 同樣ARM架構,蘋果處理器更強的原因詳解
同樣ARM架構,蘋果處理器更強的原因詳解
蘋果在2008 年4 月23 日,冒著極大風險硬著頭皮發表初代iPhone 的隔年,耗費2 億7,800 萬美元,購并了專注開發高效能Power 處理器的PA Semi,組成其處理器研發團隊的骨干,然后在2012 年9 月發表的iPhone 5,其心臟「A6」處理器,終于不再使用來自ARM 授權的核心,采用自家的「Swift」微架構(Micro Architecture)。
再以世界上首款搶灘登陸智慧型手機與平板的64 位元ARM 處理器「A7」(Cyclone 微架構)為起點,蘋果自家SoC 開始逐漸展現壓倒ARM Cortex 家族(與躺著中槍的Qualcomm 自有核心)效能優勢,且隨著時間演進,差距越拉越開。
接著,每代iPhone 發表后,各大科技媒體網站的報導,與底下的讀者回應,只會有兩種制式的單細胞生物反應:
文章高高掛著「眾人都驚呆了,連開發效能測試軟件的人都不知道發生了什么事」如內容農場般的標題,再來繼續機械化的炒作「蘋果會不會用自家芯片取代Intel處理器」的多年冷飯。
底下的讀者留言雞同鴨吵成一團,上演「Android 自由主義」和「蘋果神權政治」信徒大對決,沒有人講到任何值得注意的重點,連一絲一毫的學理成分都沒有,宗教信仰就是如此奇妙。
筆者不啰唆,直接在這里講結論:
藉由牢牢把持軟硬件平臺的「封閉性」先天優勢,蘋果掌握了ARM 指令集邁向64 位元帶來的機會,打造出一系列同時間能夠有效處理更多指令的先進微架構。
看起來好像微言大義到接近廢話的程度?如果你真的這樣想,那你就更有繼續讀下去的必要。
撥亂反正:做為電腦語言的「指令集架構」vs. 執行語言載具的「處理器核心微架構」
近年來拜ARM 為首的授權IP 商業模式之所賜,越來越多人搞不懂這兩者的差別,完全混在一起,這些年來筆者已經聽過太多讓人完全笑不出來的笑話,所以在此特別重述一次。
支配智慧型手機市場的ARM 又是怎么一回事呢?以32 位元ARMv7-A 指令集為例,在手機上常見的微架構(核心),總計有:
ARM 本家賣IP 授權給別人的Cortex-A5 / A7 / A9 / A12 / A15 / A17 這幾種核心微架構。
Qualcomm 自行打造的Scorpio / Krait。
蘋果并購PA Semi 后關起門來搞出的A6「Swift」,iPhone 5 的心臟。
換成64 位元ARMv8-A,就變成以下場景:
ARM 本家賣IP 授權給別人的Cortex-A35 / A53 / A57 / A72 / A73 這幾種核心微架構。
增加半精度浮點支援和系統可靠度機能的ARMv8.2-A 指令集:Cortex-A55 / A75。
Qualcomm 自行打造的Kyro。
nVidia 的Project Denver。
蘋果繼續關起門來搞出的A7「Cyclone」,與之后的眾多芯片,如A8「Typhoon」、A9「Twister」、A10「Fusion」(Hurricane + Zephyr)、A11「Bionic」(Monsoon + Mistra) 。
為了伺服器而量身訂做的特殊微架構,如Qualcomm Centriq 2400 的「Falkor」,和Cavium Thunder X 系列的核心。
只要作業系統相同(如同版本Android 或iOS),這些核心微架構應當正確執行使用ARM 指令集撰寫或編譯出來的軟件,講的更專業或更假掰一點,它們擁有相同的應用程式二進位執行檔介面(ABI,Application Binary Interface),如同Intel 與AMD 的x86 處理器都應可正確安裝Windows 作業系統,理所當然執行Office 等應用軟件和Battlefield 等套裝游戲。
至于Qualcomm、蘋果和nVidia,是否根本自身特殊需求,自行定義「非官方」ARM 指令,那就后頭有空再討論了。
高效能之路:讓核心微架構同時間內能夠有效處理更多的指令
在執行相同指令集「語言」的前提之上,相容處理器的效能要能夠勝出,只有微架構設計能否比競爭對手有效處理更多的指令。方向不外乎:
更高的時脈:雖然往往計算機概論會教你「指令管線階段越多,代表處理器同時執行更多的指令,只是這些指令位處于不同的階段」,但實際上最多還是一個時脈周期「吐出」一個被執行完畢的指令,所以現實層面的「加深指令管線」,實際上跟「提高運行時脈」講的是同一件事。很不幸的,智慧型手機因嚴格的功耗限制,透過積極追求高時脈以提高效能,是比較不切實際的方向。
更寬的管線:一個便當吃不夠,你可以吃第二個,嫌執行一個指令不夠看,你也可以同時執行第二個,這就是源自1966年CDC6600的「超純量」(Superscalar)架構。另外也有純軟件方式、讓編譯器去一個蘿卜一個坑塞指令到不同執行單元的「超長指令集」(VLIW),這就不在本文的討論范圍內了。
足以喂飽嗷嗷待哺執行單元的高效能記憶體子系統:包含系統主記憶體、快取記憶體、連結多個處理器核心的匯流排、舉足輕重的快取記憶體資料一致性協定(Cache Coherence Protocol) ,甚至可以非循序的存取記憶體位址(Memory Disambiguation),都是不可或缺的「基礎建設」。
天底下沒有白吃的午餐:兩種該死的「相依性」
但「指令管線化」與「指令執行平行化」也帶來了新的挑戰。
控制相依性:電腦有別于計算器的最重要特征在于「條件判斷」的能力,根據不同的條件執行不同的指令流,處理器如碰到分支(Branch)或跳躍(Jump),就須改變指令執行的流程,清除已經進入管線的指令,從另一個記憶體位址擷取指令,重新執行并存取相關的資料(或稱為「運算元」,意指運算的目標,如特定資料暫存器或記憶體位址),而具備條件判斷的分支,造成的傷害更大,因為需要管線停下來等待其結果、或著事先預測并「先斬后奏」。
解決方案:分支預測(Branch Prediction),與后面會提到、釜底抽薪減少分支指令的「條件執行」(Conditional Execution)。
資料相依性:當同時執行多個指令,最忌諱遭遇「撞衫」同時存取相同的資料暫存器與記憶體位址,特別是當指令集定義可操作的資料暫存器越少,軟件手段可以盡量排除的空間越少,發生的機率也越高。
解決方案:以暫存器重新更名機制(Register Rename)為中心的非循序指令執行(Out-Of-Order Execution)。
然后根據分支預測結果而先斬后奏「預測性執行指令」(Speculative Execution),是分支預測與非循序指令執行的結合體。總之,我們盡其所能的讓管線「順暢」的像生產線不停的運轉,實現最高的指令執行效率。
理所當然的,指令管線越深,一旦「筊杯」失敗,要復原管線并恢復指令執行的代價,也越像火燒摩天樓一樣恐怖,這也是高時脈深管線近年來不太受歡迎的另類主因,因為現實世界的應用程式,其實有很多難以預測的分支行為,越高的「代價」,更意味著更差勁的「效能/功耗」比。
LLVM 開發環境參數透露的神秘訊息
講了那么多原理,蘋果從來不公開自主微架構的技術細節,那該如何掌握他們追求高效能的設計方向?
2014 年初,當多數世人正「驚呆」A7 的64 位元與驚人的性能表現時,有人注意到蘋果提交的LLVM 原始代碼,不僅透露了微架構代號是「Cyclone」,更包含眾多重要的規格參數:
指令發出寬度(Issue Width):6
非循序指令執行緩沖區(Reorder Buffer):192
記憶體載入延遲(Load Latency):4
分支預測錯誤代價(Misprediction Penalty):16(一般介于14~19)
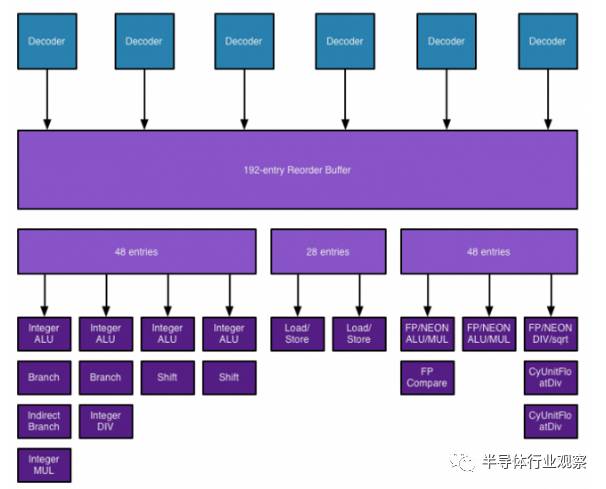
在當時,這是非常驚人的規格,就算擺在今天也是同樣駭人,可同時處理的指令是同時期ARM 核心足足兩倍(即使64 位元的Cortex-A57 也只能3 個指令),非循序指令執行引擎的「深度」則是Intel Haswell 等級,指令管線深度則中規中矩的維持在16 階這一般水準。
相信有些讀者早已從其他網站看過相關的報導,但有個「江湖傳言」倒是值得注意:部分開發iOS 應用程式的程式設計者,做了一些指令輸出率的實驗,察覺到「A7 一旦執行32 位元程式碼,指令輸出率就腰斬了」,這個「特性」一路延續到A10,直到A11 根本沒有32 位元應用程式可執行為止。
后來蘋果當然就沒有繼續「規格大放送」,Wiki上蘋果處理器的規格表,一路從A7到A11,都是維持這些數字,有沒有經過實測考驗也不得而知,反正就大家一起無限回圈繼續驚呆,蘋果持之以恒的甩開和其他競爭者的差距。
唯一可以確定的是,筆者在自己的iPad Pro 9.7 吋A10X 上,透過配對簡單指令,測出每個時脈周期可同時輸出「4 個整數,2 個浮點,2 個記憶體載入」的可怕性能。此外,A10X 與A11 放棄第三階4MB 快取記憶體,而以大型化第二階8MB 取而代之,也暗示了蘋果極可能在快取記憶體技術有了重大的突破,可兼顧高容量與低延遲。
A11?筆者沒有iPhone 8 和iPhone X 可用,有機會再測測看。
讓我們重新畫出命案現場的人形粉筆圈,歸納出蘋果的產品設計取向:
微架構以64 位元效能為優先設計考量。
既然行動處理器受制于低功耗需求,難以透過提高時脈追求效能,索性以「更寬」的指令管線取勝。
同時執行更多指令,代表要耗費更多心思去解決暫存器相依的問題。
更強力的非循序指令執行引擎。
寄望指令集本身就定義更多的資料暫存器,降低「強碰」機率。
ARM 指令集走向64 位元帶來的重大改革
讓ARM 指令集邁向64 位元的ARMv8-A,并非只有「將整數邏輯暫存器寬度延長到64 位元」和「提供64 位元記憶體定址空間」這么簡單,拋棄昔日專注于嵌入式應用的遺產,更加的簡潔優雅,更利于打造高效能微架構,引領ARM 榮登高效能的天堂,是這次指令集改版最神圣不可侵犯的絕對使命。
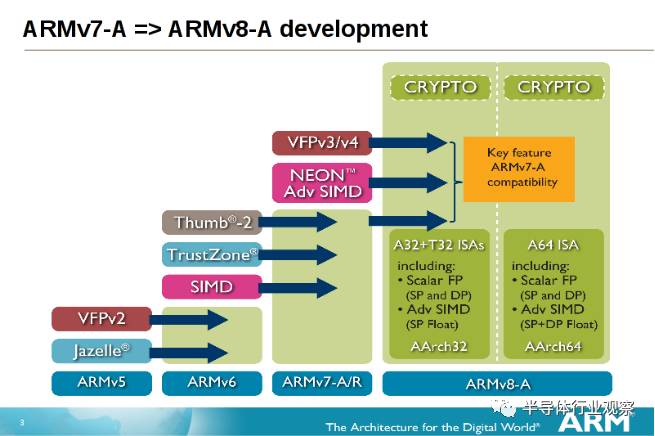
ARMv8-A 修訂項目極多,但就筆者的角度,除了取消「加速重建儲存CPU 狀態的Context Switch 相關機制」(一堆就今日觀點實在很小家子氣的技術),和簡化例外處理與執行特權階層外,最重大的改革,只有兩項:
倍增通用暫存器(GPR)數量,這件事在當年AMD 讓x86 邁向64 位元時也發生過,意義重大。
取消涵蓋整套指令集的「條件執行」(Conditional Execution),這和前者互為表里,因為總算擠出了珍貴的指令編碼空間去增加暫存器數量。
其中又稱為「引述式執行」(Predicated Execution,或Guarded Exectuion)的后者,目的在于減少程式中的分支,指令集提供簡單扼要的條件執行指令,一次做完所有事情。
直接舉例比較快。原本一個簡單的If-Then-Else 循序條件判斷,會需要等待確認條件結果,或著強行進行分支預測,管線才會繼續動作:
if condition
then do this
else
do that
就變成這樣:
(condition) do this
(not condition) do that
有沒有感覺簡潔多了?講的玄一點,條件執行的中心精神在于「將控制相依性轉化為資料相依性」。
然后有鑒于過去的應用程式,在這種If-Then-Else 的條件判斷中,有60% 都是資料搬移指令,這也是為何指令集「事后」擴充條件執行功能,如DEC Alpha、MIPS、甚至x86,都以「條件搬移」(Conditional Move)為主。
以Alpha 為例,其指令格式統一為cmovxx(xx 代表條件),一個簡單的條件搬移:
beq ra, label // if (ra) = 0, branch to 'label'
or rb, rb, rc // else move (rb) into rc
可以透過新指令,簡化如下:
cmovne ra, rb, rc
在ARMv8 之前,整套ARM 指令集每道指令,都包含了4 位元的條件碼,必須符合「某個條件」才會執行指令。如條件成立,執行此指令并寫回運算結果。反之,指令執行結果無效,或不予執行。
回到原點,條件執行的優點很明顯:
加速實際條件判斷的效率,因為實際上只要比較0 與1(Bitwise)。
減少簡單條件判斷的分支,可以提升指令平行化執行的潛力。這也是為何很多VLIW 指令集普遍支援條件執行。甚至定義存放引述碼(Predicate)的專用暫存器,以因應更復雜多樣的條件判斷,如攤平回圈的軟件管線(Software Pipeline)。
但為何ARM 要取消看似完美的條件執行?
占用4 位元指令編碼,實在是太浪費了,所以用「條件選擇」(Conditional Select)取而代之。
舉個范例:「CSEL W1, W2, W3, Cond」,如條件符合,W2 暫存器資料搬移到W1,如非,就W3 到W1。缺點是會稍微增加程式碼體積,但絕對劃算。
提高打造高效能非循序指令執行引擎的復雜度,在管線前端就要「預鎖」后面所需要的相關資源,也增加后方需要「更名」的暫存器,更不利提升時脈。
A11「極可能」是純64 位元的微架構
可確保處理器正確執行所有軟件的指令集回溯相容性,是商業上的「資產」,但也是設計處理器微架構的「包袱」。
我們有非常充分的理由相信,蘋果急著驅離「32 位元低階應用程式」,就是為了其處理器全力針對64 位元最佳化造橋鋪路,而A11 如此驚世駭俗的效能表現,除了它根本是純64 位元處理器,所有電晶體預算都砸在提升效能的刀口上,沒有其他合理的解釋了(新的異質多處理器排程也有影響,但沒那么絕對)。「就算」A11 具備32 位元相容性,其性能表現恐怕也僅聊勝于無,不足掛齒。
無獨有偶,Qualcomm 企圖搶攻伺服器市場的Centriq 2400,也是純64 位元的設計,這就是ARM 制定64 位元指令集擴充時,最希望看到的結果:雨后春筍般的高效能產品。
同場加映:Mac 改用自家芯片的可能性
關于這個「年經」(每年發表一支新iPhone)議題,筆者不會賭上爺爺的名譽做不負責任的推論,但只留下兩個留待讀者思考的問題:
蘋果能否承擔轉移的成本,尤其當Mac 用戶已非弱勢族群的當下。
蘋果是否仍希望「吸收」Windows PC 的使用者。
Mac 是否改用蘋果自家芯片這檔事,并不只是「效能夠好」就可以一筆輕松帶過的大哉問,請各位多多考量商業層面的因素。
蘋果同時掌握軟硬件的「不公平競爭」
最后,再重新貼出本文標題的答案:
「藉由牢牢把持軟硬件平臺的『封閉性』先天優勢,蘋果掌握了ARM 指令集邁向64 位元帶來的機會,打造出一系列同時間能夠有效處理更多指令的先進微架構。」
這「一體成形」的絕對優勢,在可見未來的深度學習之路上,會更加的牢不可破,這就是蘋果在iPhone 前景未明之際,就膽敢購并PA Semi 投資未來,所得到的豐碩成果,就算你不喜歡「果粉」,你也不能不佩服喬布斯的遠見。
至于PA Semi 究竟干過哪些值得蘋果冒險的好事,等以后有機會,再好好談談,如果真的還有機會。
-
處理器
+關注
關注
68文章
19409瀏覽量
231201 -
ARM
+關注
關注
134文章
9169瀏覽量
369239 -
蘋果
+關注
關注
61文章
24476瀏覽量
200020
原文標題:同樣ARM架構,為何蘋果處理器更強?
文章出處:【微信號:icbank,微信公眾號:icbank】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
傳蘋果將在WWDC發布ARM架構Mac芯片
有朋友對蘋果的處理器有研究的么
RISC架構在ARM微處理器的應用
蘋果公司為什么要用ARM處理器
蘋果M2處理器曝光:性能更強 精選資料分享
ARM公版架構 真的是麒麟處理器的槽點嗎?

蘋果電腦處理器將摒棄英特爾處理器,采用ARM架構處理器

蘋果憑借M1系列占據ARM架構處理器市場的90%收入





 工商網監
工商網監
評論