 利用Multi-Die設計的AI數據中心芯片對40G UCIe IP的需求
利用Multi-Die設計的AI數據中心芯片對40G UCIe IP的需求
越來越多的日常設備開始部署生成式人工智能,市場對大語言模型和出色算力的需求也隨之日益增長。Yole Group在2024年OCP區域峰會的演講過程中表示:“對于訓練參數達到1750億的GPT-3,我們估計需要6000到8000個A100 GPU歷時長達一個月才能完成訓練任務。”不斷提高的HPC和AI計算性能要求正在推動Multi-Die設計的部署,將多個異構或同構裸片集成到一個標準或高級封裝中。為了快速可靠地處理AI工作負載,Multi-Die設計中的Die-to-Die接口必須兼具穩健、低延遲和高帶寬特性,最后一點尤為關鍵。本文概述了利用Multi-Die設計的AI數據中心芯片對40G UCIe IP的需求。
高帶寬Die-to-Die接口用例
AI應用正在給半導體行業帶來新的挑戰。為支持深度學習和機器學習算法的海量數據處理任務,對更大帶寬的需求不斷增加,特別是對于計算和網絡應用。這些AI應用對于Die-to-Die接口提出了不同的要求。本文以100Tb網絡交換機和AI加速器為例。
圖1為100Tb交換機示例,該交換機可用于AI數據中心,采用橫向擴展方法來處理跨數據中心的海量數據。橫向擴展方法在機器協同工作的網絡中將工作負載分配到多臺服務器上。交換機SoC不斷擴展,正在接近尺寸極限,因此它被分割成更小的裸片,以提高邊緣使用率。在這種情況下,Die-to-Die接口通過高速以太網在裸片之間以及向外界傳輸大量數據,反之亦然。
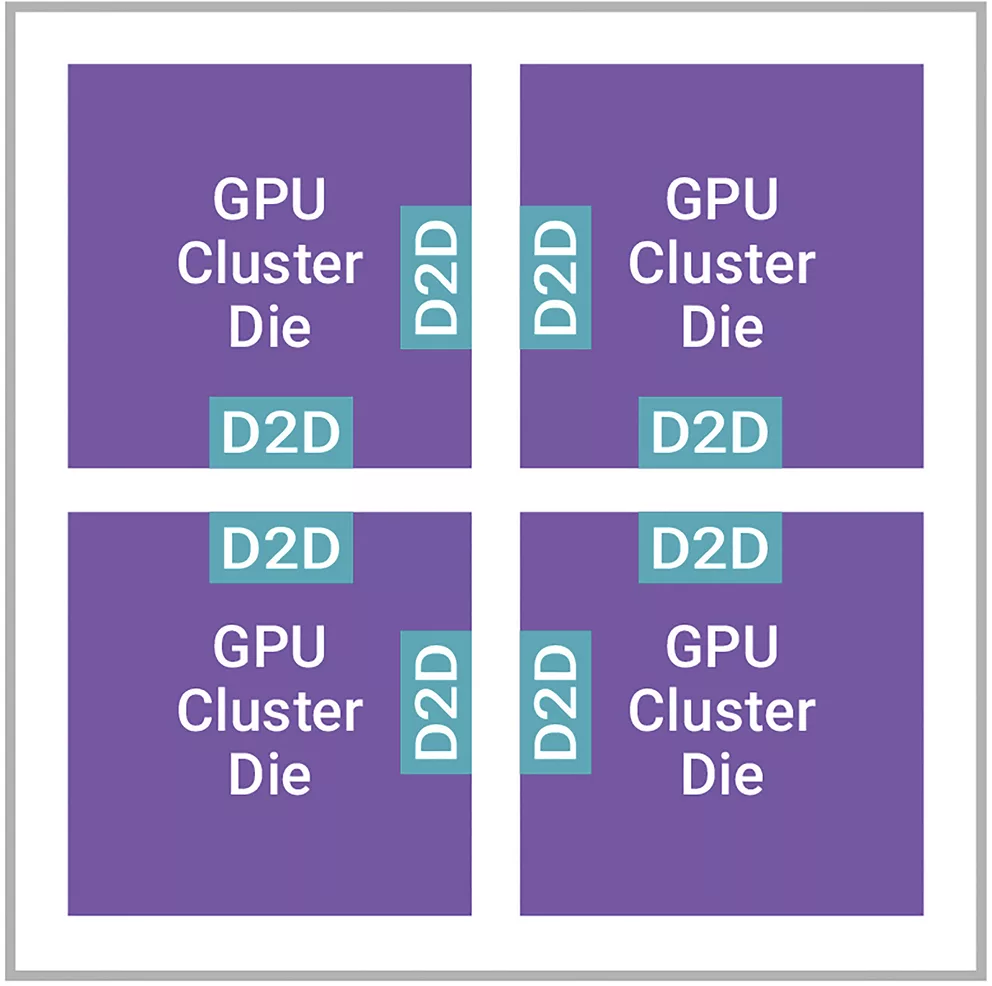
▲圖1 100Tb交換機的裸片分割用例片
類似Google張量處理單元這樣的AI加速器采用Multi-Die設計,為PCIe和以太網等接口配備單獨的計算裸片和IO裸片。此類AI處理器在更主流的技術工藝上使用IO裸片來節省成本,并在更先進的技術工藝上使用計算裸片來提高性能和能效,從而充分發揮Multi-Die設計的優勢。一些AI加速器使用圖3所示的裸片分割方法,需要高帶寬Die-to-Die接口來無縫傳輸裸片之間的數據。
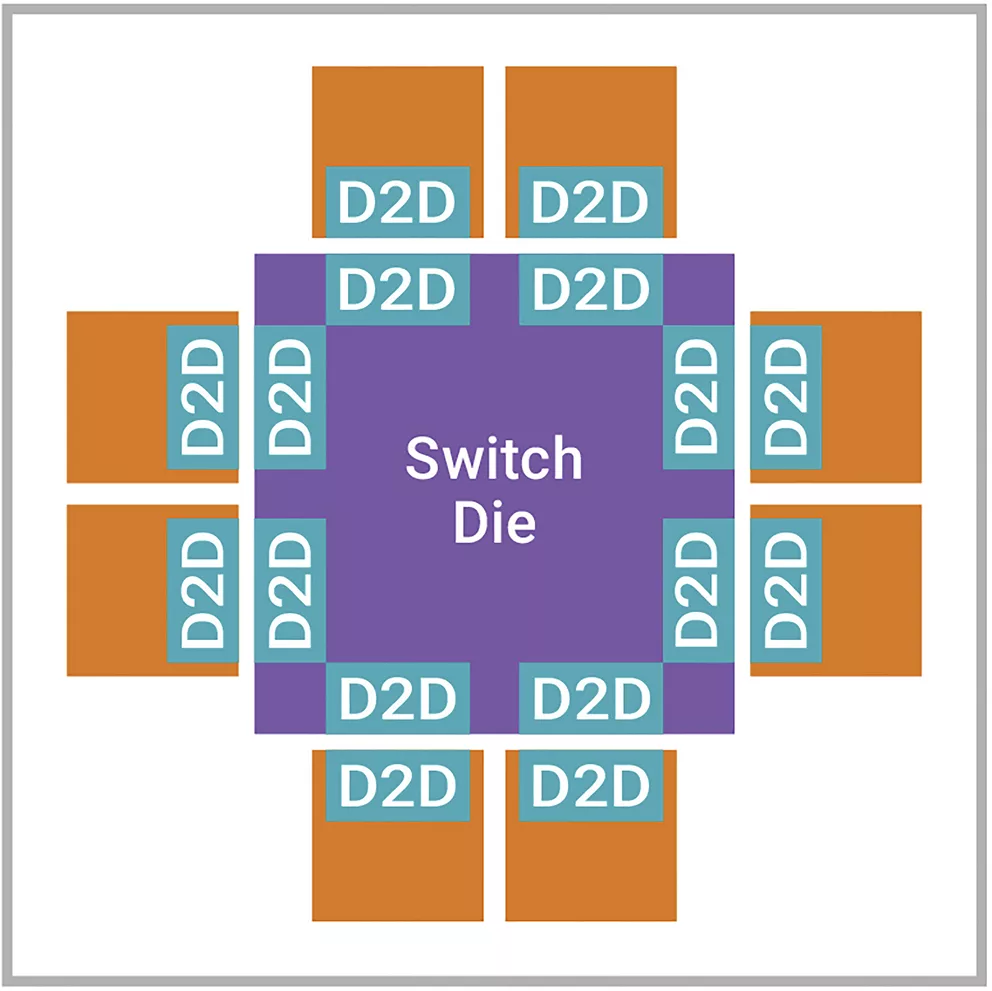
▲圖2 使用AI加速器的裸片分割用例
另一個示例是裸片連接用例,其中主服務器裸片或處理器連接到AI加速器裸片,以便執行可分流到特定功能加速器的任務。在這種用例中,Die-to-Die接口用于在需要時將數據從服務器裸片發送到加速器裸片,而無需在高帶寬下運行。此類用例使用標準封裝技術(如有機襯底),復雜性較低。許多邊緣AI和移動應用都使用此類用例。
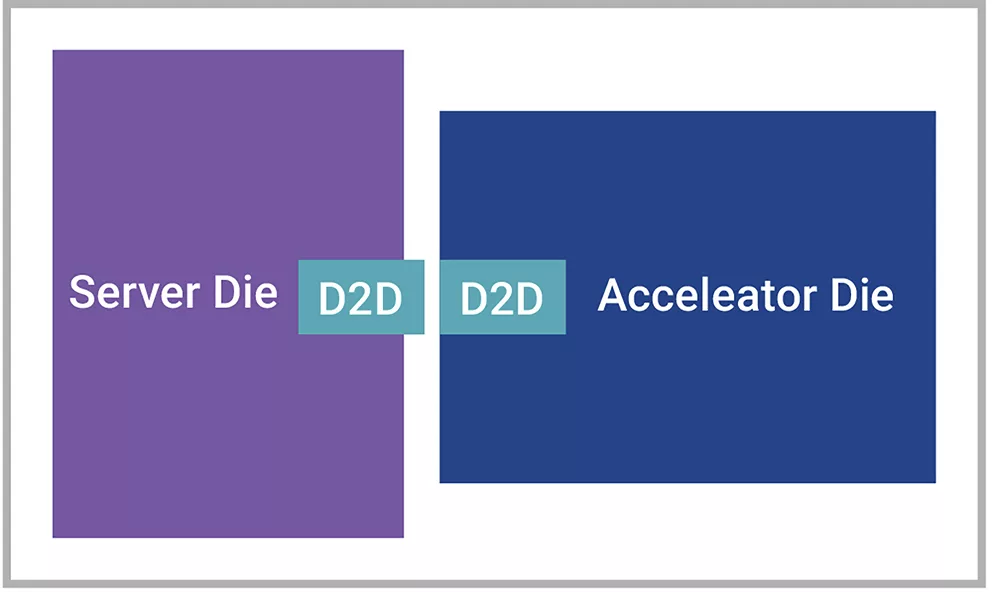
▲圖3 裸片連接用例
利用40G UCIe IP為Die-to-Die連接提供最大帶寬
UCIe規范已成為Die-to-Die連接的事實標準,確保裸片之間的互操作性、低延遲和實時數據傳輸。得益于UCIe,100Tb交換機和AI加速器等使用Multi-Die設計技術在標準封裝和高級封裝下實現了帶寬效率更高。作為通用芯粒互聯產業聯盟(UCIe Consortium)的成員,新思科技在其當前經驗證的UCIe IP基礎上,推出了40G UCIe IP解決方案,可提供比UCIe規范高25%的帶寬,而不會影響能效或面積。
40G UCIe PHY符合新的UCIe規范,實現了各種功能,可確保Die-to-Die鏈路可靠性和質量。PHY具有全面的可測性設計(DFT)功能,可用于已知良好裸片和生產測試,從而提高了可測試性。嵌入式信號完整性監視器(SIMs)可監測Die-to-Die鏈路的任務模式。監視器可以持續分析Die-to-Die信號質量,并在任務模式下執行校正措施,以實現可靠的通信。
PHY在2GHz頻率下支持高達128B的接口寬度,可以利用整個PHY的帶寬。對于必須以較低時鐘頻率運行的系統,它還在1GHz頻率下支持更寬的256B接口。40G UCIe控制器支持不同的接口選項,例如流式傳輸、CXS、AXI,以及PCIe、CXL、AXI和CHI C2C等協議,以在Die-to-Die鏈路上運行標準化數據。
雖然更高的數據速率有助于AI應用實現高帶寬效率并滿足數據處理要求,但也帶來了設計挑戰。開發者必須精心設計通道規格,避免更高的插入損耗和串擾,以實現更優性能。速度較低時,可能不需要對發射器(TX)進行均衡處理。但在速度較高時,為了達到所需的信道性能,就需要進行TX均衡,比如使用2抽頭前饋均衡(FFE)。此外還需要采用更強大的接收器(RX)均衡技術,例如1抽頭決策反饋均衡(DFE)及連續時間線性均衡(CTLE)。Die-to-Die通道需經過大量的信號完整性和電源完整性仿真,以驗證Die-to-Die鏈路特性和性能是否符合預期。
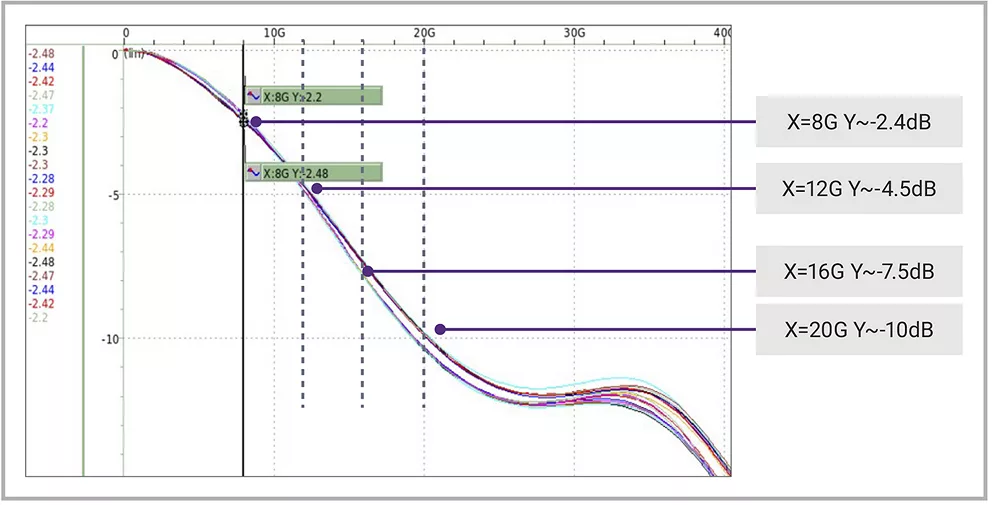
▲圖4 16G奈奎斯特頻率下的有損信道示例
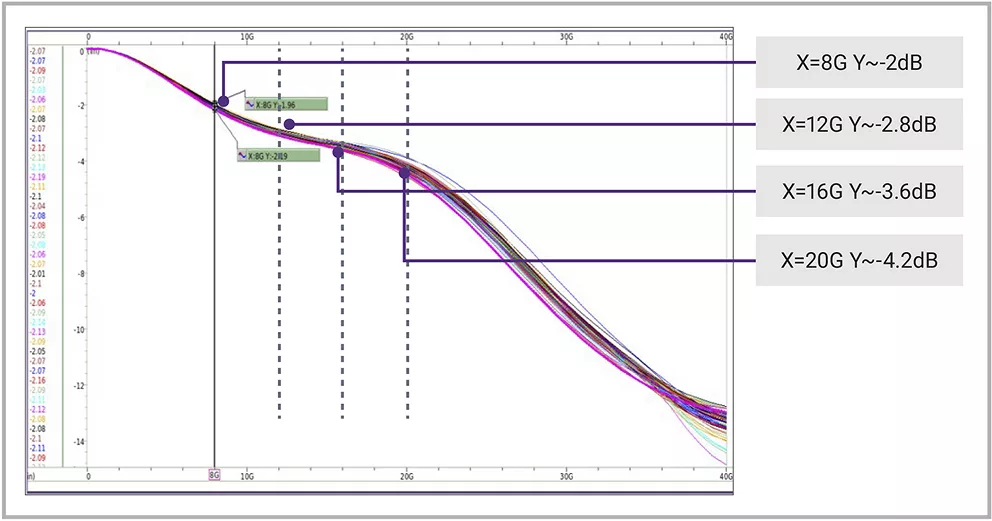
▲圖5 良好渠道設計示例
40G UCIe PHY支持新興的先進封裝技術,例如硅或RDL中介層、硅橋和RDL扇出,以及傳統的有機襯底封裝技術。PHY為先進封裝技術提供高達12 Tbps/mm的總帶寬效率,為標準封裝技術提供高達1.8 Tbps/mm的總帶寬效率,同時運行速度高達40Gbps/pin。有機襯底封裝技術雖然更為常見且比較實惠,但需要更多的布線層來支持IP實現更高速的布線。相反,先進封裝技術可以改善布線密度,但也增加了封裝設計所面臨的挑戰。了解到這種復雜性,新思科技提供了用于中介層設計的3DIC Compiler平臺及UCIe-A IP參考設計。3DIC Compiler是統一的探索到簽核解決方案,其中包含用于自動布線和自定義中介層設計的工具和腳本。
40G UCIe IP實現了前向時鐘架構,以簡化接收器架構,從而降低功耗和延遲。其中使用了四倍速率架構,對于32 Gbps/pin速度,PHY操作頻率限制為8 GHz;對于40 Gbps/pin速度,PHY操作頻率限制為10 GHz。此外還借助嵌入式低延遲FIFO來補償前向時鐘和本地時鐘之間以及不同通道之間的偏差不匹配。通用的100MHz參考時鐘用作PHY鎖相環(PLL)的輸入,可生成PHY和控制器所需的所有高頻時鐘,這樣邏輯電路就無需向PHY提供高頻時鐘。圖6為40G UCIe PHY架構。
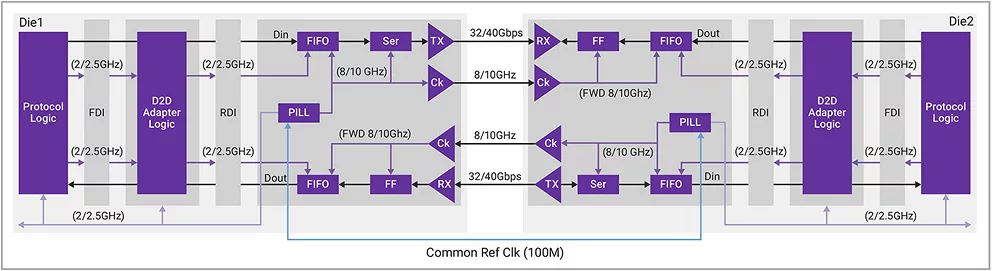
▲圖6 UCIe PHY架構
UCIe未來的發展道路
3D封裝具有功耗和性能優勢,正逐漸成為快速Multi-Die設計的優選解決方案。
UCIe規范2.0正在促使3D封裝中的Die-to-Die連接實現標準化,與2D和2.5D技術相比,其帶寬更高且功耗更低。UCIe規范為3D封裝定義了以下特性:
適合凸塊區域的電路和邏輯,這有助于實現較低的工作頻率和更簡單的電路
較小的凸塊間距,例如幾微米
預定義的Bump-PHY的Bump圖,可簡化互操作性
新思科技利用3DIO IP解決方案實現了3D封裝中的Die-to-Die連接。
3D封裝技術正蓬勃發展,未來幾年對更高數據速率的需求可能會越來越大。Die-to-Die接口也將持續演進,以支持更高的速度和能效。
業界首款40G UCIe IP解決方案,包括控制器、PHY和驗證IP,提供更高算力,可滿足速度更高的基于UCIe的Multi-Die設計需求。PHY的簡化架構簡化了IP集成,全面的監控、測試和修復功能則改善了可靠性和芯片的健康狀況。新思科技走在技術發展的前沿,并將繼續部署先進的IP來適應千變萬化的市場需求。
-
數據中心
+關注
關注
16文章
4857瀏覽量
72377 -
新思科技
+關注
關注
5文章
807瀏覽量
50424 -
AI芯片
+關注
關注
17文章
1903瀏覽量
35213 -
UCIe
+關注
關注
0文章
48瀏覽量
1650
原文標題:當 AI 芯片遇上帶寬瓶頸,看40G UCIe IP 如何打破僵局?
文章出處:【微信號:Synopsys_CN,微信公眾號:新思科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Maxim 40G傳輸解決方案有效降低功耗、提高數據吞吐率
40G光模塊選購指南
40G數據中心之銅纜布線
2023是否會成為Multi-Die的騰飛之年?
芯片革命:Multi-Die系統引領電子設計進階之路
態路小課堂丨為40G數據中心綜合布線產品選擇方案!






 工商網監
工商網監
評論