") 計(jì)算機(jī)視覺(jué)怎么給圖像分類
計(jì)算機(jī)視覺(jué)怎么給圖像分類
圖像分類是計(jì)算機(jī)視覺(jué)領(lǐng)域中的一項(xiàng)核心任務(wù),其目標(biāo)是將輸入的圖像自動(dòng)分配到預(yù)定義的類別集合中。這一過(guò)程涉及圖像的特征提取、特征表示以及分類器的設(shè)計(jì)與訓(xùn)練。隨著深度學(xué)習(xí)技術(shù)的飛速發(fā)展,圖像分類的精度和效率得到了顯著提升。本文將從圖像分類的基本概念、流程、常用算法以及未來(lái)發(fā)展趨勢(shì)等方面進(jìn)行詳細(xì)闡述。
一、圖像分類的基本概念
圖像分類是指利用計(jì)算機(jī)視覺(jué)技術(shù),將輸入的圖像根據(jù)其內(nèi)容自動(dòng)分配到預(yù)定義的類別中的過(guò)程。在計(jì)算機(jī)視覺(jué)中,圖像通常是以像素矩陣的形式表示,每個(gè)像素包含顏色、亮度等信息。圖像分類的任務(wù)就是通過(guò)對(duì)這些像素的處理和分析,最終輸出一個(gè)類別標(biāo)簽。
二、圖像分類的流程
圖像分類的流程主要包括數(shù)據(jù)準(zhǔn)備、特征提取、特征表示、分類器訓(xùn)練與評(píng)估等步驟。
1. 數(shù)據(jù)準(zhǔn)備
數(shù)據(jù)準(zhǔn)備是圖像分類的第一步,也是至關(guān)重要的一步。它包括收集并準(zhǔn)備用于訓(xùn)練和測(cè)試的圖像數(shù)據(jù)集。數(shù)據(jù)集通常被劃分為訓(xùn)練集、驗(yàn)證集和測(cè)試集,分別用于模型的訓(xùn)練、參數(shù)調(diào)整和性能評(píng)估。在準(zhǔn)備數(shù)據(jù)集時(shí),需要對(duì)圖像進(jìn)行標(biāo)注,即給每張圖像分配一個(gè)或多個(gè)類別標(biāo)簽。
2. 特征提取
特征提取是將原始圖像轉(zhuǎn)化為可用于分類的特征向量的過(guò)程。在傳統(tǒng)的計(jì)算機(jī)視覺(jué)方法中,特征提取通常依賴于手工設(shè)計(jì)的特征描述子,如SIFT(尺度不變特征變換)、HOG(方向梯度直方圖)等。然而,這些方法在處理復(fù)雜圖像時(shí)往往效果不佳。近年來(lái),隨著深度學(xué)習(xí)技術(shù)的興起,自動(dòng)特征提取成為主流。卷積神經(jīng)網(wǎng)絡(luò)(CNN)是圖像分類領(lǐng)域最常用的深度學(xué)習(xí)模型之一,它能夠自動(dòng)從圖像中學(xué)習(xí)并提取出具有代表性的特征。
3. 特征表示
特征表示是將提取出來(lái)的特征向量轉(zhuǎn)化為一個(gè)可用于分類的固定維度的向量的過(guò)程。在傳統(tǒng)的機(jī)器學(xué)習(xí)方法中,特征表示通常涉及特征選擇、降維等操作。而在深度學(xué)習(xí)中,特征表示是通過(guò)卷積神經(jīng)網(wǎng)絡(luò)中的卷積層、池化層等自動(dòng)完成的。這些層能夠逐步將圖像的特征從低級(jí)(如邊緣、紋理)抽象到高級(jí)(如形狀、對(duì)象),最終形成可用于分類的特征表示。
4. 分類器訓(xùn)練與評(píng)估
分類器訓(xùn)練是將轉(zhuǎn)化后的特征向量輸入到分類器中,通過(guò)學(xué)習(xí)預(yù)定義類別的樣本來(lái)進(jìn)行分類的過(guò)程。常用的分類器包括支持向量機(jī)(SVM)、K近鄰(KNN)、決策樹(shù)、隨機(jī)森林等。然而,在深度學(xué)習(xí)領(lǐng)域,卷積神經(jīng)網(wǎng)絡(luò)本身就可以作為一個(gè)強(qiáng)大的分類器。通過(guò)反向傳播算法和梯度下降等優(yōu)化方法,可以不斷調(diào)整網(wǎng)絡(luò)參數(shù)以最小化損失函數(shù),從而提高分類的準(zhǔn)確率。
模型評(píng)估是檢驗(yàn)分類器性能的重要環(huán)節(jié)。通常使用驗(yàn)證集對(duì)訓(xùn)練得到的分類器進(jìn)行評(píng)估,并根據(jù)評(píng)估結(jié)果調(diào)整模型參數(shù)。最后,使用測(cè)試集對(duì)訓(xùn)練好的分類器進(jìn)行測(cè)試評(píng)估,計(jì)算模型的準(zhǔn)確率、精度、召回率等指標(biāo)以衡量其性能。
三、常用算法與模型
1. 卷積神經(jīng)網(wǎng)絡(luò)(CNN)
卷積神經(jīng)網(wǎng)絡(luò)是圖像分類領(lǐng)域最常用的深度學(xué)習(xí)模型之一。它由卷積層、池化層、全連接層等組成,能夠自動(dòng)地從圖像中學(xué)習(xí)并提取出具有代表性的特征。CNN通過(guò)卷積操作實(shí)現(xiàn)局部感受野和權(quán)值共享,大大降低了模型的復(fù)雜度并提高了計(jì)算效率。同時(shí),通過(guò)池化操作實(shí)現(xiàn)特征降維和平移不變性,進(jìn)一步提高了模型的魯棒性。
2. 經(jīng)典CNN模型
- LeNet :最早的卷積神經(jīng)網(wǎng)絡(luò)之一,由Yann LeCun等人于1998年提出,主要用于手寫數(shù)字的識(shí)別任務(wù)。
- AlexNet :由Alex Krizhevsky等人于2012年在ImageNet圖像分類競(jìng)賽中獲得了第一名,是一個(gè)具有深度結(jié)構(gòu)的卷積神經(jīng)網(wǎng)絡(luò)。
- VGGNet :由Karen Simonyan和Andrew Zisserman提出,通過(guò)多個(gè)3x3的卷積層和池化層進(jìn)行特征提取,并使用全連接層進(jìn)行分類。
- GoogLeNet :由Google研究團(tuán)隊(duì)提出,創(chuàng)新性地使用了Inception模塊,提高了模型的表示能力。
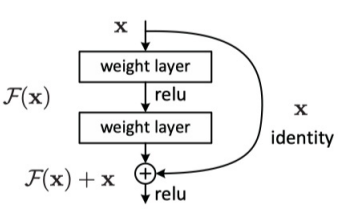
- ResNet :由Microsoft Research Asia提出,通過(guò)引入殘差連接解決了深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練中的梯度消失或梯度爆炸問(wèn)題,使得網(wǎng)絡(luò)可以更加深入地學(xué)習(xí)圖像特征。
3. 其他算法與模型
除了卷積神經(jīng)網(wǎng)絡(luò)外,還有一些其他算法和模型也被應(yīng)用于圖像分類任務(wù)中。例如,支持向量機(jī)(SVM)是一種基于最大間隔原則的分類算法,在圖像分類中表現(xiàn)出色。此外,還有一些基于圖像分割、目標(biāo)檢測(cè)等技術(shù)的圖像分類方法,它們能夠在更細(xì)粒度的層面上對(duì)圖像進(jìn)行分類。
四、當(dāng)前狀況及未來(lái)趨勢(shì)趨勢(shì)
計(jì)算機(jī)視覺(jué)(Computer Vision,CV)作為人工智能領(lǐng)域的一個(gè)重要分支,近年來(lái)取得了顯著的發(fā)展。以下是對(duì)計(jì)算機(jī)視覺(jué)領(lǐng)域當(dāng)前狀況及未來(lái)趨勢(shì)的詳細(xì)分析:
1.當(dāng)前狀況
- 技術(shù)創(chuàng)新與突破
- 分割技術(shù) :如Meta AI開(kāi)發(fā)的Segment Anything Model(SAM),幾乎可以分割圖像中的任何事物,為跨各種數(shù)據(jù)集的復(fù)雜分割任務(wù)開(kāi)辟了新途徑。
- 多模態(tài)大型語(yǔ)言模型 :如GPT-4等模型,彌合了文本和視覺(jué)數(shù)據(jù)之間的差距,使AI能夠理解和解釋復(fù)雜的多模態(tài)輸入。
- 物體檢測(cè) :YOLOv8等模型憑借其增強(qiáng)的速度和準(zhǔn)確性,為物體檢測(cè)樹(shù)立了新標(biāo)準(zhǔn)。YOLO系列的最新版本如YOLOv10,進(jìn)一步提高了性能和效率。
- 自監(jiān)督學(xué)習(xí) :DINOv2等模型展示了自監(jiān)督方法使用較少的標(biāo)記圖像訓(xùn)練高質(zhì)量模型的潛力。
- 文本轉(zhuǎn)圖像和視頻 :Midjourney creations、DALL-E 3、Stable Diffusion XL、Imagen 2等模型,以及Runway、Pika Labs和Emu Video等T2V模型,極大地提高了AI根據(jù)文本描述生成圖像和視頻的質(zhì)量和真實(shí)感。
- 應(yīng)用領(lǐng)域的擴(kuò)展
- 自動(dòng)駕駛 :計(jì)算機(jī)視覺(jué)在自動(dòng)駕駛領(lǐng)域的應(yīng)用日益成熟,通過(guò)識(shí)別道路標(biāo)志、車輛和行人等,提高行駛安全。
- 醫(yī)學(xué)影像 :在醫(yī)療領(lǐng)域,計(jì)算機(jī)視覺(jué)用于分析X射線、MRI等醫(yī)學(xué)圖像,幫助醫(yī)生更準(zhǔn)確地診斷疾病。
- 安全監(jiān)控 :通過(guò)實(shí)時(shí)視頻分析,檢測(cè)異常行為、入侵者和其他安全威脅,提高公共安全水平。
- 娛樂(lè)和社交媒體 :圖像分析技術(shù)用于內(nèi)容推薦、用戶交互和增強(qiáng)現(xiàn)實(shí)(AR)體驗(yàn),如面部識(shí)別技術(shù)用于創(chuàng)建有趣的濾鏡和效果。
- 技術(shù)挑戰(zhàn)
- 數(shù)據(jù)隱私 :隨著圖像數(shù)據(jù)的大量收集和分析,如何保護(hù)個(gè)人隱私成為一個(gè)重要問(wèn)題。
- 算法偏見(jiàn) :機(jī)器學(xué)習(xí)模型可能會(huì)學(xué)習(xí)到訓(xùn)練數(shù)據(jù)中的偏見(jiàn),導(dǎo)致不公平的結(jié)果。
- 模型可解釋性 :深度學(xué)習(xí)模型通常被認(rèn)為是“黑箱”,提高模型的可解釋性是一個(gè)挑戰(zhàn)。
2.未來(lái)趨勢(shì)
- 動(dòng)態(tài)實(shí)時(shí)數(shù)據(jù)分析
- 未來(lái)的計(jì)算機(jī)視覺(jué)技術(shù)將更加注重動(dòng)態(tài)實(shí)時(shí)數(shù)據(jù)的分析,優(yōu)化動(dòng)態(tài)數(shù)據(jù)追蹤及檢測(cè)的相關(guān)算法,以滿足實(shí)時(shí)應(yīng)用的需求。
- 多場(chǎng)景融合應(yīng)用
- 在應(yīng)用領(lǐng)域方面,多場(chǎng)景融合應(yīng)用將是重要的發(fā)展方向。計(jì)算機(jī)視覺(jué)將不僅局限于單一領(lǐng)域的應(yīng)用,而是會(huì)與其他領(lǐng)域進(jìn)行深度融合,如社會(huì)科學(xué)、人體健康等。
- 構(gòu)建多維數(shù)據(jù)集
- 視覺(jué)數(shù)據(jù)方面,需要構(gòu)建多維、全面、立體的數(shù)據(jù)集。結(jié)合物聯(lián)技術(shù)、遙感技術(shù)、AI技術(shù)的成熟,將跨時(shí)空、跨地域、跨物種的視覺(jué)數(shù)據(jù)進(jìn)行綜合疊加,構(gòu)建全周期、全過(guò)程視覺(jué)數(shù)據(jù)集。
- 視覺(jué)生成與內(nèi)容理解統(tǒng)一建模
- 通過(guò)自監(jiān)督、多模態(tài)預(yù)訓(xùn)練產(chǎn)生的基礎(chǔ)大模型,可以指導(dǎo)產(chǎn)生更加可控、有意義的圖像、視頻生成。反過(guò)來(lái),生成模型的建模方式也越來(lái)越多地成為解決復(fù)雜視覺(jué)理解任務(wù)的新思路。
- 邊緣計(jì)算
- 邊緣計(jì)算將變得更加普遍。在設(shè)備上處理視覺(jué)數(shù)據(jù)將提高數(shù)據(jù)處理的速度和效率,適用于自動(dòng)駕駛、智能安全系統(tǒng)等對(duì)實(shí)時(shí)性要求高的應(yīng)用。
- 道德與隱私保護(hù)
- 隨著計(jì)算機(jī)視覺(jué)的廣泛應(yīng)用,道德和隱私問(wèn)題將越來(lái)越受到關(guān)注。開(kāi)發(fā)更加平衡、更加注重隱私的技術(shù)將是未來(lái)的重要趨勢(shì)。
綜上所述,計(jì)算機(jī)視覺(jué)領(lǐng)域正處于快速發(fā)展階段,技術(shù)創(chuàng)新不斷涌現(xiàn),應(yīng)用領(lǐng)域持續(xù)擴(kuò)展。然而,也面臨著數(shù)據(jù)隱私、算法偏見(jiàn)和模型可解釋性等挑戰(zhàn)。未來(lái),隨著技術(shù)的不斷進(jìn)步和應(yīng)用領(lǐng)域的不斷擴(kuò)展,計(jì)算機(jī)視覺(jué)將在更多領(lǐng)域發(fā)揮重要作用,并推動(dòng)人工智能技術(shù)的進(jìn)一步發(fā)展。
-
圖像分類
+關(guān)注
關(guān)注
0文章
93瀏覽量
11956 -
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
8文章
1700瀏覽量
46127 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5513瀏覽量
121546
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深度解析計(jì)算機(jī)視覺(jué)的圖像分割技術(shù)

機(jī)器視覺(jué)與計(jì)算機(jī)視覺(jué)的關(guān)系簡(jiǎn)述
圖像處理與計(jì)算機(jī)視覺(jué)相關(guān)的書(shū)籍有哪些
用于計(jì)算機(jī)視覺(jué)訓(xùn)練的圖像數(shù)據(jù)集介紹
基于計(jì)算機(jī)視覺(jué)的自動(dòng)搜索圖像語(yǔ)義分割架構(gòu)

計(jì)算機(jī)視覺(jué)研究方向有哪些
計(jì)算機(jī)視覺(jué)常用算法_計(jì)算機(jī)視覺(jué)有哪些分類
基于計(jì)算機(jī)視覺(jué)的多維圖像智能
如何快速學(xué)習(xí)計(jì)算機(jī)視覺(jué)圖像的分類
用于計(jì)算機(jī)視覺(jué)訓(xùn)練的圖像數(shù)據(jù)集
用于計(jì)算機(jī)視覺(jué)訓(xùn)練的圖像數(shù)據(jù)集
計(jì)算機(jī)視覺(jué)之目標(biāo)檢測(cè)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論