 Flexus X 實例 ultralytics 模型 yolov10 深度學習 AI 部署與應用
Flexus X 實例 ultralytics 模型 yolov10 深度學習 AI 部署與應用
前言:
???深度學習新紀元,828 B2B 企業節 Flexus X 實例特惠!想要高效訓練 YOLOv10 模型,實現精準圖像識別?Flexus X 以卓越算力,助您輕松駕馭大規模數據集,加速模型迭代,讓 AI 智能觸手可及。把握此刻,讓創新不再受限!
???本實驗演示從 0 到 1 部署 YOLOv10 深度學習 AI 大模型的環境搭建、模型訓練、權重使用,以及各項指標解讀。實驗環境為 Flexus 云服務器 X 實例 服務器,配置:4vCPUs | 12GiB
環境準備
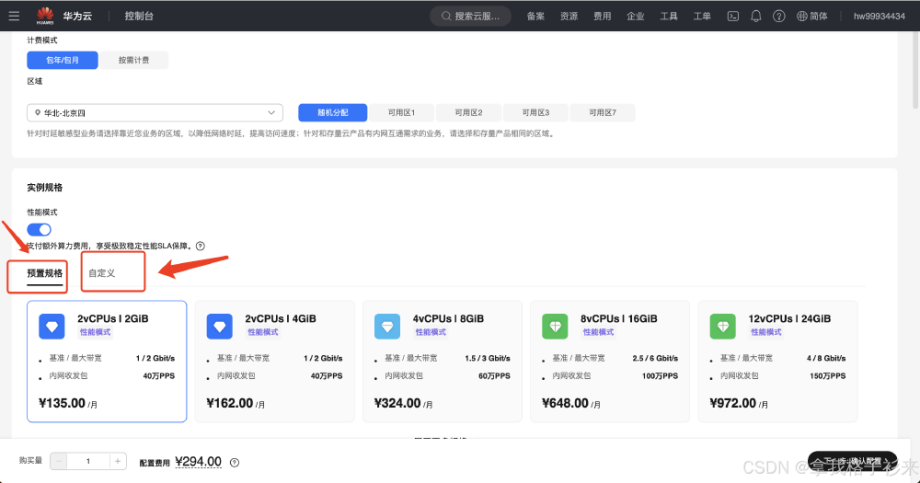
購買服務器配置
本次實驗使用的是 Flexus 云服務器 X 實例 服務器。

在性能設置中我選擇了自定義模式,使用了 4vCPUs | 12GiB,因為本次要實驗的是 yolov10 的部署與應用,Windows 操作系統具有更加直觀的用戶界面和強大的圖形支持,我選擇了公共鏡像 Windows Server 2022 數據中心版。以上配置僅供參考,并非硬性要求!
連接服務器
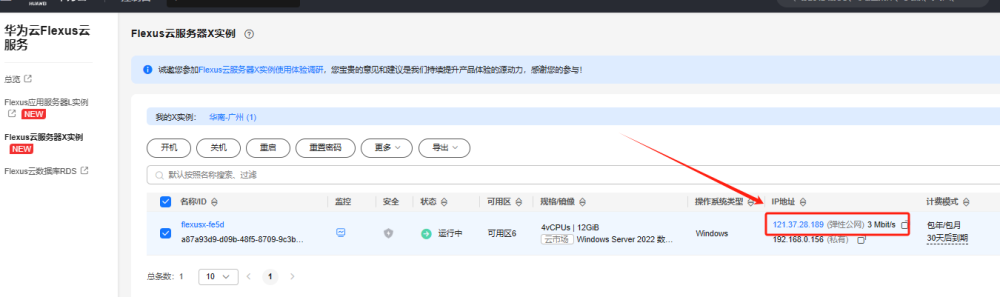
在華為云服務器控制臺中找到我們剛剛購買的服務器,將彈性公網 IP 地址復制下來。
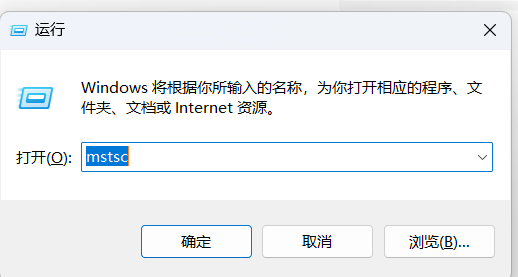
快捷鍵 Windows + R 打開運行窗口,輸入 mstsc,回車!
輸入計算機:彈性公網 IP 地址;用戶名:MicrosoftAccountAdministrator,單擊“確定”。
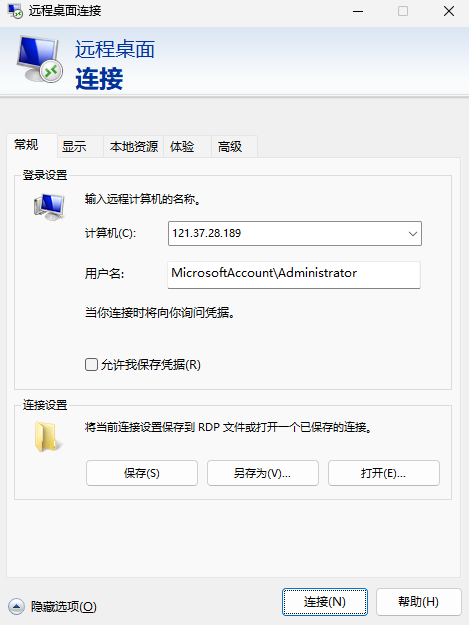
然后輸入密碼,就成功的連接到我們的服務器了。
如果忘記密碼了,可以在操作列中點擊重置密碼,重新設置我們的服務器密碼。
安裝 Python
我們先來安裝 python3,打開官網地址
Download Python | Python.org
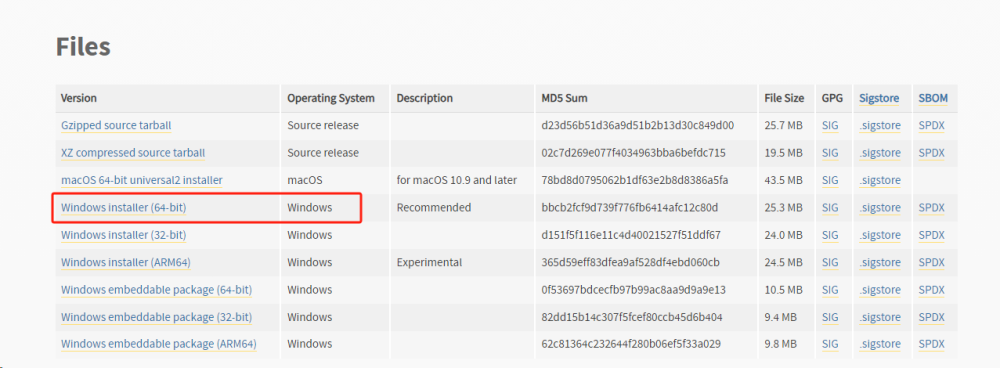
在官網下一個大于大于 3.8 的 python 安裝包(官方建議使用 3.9 的版本),選擇 amd64 的 exe 版本
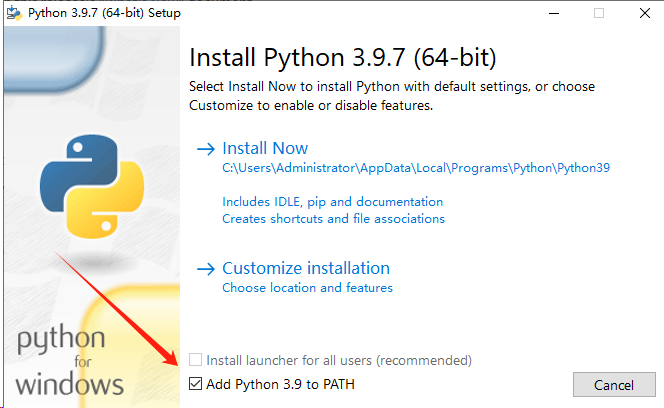
安裝的時候勾選最底下的幫我們添加環境變量
等待片刻,出現下面這個界面就是安裝成功了。
CMD 打開控制臺小黑窗,執行 python -V 和 pip -V 查看 python 版本與 pip 版本,看看我們的環境變量是否設置成功。

安裝 Pytorch
到官網安裝 Pytorch
Start Locally | PyTorch
在安裝之前看看自己買的服務器是否有 GPU,可以使用命令來查看
查看 CPU 型號:cat /proc/cpuinfo | grep "model name"
查看 GPU 型號(Nvidia GPU):nvidia-smi --query-gpu=gpu_name --format=csv
查看 GPU 型號(AMD Radeon GPU):sudo lshw -C display
因為我這臺是只有 CPU 的,因此在官網中選擇 Stable(穩定版),系統 Linux,用 pip 來安裝吧,然后 Compute Platform 選擇 CPU,然后把 Run this Command:中的命令???cmd 打開黑窗口執行。
我這里執行的是
pip3 install torch torchvision torchaudio 直接執行可能會很慢,我在后面加上指定鏡像源,切換為國內鏡像 pip3 install torch torchvision torchaudio -i https://pypi.mirrors.ustc.edu.cn/simple/
出現如下畫面即是成功下載完成。
部署 YOLOv10
YOLOv10 是 YOLO(You Only Look Once)系列的最新版本,由清華大學的研究人員開發,旨在進一步提高實時目標檢測的效率和準確性。以下是對 YOLOv10 的詳細介紹:
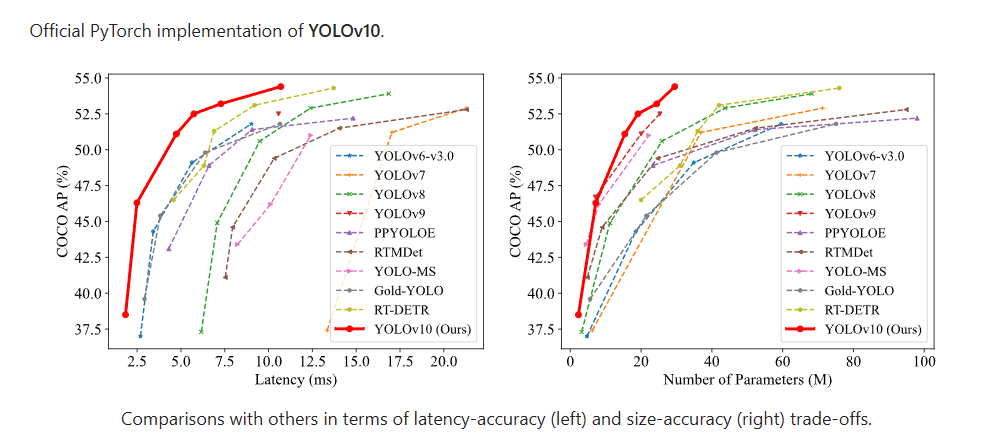
之前的 YOLO 版本在后處理和模型架構方面仍存在不足,特別是依賴于非最大抑制(NMS)進行后處理,這限制了模型的端到端部署并增加了推理延遲。YOLOv10 通過消除 NMS 和優化模型組件,旨在解決這些問題,實現更高的性能和效率。
拉取 YOLOv10 代碼并安裝相關依賴
打開 YOLOV0 的 GItHub 代碼庫,將源碼下載到本地,解壓。
GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
解壓完成后,打開命令行窗口,cd 到源碼的工作目錄,執行下面兩個命令。


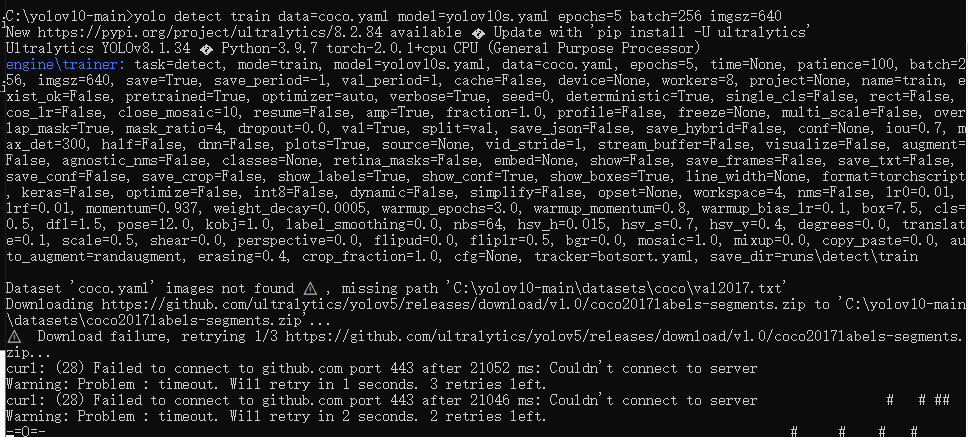
當以上相關依賴都安裝完畢后,執行以下訓練命令測試我們的環境(此步驟可跳過)。
yolo detect train data=coco.yaml model=yolov10s.yaml epochs=5 batch=256 imgsz=640
第一次執行會自動下載官方提供的訓練案例文件,需要等待較長時間。
數據集準備
YOLOv10 作為實時目標檢測模型,理論上支持多種類型的數據集,只要這些數據集符合 YOLOv10 的輸入格式和標注要求。具體來說,YOLOv10 可以支持的數據集包括但不限于以下幾種類型:
1.通用目標檢測數據集:如 COCO(Common Objects in Context)數據集,這是一個大型、豐富的圖像數據集,用于目標檢測、分割、關鍵點檢測等多種任務。YOLOv10 在 COCO 數據集上取得了顯著的性能提升,展現出優異的精度-效率平衡能力。
2.特定領域數據集:YOLOv10 也可以應用于特定領域的數據集,如交通標志檢測數據集、人臉檢測數據集、車輛檢測數據集等。這些數據集通常針對特定場景或任務進行收集和標注,以滿足特定領域的需求。
3.自定義數據集:用戶還可以根據自己的需求創建自定義數據集,并使用 YOLOv10 進行訓練和測試。自定義數據集需要按照 YOLOv10 的輸入格式進行標注和組織,包括圖像文件、標簽文件以及可能的數據集配置文件等。
通常來說,我們需要將標注結果與原圖按比例分配到三個文件夾中
如你有 100 張標注了的圖片,大約 80 張圖片用于訓練數據,約 10 張圖片用于驗證數據,約 10 張圖片用于測試數據
train 路徑用于訓練模型,val 路徑用于驗證模型,test 路徑用于測試模型。在訓練和驗證期間,模型將在不同的數據集上進行訓練和驗證,以便評估模型的性能。在測試期間,模型將使用整個數據集進行測試,以確定其性能指標
需要注意的是:訓練過的圖片通常不能用于驗證數據。這是因為在訓練期間,模型已經對這些圖片進行了訓練,并學會了識別這些圖片中的對象和場景類別。
因為數據標注要花費大量的時間,這里直接拿出我最愛的皮卡丘標注數據
400多張“皮卡丘”原圖與標注結果以及yolov8的訓練結果best.pt權重和ONNX格式文件_yolov8權重轉onnx資源-CSDN文庫
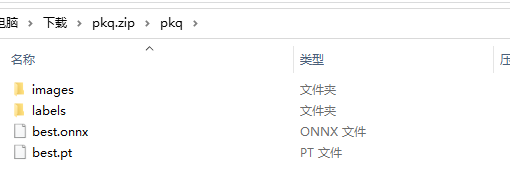
在這個壓縮包中有皮卡丘圖片與標注信息,還有 yolov8 的訓練好的權重文件,我們只留下 images 和 labels 用來訓練 yolov10 版本的權重。
因為我比較懶,能用代碼解決的事就用代碼,下面我們使用 python 對數據集進行隨機分配。
修改下面代碼中 66-67 行中的
src_data_folder = '數據集路徑' target_data_folder = '處理后的數據集'




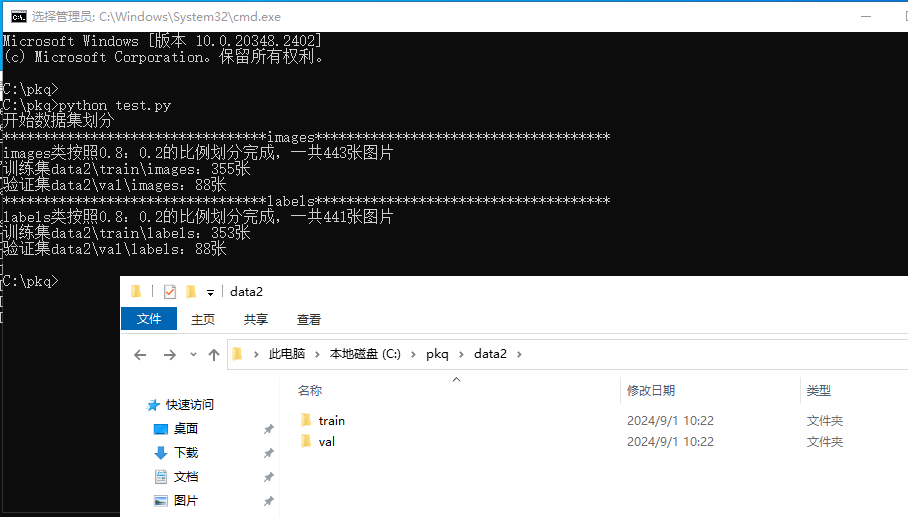
因為在 yolo 訓練中,我們并不需要將圖片和標注結果分開存放,因此我們將 train 和 val 中的 images 和 labels 里的文件都全部移出來,然后將這兩個文件夾刪掉即可。
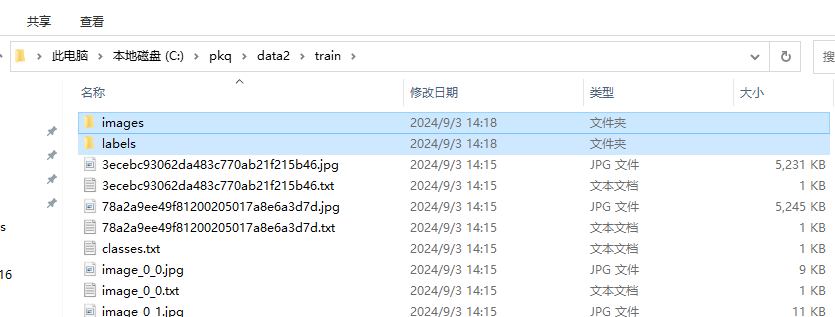
要注意的是,不管是 train 還是 val 都需要檢查是否包含這么一個 classes.txt 文件,如果沒有的話需要自己手動補上,因為我這里的素材只有一個皮卡丘目標,并且標注為 1 了,所以只寫了一個 1。
訓練數據集的配置文件
參考路徑 C:yolov10-mainultralyticscfgdatasets 找到 voc.yaml,復制一份,自定義一個名字
執行完識別命令后,可在輸出信息中看到識別結果文件所在位置,detectpredict(數字會自動疊加)
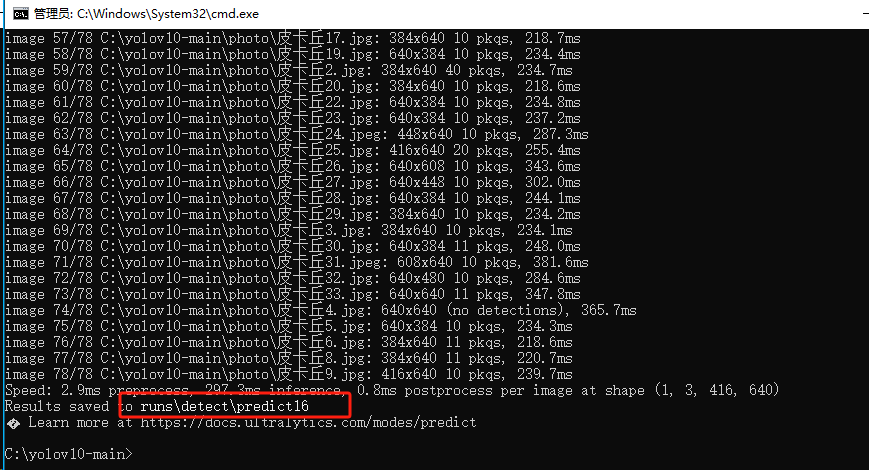
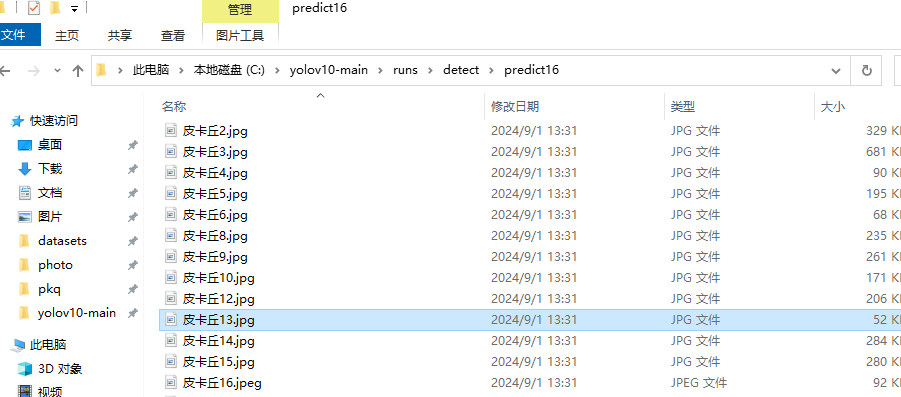
任意打開一張圖片,找出識別前的圖片對比一下,皮卡丘已經被框出來了,并打上我們設置的 pkq 標簽。
至此~我們就完成了 YOLOv10 目標檢測模型的訓練與識別工作了!整個實驗操作下來,Flexus 云服務器 X 實例的表現都是非常出色的!
審核編輯 黃宇
-
AI
+關注
關注
87文章
31536瀏覽量
270346 -
深度學習
+關注
關注
73文章
5516瀏覽量
121554 -
華為云
+關注
關注
3文章
2691瀏覽量
17588
發布評論請先 登錄
相關推薦
云服務器 Flexus X 實例:one-api 部署,支持眾多大模型

Flexus 云服務器 X 實例實踐:部署思源筆記工具
【ELF 2學習板試用】ELF2開發板(飛凌嵌入式)搭建深度學習環境部署(RKNN環境部署)
使用 sysbench 對 Flexus X 實例對 mysql 進行性能測評
Flexus 云服務器 X 實例實踐:部署 Alist 文件列表程序
云服務器 Flexus X 實例:RAG 開源項目 FastGPT 部署,玩轉大模型

華為云 Flexus 云服務器 X 實例之 openEuler 系統下部署 Joplin 筆記工具
華為云 Flexus X 實例部署安裝 Jupyter Notebook,學習 AI,機器學習算法
采用華為云 Flexus 云服務器 X 實例部署 YOLOv3 算法完成目標檢測

基于 Flexus 云服務器 X 實例體驗大模型部署體驗測評

YOLOv10自定義目標檢測之理論+實踐
YOLOv10:引領無NMS實時目標檢測的新紀元

用OpenVINO C# API在intel平臺部署YOLOv10目標檢測模型

在Windows上使用OpenVINO? C# API部署Yolov8-obb實現任意方向的目標檢測






 工商網監
工商網監
評論