") 各深度學(xué)習(xí)框架之間性能差異比較分析
各深度學(xué)習(xí)框架之間性能差異比較分析
深度學(xué)習(xí)框架哪家強:TensorFlow?Caffe?MXNet?Keras?PyTorch?對于這幾大框架在運行各項深度任務(wù)時的性能差異如何,各位讀者不免會有所好奇。
微軟數(shù)據(jù)科學(xué)家Ilia Karmanov最新測試的結(jié)果顯示,亞馬遜MXNet在CNN、RNN與NLP情感分析任務(wù)上性能強勁,而TensorFlow僅擅長于特征提取。
項目內(nèi)的測試代碼并非專門為深度學(xué)習(xí)性能而編寫,目的僅在于簡單比較一下各框架之間的性能差異。
以下為該項目詳情。
我們做這個榜單的初衷是為了好玩,所以省略了很多重要部分的比較。比如:幫助和支持,自定義圖層(可以創(chuàng)建一個膠囊網(wǎng)絡(luò)嗎?),數(shù)據(jù)加載器,調(diào)試,不同的平臺支持,分布式訓(xùn)練等等。
我們不確定是否能對框架的整體性能提出任何建議,因為本項目主要還是在演示如何在不同的框架中創(chuàng)建相同的神經(jīng)網(wǎng)絡(luò)。
例如,使用Caffe2在Python中創(chuàng)建CNN,然后在Julia中使用KNet復(fù)制這個網(wǎng)絡(luò),或者也可以在PyTorch中嘗試創(chuàng)建一個RNN并在Tensorflow中復(fù)制它。你可以在Chainer中進行一些特征提取,然后在CNTK中復(fù)制這個操作。
因為Microsoft Azure深度學(xué)習(xí)虛擬機NC6上的框架已經(jīng)更新到了最新版本,所以notebooks代碼選擇在上面運行,僅占用了顯卡Nvidia K80 GPU一半的性能。

測試目標
創(chuàng)建深度學(xué)習(xí)框架的Rosetta Stone(譯者注:一個非常好用的外語學(xué)習(xí)軟件),使數(shù)據(jù)科學(xué)家能夠輕松地將他們的專業(yè)知識從一個框架轉(zhuǎn)移到另一個框架(通過翻譯,而不是從頭開始學(xué)習(xí))。另外,是為了更加透明地在模型訓(xùn)練時間和默認選項方面進行比較。
許多在線教程使用非常低級別的API,雖然這些API非常詳細,但對于大多數(shù)用例來說,并沒有多大意義,因為大多數(shù)時候有更高級別的幫助程序可用。在這里,我們直接忽略沖突的默認值的條件下,嘗試采用最高級別的API,以便在框架之間進行更容易的比較。
下面的結(jié)果將證明,一旦使用更高級的API,代碼結(jié)構(gòu)變得非常相似,并且可以粗略地表示為:
加載數(shù)據(jù); x_train,x_test,y_train,y_test = cifar_for_library(channel_first =?,one_hot =?)
生成CNN / RNN網(wǎng)絡(luò)結(jié)構(gòu)(通常在最后一層上不激活)
指定損失函數(shù)(交叉熵與softmax是一起指定的),優(yōu)化器并初始化網(wǎng)絡(luò)權(quán)重+會話
用mini-batch的方式來訓(xùn)練訓(xùn)練集并使用自定義迭代器(所有框架都使用公共的數(shù)據(jù)庫)
在測試集的mini-batch上面進行預(yù)測
計算準確率
本質(zhì)上,我們是在比較一系列確定性的數(shù)學(xué)運算(盡管是隨機初始化),所以比較跨框架的準確性就是沒有意義了。相反,它會提示我們?nèi)z查想要的匹配(?),以確保我們正在比較的是相同的模型架構(gòu)。
測試結(jié)果
在CIFAR-10數(shù)據(jù)集上訓(xùn)練CNN(VGG類型)網(wǎng)絡(luò)
性能對比- 圖像識別
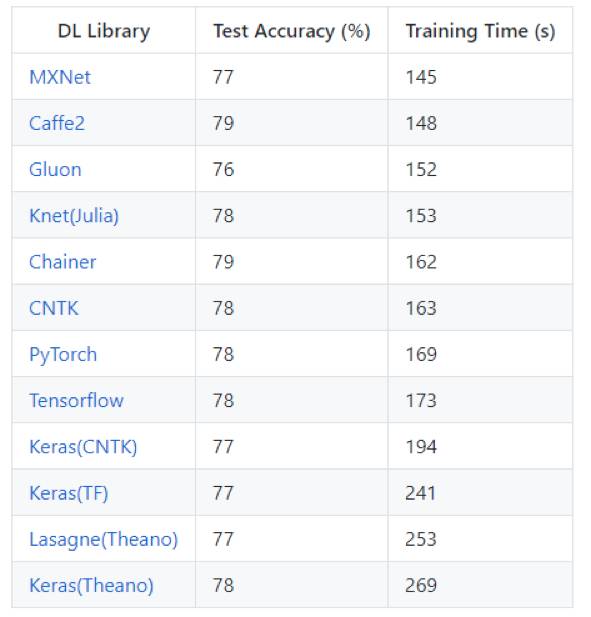
該模型的輸入是標準的CIFAR-10數(shù)據(jù)集,包含五萬個訓(xùn)練圖像和一萬個測試圖像,均勻分布在10個類別中。每個32×32像素的圖像轉(zhuǎn)化為張量的形式(3,32,32),像素值從0-255歸一化到0-1。 例如:汽車圖像的相關(guān)參數(shù)y=(0,1,0,0,0,0,0,0,0,0),其標簽是= [飛機,汽車,鳥,貓,鹿,狗,青蛙,馬,船 ,卡車]
在IMDB數(shù)據(jù)集上訓(xùn)練RNN(GRU,門控循環(huán)單元)
性能對比 - 自然語言處理(情感分析)

這個模型的輸入是標準的IMDB電影評論數(shù)據(jù)集,包含兩萬五千個訓(xùn)練評論和兩萬五千個測試評論,統(tǒng)一分為2個等級(正面/負面)。 下載的評論已經(jīng)是單詞索引的張量形式,例如 (如果你喜歡像南方公園這樣的成人喜劇漫畫)將被表示為(1 2 3 4 5 6 3 7 8)。
遵循Keras框架的處理方法,其中起始字符被設(shè)置為1,詞匯外(使用3萬大小的詞匯庫)被表示為2,因此詞索引從3開始。通過零填充/截斷的方式,把每條評論都固定到150個字。
在可能的情況下,我會嘗試使用cudnn的方式來優(yōu)化RNN(由CUDNN = True開關(guān)來控制),因為我們有一個可以輕易降低到CuDNN水平的簡單的RNN。例如,對于CNTK,我們使用optimized_rnnstack而不是Recurrence(LSTM())函數(shù)。 雖然它不太靈活,但是速度要快得多。
例如,對于CNTK,我們不能再使用類似層歸一化的更復(fù)雜的變量。在PyTorch中,這是默認啟用的。但是對于MXNet,我無法找到這樣的RNN函數(shù),而是使用稍慢的Fused RNN函數(shù)。
Keras最近剛得到了cudnn的支持,但是只有Tensorflow后端可以使用(而不是CNTK后端)。 Tensorflow有許多RNN變種,其中包括他們自己定制的內(nèi)核。這里有一個很好的基準,我將嘗試更新使用CudnnLSTM的樣例而不是當前的方法。
注:CNTK框架是支持動態(tài)軸,這意味著我們不需要將輸入填充到150個字,就可以按原樣輸入,但是由于我找不到與其他框架做到這一點的方法,所以我還是采用填充的方法。這樣對CNTK框架有點不公平,因為會低估了它的能力。
分類模型創(chuàng)建大小為(150x125)的嵌入矩陣,然后采用100個門控循環(huán)單元,并將最終輸出(不是輸出序列也不是隱藏狀態(tài))作為輸出。
ResNet-50(特征提取)推斷性能對比

加載一個預(yù)訓(xùn)練好的ResNet50模型并在avg_pooling結(jié)束后變成(7,7)向量處截斷,輸出一個2048維的向量。在這里可以插入一個softmax層或其它的分類器,例如用激勵樹來實現(xiàn)遷移學(xué)習(xí)。此處,在CPU和GPU上向avg_pool層進行前向傳遞的時間均計算在內(nèi)。
我從中學(xué)到了什么?
關(guān)于CNN
以下提供了一些我在看到github上面提出的問題后比較跨框架的測試準確率時的一些見解。
1. 上面的例子(Keras除外),為了便于比較,嘗試使用相同級別的API,因此都使用相同的生成器函數(shù)。 對于MXNet和CNTK,我嘗試了一個更高級別的API,在這里我使用了框架的訓(xùn)練生成器函數(shù)。在這個例子中,速度的提高是微不足道的,因為整個數(shù)據(jù)集都是作為NumPy數(shù)組加載到RAM中的,而且在處理的時候每個迭代的數(shù)據(jù)都是隨機的。我懷疑框架的生成器是異步執(zhí)行隨機的。
奇怪的是,框架的隨機操作似乎是在一個批次層次上而不是在一個觀察層次上進行的,因此會略微降低測試精度(至少在10個迭代之后)。 對于我們會進行的輸入輸出活動以及可能在運行中進行預(yù)處理和數(shù)據(jù)增強的情況,自定義的生成器將對性能產(chǎn)生更大的影響。
2.讓CuDNN自動調(diào)整/窮舉搜索參數(shù)(能選擇最有效的CNN算法來固定圖像的大小)能在性能上帶來一個巨大的提升。Chainer,Caffe2,PyTorch和Theano這四個框架都必須手動啟動它。CNTK,MXNet和Tensorflow三個框架是默認啟用CuDNN的。
賈揚清提到了cudnnGet (默認)和cudnnFind之間性能的提升。然而,其在TitanX GPU上的差異小得多。
現(xiàn)在看來,在K80 +上采用的新的cudnn使其性能差異問題更為突出。由于在目標檢測各種圖像大小的組合上運行cudnnFind會出現(xiàn)較大的性能下降,所以窮舉搜索算法應(yīng)該是不能在目標檢測的任務(wù)上使用了。
3.使用Keras時,選擇與后端框架相匹配的[NCHW]排序很重要。CNTK是channels first,我曾經(jīng)在Keras上錯誤的配置為channels last。這樣就必須在每一個batch上改變它的順序,同時會造成性能嚴重的下降。通常,[NHWC]是大多數(shù)框架的默認設(shè)置(如Tensorflow),[NCHW]是在NVIDIA GPU上使用cuDNN訓(xùn)練時可以使用的最佳順序。
4.Tensorflow,PyTorch,Caffe2和Theano四個框架都需要一個提供給dropout層的布爾值來指示我們是否訓(xùn)練,因為這對在測試集上的準確率有很大的影響,72 vs 77%。因此,在這種情況下不應(yīng)該使用Dropout來測試。
5.使用Tensorflow框架時需要兩個改變:通過啟用TF_ENABLE_WINOGRAD_NONFUSED,同時還改變提供給channel first而不是channel last的維度(data_format ='channels_first')。對卷積操作啟用WINOGRAD,自然而然的就將keras變成改成以TF作為后端。
6.Softmax層通常與cross_entropy_loss()函數(shù)一起用于大部分的功能,你需要檢查一下你是否要激活最終的全連接層,以節(jié)省使用兩次的時間。
7.不同框架的內(nèi)核初始化器可能會有所不同,并且會對準確性有±1%的影響。我盡可能統(tǒng)一地指定xavier / glorot,而不要太冗長的內(nèi)核初始化。
8.為了SGD-momentum中momentum類型的實現(xiàn),我不得不關(guān)閉unit_gain。因為它在CNTK框架上是默認關(guān)閉,以此來跟其他框架的實現(xiàn)保持一致。
9.Caffe2對網(wǎng)絡(luò)的第一層(no_gradient_to_input = 1)進行了額外的優(yōu)化,可以通過不計算輸入的梯度產(chǎn)生了一個比較小的速度提升。Tensorflow和MXNet可能已經(jīng)默認啟用了此功能。 計算這個梯度對于研究和像deep-dream的網(wǎng)絡(luò)是有用的。
10.在max-pooling之后使用ReLU激活意味著你在減少維度之后才執(zhí)行一個計算,從而能夠減少幾秒鐘。這可以使采用MXNet框架的運行時間縮短3秒。
11.一些可能有用的額外檢查:
是否指定的內(nèi)核(3)變成了對稱元組(3,3)或1維卷積(3,1)?
步長(最大池化中的)是否是默認為(1,1)或等于內(nèi)核(Keras這樣做的)?
默認填充通常是off(0,0)或valid,但檢查一下它不是on/'same'是很有用的
卷積層上默認的激活是否是'None'或'ReLu'的
Bias值的初始化可能不能(有時是沒有bias值)
梯度的下降和無窮大的值或 NaNs的處理可能因框架不同而不同
有些框架支持稀疏的標簽,而不是one-hot編碼類型的(例如我使用的Tensorflow有f.nn.sparse_softmax_cross_entropy_with_logits函數(shù))
數(shù)據(jù)類型的假設(shè)可能是不同的-例如,我曾經(jīng)試著用float32和int32類型來初始化X和Y。但是在torch中Y需要double類型(是為了可以使用在torch.LongTensor(y).cuda函數(shù)中)的數(shù)據(jù)
如果框架有一個稍微低級一點的API,請確保在測試過程中不要通過設(shè)置training= False來計算梯度。
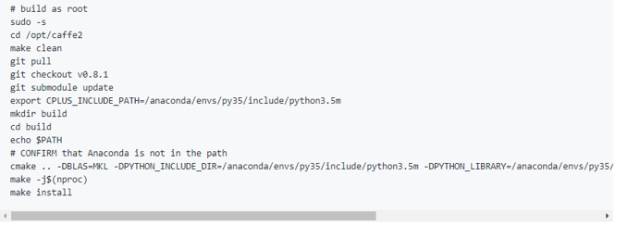
12.據(jù)說安裝支持python3.5版本的Caffe2有點困難。因此我這里分享了一個腳本
關(guān)于RNN
1. 大多數(shù)框架(例如Tensorflow)上,都有多個RNN實現(xiàn)/內(nèi)核; 一旦降低到cudnn LSTM / GRU級別,執(zhí)行速度是最快的。但是,這種實現(xiàn)不太靈活(例如,可能希望層歸一化),并且接下來如果在CPU上運行推理可能會出現(xiàn)問題。
2.在cuDNN這個層面,大部分框架的運行時間是非常相似的。這個Nvidia的博客文章寫到過幾個有趣的用于循環(huán)神經(jīng)網(wǎng)絡(luò)cuDNN優(yōu)化的方法,例如,融合 - “將許多小矩陣的計算結(jié)合為大矩陣的計算,并盡可能地對計算進行流式處理,增加與內(nèi)存I / O計算的比率,從而在GPU上獲得更好的性能。”
-
亞馬遜
+關(guān)注
關(guān)注
8文章
2680瀏覽量
83629 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5516瀏覽量
121558 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60632
原文標題:深度學(xué)習(xí)框架哪家強?TensorFlow擅長推斷特征提取,MXNet稱霸CNN、RNN和情感分析
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
深度學(xué)習(xí)工作負載中GPU與LPU的主要差異

JavaWeb框架比較
RNN與LSTM模型的比較分析
pcie在深度學(xué)習(xí)中的應(yīng)用
AI大模型與深度學(xué)習(xí)的關(guān)系
FPGA做深度學(xué)習(xí)能走多遠?
NVIDIA推出全新深度學(xué)習(xí)框架fVDB
PyTorch深度學(xué)習(xí)開發(fā)環(huán)境搭建指南

深度學(xué)習(xí)中的無監(jiān)督學(xué)習(xí)方法綜述
深度學(xué)習(xí)與nlp的區(qū)別在哪
深度學(xué)習(xí)常用的Python庫
TensorFlow與PyTorch深度學(xué)習(xí)框架的比較與選擇
深度學(xué)習(xí)與傳統(tǒng)機器學(xué)習(xí)的對比
深度學(xué)習(xí)編譯工具鏈中的核心——圖優(yōu)化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論