") 醫(yī)院SQL數(shù)據(jù)庫(kù)系統(tǒng)語(yǔ)句優(yōu)化
醫(yī)院SQL數(shù)據(jù)庫(kù)系統(tǒng)語(yǔ)句優(yōu)化
本文就如何優(yōu)化大型數(shù)據(jù)庫(kù)的性能進(jìn)行了一些探索,提出了優(yōu)化數(shù)據(jù)庫(kù)訪(fǎng)問(wèn)性能的若干策略,特別是對(duì)SQL語(yǔ)句進(jìn)行了有效的分析設(shè)計(jì)的問(wèn)題,以使其加快執(zhí)行速度,減少網(wǎng)絡(luò)傳輸,能更高效地工作,充分發(fā)揮系統(tǒng)的效率。
隨著醫(yī)院信息系統(tǒng)模塊的不斷增加,特別是近兩年電子病歷的使用,臨床診療信息大量寫(xiě)入數(shù)據(jù)庫(kù),數(shù)據(jù)量急劇增加,造成業(yè)務(wù)數(shù)據(jù)庫(kù)非常龐大,業(yè)務(wù)處理的速度明顯下降。基于這一問(wèn)題,本文就如何優(yōu)化大型數(shù)據(jù)庫(kù)的性能進(jìn)行了一些探索,提出了優(yōu)化數(shù)據(jù)庫(kù)訪(fǎng)問(wèn)性能的若干策略,特別是對(duì)SQL語(yǔ)句進(jìn)行了有效的分析設(shè)計(jì)的問(wèn)題,以使其加快執(zhí)行速度,減少網(wǎng)絡(luò)傳輸,能更高效地工作,充分發(fā)揮系統(tǒng)的效率。
醫(yī)院經(jīng)過(guò)多年的信息化建設(shè),取得了顯著成效,信息化由原來(lái)的以收費(fèi)、記帳為主,逐步向臨床醫(yī)療、服務(wù)病人過(guò)渡。隨著醫(yī)院信息系統(tǒng)模塊的不斷增加,特別是近兩年電子病歷的使用,臨床診療信息大量寫(xiě)入數(shù)據(jù)庫(kù),數(shù)據(jù)量急劇增加,造成業(yè)務(wù)數(shù)據(jù)庫(kù)非常龐大,業(yè)務(wù)處理的速度明顯下降。加之在頻繁的業(yè)務(wù)數(shù)據(jù)庫(kù)中還要進(jìn)行大數(shù)據(jù)量查詢(xún)或報(bào)表統(tǒng)計(jì),導(dǎo)致在業(yè)務(wù)處理時(shí)經(jīng)常出現(xiàn)阻塞或死鎖現(xiàn)象,嚴(yán)重影響到日常的工作。故如何對(duì)數(shù)據(jù)庫(kù)性能在進(jìn)行優(yōu)化設(shè)計(jì),即提高數(shù)據(jù)庫(kù)的吞吐量、減少用戶(hù)等待時(shí)間具有重大意義。
傳統(tǒng)的數(shù)據(jù)庫(kù)性能優(yōu)化主要從操作系統(tǒng)、客戶(hù)端應(yīng)用軟件程序設(shè)計(jì)、網(wǎng)絡(luò)及其它硬件設(shè)備等方面來(lái)考慮,這種方法只是調(diào)整數(shù)據(jù)庫(kù)的周邊環(huán)境,只能暫時(shí)緩解問(wèn)題,而不能從根本上解決問(wèn)題。實(shí)際應(yīng)用中,更多情況是醫(yī)院信息系統(tǒng)(包括數(shù)據(jù)庫(kù)系統(tǒng))都已設(shè)計(jì)好,只是在運(yùn)行的過(guò)程中隨著數(shù)據(jù)規(guī)模的增大,使得系統(tǒng)出現(xiàn)周期性性能問(wèn)題。本文提出的醫(yī)院數(shù)據(jù)庫(kù)系統(tǒng)性能優(yōu)化是在己有的硬件設(shè)施升級(jí)、數(shù)據(jù)庫(kù)的物理設(shè)計(jì)、關(guān)系規(guī)范化等方面進(jìn)行改進(jìn)基礎(chǔ)之上,對(duì)SQL語(yǔ)句進(jìn)行了有效的分析設(shè)計(jì)的問(wèn)題,以使其加快執(zhí)行速度,減少網(wǎng)絡(luò)傳輸,能更高效地工作,充分發(fā)揮系統(tǒng)的效率。
1 合理使用索引
提高數(shù)據(jù)庫(kù)查詢(xún)速度最有效的方法就是優(yōu)化索引。索引是建立在實(shí)體表上的一種數(shù)據(jù)組織,它可以提高訪(fǎng)問(wèn)表中一條或多條記錄的查詢(xún)效率,使用索引的目的是為了避免全表掃描,減少磁盤(pán)I/O的次數(shù),加快查詢(xún)速度,在大型的表中進(jìn)行索引的建立對(duì)加快表的查詢(xún)有著重要的意義。但是也并不對(duì)任何的數(shù)據(jù)表都要建立索引,索引通常能提高select、update以及delete語(yǔ)句的性能(當(dāng)訪(fǎng)問(wèn)的行較少時(shí)),但會(huì)降低insert語(yǔ)句的性能(因?yàn)樾枰瑫r(shí)對(duì)表和索引進(jìn)行插入)。此外,過(guò)多的索引會(huì)產(chǎn)生維護(hù)上的開(kāi)銷(xiāo),只會(huì)降低而不是增加系統(tǒng)的性能,索引的使用要恰到好處。索引使用原則如下:
(1)在經(jīng)常進(jìn)行連接,但是沒(méi)有指定為外鍵的列上建立索引,而不經(jīng)常連接的字段則由優(yōu)化器自動(dòng)生成索引。
(2)在頻繁進(jìn)行排序或分組(即進(jìn)行g(shù)roup by或order by操作)的列上建立索引,而頻繁進(jìn)行刪除、插入操作的表不要建立過(guò)多的索引。
(3)在條件表達(dá)式中經(jīng)常用到的不同值較多的列上建立檢索,在不同值少的列上不要建立索引。比如在雇員表的“性別”列上只有“男”與“女”兩個(gè)不同值,因此就沒(méi)有必要建立索引,如果在此建立索引不但不會(huì)提高查詢(xún)效率,反而會(huì)嚴(yán)重降低更新速度。
(4)如果待排序的列有多個(gè),可以在這些列上建立復(fù)合索引(compound index)。盡量使用較窄的索引, 這樣數(shù)據(jù)頁(yè)每頁(yè)上能因存放較多的索引行而減少操作。
(5)在查詢(xún)中經(jīng)常作為條件表達(dá)式并且不同值較多的列上建立索引,而不同值較少的列上不要建立索引。
(6)當(dāng)數(shù)據(jù)庫(kù)表更新大數(shù)據(jù)后, 刪除并重新建立索引來(lái)提高查詢(xún)速度。
總之,建立索引一定要慎重,對(duì)每個(gè)索引建立的必要性都要仔細(xì)分析,一定要有建立的依據(jù)。過(guò)多的索引或不充分、不正確的索引對(duì)提升數(shù)據(jù)庫(kù)的性能毫無(wú)益處。
2 SQL語(yǔ)句優(yōu)化
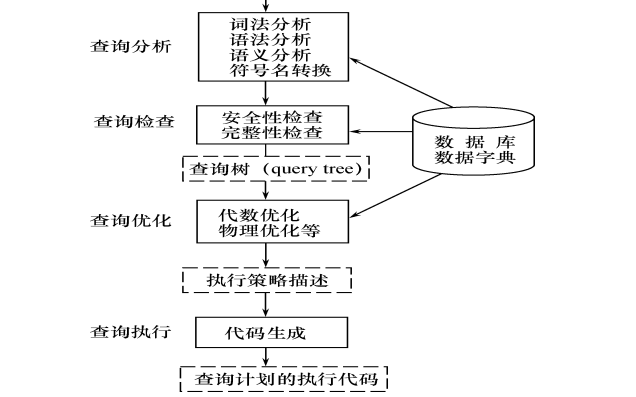
SQL語(yǔ)言是一種非常靈活的語(yǔ)言,相同功能的實(shí)現(xiàn)常可以用幾種不同的語(yǔ)句來(lái)表達(dá),但語(yǔ)句的執(zhí)行效率可能存在很的差別。因此,任何一個(gè)數(shù)據(jù)庫(kù)應(yīng)用系統(tǒng)中,合理的對(duì)SQL語(yǔ)句進(jìn)行優(yōu)化將大大的提高整個(gè)數(shù)據(jù)庫(kù)系統(tǒng)的性能。所有的SQL語(yǔ)句執(zhí)行過(guò)程分三個(gè)階段,分別是進(jìn)行處理語(yǔ)法分析、執(zhí)行、讀取數(shù)據(jù)。
圖1 SQL語(yǔ)句執(zhí)行過(guò)程
在使用SQL時(shí),性能差異在大型的或是復(fù)雜的數(shù)據(jù)庫(kù)環(huán)境中,如在HIS的一些大型表中表現(xiàn)尤為明顯。經(jīng)過(guò)一段時(shí)間的總結(jié),發(fā)現(xiàn)SQL語(yǔ)句比較低下的原因主要來(lái)自于不恰當(dāng)?shù)乃饕O(shè)計(jì)、不充分的連接條件和不可優(yōu)化的WHERE子句及其它不恰當(dāng)?shù)恼Z(yǔ)句操作等,在對(duì)它們進(jìn)行適當(dāng)?shù)膬?yōu)化后,其運(yùn)行速度有了明顯提高。下面將從這幾個(gè)方面分別進(jìn)行說(shuō)明:
2.1 LIKE操作符
LIKE操作符可以應(yīng)用通配符查詢(xún),里面的通配符組合可能達(dá)到幾乎是任意的查詢(xún),但是如果用得不好則會(huì)產(chǎn)生性能上的問(wèn)題,如like 'a%' 使用索引,like ‘%a’ 不使用索引。用 like ‘%a%’ 查詢(xún)時(shí),查詢(xún)耗時(shí)和字段值總長(zhǎng)度成正比,所以不能用CHAR類(lèi)型,而是VARCHAR。
2.2 限制返回行
在查詢(xún)Select語(yǔ)句中用Where字句限制返回的行數(shù),避免表掃描,如果返回不必要的數(shù)據(jù),浪費(fèi)了服務(wù)器的I/O資源,加重了網(wǎng)絡(luò)的負(fù)擔(dān)降低性能。如果表很大,在表掃描的期間將表鎖住,禁止其他的聯(lián)接訪(fǎng)問(wèn)表,后果嚴(yán)重。可以使用TOP語(yǔ)句來(lái)限制返回結(jié)果。當(dāng)返回多行數(shù)據(jù)時(shí),盡可能不使用光標(biāo),因?yàn)樗加么罅康馁Y源,應(yīng)該使用datastore。
2.3 UNION操作符
UNION在進(jìn)行表鏈接后會(huì)篩選掉重復(fù)的記錄,所以在表鏈接后會(huì)對(duì)所產(chǎn)生的結(jié)果集進(jìn)行排序運(yùn)算,刪除重復(fù)的記錄再返回結(jié)果。實(shí)際大部分應(yīng)用中是不會(huì)產(chǎn)生重復(fù)的記錄,最常見(jiàn)的是過(guò)程表與歷史表UNION。推薦采用UNION ALL操作符替代UNION,因?yàn)閁NION ALL操作只是簡(jiǎn)單的將兩個(gè)結(jié)果合并后就返回。
2.4 Between與IN
Between在某些時(shí)候比IN速度更快,Between能夠更快地根據(jù)索引找到范圍。如:
select * from YF_KCMX where YPXH in (12,13)
Select * from YF_KCMX where between 12 and 13
一般在GROUP BY 個(gè)HAVING字句之前就能剔除多余的行,所以盡量不要用它們來(lái)做剔除行的工作。他們的執(zhí)行順序應(yīng)該如下最優(yōu):select 的Where字句選擇所有合適的行,Group By用來(lái)分組個(gè)統(tǒng)計(jì)行,Having字句用來(lái)剔除多余的分組。這樣Group By 個(gè)Having的開(kāi)銷(xiāo)小,查詢(xún)快。對(duì)于大的數(shù)據(jù)行進(jìn)行分組和Having十分消耗資源。如果Group BY的目的不包括計(jì)算,只是分組,那么用Distinct更快。
2.5 注意細(xì)節(jié)
一般不要用如下的字句: “<>”, “!=”, “!>”, “!<”, “NOT”, “NOT EXISTS”, “NOT IN”, “NOT LIKE”, and “LIKE ‘%500’”,因?yàn)樗麄儾蛔咚饕潜頀呙琛OT IN會(huì)多次掃描表,使用EXISTS、NOT EXISTS ,IN , LEFT OUTER JOIN 來(lái)替代,特別是左連接,而Exists比IN更快,最慢的是NOT操作.如果列的值含有空,以前它的索引不起作用, “<>”, “!=”, “!>”,等還是不能優(yōu)化,用不到索引。
不要在WHere字句中的列名加函數(shù),如Convert,substring等,如果必須用函數(shù)的時(shí)候,創(chuàng)建計(jì)算列再創(chuàng)建索引來(lái)替代。還可以變通寫(xiě)法:
WHERE SUBSTRING(firstname,1,1) = ‘m’
改為:WHERE firstname like ‘m%’(索引掃描),但MIN() 和 MAX()能使用到合適的索引。
select * form ZY_FYMX where FYDJ > 3000
分析在此語(yǔ)句中若FYDJ是Float類(lèi)型的,則優(yōu)化器對(duì)其進(jìn)行優(yōu)化為Convert(float,3000),因?yàn)?000是個(gè)整數(shù),我們應(yīng)在編程時(shí)使用3000.0而不要等運(yùn)行時(shí)讓DBMS進(jìn)行轉(zhuǎn)化。同樣字符和整型數(shù)據(jù)的轉(zhuǎn)換。應(yīng)改為:
select * form ZY_FYMX where FYDJ > 3000.00
2.6 避免相關(guān)子查詢(xún)
一個(gè)列的標(biāo)簽同時(shí)在主查詢(xún)和where子句中的查詢(xún)中出現(xiàn),那么很可能當(dāng)主查詢(xún)中的列值改變之后,子查詢(xún)必須重新查詢(xún)一次。查詢(xún)嵌套層次越多,效率越低,因此應(yīng)當(dāng)盡量避免子查詢(xún)。如果子查詢(xún)不可避免,那么要在子查詢(xún)中過(guò)濾掉盡可能多的行。
-
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3846瀏覽量
64684 -
索引
+關(guān)注
關(guān)注
0文章
59瀏覽量
10500
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
數(shù)據(jù)庫(kù)SQL的優(yōu)化
Database數(shù)據(jù)庫(kù)SQL語(yǔ)句
請(qǐng)教如何用SQL語(yǔ)句來(lái)壓縮ACCESS數(shù)據(jù)庫(kù)
請(qǐng)問(wèn)labview如何通過(guò)語(yǔ)句連接sql sever數(shù)據(jù)庫(kù)?
MySQL數(shù)據(jù)庫(kù)Access存儲(chǔ)讀取SQL語(yǔ)句
DCS組態(tài)軟件實(shí)時(shí)數(shù)據(jù)庫(kù)系統(tǒng)的設(shè)計(jì)
數(shù)據(jù)庫(kù)系統(tǒng)模擬負(fù)載的探討和實(shí)現(xiàn)
數(shù)據(jù)庫(kù)SQL語(yǔ)句電子教程
數(shù)據(jù)庫(kù)系統(tǒng)概論之如何進(jìn)行數(shù)據(jù)庫(kù)編程的資料概述
數(shù)據(jù)庫(kù)系統(tǒng)概論之如何進(jìn)行關(guān)系查詢(xún)處理和查詢(xún)優(yōu)化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論