 人工神經元模型的三要素是什么
人工神經元模型的三要素是什么
人工神經元模型是人工智能和機器學習領域中非常重要的概念之一。它模仿了生物神經元的工作方式,通過數學和算法來實現對數據的處理和學習。
一、人工神經元模型的基本概念
1.1 生物神經元與人工神經元
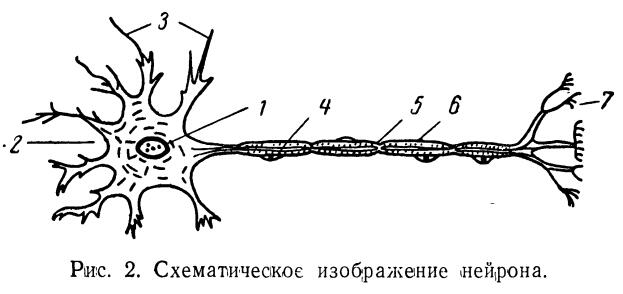
生物神經元是構成神經系統的基本單元,它們通過突觸與其他神經元相互連接,實現信息的傳遞和處理。人工神經元則是模仿生物神經元的一種數學模型,它通過數學和算法來實現對數據的處理和學習。
1.2 人工神經元模型的發展
人工神經元模型的發展可以追溯到20世紀40年代,當時科學家們開始嘗試使用數學模型來模擬生物神經元的工作方式。隨著計算機技術的發展,人工神經元模型逐漸成為人工智能和機器學習領域中的重要工具。
1.3 人工神經元模型的應用
人工神經元模型在許多領域都有廣泛的應用,包括圖像識別、語音識別、自然語言處理、推薦系統等。通過訓練人工神經元模型,我們可以自動識別和處理大量的數據,從而實現智能化的決策和預測。
二、人工神經元模型的三要素
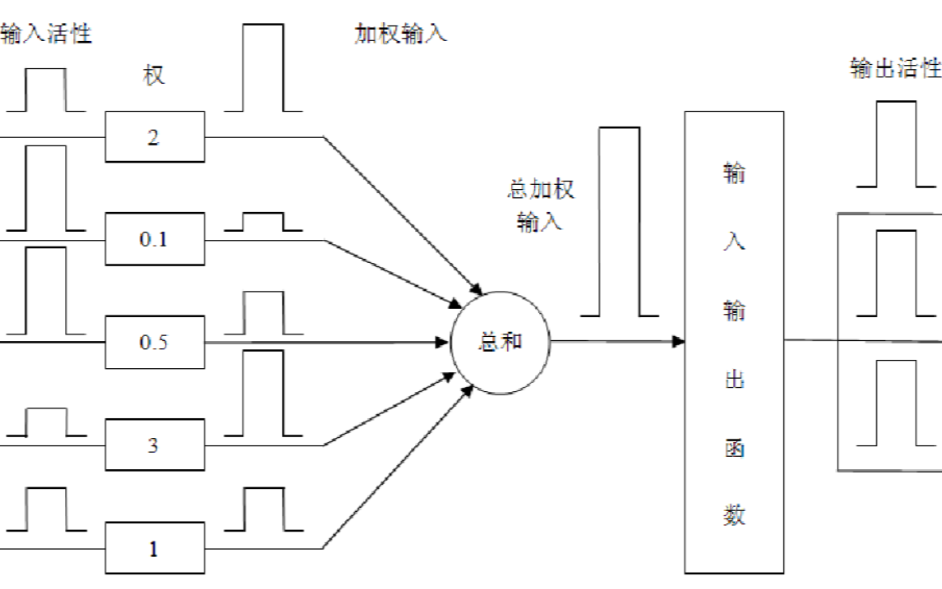
2.1 權重
權重是人工神經元模型中非常重要的一個概念,它代表了神經元之間的連接強度。在人工神經元模型中,每個神經元都與其他神經元相連,權重決定了這些連接的強度。權重的值可以是正數或負數,正數表示激活作用,負數表示抑制作用。
權重的設置對人工神經元模型的性能有很大的影響。在訓練過程中,我們通過調整權重的值來優化模型的性能。權重的調整通常采用梯度下降算法,通過計算損失函數的梯度來更新權重。
2.2 激活函數
激活函數是人工神經元模型中的另一個關鍵要素,它決定了神經元的輸出。激活函數通常是一個非線性函數,它可以將神經元的輸入線性組合轉換為非線性輸出。常見的激活函數包括Sigmoid函數、Tanh函數、ReLU函數等。
激活函數的選擇對人工神經元模型的性能有很大的影響。不同的激活函數具有不同的特點,例如Sigmoid函數具有平滑的曲線和良好的收斂性,但容易出現梯度消失的問題;ReLU函數具有計算簡單和收斂速度快的優點,但容易出現梯度爆炸的問題。
2.3 損失函數
損失函數是評估人工神經元模型性能的一個重要指標,它衡量了模型預測值與實際值之間的差異。損失函數的選擇對模型的訓練和優化有很大的影響。常見的損失函數包括均方誤差損失、交叉熵損失、Hinge損失等。
損失函數的計算通常涉及到模型的預測值和實際值,以及模型的參數。在訓練過程中,我們通過最小化損失函數來優化模型的參數,從而提高模型的預測性能。
三、人工神經元模型的訓練過程
3.1 數據預處理
在訓練人工神經元模型之前,我們需要對數據進行預處理,包括數據清洗、特征選擇、特征縮放等。數據預處理的目的是提高模型的訓練效率和預測性能。
3.2 模型初始化
模型初始化是訓練人工神經元模型的第一步,我們需要為模型設置初始的權重和偏置。權重和偏置的初始化方法有很多,例如隨機初始化、零初始化等。合理的初始化方法可以提高模型的訓練效率和預測性能。
3.3 前向傳播
前向傳播是計算模型輸出的過程,它包括輸入數據的線性組合、激活函數的計算等。在前向傳播過程中,我們可以得到模型的預測值。
3.4 損失計算
損失計算是評估模型性能的過程,它通過計算損失函數來衡量模型預測值與實際值之間的差異。在損失計算過程中,我們可以得到模型的損失值。
3.5 反向傳播
反向傳播是優化模型參數的過程,它通過計算損失函數的梯度來更新模型的權重和偏置。在反向傳播過程中,我們可以使用梯度下降算法、隨機梯度下降算法等來調整模型的參數。
3.6 模型評估
模型評估是檢驗模型性能的過程,它通過計算模型在測試集上的損失和準確率等指標來評估模型的預測性能。在模型評估過程中,我們可以使用交叉驗證、混淆矩陣等方法來評估模型的性能。
四、人工神經元模型的優化方法
4.1 正則化
正則化是一種防止模型過擬合的方法,它通過在損失函數中添加正則項來限制模型的復雜度。常見的正則化方法包括L1正則化、L2正則化等。
4.2 Dropout
Dropout是一種防止模型過擬合的方法,它通過在訓練過程中隨機丟棄一些神經元來增加模型的魯棒性。Dropout可以有效地減少模型對訓練數據的依賴,提高模型的泛化能力。
-
人工智能
+關注
關注
1796文章
47666瀏覽量
240285 -
模型
+關注
關注
1文章
3305瀏覽量
49220 -
機器學習
+關注
關注
66文章
8438瀏覽量
133084 -
人工神經元
+關注
關注
0文章
11瀏覽量
6315
發布評論請先 登錄
相關推薦
基于非聯合型學習機制的學習神經元模型
神經網絡與神經網絡控制的學習課件免費下載
一種具有高度柔性與可塑性的超香腸覆蓋式神經元模型





 工商網監
工商網監
評論