的,我們會從不同領域(包括統計學)參考或照搬算法。線性回歸可用一條線表示輸入值X和輸出值Y之間的關系,這條線的斜率的值,也叫系數。
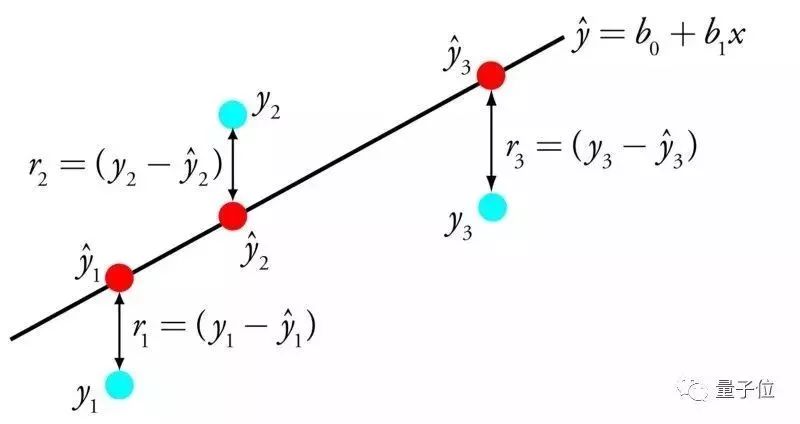
比方說,y = B0 + B1*x,我們就可以根據X值來預測Y值。機器學習的任務就是找出系數B0和B1。從數據中建立線性回歸的模型有不同的方法,比方說線性代數的最小二乘法、梯度下降優化。線性回歸已經存在了200多年,相關研究已經很多了。用這個算法關鍵在于要盡可能地移除相似的變量以及清洗數據。對算法萌新來說,是最簡單的算法了。
2邏輯回歸
這方法來自統計學領域,是一種可以用在二元分類問題上的方法。邏輯回歸,和線性回歸相似,都是要找出輸入值的系數權重。不同的地方在于,對輸出值的預測改成了邏輯函數。邏輯函數看起來像字母S,輸出值的范圍是0到1。把邏輯函數的輸出值加一個處理規則,就能得到分類結果,非0即1。比方說,可以規定輸入值小于0.5,那么輸出值就是1。
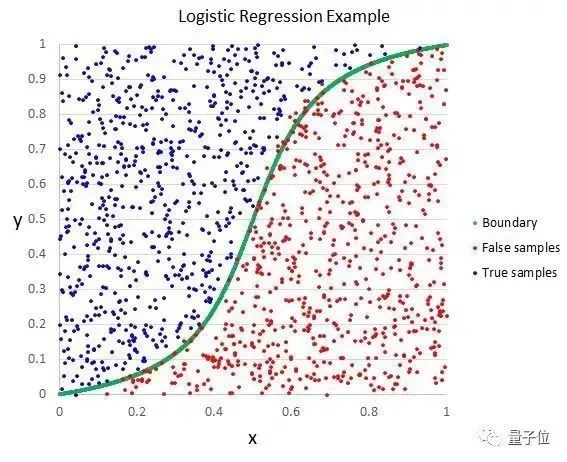
這個算法還可以用來預測數據分布的概率,適用于需要更多數據論證支撐的預測。和線性回歸相似,如果把和輸出不相干的因子或者相近的因子剔除掉的話,邏輯回歸算法的表現會更好。對于二元分類問題,邏輯回歸是個可快速上手又有效的算法。
3線性判別分析
邏輯回歸算法,只能用于二分問題。當輸出的結果類別超過兩類的時候,就要用線性判別分析算法了。這種算法的可視化結果還比較一目了然,能看出數據在統計學上的特征。這上面的結果都是分別計算得到的,單一的輸入值可以是每一類的中位數,也可以是每一類值的跨度。
基于對每種類別計算之后所得到的判別值,取最大值做出預測。這種方法是假定數據符合高斯分布。所以,最好在預測之前把異常值先踢掉。對于分類預測問題來說,這種算法既簡單又給力。
4分類與回歸樹
預測模型里,決策樹也是非常重要的一種算法。可以用分兩叉的樹來表示決策樹的模型。每一個節點代表一個輸入,每個分支代表一個變量(默認變量是數字類型)
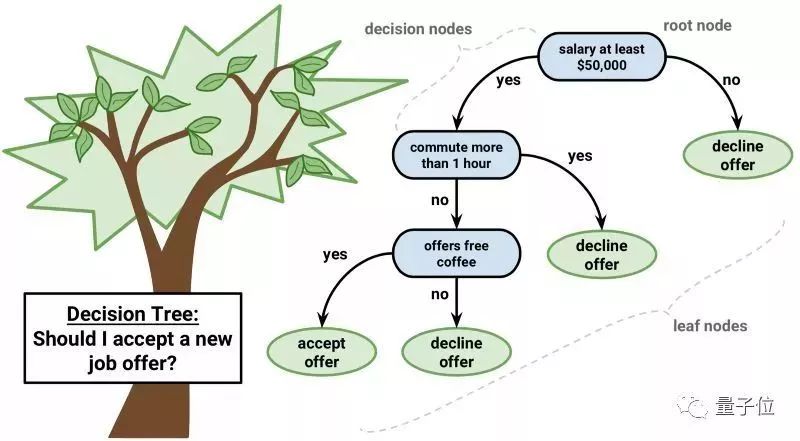
決策樹
決策樹的葉節點指的是輸出變量。預測的過程會經過決策樹的分岔口,直到最后停在了一個葉節點上,對應的就是輸出值的分類結果。決策樹很好學,也能很快地得到預測結果。對于大部分問題來說,得到的結果還挺準確,也不要求對數據進行預處理。
5樸素貝葉斯分類器
這種預測建模的算法強大到超乎想象。這種模型,可以直接從你的訓練集中計算出來兩種輸出類別的概率。一個是每種輸出種類的概率;另外一個,是根據給定的x值,得到的是有條件的種類概率。一旦計算之后,概率的模型可以用貝葉斯定理預測新的數據。當你的數據是實數值,那么按理說應該是符合高斯分布的,也就很容易估算出這個概率。
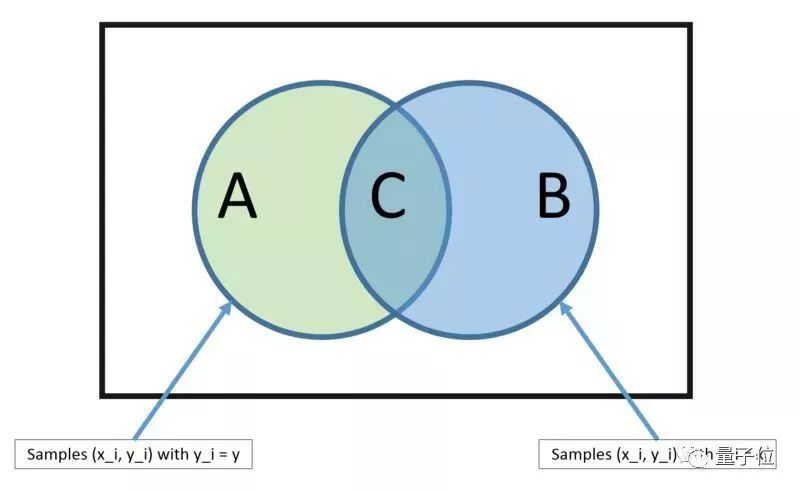
貝葉斯定理
樸素貝葉斯定理之所以名字里有個“樸素”,是因為這種算法假定每個輸入的變量都是獨立的。不過,真實的數據不可能滿足這個隱藏前提。盡管如此,這個方法對很多復雜的問題還是很管用的。
6K近鄰算法
最近K近鄰的模型表示,就是整個訓練集。很直截了當,對吧?對新數據的預測,是搜索整個訓練集的值,找到K個最近的例子(literally的鄰居)。然后總結K個輸出的變量。這種算法難就難在,怎么定義兩個數據的相似度(相距多近算相似)。如果你的特征(attributes)屬于同一個尺度的話,那最簡單的方法是用歐幾里得距離。這個數值,你可以基于每個輸入變量之間的距離來計算得出。
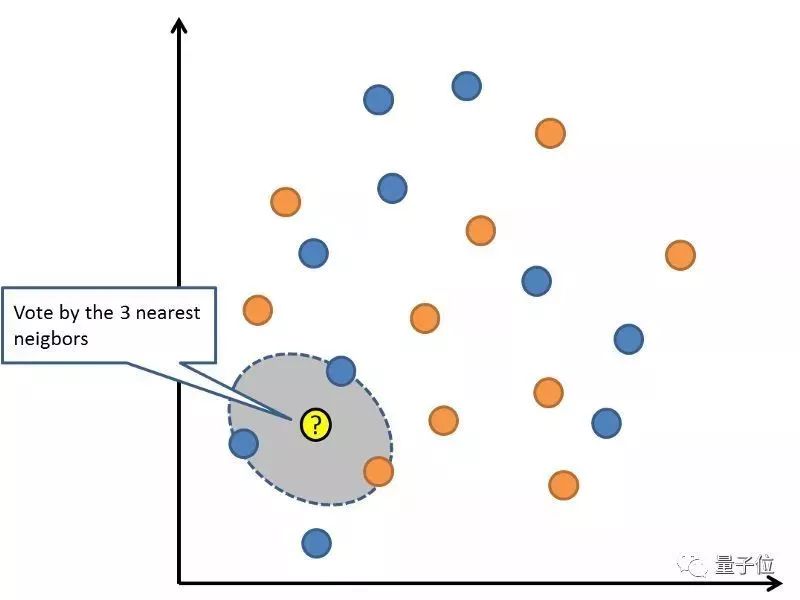
最近鄰法,需要占用大量的內存空間來放數據,這樣在需要預測的時候就可以進行即時運算(或學習)。也可以不斷更新訓練集,使得預測更加準確。距離或親密度這個思路遇到更高維度(大量的輸入變量)就行不通了,會影響算法的表現。這叫做維度的詛咒。當(數學)空間維度增加時,分析和組織高維空間(通常有成百上千維),因體積指數增加而遇到各種問題場景。所以最好只保留那些和輸出值有關的輸入變量。
7學習矢量量化
最近鄰法的缺點是,你需要整個訓練集。而學習矢量量化(后簡稱LVQ)這個神經網絡算法,是自行選擇訓練樣例。
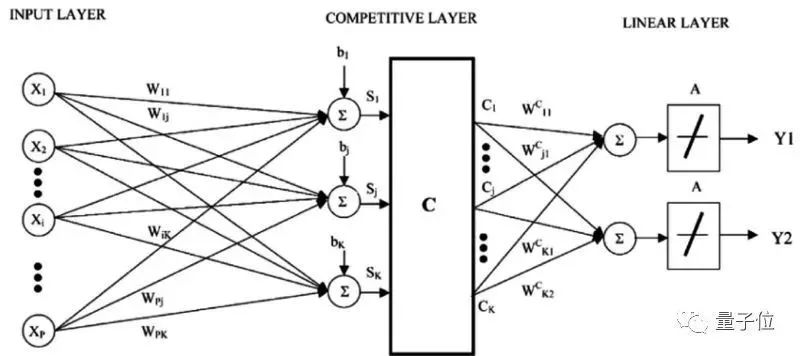
LVQ,是一組矢量,也叫碼本。一開始,矢量是隨機選的,經過幾次學習算法迭代之后,慢慢選出最能代表訓練集的矢量。學習完成后,碼本就可以用來預測了,就像最近鄰法那樣。計算新輸入樣例和碼本的距離,可以找出最相近的鄰居,也就是最匹配的碼本。如果你重新調整數據尺度,把數據歸到同一個范圍里,比如說0到1之間,那就可以獲得最好的結果。如果用最近鄰法就獲得了不錯的結果,那么可以再用LVQ優化一下,減輕訓練集儲存壓力。
8支持向量機(簡稱SVM)
這可能是機器學習里最受歡迎的算法了。超平面是一條可以分割輸入變量的空間的“線”。支持向量機的超平面,是能把輸入變量空間盡可能理想地按種類切割,要么是0,要么是1。在二維空間里,你可以把超平面可以分割變量空間的那條“線”。這條線能把所有的輸入值完美一分為二。SVM的學習目標就是要找出這個超平面。
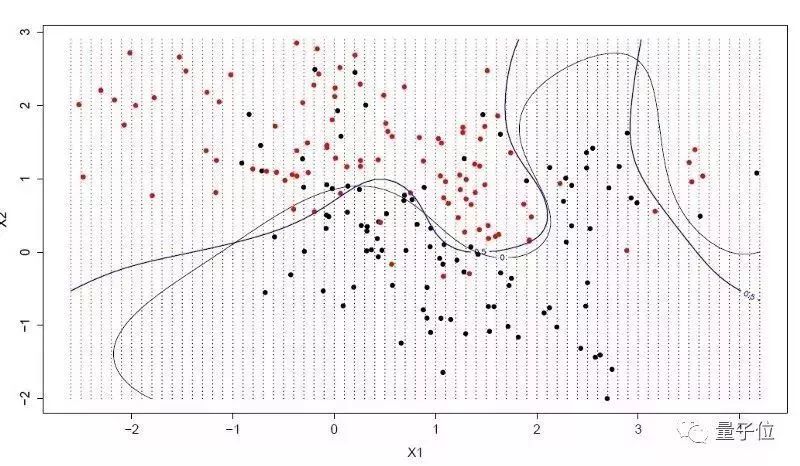
超平面和挨得最近的數據點之間的距離,叫做邊緣。最理想的超平面,是可以無誤差地劃分訓練數據。 也就是說,每一類數據里距離超平面最近的向量與超平面之間的距離達到最大值。這些點就叫做支持向量,他們定義了超平面。從實際操作上,最理想的算法是能找到這些把最近矢量與超平面值距離最大化的點。支持向量可能是最強的拿來就用的分類器了。值得用數據集試試。
9隨機森林
隨機森林,屬于一種重復抽樣算法,是最受歡迎也最強大的算法之一。在統計學里,bootstrap是個估算值大小很有效的方法。比方說估算平均值。從數據庫中取一些樣本,計算平均值,重復幾次這樣的操作,獲得多個平均值。然后平均這幾個平均值,希望能得到最接近真實的平均值。而bagging算法,是每次取多個樣本,然后基于這些樣本建模。當要預測新數據的時候,之前建的這些模型都做次預測,最后取這些預測值的平均數,盡力接近真實的輸出值。
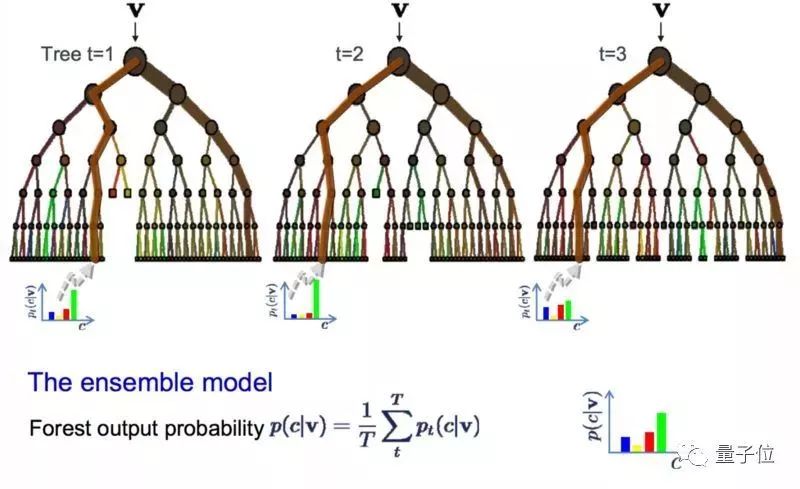
隨機森林在這個基礎上稍微有點變化。它包含多個決策樹的分類器, 并且其輸出的類別是由個別樹輸出的類別的眾數而定。如果你的高方差算法取得了不錯的結果(比方說決策樹),那么用隨機森林的話會進一步拿到更好的結果。
10提升(Boosting)算法和自適應增強(Adaboost)算法
Boosting的核心是,對同一個訓練集訓練不同的分類器(弱分類器),然后把這些弱分類器集合起來,構成一個更強的最終分類器(強分類器)。所得到的第二個弱分類器會糾正第一個弱分類器的誤差。弱分類器的不斷疊加,直到預測結果完美為止。Adaboost算法是首個成功用于二元分類問題的提升算法。現在有很多提升方法都是基于Adaboost。
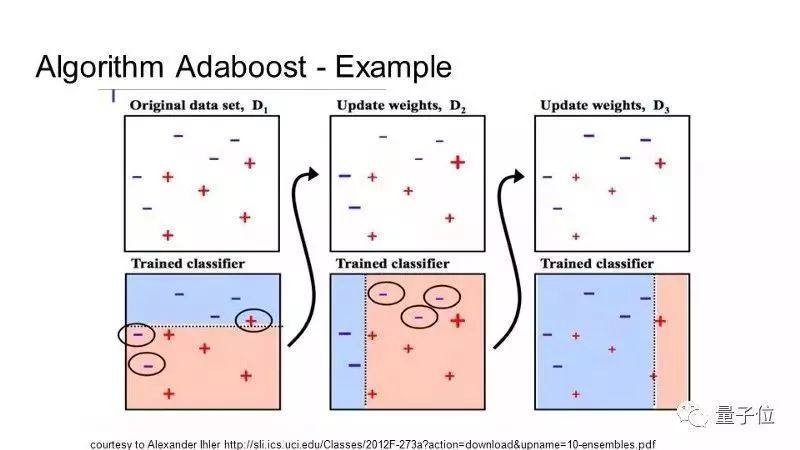
AdaBoost適用于短的決策樹。在第一個樹建立出來之后,不同的樣本訓練之后的表現可以作參考,用不同的樣本訓練弱分類器,然后根據錯誤率給樣本一個權重。很難預測的訓練數據應該給更多的權重,反過來,好預測的就少一點權重。模型按順序一個一個建,每個訓練數據的權重都會受到上一個決策樹表現的影響。當所有的決策樹都建好之后,看新數據的預測表現,結果準不準。因為訓練數據對于矯正算法非常重要,所以要確保數據清洗干凈了,不要有奇奇怪怪的偏離值。
最后的最后面對海量的機器學習算法,萌新最愛問的是,“我該選什么算法?”在回答這個問題之前,要先想清楚:
1)數據的數量、質量、本質;
2)可供計算的時間;
3)這個任務的緊急程度;
4)你用這個數據想做什么。
要知道,即使是老司機,也無法閉著眼睛說哪個算法能拿到最好的結果。還是得動手試。其實機器學習的算法很多的,以上只是介紹用得比較多的類型,比較適合萌新試試手找找感覺。
-
算法
+關注
關注
23文章
4630瀏覽量
93355 -
機器學習
+關注
關注
66文章
8438瀏覽量
133084
原文標題:機器學習萌新必學的Top10算法
文章出處:【微信號:machinelearningai,微信公眾號:機器學習算法與人工智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PROTEL新手最適合的教程我是受益匪淺希望對你有用
如何在STM板上使用機器學習算法對通過工業傳感器獲取的氣體傳感器數據進行分類?
分享最適合新手入門的10種機器學習算法
新手如何接觸機器學習的這十大算法一定不能錯過
Python基礎教程之《Python機器學習—預測分析核心算法》免費下載
機器學習新手常犯的錯誤怎么避免?
2021年最適合的機器學習初創公司進行排名
機器學習新手基礎:十大算法導覽
10個機器學習中常用的距離度量方法






 工商網監
工商網監
評論