") 以太網(wǎng)RDMA RoCE的技術(shù)局限
以太網(wǎng)RDMA RoCE的技術(shù)局限
上期我們講到了RDMA的WHY,WHAT & HOW(AI網(wǎng)絡(luò)背景下RDMA的Why,What & How),這一期我們來談一談RDMA的不足。
Ethernet & RDMA
在過去30年中,每當(dāng)我們談?wù)摼W(wǎng)絡(luò)時(shí),無論面對(duì)什么問題,答案始終是以太網(wǎng)。為什么?因?yàn)樗峁┝烁鼉?yōu)的TCO,在可擴(kuò)展性方面遠(yuǎn)超任何競(jìng)爭(zhēng)技術(shù),并且擁有任何其他技術(shù)都無法比擬的生態(tài)系統(tǒng):各個(gè)供應(yīng)商的產(chǎn)品能靈活適配、協(xié)同工作。它具備極其成熟的技術(shù)和極為巨大的規(guī)模經(jīng)濟(jì)優(yōu)勢(shì)。
RDMA網(wǎng)絡(luò)是AI/ML部署的關(guān)鍵推動(dòng)者,它允許GPU以高利用率運(yùn)行,并縮短作業(yè)完成時(shí)間(JCT)。通過提高效率,RDMA降低了擁有成本,并允許更快的訓(xùn)練時(shí)間,這是微軟、Open AI、Meta等建設(shè)AI基礎(chǔ)的關(guān)鍵指標(biāo)。
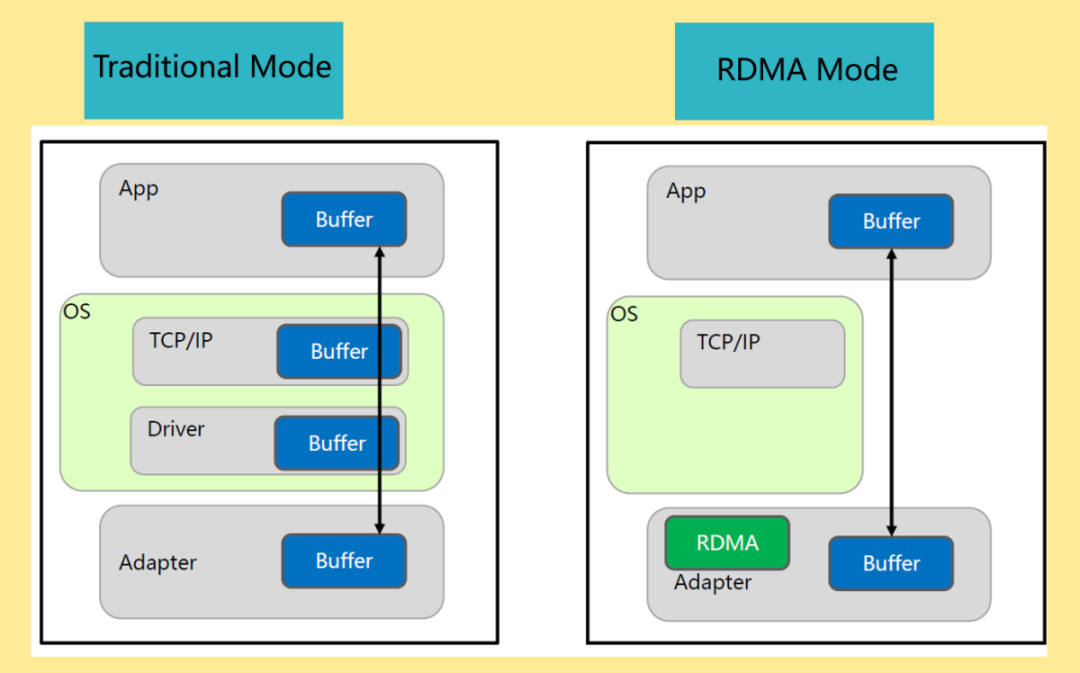
(圖片來源于網(wǎng)絡(luò))
RoCE(RDMA over converged Ethernet)就是允許通過以太網(wǎng)網(wǎng)絡(luò)實(shí)現(xiàn)RDMA功能的技術(shù),它同時(shí)具備RDMA的高效和以太網(wǎng)的生態(tài)優(yōu)勢(shì),其諸多特性在多種計(jì)算場(chǎng)景中發(fā)揮了巨大作用。然而,隨著機(jī)器學(xué)習(xí)(ML)和人工智能(AI)的迅猛發(fā)展,原本并非針對(duì)超大規(guī)模集群設(shè)計(jì)的RDMA技術(shù),在應(yīng)對(duì)成千上萬節(jié)點(diǎn)的大規(guī)模組網(wǎng)時(shí),其性能逐漸顯現(xiàn)出局限性。 隨著Mixture of Experts(MoE)等先進(jìn)模型結(jié)構(gòu)的出現(xiàn),模型參數(shù)邁入萬億規(guī)模。AI網(wǎng)絡(luò)正面臨更大規(guī)模、更高帶寬、更低延遲的一系列性能需求。 那么,現(xiàn)有的RoCE技術(shù)在應(yīng)對(duì)這些挑戰(zhàn)時(shí)存在哪些不足?展望未來,RoCE技術(shù)又將迎來哪些創(chuàng)新和變革?以下是我們對(duì)RoCE技術(shù)當(dāng)前局限性和未來發(fā)展趨勢(shì)的探討。
當(dāng)前RDMA RoCE的一些技術(shù)局限
首先,雖然運(yùn)用RoCE已經(jīng)成功實(shí)現(xiàn)了許多規(guī)模集群的組網(wǎng),隨著集群規(guī)模從萬卡向十萬卡演進(jìn),RoCE在大規(guī)模集群場(chǎng)景下面臨以下不足:
PFC 需要大量緩沖來實(shí)現(xiàn)無損傳輸
優(yōu)先級(jí)流控(PFC)是融合以太網(wǎng)(Converged Ethernet)的核心,為的是能在每個(gè)鏈路上實(shí)現(xiàn)無損傳輸。 使用 PFC 時(shí),接收方會(huì)監(jiān)控可用的輸入緩沖區(qū)空間(buffer space),一旦緩沖空間低于與帶寬-延遲乘積(BDP = BW*RTT)相關(guān)的某個(gè)閾值,接收端會(huì)向發(fā)送端發(fā)送一個(gè)PAUSE幀。此時(shí),BDP/2字節(jié)的數(shù)據(jù)已經(jīng)在傳輸中,而在發(fā)送端接收到PAUSE幀之前,它還會(huì)發(fā)送另外的BDP/2字節(jié)。因此,完全無損傳輸?shù)淖钚【彌_需求是BDP + MTU(最大傳輸單元),其中MTU為最大數(shù)據(jù)包大小。(這還只是數(shù)據(jù)包在接收端立即被處理的情況,任何一點(diǎn)延遲都會(huì)顯著降低鏈路利用率。)
覆蓋PAUSE消息傳輸延遲所需的BDP緩沖空間通常被稱為“余裕緩沖”(headroom buffer),類似于用于信用機(jī)制流量控制的緩沖空間,如InfiniBand或Fibre Channel中使用的流量控制機(jī)制。 在這些機(jī)制中,接收端主動(dòng)向發(fā)送端發(fā)送信用額度(緩沖分配),以保持輸入緩沖區(qū)的平衡,而PFC機(jī)制則是在緩沖區(qū)過滿時(shí)才反應(yīng)。這兩種機(jī)制各有優(yōu)點(diǎn)——信用額度可以主動(dòng)傳向源頭,而PFC則可以更具反應(yīng)性(遲綁定),在為不同的源鏈路分配共享緩沖空間時(shí)進(jìn)行調(diào)節(jié)。兩種機(jī)制本質(zhì)上都需要為每個(gè)鏈路保留BDP的空間,以覆蓋鏈路的往返控制延遲,這部分空間在高效轉(zhuǎn)發(fā)中是無法使用的。
實(shí)際上,緩沖空間對(duì)于處理變化的流量峰值和進(jìn)行時(shí)間和空間上的負(fù)載均衡至關(guān)重要。僅僅是所需的余裕緩沖,在不冒丟包風(fēng)險(xiǎn)的情況下無法用于其他用途,這對(duì)下一代交換機(jī)的擴(kuò)展帶來了巨大挑戰(zhàn)。
主流的交換機(jī)廠商如Broadcom、Marvell和Cisco等都已推出了50T交換機(jī)以滿足高帶寬、低時(shí)延、零丟包的網(wǎng)絡(luò)需求,以RTT 3~5微秒估算,以51.2T(64個(gè)800G)的交換機(jī)而言,BDP大小約33MB左右。隨著未來交換機(jī)吞吐量的增加,buffer size(約可以認(rèn)為是BDP)也會(huì)繼續(xù)增加。(見圖a)(圖片展示的buffer size是只考慮交換機(jī)吞吐量作為變量的情況,實(shí)際RTT也會(huì)有所變化)
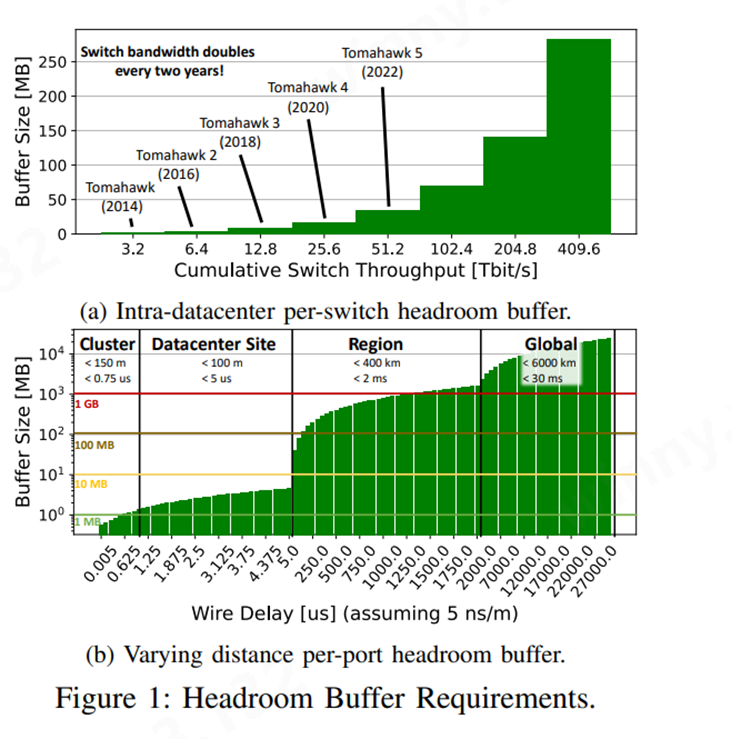
(圖源:Datacenter Ethernet and RDMA: Issues at Hyperscale)
而隨著傳輸距離的增加,對(duì)buffer size的要求也會(huì)急劇增加。(見圖b)
受害流、擁塞樹、PFC風(fēng)暴和死鎖
另一個(gè)問題源于 PFC 會(huì)暫停整個(gè)流量類別以及其中的所有流量。這會(huì)導(dǎo)致受害流的出現(xiàn):假設(shè)有兩個(gè)流:A和B共享一條鏈路L。A沒有擁塞,可以以全帶寬發(fā)送。但B在某個(gè)下游端口被阻塞,填滿了L的輸入緩沖區(qū)。最終,L 分配的緩沖區(qū)會(huì)被B的數(shù)據(jù)包填滿,L會(huì)發(fā)送一個(gè)暫停幀。這一幀也會(huì)暫停A,而A本可以獨(dú)立傳輸——因此,A因B的暫停而受害。即,未發(fā)生擁塞的流可能會(huì)受到其他擁塞流的影響。這種現(xiàn)象也被稱為隊(duì)首阻塞(Head of Line Blocking)。
由于下游端口的任何擁塞都會(huì)填滿上游的緩沖區(qū),除非端點(diǎn)擁塞控制協(xié)議做出反應(yīng),PFC 事件可以快速形成一個(gè)“擁塞樹”,這種擁塞樹會(huì)順著受害流在網(wǎng)絡(luò)中反向擴(kuò)展。擁塞樹是無損網(wǎng)絡(luò)中的常見問題,有時(shí)也被稱為 PFC 風(fēng)暴 。
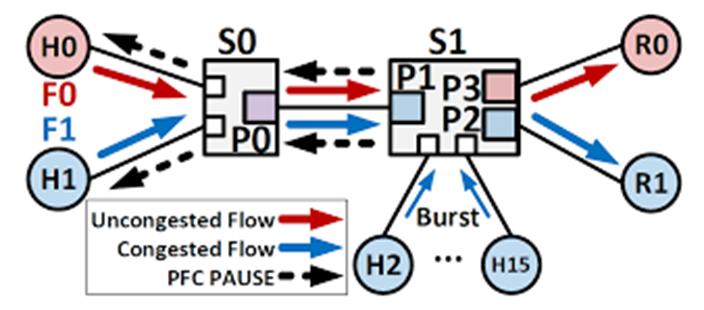
(圖片來源于網(wǎng)絡(luò))
而且任何具有有限緩沖的無損方案在路由允許形成循環(huán)時(shí)都會(huì)遭遇死鎖問題。
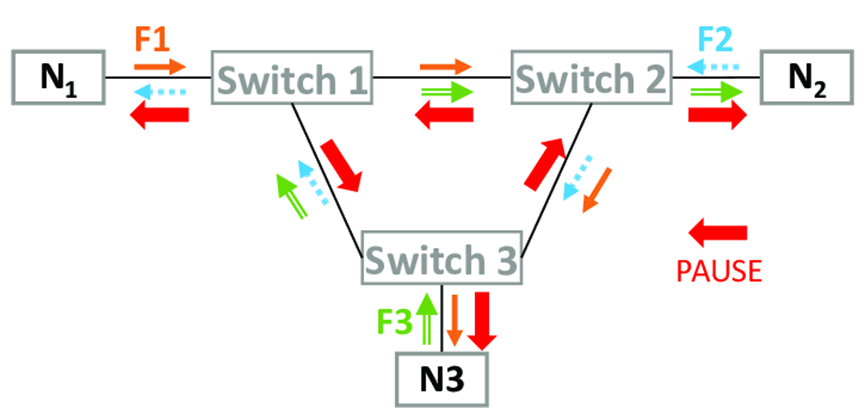
(圖片來源于網(wǎng)絡(luò))
Go-back-N 重傳
RoCE是為遵循 InfiniBand 的有序和基于信用的無損傳輸而設(shè)計(jì)的非常簡(jiǎn)單的硬件。 這意味著只有在數(shù)據(jù)包因比特錯(cuò)誤而損壞時(shí),才會(huì)丟棄數(shù)據(jù)包,這種情況非常少見。RoCE的重傳邏輯要求所有數(shù)據(jù)包必須按順序到達(dá)數(shù)據(jù)流中。這意味著第一個(gè)數(shù)據(jù)包必須在第二個(gè)數(shù)據(jù)包之后到達(dá),第三個(gè)數(shù)據(jù)包必須在第二個(gè)數(shù)據(jù)包之后到達(dá),以此類推。但如果數(shù)據(jù)包在RDMA數(shù)據(jù)流中丟失,比方說第五個(gè)數(shù)據(jù)包丟失,但后續(xù)數(shù)據(jù)包(六、七、八)已成功傳輸,“Go-back-N”重傳技術(shù)會(huì)告訴系統(tǒng),“你丟失了第五個(gè)數(shù)據(jù)包,所以我需要你重新傳輸數(shù)據(jù)包五、六、七和八。”而大量的重傳會(huì)嚴(yán)重影響網(wǎng)絡(luò)性能。
簡(jiǎn)單的 Go-back-N 方案還有一個(gè)更大問題是,它不支持多路徑或亂序交付。但支持亂序交付的其他方案則需要等待發(fā)送方的超時(shí)到期,這可能導(dǎo)致更高的恢復(fù)時(shí)間和抖動(dòng)。因此,在設(shè)計(jì)新的傳輸協(xié)議時(shí),必須仔細(xì)考慮所有這些權(quán)衡。
擁塞控制與其他流量的共存
RoCE 的默認(rèn)擁塞控制基于一種無損傳輸前提下的速率控制機(jī)制。數(shù)據(jù)中心通常使用 DCQCN、TIMELY和 HPCC 等機(jī)制,構(gòu)建在 RoCE 的基礎(chǔ)上改善流量傳輸。但現(xiàn)在大多數(shù) RoCE 部署使用非標(biāo)準(zhǔn)的擁塞控制機(jī)制,需要精細(xì)調(diào)整許多參數(shù),例如 ECN 閾值、減速因子、時(shí)間間隔等,這使得不同供應(yīng)商,甚至同一供應(yīng)商的不同硬件代之間的互操作性變得困難。這是因?yàn)閾砣刂迫匀皇且粋€(gè)艱難的問題,不同的工作負(fù)載可能需要經(jīng)過調(diào)優(yōu)的協(xié)議版本。
目前不支持智能協(xié)議棧
隨著網(wǎng)絡(luò)開銷在數(shù)據(jù)中心工作負(fù)載中的重要性日益增加,需要設(shè)計(jì)出更加智能的協(xié)議棧。新興的智能網(wǎng)卡 (Smart NIC) 為這一領(lǐng)域帶來了新的機(jī)會(huì),用戶可配置的內(nèi)核可以在 NIC 上執(zhí)行數(shù)據(jù)包和協(xié)議處理 。
比如論文《sPIN: High-performance streaming Processing In the Network》中提到的“sPIN”新型網(wǎng)絡(luò)處理模型,它是一種可編程的網(wǎng)絡(luò)接口控制器(NIC),通過硬件加速在網(wǎng)絡(luò)層直接處理數(shù)據(jù)。支持用戶自定義的程序在數(shù)據(jù)到達(dá)時(shí)進(jìn)行處理,避免數(shù)據(jù)包先被傳輸?shù)椒?wù)器端再處理的延遲。該系統(tǒng)結(jié)合了網(wǎng)絡(luò)處理器和可編程硬件(如FPGA)的優(yōu)勢(shì),能夠在數(shù)據(jù)傳輸過程中執(zhí)行簡(jiǎn)單的計(jì)算任務(wù),比如數(shù)據(jù)壓縮、過濾等操作。
系統(tǒng)層面的問題
隨著鏈路層和端到端延遲的增加,系統(tǒng)也會(huì)面臨更多問題。高延遲會(huì)導(dǎo)致緩沖區(qū)占用增加、能耗上升,并使擁塞控制效率降低。特別是對(duì)于那些傳輸速度超過單個(gè)往返時(shí)間(RTT)的消息,依賴接收端反饋的擁塞控制機(jī)制變得無效,導(dǎo)致小消息引發(fā)的不良 incast 問題變得更加嚴(yán)重或頻繁。
此外,RDMA固有的語義復(fù)雜性和安全性問題也應(yīng)引起關(guān)注。暴露進(jìn)程本地的虛擬地址會(huì)引發(fā)安全隱患。路由和負(fù)載均衡仍然是挑戰(zhàn),尤其是在數(shù)據(jù)中心和 HPC 網(wǎng)絡(luò)中,不同的系統(tǒng)架構(gòu)需要不同的機(jī)制來優(yōu)化網(wǎng)絡(luò)流量和消息處理順序。
那么,現(xiàn)在有哪些改進(jìn)思路呢?
RoCE改進(jìn)建議
改進(jìn)流控機(jī)制
當(dāng)前的PFC機(jī)制由于需要大量緩沖區(qū)并且無法精細(xì)地管理個(gè)別流量,可以通過更加細(xì)粒度的流量控制方法來解決這些問題。例如,使用基于流的擁塞追蹤而不是基于優(yōu)先級(jí)的追蹤,可以有效減少受害流現(xiàn)象。同時(shí),通過動(dòng)態(tài)調(diào)整擁塞優(yōu)先級(jí)(如擁塞隔離技術(shù))也可以有效緩解擁塞問題。
擁塞管理與路由改進(jìn)
針對(duì)擁塞樹和PFC風(fēng)暴的問題,可以使用更復(fù)雜的流量監(jiān)控和管理機(jī)制,例如在交換機(jī)中維護(hù)每個(gè)流的狀態(tài),以便更好地追蹤擁塞情況。此外,動(dòng)態(tài)調(diào)整流量?jī)?yōu)先級(jí)或采用無擁塞路由策略,也可以避免受害流和擁塞樹的產(chǎn)生。
增強(qiáng)重傳機(jī)制
針對(duì)Go-back-N機(jī)制的局限性,可以采用選擇性重傳(Selective re-transmission)或支持亂序傳輸?shù)臋C(jī)制,以減少不必要的數(shù)據(jù)重傳。例如,最新的RoCE適配器已經(jīng)引入了選擇性重傳技術(shù),但仍需進(jìn)一步優(yōu)化,尤其是在處理多路徑傳輸時(shí)。
展望未來
隨著計(jì)算任務(wù)的復(fù)雜性和數(shù)據(jù)規(guī)模的增加,AI網(wǎng)絡(luò)面臨的壓力也越來越大。未來的發(fā)展方向不僅包括改進(jìn)現(xiàn)有的RoCE技術(shù),還包括探索新的網(wǎng)絡(luò)拓?fù)洹⒘骺睾蛽砣芾矸椒ā?/p>
RoCE技術(shù)的進(jìn)一步發(fā)展需要與新的網(wǎng)絡(luò)需求相適應(yīng),如機(jī)密計(jì)算、地理復(fù)制數(shù)據(jù)中心和多租戶環(huán)境等。這些新興技術(shù)和應(yīng)用場(chǎng)景將推動(dòng)下一代高性能AI網(wǎng)絡(luò)的創(chuàng)新,確保智算中心能夠在極端工作負(fù)載下保持高效穩(wěn)定的運(yùn)行。
因此,Ultra Ethernet提出了解決RDMA問題的構(gòu)想,稱之為“Ultra Ethernet Transport”。包括奇異摩爾在內(nèi)的UEC成員們正在采取一系列措施,目標(biāo)是建立一個(gè)具有高彈性、高性能的令人難以置信的強(qiáng)大網(wǎng)絡(luò),在一個(gè)非常穩(wěn)健的網(wǎng)絡(luò)環(huán)境中實(shí)現(xiàn)超過十萬個(gè)節(jié)點(diǎn)的可擴(kuò)展性,并在開放標(biāo)準(zhǔn)框架內(nèi)運(yùn)行。(構(gòu)建更完善、更高效的AI網(wǎng)絡(luò)基礎(chǔ)設(shè)施:UEC 超以太聯(lián)盟最新進(jìn)展)
Broadcom公司高級(jí)副總裁Ram Velaga說,在ML/AI的世界里,不會(huì)有一家公司提供所有GPU,也不會(huì)有一家公司提供所有互連解決方案。我們實(shí)現(xiàn)可擴(kuò)展性的唯一方法是建立一個(gè)生態(tài)系統(tǒng),由多個(gè)供應(yīng)商提供加速器。這個(gè)生態(tài)系統(tǒng)的生存依賴于構(gòu)建一個(gè)開放的、基于標(biāo)準(zhǔn)的、高性能的和具有成本效益的互連架構(gòu)。以太網(wǎng)是唯一的選擇,無論是昨天、今天還是明天。
-
以太網(wǎng)
+關(guān)注
關(guān)注
40文章
5460瀏覽量
172737 -
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
7599瀏覽量
89251 -
AI
+關(guān)注
關(guān)注
87文章
31520瀏覽量
270335 -
云交換機(jī)
+關(guān)注
關(guān)注
0文章
2瀏覽量
6014 -
RDMA
+關(guān)注
關(guān)注
0文章
78瀏覽量
8981
原文標(biāo)題:Kiwi Talks | 超大規(guī)模下的以太網(wǎng)RDMA的局限與展望
文章出處:【微信號(hào):奇異摩爾,微信公眾號(hào):奇異摩爾】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
RoCE與IB對(duì)比分析(一):協(xié)議棧層級(jí)篇

車載以太網(wǎng)基礎(chǔ)培訓(xùn)——車載以太網(wǎng)的鏈路層#車載以太網(wǎng)
工業(yè)以太網(wǎng)交換技術(shù)原理
快速以太網(wǎng),快速以太網(wǎng)是什么意思
以太網(wǎng)的分類及靜態(tài)以太網(wǎng)交換和動(dòng)態(tài)以太網(wǎng)交換、介紹
千兆以太網(wǎng)發(fā)展現(xiàn)狀 千兆以太網(wǎng)技術(shù)優(yōu)勢(shì)
用NVIDIA NetQ 4.0.0實(shí)現(xiàn)網(wǎng)絡(luò)質(zhì)量和可靠性監(jiān)測(cè)
如何快速分辨以太網(wǎng)與千兆以太網(wǎng)
RDMA技術(shù)簡(jiǎn)介 RDMA的控制通路和數(shù)據(jù)通路方案
RDMA網(wǎng)卡相比以太網(wǎng)卡的優(yōu)勢(shì)在哪里呢?
數(shù)據(jù)中心以太網(wǎng)和RDMA:超大規(guī)模環(huán)境下的問題

什么是RDMA?什么是RoCE網(wǎng)絡(luò)技術(shù)?
深度解讀RoCE v2的核心技術(shù)原理
加速網(wǎng)絡(luò)性能:融合以太網(wǎng) RDMA (RoCE) 的影響





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論