 如何使用MATLAB構建Transformer模型
如何使用MATLAB構建Transformer模型
Transformer 模型在 2017 年由 Vaswani 等人在論文《Attentionis All You Need》中首次提出。其設計初衷是為了解決自然語言處理(Nature LanguageProcessing, NLP)中的序列到序列任務,如機器翻譯。Transformer 通過引入自注意力機制使得處理長距離依賴關系時變得高效。因此 Vaswani 等人的論文強調“注意力是所需的一切”。
傳感器數據表現為時間序列,并且序列內部往往存在時間上的依賴關系,這些時間上的依賴能夠反映出設備的當下或未來的狀態,如何發現和挖掘序列內部的知識和依賴關系,是以傳感器表征設備狀態的工業領域中故障診斷關注的重點。
本文中主要關注 Transformer 在傳感器數據中的應用,通過其編碼器功能捕獲序列內部依賴關系,尤其是長距離的依賴關系,并生成輸出數據做進一步處理。后續的內容將對圖 1 中的編碼器的功能及其在 MATLAB 中的實現做進一步介紹,最后通過一個案例演示在 MATLAB 如如何設計和構建 Transformer 的編碼器網絡,并在信號數據集中進行訓練,同時也展示了經過初步訓練后的模型在測試集上的良好測試結果。由于篇幅所限,文章中不能展示全部過程的 MATLAB 代碼,如果讀者想要測試運行代碼,可以掃碼后通過提供的鏈接進行下載。
1. Transformer 模型
Transformer 模型的核心是自注意力機制(Self-Attention Mechanism)及完全基于注意力的編碼器-解碼器架構。圖1顯示了在論文《Attention is All You Need》中提出的 Transformer 架構,其主要由編碼器(Encoder,圖 1 中左側部分)和解碼器(Decoder,圖1中的右側部分)兩個部分組成,編碼器的輸出序列將編碼器和解碼器關聯起來,構建跨序列的注意力機制。
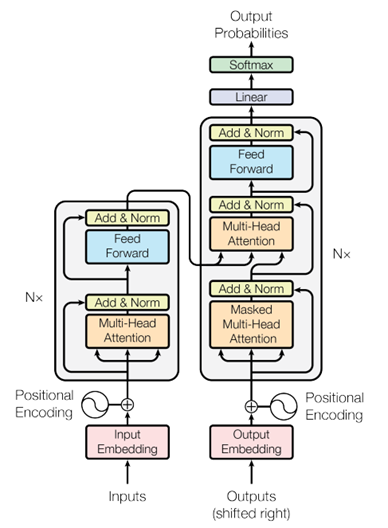
圖 1 Transformer 架構
Transformer 編碼器(Encoder)專門用于處理輸入序列,通過引入自注意力機制,使其能夠高效地捕捉序列中的長距離依賴關系。而這種依賴關系體現為輸入序列不同位置之間的相關性。并且將相關性信息加入到輸出序列中,使得輸出數據包含豐富的上下文信息。
Transformer 解碼器(Decoder)主要負責逐步生成輸出結果。解碼器根據編碼器生成的上下文信息和前一步生成的輸出,逐步輸出目標序列的每一個元素。在解碼器中,采用了帶有掩碼的自注意力機制,使得在計算輸出向量時只考慮當前和之前的輸入數據,以保持生成結果的順序性。同時,解碼也采用了交叉注意力機制,將編碼器的輸出結果引入到解碼器中。通過交叉注意力機制,計算與編碼器的輸出序列的相關性。這一機制保證解碼器在生成每個輸出向量(輸出詞)時,不僅要考慮之前輸出的詞,還要考慮編碼器生成的上下文信息。
本文主要關注 Transformer 在時間序列(信號)上的應用,主要利用 Transformer 編碼器發現序列內部在時間上的依賴關系。接下來將重點介紹 Transformer 編碼器及其在 MATLAB 中的實現,并利用 Transformer 編碼器構建分類模型 。
2.Transformer編碼器及其在MATLAB中的實現
Transformer 編碼器的主要由輸入、位置編碼(input embedding)、多頭注意力(multi-head attention)、殘差(Add)、標準化(Norm),以及前饋網絡(Feed Forward)組成。對于每一個組成部分,在MATLAB中都對應的網絡層。
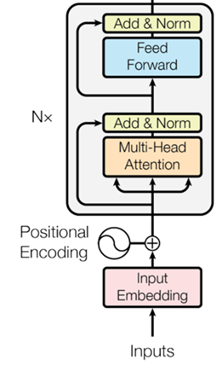
圖 2Transformer 編碼器
輸入序列
Transformer 的提出是針對序列到序列的自然語言處理任務。自然語言文本首先被轉換為固定長度的向量表示,進而形成輸入向量序列。我們以自然語言文本“Do you speak MATLAB”為例,MATLAB 中的文本分析工具箱提供FastText預訓練詞嵌入模型,可以將英文單詞轉換為 300 維的詞向量。例如對于“Do”,通過以下操作可以轉為300維的詞向量 vec (如下所示):

基于 FastText 生成詞向量
其中,fastTextWordEmbedding是FastText預訓練詞嵌入模型,word2vec將詞轉換為向量表示。進而,輸入的自然語言文本被轉換為詞向量序列,如圖 3 所示

圖 3 自然語言文本轉換為詞向量序列
位置編碼(input embedding)
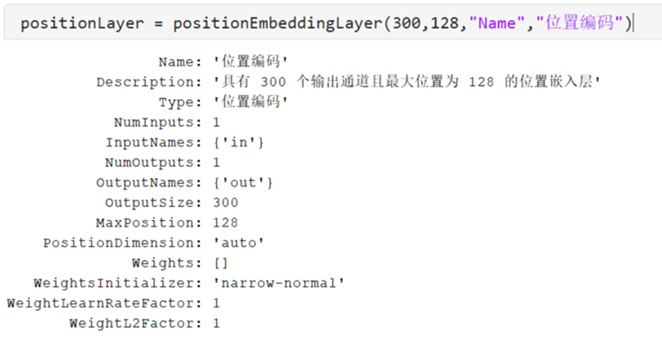
Transformer 不具備內置的序列順序信息,需要通過位置編碼將序列位置信息注入到輸入數據中。在 MATLAB 中,通過使用positionEmbeddingLayer層,將序列順序信息注入到輸入數據中,如下所示。positionEmbeddingLayer的OutputSize的屬性設置為詞向量維度。
自注意力機制
Transformer 模型的核心是自注意力機制。對于輸入序列中每個位置對應的向量。自注意力機制首先通過線性變換生成三個向量:查詢(Query),鍵(Key),和值(Value)。然后,通過計算查詢和鍵之間的點積來獲得注意力得分(即相關性),這些得分經過 Softmax 歸一化后,用于加權求和值向量,即生成輸出向量。
以圖3中的輸入序列為例,假設自然語言文本對應的詞向量按順序分別定義為d, y, s, m。并且定義 Query,Key,Value 的轉換矩陣為wq, wk, wv。對于詞“you”對應的詞向量y,通過線性變換生成的 Query,Key,Value 向量為:
yq = wq × y;
yk = wk × y;
yv = wv × y;
同理,對于詞“Do”對應的詞向量d,通過線性變換生成的 Query,Key,Value 向量為:
dq = wq × d;
dk = wk × d;
dv = wv × d;
其它兩個詞向量以此類推。
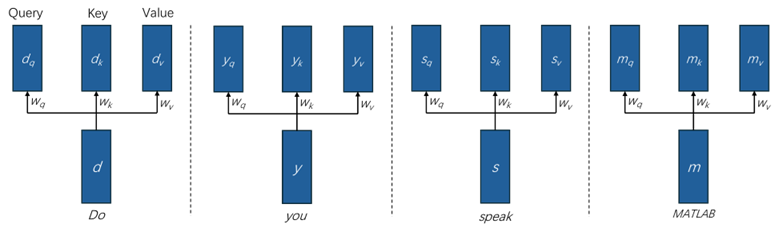
圖 4 詞向量的線性變換
對于詞“Do”,計算其與其它四個詞的相關性,分別為:·
rdd =dq· dk
rdy =dq· yk
rds = dq · sk
rdm =dq· mk
其中,rdd,rdy,rds,rdm,分別表示“Do”與自身、“you”、“speak”、“MATLAB”的相關性。利用 softmax 對相關性做歸一化處理,并生成歸一化后的相關性srdd,srdy,srds,srdm,將其它詞對當前詞的影響納入的新生成的向量do 中,即:
do=srdd× dv+ srdy× yv + srds× sv+ srdm× mv
使用同樣的計算,可以得到輸出向量:do,yo,so,mo(如圖5所示)。
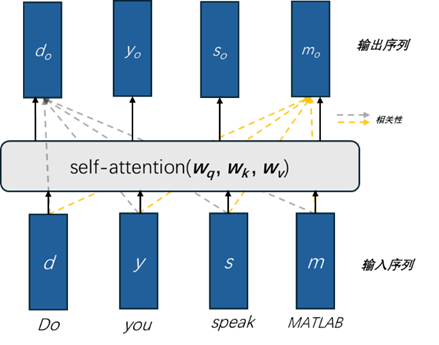
圖 5 輸入的序列經過自注意力計算后生成新的輸出序列
通過以上介紹,self-attention 機制可以總結出:
通過三個線性變換(也是要學習的參數,當然還包含偏差)對輸入序列的每個位置的向量衍生出三個向量,經過相關性計算以及加權平均,又轉換為一個輸出向量。但是輸出向量不僅包含自身的信息,還同時包含了與輸入序列其它位置的依賴關系(即其它位置向量的相關性),因此其信息內容更加豐富。
每個輸入序列位置上的計算過程都是獨立進行,并沒有前后依賴關系(類似 LSTM),因此可以通過并行計算進行加速
通過獨立計算不同位置間的相關性來捕獲輸入序列內部的依賴信息,因此其處理長距離的依賴關系更有效,可以避免 LSTM 的長距離依賴關系通過串行傳遞導致的信息不斷衰減問題。
在 MATLAB 中,selfAttentionLayer層實現了自注意力機制。NumKeyChannels屬性決定轉換后的 Key 向量的維度。因為 Query 要與 Key 做內積,所以 Query 向量的維度與 Key 的維度相同。對于 Value 向量的維度,也可以通過屬性NumValueChannels進行設置。如果NumValueChannels設置為“auto”,那么其與 key 向量的維度一致 (如下所示)。

自注意力機制中,線性變換矩陣就是要學習的參數(當然也包含偏差)。而參數規模通過設置生成的 Query、Key 和 Value 向量的維度自動決定。例如,當詞向量 d 的維度是 300,如果設置 Key 向量 k 的維度設置為 512,那么變換矩陣wk(Key Weights)大小為:512×300,即:

自注意力中的 Key 向量生成過程
帶有掩碼的自注意力機制(Masked Self-Attention)
Masked Self-Attention 主要用于處理序列數據中的有序性,使用掩碼來限制注意力的范圍。具體來說,掩碼會遮擋掉未來時間步的信息,確保模型在生成當前位置的輸出向量時,只能訪問當前位置及之前位置的詞向量,以保持生成過程的順序性。在 MATLAB 中,通過設置selfAttentionLayer層的屬性AttentionMask值為“causal”實現帶掩碼的自注意力機制。
多頭自注意力機制
多頭自注意力通過并行地執行多個自注意力計算(也就是單頭自注意力計算),然后將結果拼接起來。這種方法允許模型在不同的“注意力空間”中捕捉不同類型的信息。這里的“注意力空間”可以用一組 Query、key、Value 向量的線性變換表示。每個“頭”使用不同的線性變換對輸入序列生成 Query、key、Value,再計算注意力,并生成不同的輸出向量。將所有頭的輸出向量拼接(concatenate)在一起。拼接后的結果可以選擇(也可以不選擇)通過另一個線性變換整合來自所有頭的信息,生成最終的多頭自注意力輸出向量(如圖6所示)。
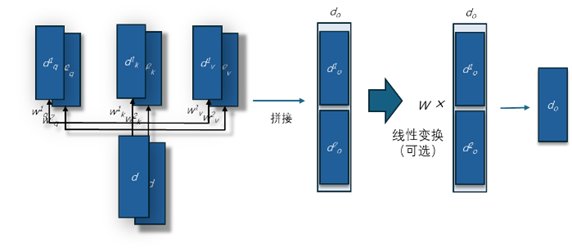
圖 6 多頭(2頭,two-head)自注意力機制
在 MATLAB 中,通過設置selfAttentionLayer層的屬性NumHeads來決定多頭自注意力機制的頭數(heads)。
在 Transformer 中,除了自注意力機制外的前饋網絡、殘差鏈接、以及層歸一化,都屬于常規網絡層,分別對應 MATLAB 中fullyConnectedLayer、additionLayer和layerNormalizationLayer,這些都是常規操作,這里就不做介紹。 ▼
3.Transformer編碼器在基于信號數據的故障診斷中的應用
設備故障診斷是涉及通過各種傳感器數據檢測和識別設備故障。傳感器數據內部蘊含了時間上的依賴關系,這種依賴關系表現了設備的動態變化過程,因此,捕獲傳感器數據蘊含的動態變化過程,可以很好的識別和預測設備的故障狀態。
本文的故障診斷案例是針對使用軸承的旋轉機械。這些機械系統常常因電流通過軸承放電而導致電機軸承在系統啟動后的幾個月內發生故障。如果未能及時檢測這些問題,可能會導致系統運行的重大問題。
數據集
數據集包含從軸承測試臺和真實生產中的旋轉機械收集的振動數據。總共有 34 組數據。信號采樣頻率為 25 Hz。設備狀態包含三種:健康(healthy),內圈故障(inner race fault),外圈故障(outer race fault)。
由于軸承電流是由變速條件引起的,故障頻率會隨著速度變化而在頻率范圍內上下波動。因此,軸承振動信號本質上是非平穩的。時頻表示可以很好地捕捉這種非平穩特性。從信號的時間、頻率和時頻表示中提取的組合特征可用于提高系統的故障檢測性能。圖7顯示了信號在時域和時頻域上的顯示。
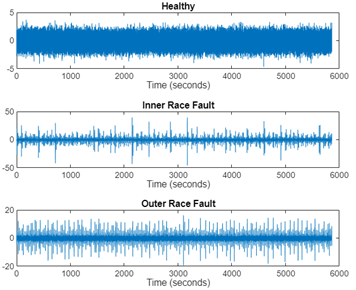
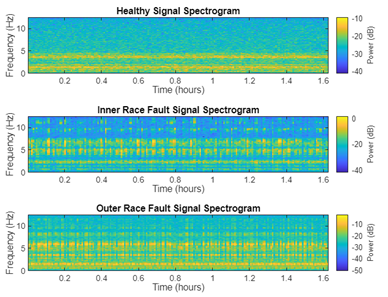
圖 7 輸入數據(信號)在時域(上)和時頻域(下)上的顯示
對于信號數據,MATLAB 提供了特征提取函數,可以分別從時域、頻域和時頻域上提取特征:
時域 - signalTimeFeatureExtractor
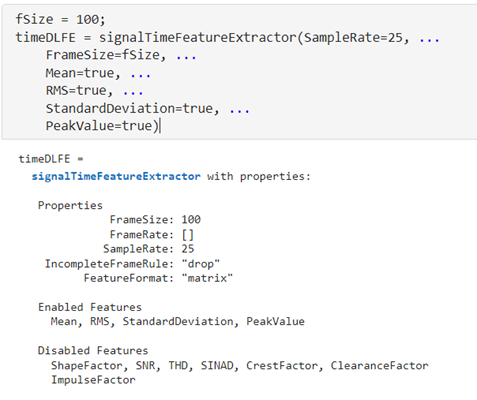
signalTimeFeatureExtractor 可以提取時域上的統計特征,如期望(mean)、均方根(RMS)、標準差(StandardDeviation)、及峰值(PeakValue)。而時域上的其它特征,如ShapeFactor、SNR等在本文案例中并沒有提取。signalTimeFeatureExtractor 在做信號特征提取的時候需要設置一個窗口(FrameSize),窗口大小決定了計算統計特征的采樣點數量。
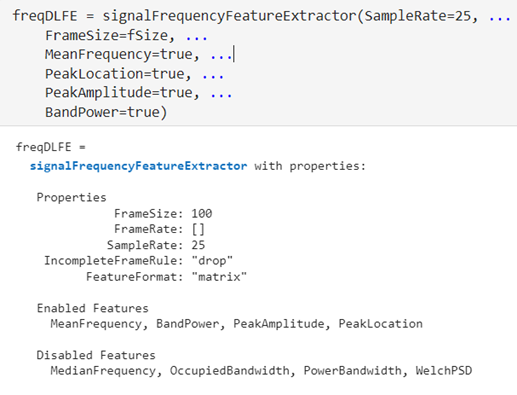
頻域 – signalFrequencyFeatureExtractor
signalFrequencyFeatureExtractor 用于在頻域上提取信號的統計特征,在本文中,主要提取頻率期望(MeanFrequency)、頻譜峰值位置(PeakLocation)、頻譜峰值(PeakAmplitude)、及平均頻帶功率(BandPower)。頻域上的其它特征,如OccupiedBandwidth等在本文中并沒有提取。signalFrequencyFeatureExtractor 在做信號特征提取時,同樣需要設置一個窗口(FrameSize),用于指定每個幀的采樣點數,也是頻域特征提取時分析窗口的大小。當處理長時間信號時,將信號分成較小的幀可以更有效地進行頻域分析。
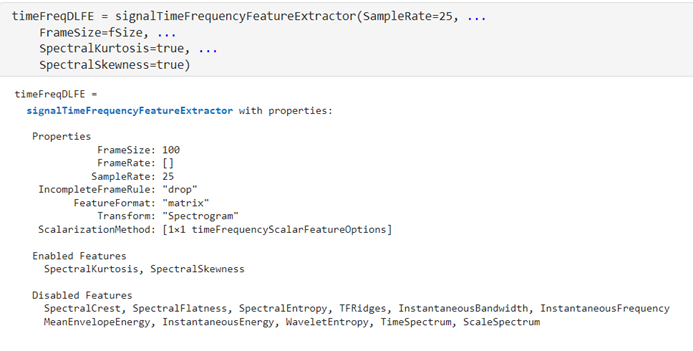
時頻域 – signalTimeFrequencyFeatureExtractor
signalTimeFrequencyFeatureExtractor 用于在時頻域上提取信號的特征,捕捉到信號在時間和頻率上的變化。在本文中,時頻上提取頻譜峭度(SpectralKurtosis)和頻譜偏度(SpectralSkewness)。在時頻域分析中,譜峭度值描述了信號在特定時間點上的頻譜形狀的尖銳程度或平坦程度,通過頻譜峭度分析,可以識別信號中的瞬態事件或沖擊。譜偏度值描述了信號在特定時間點上頻譜的對稱性或偏斜程度,通過分析頻譜偏度,可以識別信號中非對稱的頻率分布。
原始信號經過分幀并做特征提取,從具有 146484 采樣點一維數據,轉換為 1464×30 的二維矩陣,如圖 8 所示。矩陣的行表示時間點,矩陣的列表示特征。
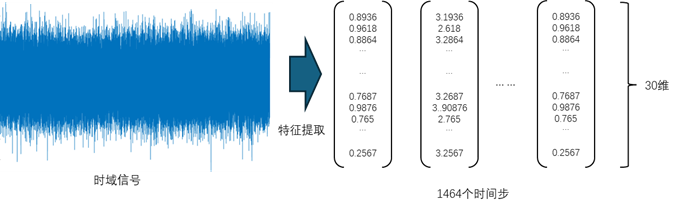
圖 8 經過特征提取的信號數據
對于轉換后的數據,每個特征可以抽象成一個傳感器,每個采樣點同時從 30 個傳感器采集數據而組成一個特征向量。一個樣本共進行1464次采樣。這樣就為接下來的 Transformer 編碼器模型訓練準備好了數據基礎
基于Transformer編碼器構建分類模型
本文是對照《Attentionis all you need》論文中的 Transformer 編碼器,通過Deep Network Designer App構建編碼器網絡,如圖9所示。Transformer 編碼器的每個組成部分,在MATLAB中都有對應的網絡層,通過這些層可以快速的組建網絡,并自定義每層的參數。例如本文中,selfAttentionLayer層的頭數是 2,并帶有掩碼。
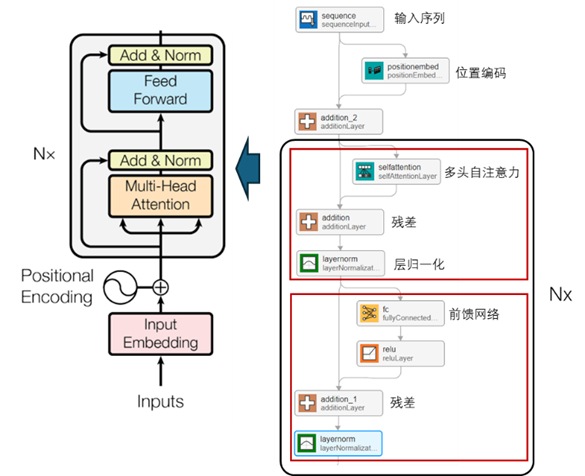
圖 9 基于Transformer的編碼器構建故障診斷模型(分類模型)
編碼器的輸出是帶有上下文信息的向量序列,而在設備的故障診斷中,故障的類型是離散的。本文中,軸承有內圈故障、外圈故障、以及健康狀態三種類型。因此,還需要利用編碼器的輸出向量,進一步來構建三分類模型。
對于 Transformer 編碼器的輸出向量序列,MATLAB 提供globalAveragePooling1dLayer和globalMaxPooling1dLayer兩種全局池化方法,在序列(或時間)方向上做向量每個維度上的數據合并。在本文中,編碼器的輸出序列向量的維度是 30,序列長度(時間步)是 1464,即 1464×30。經過數據合并后,變為:1×30,如圖 10 所示。
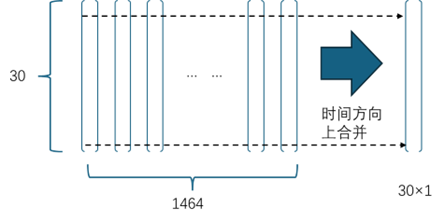
圖 10 向量序列在時間方向的合并
序列數據做全局池化后的輸出結果是一維數據,通過連接全連接網絡層fullyConnectedLayer,進一步縮減為三輸出,即對應于三分類。最后再通過softmaxLayer轉換為概率分布,進而判斷所屬類別。整體網絡模型如圖11所示。
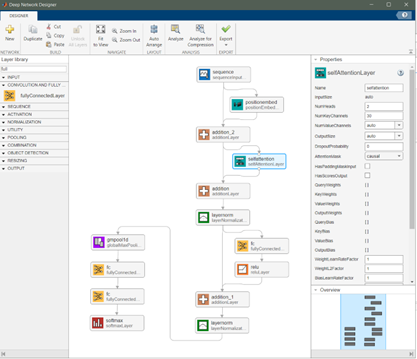
圖11 基于 Transformer 的編碼器構建分類模型
模型訓練與測試
本文共收集34條信號數據,采用隨機的方式按照 70% 和 30% 進一步將數據集劃分為訓練集和測試集(由于數據量有限,訓練過程并沒有使用驗證集)。
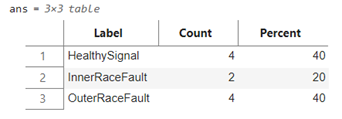
訓練集(上)和測試集(下)
模型訓練過程,MATLAB 提供了超參數選項實現模型的進一步調優,而超參數選項是通過 trainingOptions 函數設置的,包括初始學習速率、學習速率衰減策略、minibatch 大小、訓練執行環境(GPU、CPU)、訓練周期等等。經過 100 個 Epoch 訓練的模型在測試集上的測試結果如下:
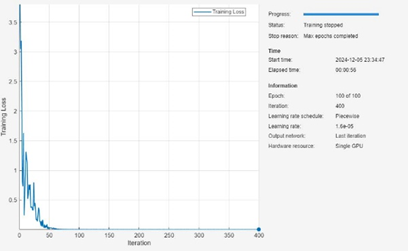
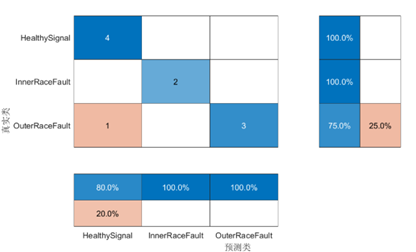
圖 12 模型訓練過程(上)和測試集精度(heatmap)(下)
從測試的結果看,Transforme 編碼器對長距離依賴關系的捕獲效果還是比較好的。
4.總結
本文的目的主要是介紹 Transformer 模型的編碼器,以及如何使用 MATLAB 構建 Transformer 模型,并為讀者提供一種 Transformer 編碼器的應用思路,模型本身以及訓練過程還有可以優化地方,僅為讀者提供參考,也歡迎大家做進一步模型結構調整和精度提升。
-
matlab
+關注
關注
185文章
2981瀏覽量
231010 -
編碼器
+關注
關注
45文章
3669瀏覽量
135245 -
模型
+關注
關注
1文章
3309瀏覽量
49224 -
深度學習
+關注
關注
73文章
5515瀏覽量
121551 -
Transformer
+關注
關注
0文章
146瀏覽量
6047
原文標題:傳感器數據的深度學習模型應用(一)—— Transformer 模型
文章出處:【微信號:MATLAB,微信公眾號:MATLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大語言模型背后的Transformer,與CNN和RNN有何不同

【大語言模型:原理與工程實踐】大語言模型的基礎技術
你了解在單GPU上就可以運行的Transformer模型嗎
如何使用Matlab/Simulink構建MIMXRT1170 EVK?
TensorFlow2.0中創建了一個Transformer模型包,可用于重新構建GPT-2、 BERT和XLNet

Microsoft使用NVIDIA Triton加速AI Transformer模型應用
基于Transformer的大型語言模型(LLM)的內部機制

transformer模型詳解:Transformer 模型的壓縮方法
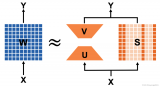
基于Transformer模型的壓縮方法






 工商網監
工商網監
評論