 如何使用內存加速存儲訪問速度
如何使用內存加速存儲訪問速度
本篇文章是首爾大學發表在FAST 2023上的文章。隨著閃存容量的增加,邏輯地址到物理地址的映射表項也相應增加。映射表項通常存放在設備控制器中的SRAM來加速訪問。然而由于成本問題SRAM一直無法增長,這使得其中只能存放很少量的數據表項。而為了解決這一問題,現有工作使用部分主機端內存(high performance booster, HPB)來緩存映射表項。然而文章中發現,現有的HPB管理策略并不能夠很好的提升用戶體驗。這是因為現有的管理策略通常可能會將前臺應用的表項剔除。而為了解決這一問題,本文設計提出HPBvalve技術來盡量緩存前臺應用的映射表項。通過在搭建的真實平臺上的驗證,該技術能夠很好的提升用戶體驗。
背景
當主機下發請求時會附上邏輯地址,UFS收到請求后會在閃存轉換層(FTL)進行地址轉換,將邏輯地址轉換為物理地址,如圖1所示。記錄從邏輯地址到物理地址映射信息的稱之為映射表項。而為了加速這一過程,UFS中通常配備一個較小的SRAM用于緩存常用的映射表項。然而隨著閃存的迅速發展,SRAM空間越發不夠存儲經常訪問的表項。例如對于1TB的UFS設備配備512KB SRAM,則只有0.0005%的表項能夠緩存在其中。顯然這遠遠不夠。而為了緩解這一問題,現有工作提出使用部分主機內存(HPB)來緩存映射表項。相較于SRAM來說,主機能夠提供較大的內存,從而緩存更多的映射表項來加速訪問。
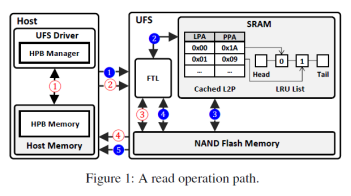
動機
為了展示映射表項對用戶體驗的影響,文章中在搭建的平臺上做了很多實驗。平臺將在實驗部分介紹。其中設備容量為1TB,設備SRAM為512KB,HPB大小為256MB。OPTIMAL為所有映射表項都命中在設備SRAM的情況。應用啟動時間和加載時間作為衡量用戶體驗的指標。
圖2展示了映射表項訪問確實對用戶感知延遲的影響。從中我們可以得出三個結論:
通過對比OPTIMAL和其他兩個可以看出,啟動延遲和加載延遲都得到了較為明顯的提升。從絕對值來看,分別是220ms和183ms,已經是用戶可感知的延遲。
通過比較UFS和UFS+HPB可以發現,盡管HPB能夠提供較大的容量,然而現有的管理策略并不能夠利用其很好的提升用戶體驗。
HPB從主機端借用了較多的內存反而會使得主機內存壓力增加。
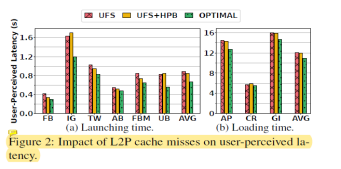
圖3中進一步分析了HPB中前臺應用和后臺應用中映射表項的命中情況。從圖中我們可以看出前臺應用的映射表項缺失情況比后臺應用更加嚴重,這是因為:1)傳統HPB采用基于計數的取映射表項策略。而后臺應用比前臺應用會下發更多的讀請求,這使得后臺應用的映射表項的讀取計數通常比前臺應用的高。因此會更傾向于將后臺應用的映射表項取到HPB中。2)傳統HPB采用基于時間的映射表項剔除策略。然而當用戶切換應用并使用一段時間后,剛才使用應用的映射表項也將會被剔除。這導致用戶再切換回來后映射表項缺失,影響用戶體驗。
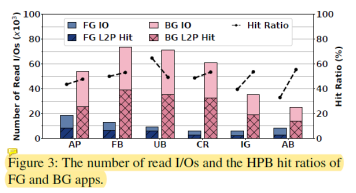
圖4和圖5分析了HPB無法很好預測哪些表項會被使用的原因。這是因為在應用啟動的時候,會有大量隨機的I/O請求,并且覆蓋很大的邏輯地址空間。這使得很難提高表項命中率。
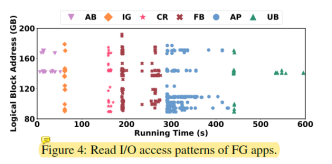
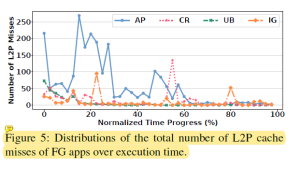
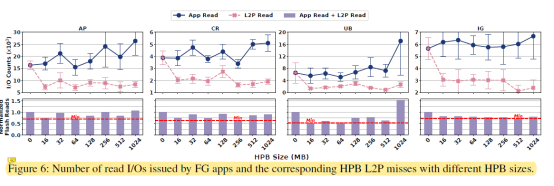
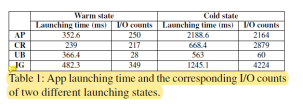
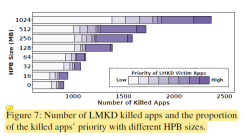
圖6探索了HPB大小對用戶體驗的影響。從中我們可以發現最佳的HPB大小隨著應用不同而不同。同時隨著HPB的大小增加,前臺應用下發的讀取請求也在增加。這是因為HPB分配過多內存導致內存壓力過大,會殺掉一些應用。當這些應用(cold state)之后再被訪問的時候不僅啟動時間增加,而且需要下發更多的讀取請求,如表1所示。圖7展示的是隨著HPB大小的增加,越來越多的應用會被殺掉。
設計
為了解決上述問題,文章中提出了HPBvalve(Hvalve),如圖8所示。Hvalve包含了五個部分。其中app-detector和mem-detector分別用于判斷應用是否為前臺應用、應用狀態變化和內存壓力情況。FG profiler維護了近期使用應用會訪問的映射表項,用于預取映射表項。L2P manager用于單獨管理前臺應用的映射表項。HPB regulator用于根據內存壓力情況調整HPB大小,避免過多應用被殺掉。
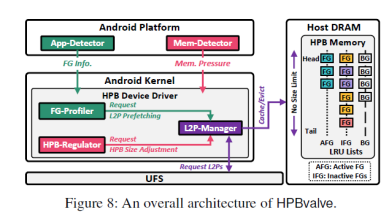
1. 前臺/后臺應用識別:Hvalve在bio結構體中創建新的變量UID,用于記錄下發請求所屬的應用。當bio創建請求的時候,UID也會集成在請求中。同時app detector會通過安卓活動任務管理器(android activity task manager)來檢測是否有新的前臺應用啟動。如果有一個新的前臺應用啟動時,將該應用的UID傳遞給HPB。這樣HPB可以將該UID與請求中攜帶的UID進行比較,從而判斷應用是否為前臺應用。
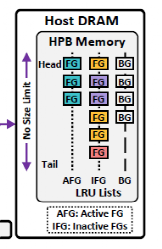
2. L2P management:Hvalve維護了三個LRU鏈表,分別用戶記錄活躍前臺應用、非活躍前臺應用和后臺應用的映射表項。當新的前臺應用啟動時,會將之前的前臺應用表項降級到非活躍前臺應用鏈表中。當需要剔除表項的時候優先提出后臺應用表項,然后是非活躍前臺應用表項。而前臺應用表項不會被剔除。
3. Hvalve緩存策略:1)其中依舊延續傳統的基于訪問計數的方式來緩存經常被訪問的表項。2)對于前臺應用緩存表項未命中時,立即將該表項取到HPB中。3)根據FG profiler預取表項。
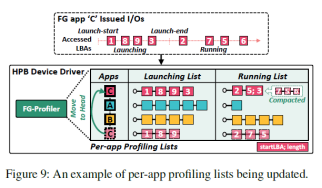
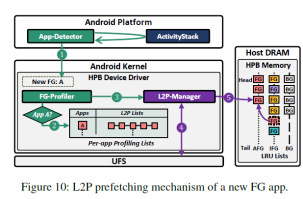
4. 前臺應用分析和預取:圖9展示了FG-profiler中記錄的信息。FG-profiler記錄近期訪問應用的映射表項。同時根據app detector基于安卓活躍任務管理器發出的應用啟動開始和啟動結束信號,可以將映射表項分為啟動表項和運行表項。當一個應用被切換為前臺應用的時候,hvalve會先判斷該應用對應的映射表項是否記錄在FG-profiler中。如果在,則將記錄的映射表項預取到HPB中,以加速訪問,如圖10所示。
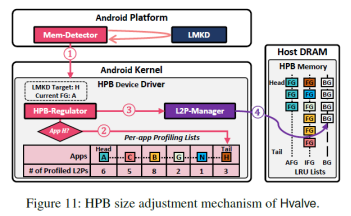
5. HPB大小動態調整:mem-detector時刻監測LMKD。當內存不足激活LMKD殺進程時,mem-detector會將將要殺掉的進程UID傳送給HPB-regulator。HPB-regulator會判斷該應用在FG-profiler中是否有記錄,如果沒有說明不是近期訪問過的應用,則直接殺掉。如果有,則會根據LMKD需要釋放內存的大小剔除HPB中的表項。優先提出后臺應用表項,然后是非活躍應用表項。如果剔除之后內存仍然不足,則需要重新喚醒LMKD選取應用殺掉。該過程如圖11所示。
實驗
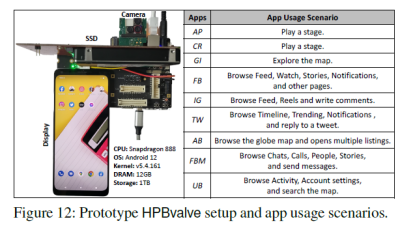
該文章為了探尋HPB不同方面的影響,自己搭建了一個平臺,如圖12所示。其中使用高性能SSD作為主要存儲,同時簡單實現了HPB的管理策略,來進行映射表項的存取。應用場景也如圖12所示。
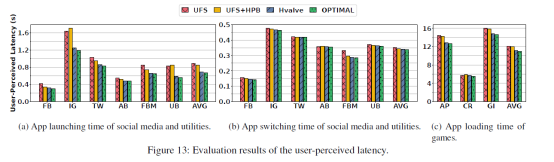
性能:性能提升如圖13所示。Hvalve相較于UFS和UFS+HPB均有所改善,并且接近OPTIMAL的場景。
表項未命中模式:圖14展示了前臺應用表項缺失隨著運行時間的分布。可以看出Hvalve很好的控制住了在應用剛運行時候的缺失率高的問題。

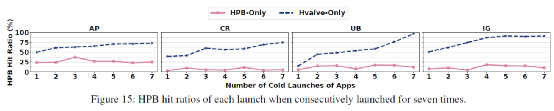
命中率:圖15展示了Hvalve的命中率情況。相較于HPB-only,Hvalve很好的提升了應用冷啟動時的映射表項命中率。
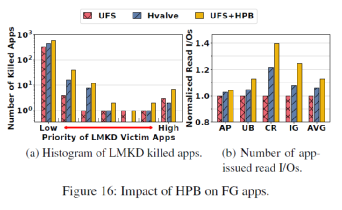
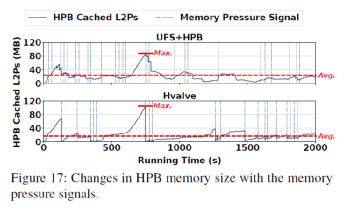
HPB大小動態調整效果:圖16展示了Hvalve動態調整對前臺應用的影響。可以看出Hvalve相較于傳統的HPB管理策略減少了被殺掉的應用,同時很好的保護了高優先級的應用,減少了應用下發的讀請求數量。圖17可以觀察到HPB大小動態調整的過程。
總結
為了提高HPB的使用效率從而提升用戶體驗,本文在自己搭建的平臺上深入的分析了當前HPB管理策略存在的問題,并在此基礎上設計了Hvalve。Hvalve通過對前臺應用映射表項的識別和管理,提高了前臺應用的訪問速度,提升用戶體驗。同時根據內存壓力動態調整HPB大小,避免導致內存壓力過大而殺掉過多的應用,影響用戶體驗。實驗結果顯示,Hvalve提升了用戶前臺應用表項的命中率,減少了被殺掉的應用,提升了用戶體驗。
-
存儲
+關注
關注
13文章
4353瀏覽量
86162 -
sram
+關注
關注
6文章
768瀏覽量
114880 -
內存
+關注
關注
8文章
3052瀏覽量
74323
原文標題:手機訪問卡頓,看如何使用內存加速存儲訪問速度!
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
拋棄8GB內存,端側AI大模型加速內存升級

內存擴展CXL加速發展,繁榮AI存儲

高速緩沖存儲器是內存還是外存,高速緩沖存儲器是為了解決什么
內存儲器的特點是速度快成本低容量小對嗎
內存儲器由什么組成
內存儲器主要用來存儲什么
內存儲器分為隨機存儲器和什么
恒訊科技分析:香港服務器網站訪問速度如何才能達到最快?
Jtti:新加坡云服務器運行內存和存儲內存有何區別?
集成32GB HBM2e內存,AMD Alveo V80加速卡助力傳感器處理、存儲壓縮等

CW32L052 DMA直接內存訪問






 工商網監
工商網監
評論