") Transformer架構(gòu)在自然語言處理中的應(yīng)用
Transformer架構(gòu)在自然語言處理中的應(yīng)用
引言
隨著人工智能技術(shù)的飛速發(fā)展,自然語言處理(NLP)領(lǐng)域取得了顯著的進(jìn)步。其中,Transformer架構(gòu)的提出,為NLP領(lǐng)域帶來了革命性的變革。本文將深入探討Transformer架構(gòu)的核心思想、組成部分以及在自然語言處理領(lǐng)域的應(yīng)用,旨在幫助讀者全面理解并應(yīng)用這一革命性的技術(shù)。
Transformer架構(gòu)的核心思想
Transformer架構(gòu)的核心思想是使用自注意力機(jī)制(self-attention mechanism)來建立輸入序列的表示。傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)架構(gòu)在處理序列數(shù)據(jù)時(shí),需要按照順序逐步處理,這在一定程度上限制了模型的并行處理能力。而Transformer架構(gòu)則打破了這一限制,通過自注意力機(jī)制并行地處理整個(gè)序列,大大提高了模型的計(jì)算效率。
自注意力機(jī)制
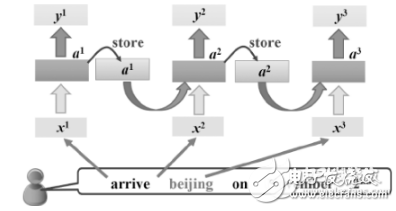
自注意力機(jī)制是Transformer架構(gòu)的核心組成部分。它允許模型在處理序列中的每個(gè)元素時(shí),都能夠關(guān)注到序列中的其他元素,從而捕獲序列中任意兩個(gè)位置之間的依賴關(guān)系,無論它們之間的距離有多遠(yuǎn)。對于輸入序列中的每個(gè)詞,計(jì)算其與其他詞的點(diǎn)積,然后通過softmax函數(shù)轉(zhuǎn)化為權(quán)重,這些權(quán)重會被用來組合輸入的詞向量,生成一個(gè)新的上下文相關(guān)的詞向量。
編碼器與解碼器
Transformer架構(gòu)由兩個(gè)主要組件組成:編碼器(Encoder)和解碼器(Decoder)。編碼器負(fù)責(zé)將輸入序列編碼成一個(gè)表示,而解碼器則根據(jù)該表示生成輸出序列。每個(gè)組件都由多個(gè)層級組成,每個(gè)層級包含多頭自注意力機(jī)制和全連接神經(jīng)網(wǎng)絡(luò)。
- 編碼器 :編碼器的主要任務(wù)是將輸入序列轉(zhuǎn)換為一種內(nèi)部表示。在編碼器中,每個(gè)層級的輸入首先通過自注意力機(jī)制進(jìn)行處理,然后通過全連接神經(jīng)網(wǎng)絡(luò)進(jìn)行變換。經(jīng)過多個(gè)層級的堆疊,編碼器最終將輸入序列轉(zhuǎn)換為一個(gè)固定長度的向量表示。
- 解碼器 :解碼器的主要任務(wù)是根據(jù)編碼器的輸出生成目標(biāo)序列。與編碼器類似,解碼器也包含多個(gè)層級,每個(gè)層級都包含自注意力機(jī)制和全連接神經(jīng)網(wǎng)絡(luò)。不同的是,解碼器在每個(gè)層級的輸入中還會引入編碼器的輸出作為上下文信息,以便在生成目標(biāo)序列時(shí)能夠考慮到源語言序列的信息。
Transformer架構(gòu)的組成部分
自注意力層
自注意力層是Transformer架構(gòu)中的核心層。它通過計(jì)算輸入序列中每個(gè)元素與其他元素之間的相關(guān)性,來生成新的上下文相關(guān)的表示。每個(gè)自注意力層都包含多個(gè)頭(head),每個(gè)頭都可以獨(dú)立地進(jìn)行自注意力計(jì)算,并將結(jié)果拼接后通過線性變換得到最終輸出。這種多頭自注意力機(jī)制可以更好地捕捉到輸入序列中的局部和全局信息。
前饋神經(jīng)網(wǎng)絡(luò)層
前饋神經(jīng)網(wǎng)絡(luò)層是一個(gè)普通的全連接神經(jīng)網(wǎng)絡(luò),它會對自注意力層的輸出進(jìn)行進(jìn)一步的處理。前饋神經(jīng)網(wǎng)絡(luò)層的作用是對自注意力層的輸出進(jìn)行非線性變換,以提高模型的表示能力。
殘差連接與層歸一化
在Transformer架構(gòu)中,每個(gè)子層后面都有一個(gè)殘差連接和層歸一化操作。殘差連接通過在網(wǎng)絡(luò)中引入跳躍連接,將前一層的輸入直接與當(dāng)前層的輸出相加,以避免在深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程中出現(xiàn)梯度消失或梯度爆炸的問題。層歸一化則是一種特征縮放技術(shù),用于穩(wěn)定深度神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程。
Transformer架構(gòu)在自然語言處理中的應(yīng)用
預(yù)訓(xùn)練語言模型
預(yù)訓(xùn)練語言模型(Pretrained Language Model)是利用大規(guī)模語料庫進(jìn)行訓(xùn)練,從而得到具有強(qiáng)大表示能力的模型。其中最具代表性的模型之一是BERT(Bidirectional Encoder Representations from Transformers),它通過使用Transformer模型進(jìn)行雙向上下文信息的捕捉,在多項(xiàng)NLP任務(wù)中取得了顯著成果。另一個(gè)重要的模型是GPT(Generative Pre-trained Transformer),它通過自回歸的方式進(jìn)行語言建模,在文本生成、文本摘要等任務(wù)中表現(xiàn)出色。
機(jī)器翻譯
機(jī)器翻譯是自然語言處理領(lǐng)域的經(jīng)典任務(wù)之一。傳統(tǒng)的基于RNN或LSTM的翻譯方法在處理長序列時(shí)會出現(xiàn)梯度消失或梯度爆炸的問題。而基于Transformer的翻譯方法通過使用自注意力機(jī)制進(jìn)行信息的交互與傳遞,可以更好地捕捉到源語言和目標(biāo)語言之間的語義關(guān)系。因此,基于Transformer的翻譯方法在翻譯質(zhì)量、速度和靈活性等方面都表現(xiàn)出了顯著的優(yōu)勢。
文本分類與情感分析
Transformer模型也被廣泛應(yīng)用于文本分類和情感分析任務(wù)中。通過將文本輸入到預(yù)訓(xùn)練語言模型中,可以得到文本的向量表示,進(jìn)而使用分類器或回歸器對文本進(jìn)行分類或情感極性預(yù)測。Transformer模型在文本分類和情感分析任務(wù)中表現(xiàn)出了較高的準(zhǔn)確率和魯棒性。
其他應(yīng)用
除了上述應(yīng)用外,Transformer模型還被廣泛應(yīng)用于其他自然語言處理任務(wù)中,如問答系統(tǒng)、命名實(shí)體識別、文本生成等。其強(qiáng)大的表示能力和高效的處理能力使得它在各種NLP任務(wù)中都取得了優(yōu)異的成績。
實(shí)踐建議與未來展望
實(shí)踐建議
- 數(shù)據(jù)預(yù)處理 :對輸入序列進(jìn)行合適的數(shù)據(jù)預(yù)處理是提高模型性能的關(guān)鍵。例如,對于文本數(shù)據(jù),可以進(jìn)行分詞、去除停用詞等操作,以提高模型的泛化能力。
- 模型調(diào)優(yōu) :針對具體任務(wù)調(diào)整模型參數(shù)和結(jié)構(gòu)是提高模型性能的有效途徑。對于Transformer模型而言,可以通過以下幾種方式進(jìn)行調(diào)優(yōu):
- 調(diào)整層數(shù)和頭數(shù) :增加Transformer模型的層數(shù)和頭數(shù)可以提高模型的復(fù)雜度和表示能力,但也會增加模型的計(jì)算量和訓(xùn)練時(shí)間。因此,需要根據(jù)具體任務(wù)的需求和計(jì)算資源來選擇合適的層數(shù)和頭數(shù)。
- 調(diào)整隱藏層大小 :隱藏層大小是模型參數(shù)量的一個(gè)重要因素,增加隱藏層大小可以提高模型的表示能力,但也會增加模型的復(fù)雜度和訓(xùn)練難度。因此,需要在模型性能和計(jì)算資源之間做出權(quán)衡。
- 使用預(yù)訓(xùn)練模型 :利用在大規(guī)模語料庫上預(yù)訓(xùn)練的模型進(jìn)行微調(diào),可以顯著提高模型在特定任務(wù)上的性能。預(yù)訓(xùn)練模型已經(jīng)學(xué)習(xí)到了豐富的語言知識和表示能力,通過微調(diào)可以使其更好地適應(yīng)具體任務(wù)的需求。
訓(xùn)練策略
采用合適的訓(xùn)練策略對于提高模型性能至關(guān)重要。以下是一些常用的訓(xùn)練策略:
- 預(yù)訓(xùn)練加微調(diào) :先在大規(guī)模語料庫上進(jìn)行預(yù)訓(xùn)練,然后在具體任務(wù)上進(jìn)行微調(diào)。這種方式可以充分利用預(yù)訓(xùn)練模型學(xué)到的語言知識和表示能力,同時(shí)避免從頭開始訓(xùn)練模型所需的巨大計(jì)算量和時(shí)間成本。
- 混合精度訓(xùn)練 :通過使用混合精度(Mixed Precision)訓(xùn)練技術(shù),可以在保持模型性能的同時(shí)減少計(jì)算量和內(nèi)存占用。混合精度訓(xùn)練通常涉及使用半精度(FP16)或更低精度的浮點(diǎn)數(shù)進(jìn)行計(jì)算,并通過特定的優(yōu)化算法來減少精度損失。
- 分布式訓(xùn)練 :利用多臺機(jī)器或多塊GPU進(jìn)行分布式訓(xùn)練,可以顯著加快模型的訓(xùn)練速度。分布式訓(xùn)練通過并行計(jì)算和數(shù)據(jù)并行等方式,將訓(xùn)練任務(wù)分解到多個(gè)計(jì)算節(jié)點(diǎn)上,從而實(shí)現(xiàn)更快的訓(xùn)練速度。
未來展望
Transformer架構(gòu)的未來發(fā)展?jié)摿θ匀痪薮蟆kS著技術(shù)的不斷進(jìn)步和應(yīng)用場景的不斷拓展,我們可以期待以下幾個(gè)方面的發(fā)展:
- 更高效的模型設(shè)計(jì) :未來的研究將聚焦于設(shè)計(jì)更輕量級、更高效的Transformer模型,以滿足低資源場景和實(shí)時(shí)應(yīng)用的需求。這可能涉及到模型剪枝、量化、蒸餾等技術(shù),以減少模型的計(jì)算量和存儲需求。
- 跨模態(tài)學(xué)習(xí)與推理 :隨著多模態(tài)數(shù)據(jù)的日益豐富,Transformer架構(gòu)有望擴(kuò)展到音頻、視頻、圖像等領(lǐng)域,實(shí)現(xiàn)跨模態(tài)的學(xué)習(xí)和推理。這將使得人工智能系統(tǒng)能夠同時(shí)理解和處理多種類型的數(shù)據(jù),從而在實(shí)際應(yīng)用中發(fā)揮更大的作用。
- 增強(qiáng)可解釋性和魯棒性 :雖然Transformer模型在多個(gè)領(lǐng)域取得了顯著的成果,但其內(nèi)部機(jī)制仍然相對復(fù)雜,缺乏直觀的解釋性。未來的研究將聚焦于提高Transformer模型的可解釋性,揭示其內(nèi)部工作機(jī)制,并增強(qiáng)其魯棒性,以應(yīng)對各種復(fù)雜和不確定的情況。
- 持續(xù)學(xué)習(xí)與自適應(yīng)能力 :隨著人工智能應(yīng)用的不斷發(fā)展,模型需要不斷適應(yīng)新的數(shù)據(jù)和任務(wù)。未來的Transformer模型將具備更強(qiáng)的持續(xù)學(xué)習(xí)和自適應(yīng)能力,能夠在線學(xué)習(xí)和更新,以適應(yīng)不斷變化的環(huán)境和需求。這將使得人工智能系統(tǒng)更加智能、靈活和可靠。
總之,Transformer架構(gòu)作為自然語言處理領(lǐng)域的重要里程碑,其未來發(fā)展?jié)摿θ匀粺o限。通過不斷研究和探索,我們有信心將Transformer模型打造成為引領(lǐng)人工智能新紀(jì)元的關(guān)鍵技術(shù)。
-
人工智能
+關(guān)注
關(guān)注
1796文章
47666瀏覽量
240281 -
Transformer
+關(guān)注
關(guān)注
0文章
145瀏覽量
6047 -
自然語言處理
+關(guān)注
關(guān)注
1文章
619瀏覽量
13646
發(fā)布評論請先 登錄
相關(guān)推薦
python自然語言
【推薦體驗(yàn)】騰訊云自然語言處理
什么是自然語言處理?
RNN在自然語言處理中的應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論